SQL सर्वर पारंपरिक रूप से कुछ अधिक सामान्य सांख्यिकीय प्रश्नों के मूल समाधान प्रदान करने से कतराता है, जैसे कि माध्यिका की गणना करना। विकिपीडिया के अनुसार, "माध्यिका को उस संख्यात्मक मान के रूप में वर्णित किया जाता है जो एक नमूने के उच्च आधे भाग, एक जनसंख्या, या एक संभाव्यता वितरण को निचले आधे से अलग करता है। संख्याओं की एक परिमित सूची का माध्यिका सभी अवलोकनों को व्यवस्थित करके पाया जा सकता है। निम्नतम मान से उच्चतम मान और बीच वाले को चुनना। यदि अवलोकनों की संख्या समान है, तो कोई एकल मध्य मान नहीं है; तब माध्यिका को आमतौर पर दो मध्य मानों के माध्य के रूप में परिभाषित किया जाता है।"
SQL सर्वर क्वेरी के संदर्भ में, आप जो महत्वपूर्ण चीज़ निकालेंगे, वह यह है कि आपको सभी मानों को "व्यवस्थित" (क्रमबद्ध) करने की आवश्यकता है। यदि कोई सहायक अनुक्रमणिका नहीं है, तो SQL सर्वर में छंटनी आम तौर पर एक बहुत महंगा ऑपरेशन है, और एक ऐसे ऑपरेशन का समर्थन करने के लिए एक अनुक्रमणिका जोड़ना जो शायद अनुरोध नहीं किया जाता है जो अक्सर सार्थक नहीं हो सकता है।
आइए देखें कि हमने SQL सर्वर के पिछले संस्करणों में इस समस्या को आम तौर पर कैसे हल किया है। आइए पहले एक बहुत ही सरल तालिका बनाएं ताकि हम यह देख सकें कि हमारा तर्क सही है और एक सटीक माध्यिका प्राप्त कर रहा है। हम निम्नलिखित दो तालिकाओं का परीक्षण कर सकते हैं, एक सम संख्या वाली पंक्तियों के साथ, और दूसरी विषम संख्या में पंक्तियों के साथ:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); केवल आकस्मिक पालन से, हम देख सकते हैं कि विषम पंक्तियों वाली तालिका का माध्यक 6 होना चाहिए, और सम तालिका के लिए यह 7.5 ((6+9)/2) होना चाहिए। तो आइए अब कुछ ऐसे समाधान देखें जिनका उपयोग वर्षों से किया जा रहा है:
एसक्यूएल सर्वर 2000
SQL Server 2000 में, हम एक बहुत ही सीमित T-SQL बोली के लिए विवश थे। मैं तुलना के लिए इन विकल्पों की जांच कर रहा हूं क्योंकि कुछ लोग अभी भी SQL Server 2000 चला रहे हैं, और अन्य ने अपग्रेड किया हो सकता है, लेकिन चूंकि उनकी औसत गणना "दिन में वापस" लिखी गई थी, इसलिए कोड आज भी इस तरह दिख सकता है।
2000_A - अधिकतम एक आधा, दूसरे का न्यूनतम
यह दृष्टिकोण पहले 50 प्रतिशत से उच्चतम मूल्य लेता है, पिछले 50 प्रतिशत से सबसे कम मूल्य लेता है, फिर उन्हें दो से विभाजित करता है। यह सम या विषम पंक्तियों के लिए काम करता है, क्योंकि सम स्थिति में, दो मान दो मध्य पंक्तियाँ हैं, और विषम स्थिति में, दो मान वास्तव में एक ही पंक्ति से हैं।
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B - #temp तालिका
यह उदाहरण पहले एक #temp तालिका बनाता है, और ऊपर दिए गए गणित के समान प्रकार का उपयोग करके, एक सन्निहित IDENTITY की सहायता से दो "मध्य" पंक्तियों को निर्धारित करता है वैल कॉलम द्वारा आदेशित कॉलम। (IDENTITY . के असाइनमेंट का क्रम मानों पर केवल MAXDOP . के कारण ही भरोसा किया जा सकता है सेटिंग।)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL सर्वर 2005, 2008, 2008 R2
