जब आप एक नया डेटाबेस बनाते हैं तो क्या आप कुछ सोचते हैं? मुझे लगता है कि आप में से अधिकांश लोग नहीं कहेंगे, क्योंकि हम सभी डिफ़ॉल्ट पैरामीटर का उपयोग करते हैं, हालांकि वे इष्टतम होने से बहुत दूर हैं। हालांकि, डिस्क सेटिंग्स का एक गुच्छा है, और वे वास्तव में सिस्टम विश्वसनीयता और प्रदर्शन को बढ़ाने में मदद करते हैं।
हम डेटा विश्वसनीयता के लिए एनटीएफएस फाइल सिस्टम के महत्व के बारे में बात नहीं करेंगे, हालांकि यह फाइल सिस्टम एमएस एसक्यूएल सर्वर को सबसे प्रभावी तरीके से डिस्क का उपयोग करने की अनुमति देता है।
यदि आपके पास संसाधनों की कमी है और कुछ धीमी गति से काम करना शुरू कर देता है, तो पहली बात जो दिमाग में आती है वह है अपग्रेड करना। लेकिन हर मामले में उन्नयन की आवश्यकता नहीं है। आप ट्यूनिंग से दूर हो सकते हैं, हालांकि यह तब नहीं किया जाना चाहिए जब सर्वर धीमी गति से चलने लगे, लेकिन डिजाइन और स्थापना के चरण में।
अनुकूलन एक जटिल प्रक्रिया है और अक्सर यह न केवल एक निश्चित कार्यक्रम (हमारे मामले में, एक निश्चित डेटाबेस से) बल्कि ओएस और हार्डवेयर से भी संबंधित होता है। हालांकि हम ज्यादातर डेटाबेस के बारे में बात करेंगे, हम बाहरी चीजों को नजरअंदाज नहीं कर सकते हैं।
डेटा आर्किटेक्चर
SQL सर्वर 8 KB प्रत्येक ब्लॉक द्वारा डेटा संग्रहीत, पढ़ता और लिखता है। इन ब्लॉकों को पेज कहा जाता है। एक डेटाबेस 128 पेज प्रति मेगाबाइट (1 मेगाबाइट या 1048576 बाइट्स 8 किलोबाइट या 8192 बाइट्स से विभाजित) स्टोर कर सकता है। सभी पृष्ठ एक हद तक संग्रहीत हैं। एक हद पिछले 8 अनुक्रमिक पृष्ठ या 64 केबी है। इस प्रकार, 1 मेगाबाइट 16 विस्तार को संग्रहीत करता है।
पृष्ठ और विस्तार SQL सर्वर भौतिक डेटाबेस संरचना का आधार हैं। एमएस एसक्यूएल सर्वर विभिन्न पेज प्रकारों का उपयोग करता है, उनमें से कुछ आवंटित स्थान को ट्रैक करते हैं, कुछ में उपयोगकर्ता डेटा और इंडेक्स होते हैं। आवंटित स्थान को ट्रैक करने वाले पृष्ठों में सघन रूप से संकुचित डेटा होता है। यह एमएस एसक्यूएल सर्वर को आसानी से पढ़ने के लिए उन्हें प्रभावी ढंग से मेमोरी में स्टोर करने की अनुमति देता है।
SQL सर्वर दो प्रकार के विस्तार का उपयोग करता है:
- विस्तार जो पृष्ठों को दो से कई वस्तुओं में संग्रहीत करते हैं, मिश्रित विस्तार कहलाते हैं। प्रत्येक तालिका मिश्रित सीमा के रूप में शुरू होती है। आप मुख्य रूप से उन पृष्ठों के लिए मिश्रित सीमा का उपयोग करते हैं जो स्थान संग्रहित करते हैं और जिनमें छोटी वस्तुएं होती हैं।
