फॉरवर्ड किए गए रिकॉर्ड्स प्रदर्शन समस्या के माध्यम से जाने और इसे हल करने से पहले, हमें SQL सर्वर तालिकाओं की संरचना की समीक्षा करने की आवश्यकता है।
तालिका संरचना अवलोकन
SQL सर्वर में, डेटा संग्रहण की मूलभूत इकाई 8-KB पृष्ठ . है . प्रत्येक पृष्ठ 96-बाइट हेडर से शुरू होता है जो उस पृष्ठ के बारे में सिस्टम जानकारी संग्रहीत करता है। फिर, तालिका पंक्तियों को शीर्षलेख के बाद क्रमिक रूप से डेटा पृष्ठों पर संग्रहीत किया जाएगा। पृष्ठ के अंत में, पंक्ति ऑफ़सेट तालिका, जिसमें प्रत्येक पंक्ति के लिए एक प्रविष्टि होती है, पृष्ठ में पंक्तियों के अनुक्रम के विपरीत संग्रहीत की जाएगी। यह पंक्ति ऑफ़सेट प्रविष्टि दर्शाती है कि उस पंक्ति की पहली बाइट पृष्ठ की शुरुआत से कितनी दूर स्थित है।
SQL सर्वर हमें उस तालिका की संरचना के आधार पर दो प्रकार की तालिकाएँ प्रदान करता है। संकुलित तालिका पूर्वनिर्धारित क्लस्टर इंडेक्स कुंजी कॉलम या कॉलम मानों के आधार पर डेटा पृष्ठों में डेटा को स्टोर और सॉर्ट करती है। इसके अलावा, क्लस्टर्ड टेबल के भीतर डेटा पेजों को क्लस्टर्ड इंडेक्स की वैल्यू के आधार पर एक लिंक्ड लिस्ट में सॉर्ट और लिंक किया जाता है। बी-पेड़ क्लस्टर इंडेक्स की संरचना क्लस्टर्ड इंडेक्स कुंजी मानों के आधार पर एक तेज़ डेटा एक्सेस विधि प्रदान करती है। यदि कोई नई पंक्ति सम्मिलित की जाती है या क्लस्टर तालिका में एक मौजूदा कुंजी मान अद्यतन किया जाता है, तो SQL सर्वर नए मान को सही तार्किक स्थिति में संग्रहीत करेगा जो सम्मिलित किए गए पंक्ति आकार को क्रमित करने के मानदंड को तोड़े बिना फिट बैठता है। अगर डाला या अपडेट किया गया मान डेटा पेज में उपलब्ध जगह से बड़ा है, तो पेज को नए मान में फ़िट करने के लिए दो पेजों में विभाजित किया जाएगा।
दूसरे प्रकार की टेबल हीप . है तालिका, जिसमें डेटा किसी भी क्रम में डेटा पृष्ठों के भीतर सॉर्ट नहीं किया जाता है और पृष्ठों को एक साथ लिंक नहीं किया जाता है, क्योंकि किसी भी सॉर्टिंग मानदंड को लागू करने के लिए उस तालिका पर कोई क्लस्टर इंडेक्स परिभाषित नहीं किया गया है। उन पृष्ठों को ट्रैक करना जो किसी ऑर्डरिंग मानदंड में क्रमबद्ध नहीं हैं या हीप टेबल में एक साथ जुड़े हुए हैं, एक आसान मिशन नहीं है। हीप तालिका में पृष्ठ आवंटन की ट्रैकिंग प्रक्रिया को सरल बनाने के लिए, SQL सर्वर अनुक्रमणिका आवंटन मानचित्र का उपयोग करता है (IAM), हीप तालिका में डेटा पृष्ठों के बीच एकमात्र तार्किक कनेक्शन, तालिका में प्रत्येक डेटा पृष्ठ या IAM तालिका में अनुक्रमणिका के लिए एक प्रविष्टि रखकर। हीप टेबल से किसी भी डेटा को पुनः प्राप्त करने के लिए, SQL सर्वर इंजन उस सीमा का पता लगाने के लिए IAM को स्कैन करता है, जो अनुरोधित डेटा को संग्रहीत करने वाले 8 पृष्ठ बनाता है।