SQL सर्वर 2005 ने कुछ दिलचस्प नए विंडो फ़ंक्शन पेश किए, जैसे ROW_NUMBER() , जो SQL Server 2000 की तुलना में माध्यिका जैसी सांख्यिकीय समस्याओं को हल करने में हमारी मदद कर सकता है। ये SQL Server 2005 और इसके बाद के सभी कार्यों को पूरा करते हैं:
2005_A - द्वंद्वयुद्ध पंक्ति संख्या
यह उदाहरण ROW_NUMBER() . का उपयोग करता है प्रत्येक दिशा में एक बार मूल्यों को ऊपर और नीचे चलने के लिए, फिर उस गणना के आधार पर "मध्य" एक या दो पंक्तियों को ढूंढता है। यह आसान सिंटैक्स के साथ ऊपर दिए गए पहले उदाहरण के समान है:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B - पंक्ति संख्या + गिनती
ROW_NUMBER() . की एकल गणना का उपयोग करते हुए, यह उपरोक्त के समान ही है और फिर कुल COUNT() . का उपयोग करके "मध्य" एक या दो पंक्तियों को खोजने के लिए:
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C - पंक्ति संख्या + गणना पर भिन्नता
फेलो एमवीपी इत्ज़िक बेन-गण ने मुझे यह तरीका दिखाया, जो उपरोक्त दो विधियों के समान उत्तर प्राप्त करता है, लेकिन बहुत थोड़े अलग तरीके से:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
एसक्यूएल सर्वर 2012
SQL सर्वर 2012 में, हमारे पास T-SQL में नई विंडोिंग क्षमताएं हैं जो माध्यिका जैसी सांख्यिकीय गणनाओं को अधिक सीधे व्यक्त करने की अनुमति देती हैं। मानों के एक सेट के लिए माध्यिका की गणना करने के लिए, हम PERCENTILE_CONT() का उपयोग कर सकते हैं . हम ORDER BY . में नए "पेजिंग" एक्सटेंशन का भी उपयोग कर सकते हैं क्लॉज (OFFSET / FETCH )।
2012_A - नई वितरण कार्यक्षमता
यह समाधान वितरण का उपयोग करके एक बहुत ही सरल गणना का उपयोग करता है (यदि आप पंक्तियों की एक समान संख्या के मामले में दो मध्य मानों के बीच औसत नहीं चाहते हैं)।
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B - पेजिंग ट्रिक
यह उदाहरण OFFSET / FETCH . के चतुर उपयोग को लागू करता है (और ठीक उसी के लिए नहीं जिसके लिए यह इरादा किया गया था) - हम केवल उस पंक्ति में जाते हैं जो आधी गिनती से पहले होती है, फिर अगली एक या दो पंक्तियों को इस आधार पर लेते हैं कि गिनती विषम थी या सम। इस दृष्टिकोण को इंगित करने के लिए इत्ज़िक बेन-गण का धन्यवाद।
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
लेकिन कौन बेहतर प्रदर्शन करता है?
हमने सत्यापित किया है कि उपरोक्त सभी विधियां हमारी छोटी तालिका पर अपेक्षित परिणाम उत्पन्न करती हैं, और हम जानते हैं कि SQL सर्वर 2012 संस्करण में सबसे साफ और सबसे तार्किक वाक्यविन्यास है। लेकिन आपको अपने व्यस्त उत्पादन परिवेश में किसका उपयोग करना चाहिए? हम सिस्टम मेटाडेटा से एक बहुत बड़ी तालिका बना सकते हैं, यह सुनिश्चित करते हुए कि हमारे पास बहुत सारे डुप्लिकेट मान हैं। यह स्क्रिप्ट 10,000,000 गैर-अद्वितीय पूर्णांकों के साथ एक तालिका तैयार करेगी:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
