SQL सर्वर ने इन-मेमोरी OLTP ऑब्जेक्ट को SQL Server 2014 में पेश किया। प्रारंभिक रिलीज़ में कई सीमाएँ थीं; कुछ को SQL सर्वर 2016 में संबोधित किया गया है, और यह उम्मीद की जाती है कि अगली रिलीज़ में और अधिक को संबोधित किया जाएगा क्योंकि यह सुविधा विकसित हो रही है। अब तक, इन-मेमोरी ओएलटीपी को अपनाना बहुत व्यापक नहीं लगता है, लेकिन जैसे-जैसे फीचर परिपक्व होता है, मुझे उम्मीद है कि अधिक ग्राहक कार्यान्वयन के बारे में पूछना शुरू कर देंगे। किसी भी प्रमुख स्कीमा या कोड परिवर्तन के साथ, मैं यह निर्धारित करने के लिए पूरी तरह से परीक्षण की अनुशंसा करता हूं कि इन-मेमोरी ओएलटीपी अपेक्षित लाभ प्रदान करेगा या नहीं। इसे ध्यान में रखते हुए, मुझे यह देखने में दिलचस्पी थी कि इन-मेमोरी ओएलटीपी के साथ बहुत ही सरल INSERT, UPDATE और DELETE स्टेटमेंट के लिए प्रदर्शन कैसे बदल गया। मुझे उम्मीद थी कि अगर मैं डिस्क-आधारित तालिकाओं के साथ एक समस्या के रूप में लैचिंग या लॉकिंग प्रदर्शित कर सकता हूं, तो इन-मेमोरी टेबल एक समाधान प्रदान करेंगे, क्योंकि वे लॉक- और लैच-फ्री हैं।
मैंने निम्नलिखित परीक्षण विकसित किया है मामले:
- डीएमएल के लिए पारंपरिक संग्रहीत प्रक्रियाओं के साथ एक डिस्क-आधारित तालिका।
- डीएमएल के लिए पारंपरिक संग्रहित प्रक्रियाओं के साथ एक इन-मेमोरी टेबल।
- डीएमएल के लिए मूल रूप से संकलित प्रक्रियाओं के साथ एक इन-मेमोरी टेबल।
मुझे पारंपरिक संग्रहीत प्रक्रियाओं और मूल रूप से संकलित प्रक्रियाओं के प्रदर्शन की तुलना करने में दिलचस्पी थी, क्योंकि मूल रूप से संकलित प्रक्रिया का एक प्रतिबंध यह है कि संदर्भित किसी भी तालिका को इन-मेमोरी होना चाहिए। जबकि कुछ प्रणालियों में एकल-पंक्ति, एकान्त संशोधन आम हो सकते हैं, मैं अक्सर एक या अधिक तालिकाओं तक पहुँचने वाले कई कथनों (चयन और डीएमएल) के साथ एक बड़ी संग्रहीत प्रक्रिया के भीतर होने वाले संशोधनों को देखता हूं। इन-मेमोरी OLTP दस्तावेज़ प्रदर्शन के मामले में सबसे अधिक लाभ प्राप्त करने के लिए मूल रूप से संकलित प्रक्रियाओं का उपयोग करने की दृढ़ता से अनुशंसा करता है। मैं समझना चाहता था कि इसने प्रदर्शन में कितना सुधार किया।
सेट अप
मैंने एक स्मृति-अनुकूलित फ़ाइल समूह के साथ एक डेटाबेस बनाया और फिर डेटाबेस में तीन अलग-अलग टेबल बनाए (एक डिस्क-आधारित, दो इन-मेमोरी):
- डिस्कटेबल
- InMemory_Temp1
- InMemory_Temp2
डीडीएल सभी वस्तुओं के लिए लगभग समान था, जहां उपयुक्त हो, ऑन-डिस्क बनाम इन-मेमोरी के लिए लेखांकन। डिस्कटेबल डीडीएल बनाम इन-मेमोरी डीडीएल:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
मैंने नौ संग्रहित प्रक्रियाएं भी बनाईं - प्रत्येक तालिका/संशोधन संयोजन के लिए एक।
- डिस्कटेबल_सम्मिलित करें
- डिस्कटेबल_अपडेट
- डिस्कटेबल_डिलीट
- InMemRegularSP_Insert
- इनमेमरेगुलरएसपी _अपडेट
- InMemRegularSP _Delete
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