अग्रेषित रिकॉर्ड समस्या
यदि हीप तालिका में एक नई पंक्ति डाली जाती है, तो SQL सर्वर इंजन पृष्ठ खाली स्थान को स्कैन करेगा (PFS) पृष्ठ आवंटन स्थिति और प्रत्येक डेटा पृष्ठ पर स्थान के उपयोग को ट्रैक करने के लिए ताकि सम्मिलित पंक्ति आकार में फिट होने वाले डेटा पृष्ठों में पहला उपलब्ध स्थान ढूंढा जा सके। फिर, पंक्ति को चयनित पृष्ठ में जोड़ दिया जाएगा। यदि डाला गया मान डेटा पृष्ठों में उपलब्ध स्थान से बड़ा है, तो उस तालिका में एक नया पृष्ठ जोड़ा जाएगा ताकि वह नया मान सम्मिलित कर सके।
दूसरी ओर, यदि हीप तालिका में मौजूदा डेटा को संशोधित किया गया है, उदाहरण के लिए, हमने बड़े डेटा आकार के साथ एक चर लंबाई स्ट्रिंग को अपडेट किया है, और वर्तमान स्थान नए डेटा में फिट नहीं होता है, तो डेटा को एक अलग भौतिक में ले जाया जाएगा स्थान और अग्रेषित रिकॉर्ड उस डेटा के नए स्थान को इंगित करने और ट्रैकिंग डेटा स्थान को सरल बनाने के लिए, मूल डेटा स्थान में हीप तालिका में डाला जाएगा। नए डेटा स्थान में एक पॉइंटर भी होता है जो डेटा को नए स्थान से ले जाने के मामले में इसे अद्यतन रखने के लिए और लंबी अग्रेषण सूचक श्रृंखला को रोकने या इसे हटाने के लिए अग्रेषण सूचक पर इंगित करता है। इससे अग्रेषण रिकॉर्ड भी हटाया जा सकता है।
हालांकि अग्रेषित रिकॉर्ड पुनर्निर्देशन विधि संसाधन-गहन तालिका की आवश्यकता को कम करती है और गैर-संकुल अनुक्रमणिका हर बार डेटा के स्थान को बदलने पर डेटा पते को अद्यतन करने के लिए संचालन के पुनर्निर्माण के लिए, यह डेटा को पुनः प्राप्त करने के लिए आवश्यक रीड्स की संख्या को भी दोगुना कर देती है। SQL सर्वर पहले पुराने स्थान पर जाएगा, जहां उसे अग्रेषित रिकॉर्ड मिलेगा जो इसे नए डेटा स्थान पर पुनर्निर्देशित करता है। फिर, यह अनुरोधित डेटा को पढ़ेगा, रीड ऑपरेशन को दो बार निष्पादित करेगा। इसके अलावा, फ़ॉरवर्डेड रिकॉर्ड्स की समस्या से पढ़े जाने वाले अनुक्रमिक डेटा को रैंडम डेटा रीड में बदल दिया जाता है, जिससे समय के साथ डेटा पुनर्प्राप्ति संचालन प्रदर्शन नकारात्मक रूप से प्रभावित होता है।
आइए निम्नलिखित ForwardRecordDemo ढेर बनाएं:क्रिएट टेबल टी-एसक्यूएल स्टेटमेंट का इस्तेमाल करके टेबल:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
फिर, नीचे दिए गए T-SQL कथन में INSERT का उपयोग करके, परीक्षण उद्देश्यों के लिए उस तालिका को 3K रिकॉर्ड के साथ पॉप्युलेट करें:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 अग्रेषित रिकॉर्ड समस्या की पहचान करना
