मार्च में वापस, मैंने SQL सर्वर में व्यापक प्रदर्शन मिथकों पर एक श्रृंखला शुरू की। एक विश्वास जो मुझे समय-समय पर मिलता है, वह यह है कि आप बिना किसी दंड के varchar या nvarchar कॉलम को बड़ा कर सकते हैं।
आइए मान लें कि आप ई-मेल पते संग्रहीत कर रहे हैं। पिछले जीवन में, मैंने इसे काफी हद तक निपटाया - उस समय, RFC 3696 ने कहा था कि एक ई-मेल पता 320 वर्णों (64chars@255chars) का हो सकता है। एक नया RFC, #5321, अब स्वीकार करता है कि 254 वर्ण सबसे लंबा ई-मेल पता हो सकता है। और अगर आप में से किसी के पास इतना लंबा पता है, तो शायद हमें चैट करनी चाहिए। :-)
अब, चाहे आप पुराने मानक से चलें या नए, आपको इस संभावना का समर्थन करना होगा कि कोई व्यक्ति सभी अनुमत वर्णों का उपयोग करेगा। यानी आपको 254 या 320 कैरेक्टर का इस्तेमाल करना होगा। लेकिन मैंने लोगों को मानक पर शोध करने की जहमत नहीं उठाते हुए देखा है, और केवल यह मान लिया है कि उन्हें 1,000 वर्णों, 4,000 वर्णों, या उससे भी आगे का समर्थन करने की आवश्यकता है।
तो आइए एक नजर डालते हैं कि क्या होता है जब हमारे पास अलग-अलग आकार के ई-मेल एड्रेस कॉलम वाली टेबल होती हैं, लेकिन ठीक उसी डेटा को स्टोर करना होता है:
टेबल डीबीओ बनाएं। ईमेल_वी 320 (आईडी int पहचान प्राथमिक कुंजी, ईमेल वर्कर (320)); तालिका बनाएं dbo.Email_V1000 (आईडी int पहचान प्राथमिक कुंजी, ईमेल वर्कर (1000)); तालिका बनाएं dbo.Email_V4000 (आईडी int पहचान प्राथमिक कुंजी, ईमेल varchar(4000)); तालिका बनाएं dbo.Email_Vmax (आईडी int पहचान प्राथमिक कुंजी, ईमेल वर्कर (अधिकतम));
अब, सिस्टम मेटाडेटा से 10,000 काल्पनिक ई-मेल पता उत्पन्न करते हैं, और सभी चार तालिकाओं को समान डेटा से भरते हैं:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ',') से sys.all_columns के रूप में c इनर जॉइन sys.all_objects के रूप में ओ ऑन सी। [ऑब्जेक्ट_आईडी] =ओ। [ऑब्जेक्ट_आईडी] इनर जॉइन sys.all_columns एएस सी 2 ऑन सी। [ऑब्जेक्ट_आईडी] =सी 2। [ऑब्जेक्ट_आईडी] ऑर्डर NEWID द्वारा (); INSERT dbo.Email_V1000 (ईमेल) dbo से ईमेल चुनें। -- आइए डीबीओ पर ऑल्टर इंडेक्स को फिर से बनाएं।ईमेल_वी320 रीबिल्ड;ऑल्टर इंडेक्स ऑल ऑन डीबीओ.ईमेल_वी1000 रीबिल्ड;ऑल्टर इंडेक्स ऑल ऑन डीबीओ.ईमेल_वी4000 रीबिल्ड;ऑल्टर इंडेक्स ऑल ऑन डीबीओ.ईमेल_वीमैक्स रीबिल्ड;सेयह सत्यापित करने के लिए कि प्रत्येक तालिका में बिल्कुल समान डेटा है:
dbo.Email_;
चुनें AVG(LEN(email)), MAX(LEN(email))उन चारों में से मेरे लिए 35 और 77 उपज; आपकी माइलेज भिन्न हो सकती है। आइए यह भी सुनिश्चित करें कि सभी चार तालिकाओं में डिस्क पर समान संख्या में पृष्ठ हों:
ओ.नाम चुनें, COUNT(p.[object_id]) sys.objects से एक क्रॉस लागू के रूप में sys.dm_db_database_page_allocations (DB_ID(), o.object_id, 1, NULL, 'limited') जहां से ओ.नाम LIKE N'Email[_]V[^2]%' GROUP BY o.name;उन सभी चार प्रश्नों में 89 पृष्ठ हैं (फिर से, आपका लाभ भिन्न हो सकता है)।
अब, एक सामान्य क्वेरी लेते हैं जिसके परिणामस्वरूप एक क्लस्टर इंडेक्स स्कैन होता है:
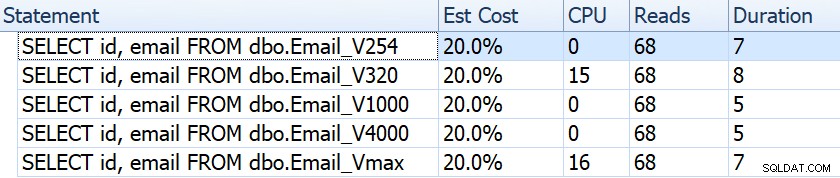
सिलेक्ट आईडी, ईमेल फ्रॉम dbo.Email_; अगर हम अवधि, पढ़ने, और अनुमानित लागत जैसी चीज़ों को देखें, तो वे सभी एक जैसी लगती हैं:
यह लोगों को एक गलत धारणा में फंसा सकता है कि प्रदर्शन पर कोई प्रभाव नहीं पड़ता है। लेकिन अगर हम प्रत्येक योजना में क्लस्टर इंडेक्स स्कैन के टूलटिप पर थोड़ा और करीब से देखें, तो हमें एक अंतर दिखाई देता है जो अन्य, अधिक विस्तृत प्रश्नों में काम आ सकता है:
यहां से हम देखते हैं कि, कॉलम की परिभाषा जितनी बड़ी होगी, अनुमानित पंक्ति और डेटा का आकार उतना ही अधिक होगा। इस सरल क्वेरी में, I/O लागत (0.0512731) परिभाषा की परवाह किए बिना सभी प्रश्नों में समान है, क्योंकि क्लस्टर इंडेक्स स्कैन को वैसे भी सभी डेटा को पढ़ना होता है।
लेकिन ऐसे अन्य परिदृश्य भी हैं जहां इस अनुमानित पंक्ति और कुल डेटा आकार का प्रभाव पड़ेगा:संचालन जिसके लिए अतिरिक्त संसाधनों की आवश्यकता होती है, जैसे कि सॉर्ट। आइए इस हास्यास्पद प्रश्न को लें जो कई प्रकार के संचालन की आवश्यकता के अलावा किसी भी वास्तविक उद्देश्य की पूर्ति नहीं करता है:
चुनें /* वी<आकार> */ ROW_NUMBER() ओवर (ईमेल डीईएससी द्वारा ईमेल ऑर्डर द्वारा विभाजन), ईमेल, रिवर्स (ईमेल), सबस्ट्रिंग (ईमेल, 1, CHARINDEX ('@', ईमेल)) डीबीओ से .Email_Vग्रुप बाय रिवर्स (ईमेल), ईमेल, सबस्ट्रिंग (ईमेल, 1, CHARINDEX ('@', ईमेल)) रिवर्स बाय ऑर्डर (ईमेल), ईमेल; हम इन चार प्रश्नों को चलाते हैं और हम देखते हैं कि सभी योजनाएं इस तरह दिखती हैं:
हालांकि सेलेक्ट ऑपरेटर पर चेतावनी आइकन केवल 4000/अधिकतम टेबल पर दिखाई देता है। चेतावनी क्या है? यह एक अत्यधिक स्मृति अनुदान चेतावनी है, जिसे SQL सर्वर 2016 में पेश किया गया है। यहाँ varchar(4000) के लिए चेतावनी है:
और वर्कर (अधिकतम) के लिए:
आइए थोड़ा करीब से देखें और देखें कि क्या हो रहा है, कम से कम sys.dm_exec_query_stats के अनुसार:
चुनें [टेबल] =सबस्ट्रिंग(टी.[टेक्स्ट], 1, चारिंडेक्स(एन'*/', टी.[टेक्स्ट])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kbFROM sys.dm_exec_query_stats AS s क्रॉस लागू करें sys.dm_exec_sql_text(s.sql_handle) जहां t.[text] LIKE N'%/*%dbo.'+N'Email_V%' s.last_grant_kb द्वारा आदेश;परिणाम:
मेरे परिदृश्य में, अवधि स्मृति अनुदान अंतर (अधिकतम मामले को छोड़कर) से प्रभावित नहीं थी, लेकिन आप कॉलम के घोषित आकार के साथ मेल खाने वाली रैखिक प्रगति को स्पष्ट रूप से देख सकते हैं। जिसे आप एक्सट्रपलेशन के लिए उपयोग कर सकते हैं कि अपर्याप्त मेमोरी वाले सिस्टम पर क्या होगा। या बहुत बड़े डेटा सेट के विरुद्ध अधिक विस्तृत क्वेरी। या महत्वपूर्ण समवर्ती। सॉर्ट संचालन को संसाधित करने के लिए उन परिदृश्यों में से किसी को स्पिल की आवश्यकता हो सकती है, और परिणामस्वरूप अवधि लगभग निश्चित रूप से प्रभावित होगी।
लेकिन ये बड़े स्मृति अनुदान कहाँ से आते हैं? याद रखें, यह वही क्वेरी है, ठीक उसी डेटा के विरुद्ध। समस्या यह है कि, कुछ कार्यों के लिए, SQL सर्वर को यह ध्यान रखना होता है कि एक कॉलम में कितना डेटा *हो सकता है*। यह वास्तव में डेटा की रूपरेखा के आधार पर ऐसा नहीं करता है, और यह <=201 हिस्टोग्राम चरण मानों के आधार पर कोई धारणा नहीं बना सकता है। इसके बजाय, यह अनुमान लगाना होगा कि प्रत्येक पंक्ति में घोषित स्तंभ आकार का आधा मान . होता है . तो एक वर्चर (4000) के लिए, यह मानता है कि प्रत्येक ई-मेल पता 2,000 वर्ण लंबा है।
जब 254 या 320 वर्णों से अधिक लंबा ई-मेल पता संभव नहीं है, तो अधिक आकार देने से कुछ हासिल नहीं होता है, और संभावित रूप से खोने के लिए बहुत कुछ है। एक चर-चौड़ाई वाले कॉलम के आकार को बाद में बढ़ाना अब सभी कमियों से निपटने की तुलना में बहुत आसान है।
बेशक, ओवरसाइज़िंग
charयाncharकॉलम में बहुत अधिक स्पष्ट दंड हो सकते हैं।