प्रत्येक संग्रहीत प्रक्रिया ने उस संख्या में संशोधनों के लिए लूप में एक पूर्णांक इनपुट स्वीकार किया। संग्रहीत प्रक्रियाओं ने एक ही प्रारूप का पालन किया, विविधताएं केवल तालिका तक पहुंच थीं और वस्तु को मूल रूप से संकलित किया गया था या नहीं। डेटाबेस और ऑब्जेक्ट बनाने का पूरा कोड यहां पाया जा सकता है, उदाहरण के लिए INSERT और UPDATE स्टेटमेंट नीचे दिए गए हैं:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
नोट:INSERT के प्रत्येक सेट के पूरा होने के बाद IDs_* टेबल को फिर से पॉप्युलेट किया गया, और ये तीन अलग-अलग परिदृश्यों के लिए विशिष्ट थे।
परीक्षण पद्धति
परीक्षण .cmd स्क्रिप्ट का उपयोग करके किया गया था, जो एक स्क्रिप्ट को कॉल करने के लिए sqlcmd का उपयोग करता था जो संग्रहीत प्रक्रिया को निष्पादित करता था, उदाहरण के लिए:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"बाहर निकलें
मैंने डेटाबेस से एक या अधिक कनेक्शन बनाने के लिए इस दृष्टिकोण का उपयोग किया जो समवर्ती रूप से चलेंगे। प्रदर्शन में बुनियादी बदलावों को समझने के अलावा, मैं विभिन्न कार्यभार के प्रभाव की भी जांच करना चाहता था। इन लिपियों को तत्काल कनेक्शन के ऊपरी हिस्से को खत्म करने के लिए एक अलग मशीन से शुरू किया गया था। प्रत्येक संग्रहीत प्रक्रिया को एक कनेक्शन द्वारा 1000 बार निष्पादित किया गया था, और मैंने 1 कनेक्शन, 10 कनेक्शन और 100 कनेक्शन (क्रमशः 1000, 10000, और 100000 संशोधन) का परीक्षण किया। मैंने क्वेरी स्टोर का उपयोग करके प्रदर्शन मेट्रिक्स पर कब्जा कर लिया, और प्रतीक्षा सांख्यिकी पर भी कब्जा कर लिया। क्वेरी स्टोर के साथ मैं प्रत्येक संग्रहीत प्रक्रिया के लिए औसत अवधि और सीपीयू पर कब्जा कर सकता था। dm_exec_session_wait_stats का उपयोग करके प्रत्येक कनेक्शन के लिए प्रतीक्षा आँकड़े डेटा कैप्चर किया गया, फिर पूरे परीक्षण के लिए एकत्र किया गया।
मैंने प्रत्येक परीक्षण को चार बार चलाया और फिर इस पोस्ट में उपयोग किए गए डेटा के लिए समग्र औसत की गणना की। कार्यभार परीक्षण के लिए उपयोग की जाने वाली लिपियों को यहां से डाउनलोड किया जा सकता है।
परिणाम
जैसा कि कोई भविष्यवाणी करेगा, इन-मेमोरी ऑब्जेक्ट्स के साथ प्रदर्शन डिस्क-आधारित ऑब्जेक्ट्स की तुलना में बेहतर था। हालांकि, नियमित रूप से संग्रहीत कार्यविधि वाली इन-मेमोरी तालिका में कभी-कभी नियमित संग्रहीत कार्यविधि वाली डिस्क-आधारित तालिका की तुलना में तुलनीय या केवल थोड़ा बेहतर प्रदर्शन होता है। याद रखें:मुझे यह समझने में दिलचस्पी थी कि क्या मुझे वास्तव में एक इन-मेमोरी टेबल के साथ एक बड़ा लाभ प्राप्त करने के लिए एक संकलित संग्रहीत प्रक्रिया की आवश्यकता है। इस परिदृश्य के लिए, मैंने किया। सभी मामलों में, मूल रूप से संकलित प्रक्रिया के साथ इन-मेमोरी तालिका का प्रदर्शन काफी बेहतर था। नीचे दिए गए दो ग्राफ़ समान डेटा दिखाते हैं, लेकिन एक्स-अक्ष के लिए अलग-अलग पैमानों के साथ, नियमित रूप से संग्रहीत प्रक्रियाओं के लिए उस प्रदर्शन को प्रदर्शित करने के लिए जो अधिक समवर्ती कनेक्शन के साथ डेटा को संशोधित करते हैं।