तालिका प्रकार और तालिका डेटा संग्रहीत करते समय उपभोग किए गए पृष्ठों की संख्या, साथ ही सूचकांक विखंडन प्रतिशत और किसी विशिष्ट तालिका के लिए अग्रेषित रिकॉर्ड की संख्या के बारे में जानकारी sys.dm_db_index_physical_stats को क्वेरी करके देखी जा सकती है।> सिस्टम गतिशील प्रबंधन फ़ंक्शन और विस्तृत . को पास करके अग्रेषण रिकॉर्ड की संख्या वापस करने के लिए मोड। ऐसा करने के लिए, नीचे टी-एसक्यूएल स्क्रिप्ट का उपयोग करें:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
जैसा कि आप क्वेरी परिणाम से देख सकते हैं, पिछली तालिका हीप तालिका है जिसमें पृष्ठों में डेटा को सॉर्ट करने और पृष्ठों को एक दूसरे के बीच जोड़ने के लिए कोई क्लस्टर इंडेक्स नहीं बनाया गया है। तालिका में डाली गई 3K पंक्तियों को 15 . को असाइन किया गया है डेटा पृष्ठ, अग्रेषित रिकॉर्ड और शून्य विखंडन प्रतिशत के बिना, जैसा कि नीचे दिए गए परिणाम में दिखाया गया है:

जब आप किसी स्तंभ के डेटा प्रकार को VARCHAR या NVARCHAR के रूप में परिभाषित करते हैं, तो डेटा प्रकार की परिभाषा में निर्दिष्ट मान उस स्ट्रिंग के लिए अधिकतम अनुमत आकार होता है, डेटा पृष्ठों में मानों को सहेजते समय उस राशि को पूरी तरह से आरक्षित किए बिना। उदाहरण के लिए, जॉन उस तालिका में डाला गया कर्मचारी नाम उस कॉलम के लिए अधिकतम 100 बाइट्स में से केवल 8 बाइट्स आरक्षित करेगा, इस बात को ध्यान में रखते हुए कि NVARCHAR स्ट्रिंग को सहेजने से VARCHAR कॉलम के लिए आवश्यक बाइट्स दोगुनी हो जाएंगी, जैसा कि DATALENGTH कार्य परिणाम नीचे:
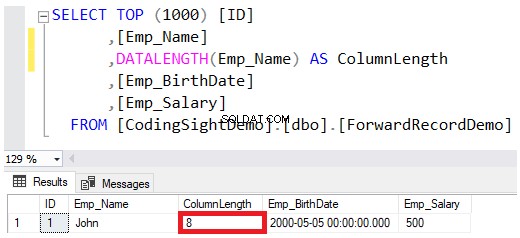
यदि आप जॉन कर्मचारी का पूरा नाम शामिल करने के लिए Emp_Name कॉलम का मान अपडेट करना चाहते हैं, तो नीचे दिए गए UPDATE स्टेटमेंट का उपयोग करें:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
DATALENGTH . का उपयोग करके अपडेट किए गए कॉलम की लंबाई की जांच करें समारोह। आप देखेंगे कि अपडेट की गई पंक्तियों में Emp_Name कॉलम की लंबाई 28 . तक बढ़ा दी गई है प्रत्येक कॉलम के लिए बाइट्स, जो लगभग 3.5 . है उस तालिका के अतिरिक्त डेटा पृष्ठ, जैसा कि नीचे परिणाम में दिखाया गया है:
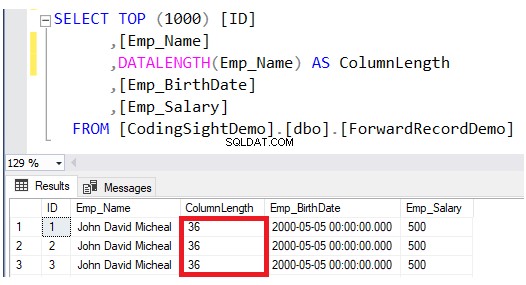
फिर, sys.dm_db_index_physical_stats सिस्टम डायनेमिक मैनेजमेंट फ़ंक्शन को क्वेरी करके अद्यतन कार्रवाई के बाद फ़ॉरवर्ड किए गए रिकॉर्ड्स की संख्या की जाँच करें। ऐसा करने के लिए, नीचे टी-एसक्यूएल स्क्रिप्ट का उपयोग करें:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
जैसा कि आप देख सकते हैं, 1K रिकॉर्ड पर Emp_Name कॉलम को बड़े स्ट्रिंग मानों के साथ अपडेट करना, बिना कोई नया रिकॉर्ड जोड़े, अतिरिक्त 5 असाइन करेगा पहले की अपेक्षा के अनुसार 3.5 पृष्ठों के बजाय उस तालिका के पृष्ठ। ऐसा 484 . जनरेट करने के कारण होगा स्थानांतरित डेटा के नए स्थानों को इंगित करने के लिए अग्रेषित रिकॉर्ड। इससे तालिका 33% हो सकती है खंडित, जैसा कि नीचे स्पष्ट रूप से दिखाया गया है:

दोबारा, यदि आप Zaid कर्मचारी का पूरा नाम शामिल करने के लिए Emp_Name कॉलम के मान को अपडेट करने का प्रबंधन करते हैं, तो नीचे दिए गए UPDATE स्टेटमेंट का उपयोग करें:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
DATALENGTH . का उपयोग करके अपडेट किए गए कॉलम की लंबाई की जांच करें समारोह। आप देखेंगे कि अपडेट की गई पंक्तियों में Emp_Name कॉलम की लंबाई 22 . तक बढ़ गई है प्रत्येक कॉलम के लिए बाइट्स, जो लगभग 2.7 . है उस तालिका में अतिरिक्त डेटा पृष्ठ जोड़े गए, जैसा कि नीचे दिए गए परिणाम में दिखाया गया है:
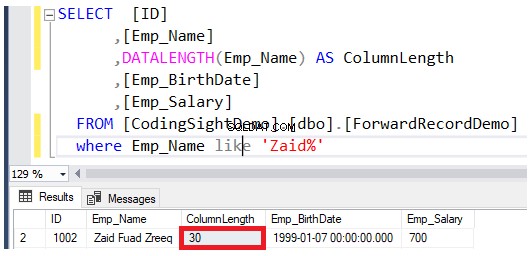
अद्यतन कार्रवाई करने के बाद अग्रेषित रिकॉर्ड की संख्या की जाँच करें। आप नीचे समान T-SQL स्क्रिप्ट का उपयोग करके sys.dm_db_index_ Physical_stats सिस्टम डायनेमिक मैनेजमेंट फ़ंक्शन को क्वेरी करके ऐसा कर सकते हैं:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
परिणाम आपको दिखाएगा कि किसी भी नई पंक्ति को सम्मिलित किए बिना बड़े स्ट्रिंग मानों के साथ अन्य 1K रिकॉर्ड पर Emp_Name कॉलम को अपडेट करने से एक और 4 असाइन किया जाएगा। अपेक्षानुसार 2.7 पृष्ठों के बजाय उस तालिका के पृष्ठ। यह अतिरिक्त 417 . उत्पन्न करने के कारण होगा स्थानांतरित किए गए डेटा के नए स्थानों को इंगित करने के लिए और उसी को बनाए रखने के लिए रिकॉर्ड अग्रेषित किए गए 33% विखंडन प्रतिशत, जैसा कि नीचे दिखाया गया है:

अग्रेषित रिकॉर्ड समस्या को ठीक करना
अग्रेषित रिकॉर्ड समस्या को ठीक करने का सबसे आसान तरीका है कि कॉलम में संग्रहीत की जाने वाली स्ट्रिंग की अधिकतम लंबाई का अनुमान लगाया जाए और इसे निश्चित लंबाई का उपयोग करके असाइन किया जाए। चर लंबाई डेटा प्रकार का उपयोग करने के बजाय उस कॉलम के लिए डेटा प्रकार। अग्रेषित रिकॉर्ड समस्या को ठीक करने का इष्टतम स्थायी तरीका संकुल अनुक्रमणिका . जोड़ना है उस टेबल को। इस तरह, तालिका पूरी तरह से एक क्लस्टर तालिका में परिवर्तित हो जाएगी, जिसे क्लस्टर्ड इंडेक्स कुंजी मानों के आधार पर क्रमबद्ध किया जाता है। यह मौजूदा डेटा के क्रम को नियंत्रित करेगा, नया डाला और अपडेट किया गया डेटा जो डेटा पेज में वर्तमान उपलब्ध स्थान में फिट नहीं होता है, जैसा कि इस आलेख की शुरूआत में पहले वर्णित है।
यदि उस तालिका में क्लस्टर्ड इंडेक्स जोड़ना विशिष्ट आवश्यकताओं के लिए एक विकल्प नहीं है, जैसे स्टेजिंग टेबल या ईटीएल टेबल, तो आप फॉरवर्ड किए गए रिकॉर्ड्स की समस्या को अस्थायी रूप से फॉरवर्ड किए गए रिकॉर्ड्स की निगरानी करके और इसे हटाने के लिए हीप टेबल को फिर से बनाकर दूर कर सकते हैं। उस हीप टेबल पर सभी गैर-क्लस्टर इंडेक्स को भी अपडेट करें। हीप तालिका के पुनर्निर्माण की कार्यक्षमता SQL Server 2008 में तालिका बदलें…पुनर्निर्माण का उपयोग करके प्रस्तुत की गई है। टी-एसक्यूएल कमांड।