- विस्तार जिनमें सभी 8 पृष्ठ एक वस्तु के लिए आवंटित किए गए हैं, एकसमान विस्तार कहलाते हैं। उनका उपयोग तब किया जाता है जब किसी तालिका या अनुक्रमणिका को 64 KB से अधिक की आवश्यकता होती है।
प्रत्येक फ़ाइल के लिए पहली सीमा एक समान होती है और इसमें फ़ाइल हेडर के पृष्ठ होते हैं, अगले विस्तार में प्रत्येक में 3 आवंटित पृष्ठ होते हैं। जब आप एक मूल डेटा फ़ाइल बनाते हैं और अपने आंतरिक कार्यों के लिए इन पृष्ठों का उपयोग करते हैं, तो सर्वर इन मिश्रित विस्तारों को आवंटित करता है। फ़ाइल हेडर पेज में फ़ाइल विशेषताएँ होती हैं, जैसे फ़ाइल में संग्रहीत डेटाबेस का नाम, फ़ाइल समूह, न्यूनतम आकार, वृद्धि आकार। यह प्रत्येक फ़ाइल का पहला पृष्ठ है (पृष्ठ 0)।
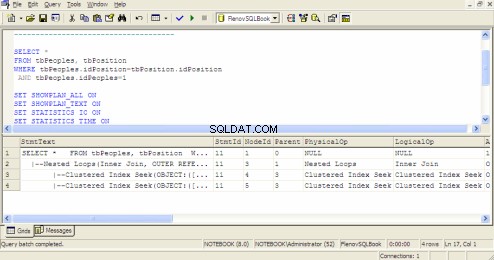
SQL क्वेरी विश्लेषक में क्वेरी निष्पादन योजना
पृष्ठ खाली स्थान (PFS ) एक आवंटित पृष्ठ में जिसमें फ़ाइल में उपलब्ध खाली स्थान के बारे में जानकारी है। यह जानकारी पृष्ठ 1 पर संग्रहीत है। ऐसा प्रत्येक पृष्ठ 8000 सन्निहित पृष्ठों तक विस्तारित हो सकता है, जो लगभग 64 एमबी डेटा है।
लेन-देन लॉग सिस्टम त्रुटि के क्षण में डेटाबेस को पुनर्स्थापित करने और डेटा अखंडता सुनिश्चित करने के लिए सर्वर पर होने वाले परिवर्तनों के बारे में सभी जानकारी एकत्र करता है।
ध्यान दें कि सभी संख्याएँ 8 या 16 के गुणज हैं। ऐसा इसलिए है क्योंकि हार्ड डिस्क नियंत्रक इस आकार के डेटा को अधिक आसानी से पढ़ता है। डेटा को डिस्क से पृष्ठों द्वारा पढ़ा जाता है, यानी 8 किलोबाइट, जो कि एक इष्टतम मूल्य है।
पेज सुरक्षा
MS SQL Server 2005 की तरह, डेटाबेस सर्वर में एक नया विकल्प है - पृष्ठ-स्तरीय डेटा नियंत्रण। अगर AGE_VERIFY_CHECKSUM पैरामीटर सक्षम है (यह डिफ़ॉल्ट रूप से सक्षम है), सर्वर पृष्ठों के चेकसम को नियंत्रित करेगा। यदि हम इस पैरामीटर के लिए मैनुअल में देखते हैं, तो हम देखेंगे कि चेकसम इनपुट/आउटपुट त्रुटियों को ट्रैक करने की अनुमति देता है जिसे ओएस ट्रैक करने में असमर्थ है। वे किस प्रकार की त्रुटियां हैं? ऐसा लगता है कि वे डेटाबेस सर्वर के आंतरिक मुद्दे हैं।
डेटा अखंडता जांच कभी खराब नहीं होती है, इसलिए इसे सक्षम करना बेहतर है। इसके लिए हमें निम्न कमांड निष्पादित करने की आवश्यकता है:
ALTER DATABASE имя базы SET PAGE_VERIFY
यदि पृष्ठ पर कोई त्रुटि है, तो सर्वर हमें इसके बारे में सूचित करेगा। लेकिन हम इसे जल्दी कैसे ठीक कर सकते हैं? इसके लिए पृष्ठ स्तर पर डेटा को पुनर्स्थापित करने का विकल्प है।