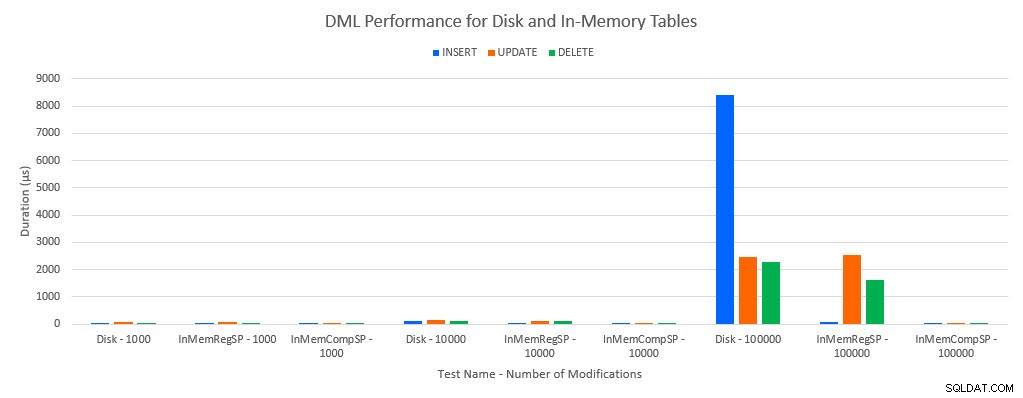
परीक्षण और कार्यभार द्वारा डीएमएल प्रदर्शन
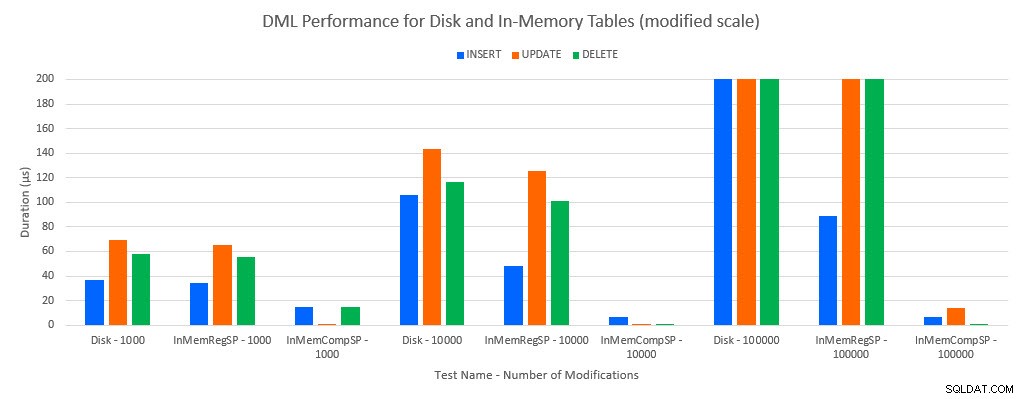
परीक्षण और कार्यभार द्वारा डीएमएल प्रदर्शन [संशोधित पैमाने]
अपवाद है INSERTs इन-मेमोरी टेबल में नियमित रूप से संग्रहीत कार्यविधि के साथ। 100 कनेक्शन के साथ, डिस्क-आधारित तालिका के लिए औसत अवधि 8ms से अधिक है, लेकिन इन-मेमोरी तालिका के लिए 100 माइक्रोसेकंड से कम है। संभावित कारण इन-मेमोरी टेबल के साथ लॉकिंग और लैचिंग की अनुपस्थिति है, और यह प्रतीक्षा आंकड़े डेटा के साथ समर्थित है:
| परीक्षा | <थ>सम्मिलित करेंअद्यतन करें | हटाएं | |
|---|---|---|---|
| डिस्क टेबल - 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP - 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP - 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| डिस्क तालिका - 10,000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP - 10,000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP - 10,000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| डिस्क तालिका - 100,000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP - 100,000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP - 100,000 | WRITELOG | WRITELOG | WRITELOG |
परीक्षण द्वारा सांख्यिकी की प्रतीक्षा करें
कुल संसाधन प्रतीक्षा समय के आधार पर प्रतीक्षा सांख्यिकी डेटा यहां सूचीबद्ध है (जिसे आम तौर पर उच्चतम औसत संसाधन समय में भी अनुवादित किया जाता है, लेकिन अपवाद थे)। WRITELOG प्रतीक्षा प्रकार इस प्रणाली में अधिकांश समय सीमित कारक है। हालाँकि, PAGELATCH_EX INSERT कथन चलाने वाले 100 समवर्ती कनेक्शनों के लिए प्रतीक्षा करता है, यह बताता है कि अतिरिक्त लोड के साथ डिस्क-आधारित तालिकाओं के साथ मौजूद लॉकिंग और लैचिंग व्यवहार सीमित कारक हो सकता है। अद्यतन और DELETE परिदृश्यों में डिस्क-आधारित तालिका परीक्षणों के लिए 10 और 100 कनेक्शन के साथ, औसत संसाधन प्रतीक्षा समय ताले (LCK_M_X) के लिए उच्चतम था।
निष्कर्ष
इन-मेमोरी ओएलटीपी सही कार्यभार के लिए प्रदर्शन को पूरी तरह से बढ़ावा दे सकता है। हालांकि, यहां परीक्षण किए गए उदाहरण बेहद सरल हैं, और इन-मेमोरी समाधान में माइग्रेट करने के लिए अकेले कारण के रूप में न्याय नहीं किया जाना चाहिए। ऐसी कई सीमाएँ हैं जो अभी भी मौजूद हैं जिन पर विचार किया जाना चाहिए, और माइग्रेशन होने से पहले पूरी तरह से परीक्षण किया जाना चाहिए (विशेषकर क्योंकि इन-मेमोरी तालिका में माइग्रेट करना एक ऑफ़लाइन प्रक्रिया है)। लेकिन सही परिदृश्य के लिए, यह नई सुविधा प्रदर्शन को बढ़ावा दे सकती है। जब तक आप समझते हैं कि कुछ अंतर्निहित सीमाएं अभी भी मौजूद हैं, जैसे कि टिकाऊ तालिकाओं के लिए लेन-देन लॉग गति, हालांकि कम तरीके से सबसे अधिक संभावना है - चाहे तालिका डिस्क या इन-मेमोरी पर मौजूद हो।