डेटा पुनर्प्राप्ति प्रश्नों पर अग्रेषित रिकॉर्ड के प्रदर्शन प्रभाव को देखने के लिए, आइए हम चयन क्वेरी चलाते हैं जो Emp_Name कॉलम मानों के आधार पर खोज करती हैю हालांकि, क्वेरी निष्पादित करने से पहले, TIME और IO आंकड़े सक्षम करें:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
परिणामस्वरूप, आप देखेंगे कि 925 अनुरोधित डेटा को 84ms . के भीतर पुनर्प्राप्त करने के लिए तार्किक पठन संचालन किया जाता है जैसा कि नीचे दिखाया गया है:

सभी अग्रेषित रिकॉर्ड्स को निकालने के लिए हीप टेबल को फिर से बनाने के लिए, ALTER TABLE…REBUILD कमांड का उपयोग करें:
ALTER TABLE ForwardRecordDemo REBUILD;
वही सेलेक्ट स्टेटमेंट फिर से चलाएँ:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
TIME और IO आँकड़े आपको दिखाएंगे कि केवल 21 925 . की तुलना में तार्किक पठन संचालन फॉरवर्ड किए गए रिकॉर्ड के साथ तार्किक पठन संचालन 79ms के भीतर अनुरोधित डेटा को पुनः प्राप्त करने के लिए किया जाता है :

हीप तालिका के पुनर्निर्माण के बाद अग्रेषित रिकॉर्ड की संख्या की जांच करने के लिए, sys.dm_db_index_physical_stats सिस्टम गतिशील प्रबंधन फ़ंक्शन चलाएँ, नीचे समान T-SQL स्क्रिप्ट का उपयोग करें:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
आप देखेंगे कि केवल 21 पृष्ठ, पिछले 3 . के साथ फॉरवर्ड किए गए रिकॉर्ड्स के लिए खपत किए गए पेज, डेटा को स्टोर करने के लिए उस टेबल को असाइन किए जाते हैं, जो डेटा इंसर्ट और अपडेट ऑपरेशंस (15 + 3.5 + 2.7) के दौरान हमें मिले अनुमानित परिणाम के समान है। हीप तालिका के पुनर्निर्माण के बाद, सभी अग्रेषित रिकॉर्ड अब हटा दिए जाते हैं। परिणामस्वरूप, हमारे पास एक तालिका है जिसमें कोई विखंडन नहीं है:

अग्रेषित रिकॉर्ड समस्या एक महत्वपूर्ण प्रदर्शन समस्या है जिस पर डेटाबेस व्यवस्थापकों को योजना बनाते समय विचार करना चाहिए। ढेर तालिका रखरखाव। पिछले परिणाम हमारी परीक्षण तालिका से प्राप्त किए गए हैं जिसमें केवल 3K रिकॉर्ड हैं। आप कल्पना कर सकते हैं कि बड़ी तालिकाओं से पढ़ने पर बड़ी संख्या में अग्रेषित रिकॉर्ड पढ़ने के कारण, अग्रेषित रिकॉर्ड और I/O प्रदर्शन गिरावट से बर्बाद होने वाले पृष्ठों की संख्या!
संदर्भ:
- पृष्ठ और विस्तार वास्तुकला मार्गदर्शिका
- dm_db_index_physical_stats (ट्रांजैक्ट-एसक्यूएल)
- वैकल्पिक तालिका (लेनदेन-एसक्यूएल)
- 'फॉरवर्ड किए गए रिकॉर्ड' के बारे में जानने से प्रदर्शन संबंधी समस्याओं का पता लगाने में मुश्किलों का पता लगाने में मदद मिल सकती है