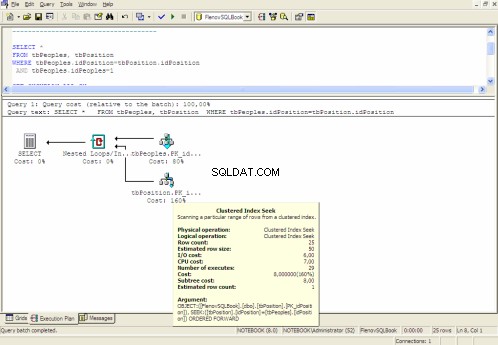
ग्राफिकल निष्पादन योजना
फाइल ग्रोथ
जब हम एक डेटाबेस बनाते हैं, तो हमें प्रारंभिक आकार और वृद्धि विधि का चयन करने के लिए कहा जाता है। जब हमारे पास वर्तमान स्थान की कमी होती है, तो सर्वर इसे प्रीसेट इंक्रीमेंट विधि के अनुरूप बढ़ा देता है।
फ़ाइलों के लिए तीन वृद्धि विधियाँ हैं:
- मेगाबाइट में वृद्धि।
- प्रतिशत की वृद्धि।
- मैन्युअल विकास.
पहली दो विधियां स्वचालित रूप से निष्पादित की जाती हैं, लेकिन उन्हें केवल परीक्षण डेटाबेस के लिए अनुशंसित किया जाता है क्योंकि व्यवस्थापक के पास फ़ाइल आकार पर नियंत्रण नहीं होता है।
यदि किसी फ़ाइल को मेगाबाइट की एक निश्चित मात्रा से बढ़ाया जाता है, तो किसी बिंदु पर, डेटा प्रविष्टि की गति बढ़ सकती है और फ़ाइल की वृद्धि बहुत अधिक हो सकती है, और यह अतिरिक्त लागत है। प्रतिशत में फ़ाइल वृद्धि भी लाभहीन है। 10% फ़ाइल वृद्धि का उपयोग करने की अनुशंसा की जाती है और यह छोटे और मध्यम डेटाबेस के लिए ठीक है। लेकिन जब यह 1000 गीगाबाइट तक पहुंच जाता है, तो इसे प्रत्येक वृद्धि पर 100 गीगाबाइट की आवश्यकता होगी। इससे डिस्क स्थान की व्यर्थ बर्बादी होगी।
फ़ाइलों और लेन-देन लॉग के आकार में परिवर्तन को हमेशा नियंत्रित करें। यह आपको सबसे प्रभावी तरीके से डिस्क संसाधनों का उपयोग करने की अनुमति देगा।
MS SQL सर्वर डेटाबेस गुण
डेटा संपीड़न
हार्ड ड्राइव कंप्यूटर का एक समझदार स्थान बना हुआ है। प्रोसेसर का प्रदर्शन तेजी से बढ़ता है, जबकि हार्ड डिस्क कुछ नया पेश नहीं कर सकती है। इनपुट/आउटपुट संचालन की संख्या को बचाने और हार्ड डिस्क पर संग्रहीत डेटा को कम करने के लिए, आप संपीड़न के साथ डिस्क का उपयोग कर सकते हैं। केवल ऐसी डिस्क केवल-पढ़ने के लिए फ़ाइल समूहों को संग्रहीत करने के लिए अच्छी हैं। शायद, ऐसा इसलिए है क्योंकि लेखन के लिए संपीड़न की आवश्यकता होती है, और इसके लिए अतिरिक्त प्रोसेसर लागत की आवश्यकता होती है।
डेटा संपीड़न और केवल-पढ़ने की स्थिति अभिलेखीय डेटा के लिए अच्छी है। उदाहरण के लिए, पिछले वर्षों के लेखांकन डेटा को लिखने के लिए आवश्यक नहीं है और यह बहुत अधिक स्थान ले सकता है। डिस्क के अभिलेखीय खंड पर डेटा रखने से, आप बहुत जगह बचाएंगे।
विश्वसनीयता के लिए डिस्क
निम्नलिखित विधि एक ही समय में विश्वसनीयता और प्रदर्शन बढ़ाने की अनुमति देती है, और फिर से, यह हार्ड ड्राइव से संबंधित है। खैर, वहाँ यह है, यांत्रिकी न केवल सबसे धीमी है, बल्कि सबसे अविश्वसनीय भी है। जहां तक विश्वसनीयता का सवाल है, मैंने आंकड़े एकत्र नहीं किए, लेकिन घर और काम दोनों जगहों पर, मैं ज्यादातर हार्ड ड्राइव से निपटता हूं।