मेरे सिस्टम पर इस तालिका के लिए माध्यिका 146,099,561 होनी चाहिए। मैं निम्नलिखित क्वेरी का उपयोग करके 10,000,000 पंक्तियों की मैन्युअल स्पॉट जांच के बिना बहुत जल्दी इसकी गणना कर सकता हूं:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); परिणाम:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
तो अब हम प्रत्येक विधि के लिए एक संग्रहित प्रक्रिया बना सकते हैं, सत्यापित कर सकते हैं कि प्रत्येक सही आउटपुट उत्पन्न करता है, और फिर अवधि, सीपीयू और पढ़ने जैसे प्रदर्शन मीट्रिक को मापता है। हम इन सभी चरणों को मौजूदा तालिका के साथ निष्पादित करेंगे, और उस तालिका की एक प्रति के साथ भी करेंगे जो क्लस्टर्ड इंडेक्स से लाभ नहीं उठाती है (हम इसे छोड़ देंगे और तालिका को एक हीप के रूप में फिर से बनाएंगे)।
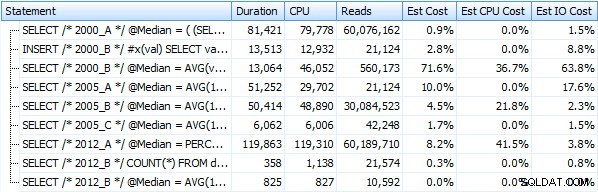
मैंने उपरोक्त क्वेरी विधियों को लागू करने वाली सात प्रक्रियाएं बनाई हैं। संक्षिप्तता के लिए मैं उन्हें यहां सूचीबद्ध नहीं करूंगा, लेकिन प्रत्येक का नाम dbo.Median_<version> है , जैसे dbo.Median_2000_A , dbo.Median_2000_B , आदि ऊपर वर्णित दृष्टिकोणों के अनुरूप। यदि हम इन सात प्रक्रियाओं को मुफ्त SQL संतरी प्लान एक्सप्लोरर का उपयोग करके चलाते हैं, तो यहां हम अवधि, सीपीयू और रीडिंग के संदर्भ में देखते हैं (ध्यान दें कि हम निष्पादन के बीच DBCC FREEPROCCACHE और DBCC DROPCLEANBUFFERS चलाते हैं):
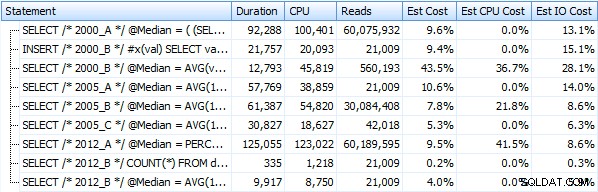
और अगर हम इसके बजाय एक ढेर के खिलाफ काम करते हैं तो ये मेट्रिक्स बहुत ज्यादा नहीं बदलते हैं। सबसे बड़ा प्रतिशत परिवर्तन वह तरीका था जो अभी भी सबसे तेज़ था:OFFSET / FETCH का उपयोग करके पेजिंग ट्रिक:
यहाँ परिणामों का एक चित्रमय प्रतिनिधित्व है। इसे और स्पष्ट करने के लिए, मैंने लाल रंग में सबसे धीमे प्रदर्शन करने वाले और हरे रंग में सबसे तेज़ दृष्टिकोण को हाइलाइट किया।
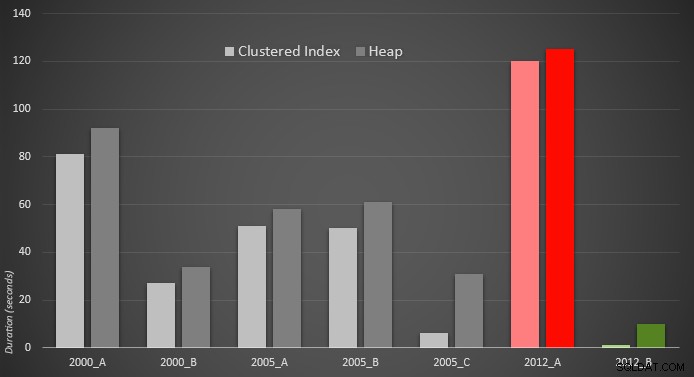
मुझे यह देखकर आश्चर्य हुआ कि, दोनों ही मामलों में, PERCENTILE_CONT() - जिसे इस प्रकार की गणना के लिए डिज़ाइन किया गया था - वास्तव में पहले के अन्य सभी समाधानों से भी बदतर है। मुझे लगता है कि यह सिर्फ यह दिखाने के लिए जाता है कि कभी-कभी नए सिंटैक्स हमारे कोडिंग को आसान बना सकते हैं, यह हमेशा गारंटी नहीं देता कि प्रदर्शन में सुधार होगा। OFFSET / FETCH . देखकर मैं भी हैरान रह गया उन परिदृश्यों में इतने उपयोगी साबित होते हैं जो आमतौर पर अपने उद्देश्य के अनुरूप नहीं लगते - पेजिनेशन।
किसी भी मामले में, मुझे आशा है कि मैंने प्रदर्शित किया है कि आपको SQL सर्वर के आपके संस्करण के आधार पर किस दृष्टिकोण का उपयोग करना चाहिए (और यह कि विकल्प समान होना चाहिए कि आपके पास गणना के लिए एक सहायक सूचकांक है या नहीं)।