तो, प्रदर्शन और विश्वसनीयता बढ़ाने के लिए, आप बस एक के बजाय दो या अधिक हार्ड ड्राइव का उपयोग कर सकते हैं। ये और भी बेहतर होगा अगर इन्हें अलग-अलग कंट्रोलर्स से जोड़ा जाए. आप डेटाबेस को एक डिस्क पर और लेन-देन लॉग को दूसरी डिस्क पर स्टोर कर सकते हैं। अगर कोई तीसरी डिस्क है, तो वह सिस्टम को स्टोर कर सकती है।
अलग-अलग डिस्क पर डेटा और लॉग स्टोर करना आपको विश्वसनीयता बढ़ाने की अनुमति देता है। मान लीजिए कि आपके पास एक डिस्क पर सब कुछ है और यह नीचे चला जाता है। क्या करें? आप एक ऐसी कंपनी तक पहुँच सकते हैं जो सब कुछ ठीक करने की कोशिश करेगी या अपने दम पर ऐसा करने की कोशिश करेगी, लेकिन ठीक होने की संभावना 100% से बहुत दूर है। इसके अलावा, सर्वर को वापस काम पर लौटने में काफी समय लग सकता है। फास्ट रिकवरी केवल अंतिम बैकअप कॉपी के क्षण तक ही की जा सकती है। बाकी संदिग्ध है।
और अब, मान लीजिए कि आपके पास अलग-अलग डिस्क पर डेटा और लेन-देन लॉग है। यदि लॉग वाली डिस्क बंद हो जाती है, तो डेटा वहीं रहेगा। केवल एक चीज यह है कि आप नया डेटा नहीं जोड़ सकते हैं, लेकिन यदि आप एक नया लॉग बनाते हैं, तो आप काम करना जारी रख सकते हैं।
यदि डेटा वाली डिस्क बंद हो जाती है, तब भी हम छोटी से छोटी डेटा हानि को रोकने के लिए लेन-देन लॉग आरक्षित कर सकते हैं। उसके बाद, हम डेटा को पूर्ण बैकअप से पुनर्प्राप्त करते हैं (यह हमेशा पहले से किया जाना चाहिए, एक अच्छा व्यवस्थापक दिन में कम से कम एक बार ऐसा करता है) और लॉग की बैकअप प्रति से परिवर्तन जोड़ें।
प्रदर्शन के लिए डिस्क
यदि डेटा और लॉग अलग-अलग डिस्क पर स्थित हैं, तो इसका मतलब न केवल सुरक्षा है, बल्कि प्रदर्शन वृद्धि भी है। बात यह है कि डेटाबेस सर्वर एक साथ लॉग और डेटा फ़ाइल में डेटा लिख सकता है।
हम आगे बढ़ सकते हैं और एक हार्ड ड्राइव को ट्रांजेक्शन लॉग में और कई हार्ड ड्राइव को डेटा आवंटित कर सकते हैं। सर्वर डेटा के साथ अधिक बार काम करता है, इसलिए इसके लिए कई स्टोरेज की आवश्यकता होती है जिसके साथ आप एक ही समय में काम कर सकते हैं। और अगर ये भंडारण विभिन्न नियंत्रकों से जुड़े हैं, तो एक साथ काम करने की गारंटी है।
RAID . का उपयोग करना सबसे तेज़ और सबसे विश्वसनीय संस्करण है . हालांकि, हर RAID . नहीं एक ही समय में विश्वसनीय और तेज़ है। फ़ाइल समूहों के लिए, RAID10 . चुनने की अनुशंसा की जाती है , चूंकि इसमें अच्छी तरह से संतुलित विशेषताएं हैं, लेकिन डेटाबेस डेटा के आधार पर, आप दूसरा संस्करण चुन सकते हैं।
आप किसी सॉफ़्टवेयर या हार्डवेयर समाधान का उपयोग RAID . के रूप में कर सकते हैं . एक सॉफ्टवेयर समाधान सस्ता है, लेकिन यह सीपीयू के अतिरिक्त संसाधन लेता है। और एक प्रोसेसर के पास अतिरिक्त संसाधन नहीं होते हैं। इसलिए हार्डवेयर समाधानों का उपयोग करना बेहतर है जहां एक समर्पित चिप RAID . के लिए जिम्मेदार है ।
सूचकांक
सभी जानते हैं कि इंडेक्स डेटा सर्च स्पीड को बढ़ाने में मदद करते हैं। हम में से अधिकांश लोग समझते हैं कि इंडेक्स डेटा इंसर्ट और अपडेट को नकारात्मक रूप से प्रभावित करते हैं, इसलिए आपके पास जितने अधिक इंडेक्स होंगे, सर्वर के लिए उन्हें बनाए रखना उतना ही कठिन होगा। उस पर, बहुत से लोग यह भी नहीं सोचते कि अनुक्रमणिका को रखरखाव की आवश्यकता होती है। इंडेक्स डेटा वाले डेटाबेस पेज ओवरफ्लो हो सकते हैं और अंततः असंतुलित हो सकते हैं।
हां, हम विभिन्न मापदंडों को नजरअंदाज कर सकते हैं और महीने में एक बार इंडेक्स को फिर से बना सकते हैं, जो कि रखरखाव के समान है। SQL सर्वर में दो पैरामीटर शामिल हैं जो अनुक्रमणिका को उनके निर्माण के आधे घंटे में पुराने होने से रोकते हैं:FILLFACTOR और PAD_INDEX ।
आप क्लस्टर्ड या गैर-क्लस्टर इंडेक्स वाले इन्सर्ट और अपडेट ऑपरेशंस के प्रदर्शन को ऑप्टिमाइज़ करने के लिए FILLFACTOR विकल्प का उपयोग कर सकते हैं। अनुक्रमणिका डेटा को कई डेटा पृष्ठों में संग्रहीत किया जा सकता है। जैसा कि मैंने ऊपर बताया, प्रत्येक पृष्ठ में 8 केबी होते हैं। जब कोई अनुक्रमणिका पृष्ठ भर जाता है, तो सर्वर एक नया पृष्ठ बनाता है और डेटा सम्मिलित करने के लिए पृष्ठ को दो भागों में विभाजित करता है।
सर्वर को पृष्ठ विभाजन और एक नया पृष्ठ बनाने के लिए समय की आवश्यकता होती है। पेज डिवीजन को ऑप्टिमाइज़ करने के लिए, फिलफैक्टर . का उपयोग करें सूचकांक पृष्ठ के सभी पत्तों पर खाली स्थान का प्रतिशत निर्धारित करने का विकल्प। लीफ-लेवल पेजों में जितना बड़ा डिस्क स्थान होगा, उतनी ही कम बार आपको इंडेक्स पेजों को विभाजित करना होगा। उस समय, इंडेक्स ट्री बहुत बड़ा होगा और इसे बायपास करने में अतिरिक्त समय लगेगा।
PAD_INDEX विकल्प गैर-पत्ती पृष्ठों के भरने के प्रतिशत को इंगित करता है। आप PAD_INDEX . का उपयोग कर सकते हैं केवल तभी जब FILLFACTOR PAD_INDEX . के प्रतिशत मान के बाद से विकल्प निर्दिष्ट किया गया है FILLFACTOR . में निर्दिष्ट प्रतिशत पर निर्भर करता है ।
आंकड़े
सांख्यिकी सर्वर को अनुक्रमणिका उपयोग और पूर्ण तालिका स्कैनिंग के बीच सही निर्णय लेने की अनुमति देती है। मान लीजिए आपके पास एक फाउंड्री शॉप के कर्मचारियों की सूची है। ऐसी सूची लगभग 90% पुरुषों की बनेगी।
अब, मान लीजिए हमें सभी महिलाओं को खोजने की जरूरत है। चूंकि उनमें से कई नहीं हैं, इसलिए सबसे प्रभावी विकल्प सूचकांक का उपयोग करना होगा। लेकिन अगर हमें सभी पुरुषों को खोजने की जरूरत है, तो सूचकांक की दक्षता धीमी हो जाती है। चयनित रिकॉर्ड्स की संख्या बहुत बड़ी है और उनमें से प्रत्येक के लिए इंडेक्स ट्री को बायपास करना एक ओवरहेड होगा। संपूर्ण तालिका को स्कैन करना बहुत आसान है - निष्पादन बहुत तेज़ होगा क्योंकि सर्वर को सभी स्तरों के एकाधिक पढ़ने की आवश्यकता के बिना अनुक्रमणिका के सभी निम्न-स्तर के पत्तों को एक बार पढ़ने की आवश्यकता होगी।
SQL सर्वर सभी फ़ील्ड मानों को पढ़कर या समान रूप से वितरित और क्रमबद्ध मान सूची के निर्माण के लिए एक टेम्पलेट के साथ आँकड़े एकत्र करता है। SQL सर्वर गतिशील रूप से उन पंक्तियों के प्रतिशत का पता लगाता है जिन्हें तालिका में पंक्तियों की संख्या के आधार पर परीक्षण किया जाना चाहिए। आंकड़े एकत्रित करते समय, क्वेरी अनुकूलक या तो एक पूर्ण स्कैन या पंक्ति टेम्पलेट निष्पादित करेगा।
आंकड़ों को काम करने के लिए, इसे बनाया जाना चाहिए। बड़े पैमाने पर डेटा अपडेट के मामले में, आंकड़ों में गलत डेटा हो सकता है, और सर्वर गलत निर्णय लेगा। लेकिन सब कुछ ठीक किया जा सकता है, - आपको आंकड़ों पर नजर रखने की जरूरत है। अधिक विस्तृत जानकारी के लिए, Transact-SQL या MS SQL सर्वर पर पुस्तकें देखें।
सारांश
डिफ़ॉल्ट सेटिंग्स हार्डवेयर की सभी क्षमता का उपयोग करने की अनुमति नहीं देती हैं और सभी प्रकार के सर्वरों के साथ काम करती हैं। सेटिंग्स की जिम्मेदारी प्रशासकों की होती है। तथ्य यह है कि Microsoft उत्पादों में सरल इंस्टॉलेशन प्रोग्राम, ग्राफिकल एडमिनिस्ट्रेशन यूटिलिटीज और ऑफ़लाइन काम करने की क्षमता का मतलब यह नहीं है कि यह एक इष्टतम संस्करण है।
हम ऐसे डेटाबेस ट्यूनिंग विकल्पों को हार्डवेयर त्वरण के रूप में नहीं मानते हैं। यदि सभी ट्यूनिंग विकल्प समाप्त हो गए हैं, तो अपग्रेड के बारे में सोचना बेहतर है, क्योंकि हार्डवेयर त्वरण सिस्टम की विश्वसनीयता को नकारात्मक रूप से प्रभावित करता है।
सबसे महत्वपूर्ण बात यह है कि किसी भी डेटाबेस सर्वर अनुकूलन या किसी भी अपग्रेड से मदद नहीं मिलेगी यदि प्रश्नों को अनुकूलित नहीं किया गया है।