इंडेक्स फ़्रेग्मेंटेशन हटाने और रोकथाम लंबे समय से सामान्य डेटाबेस रखरखाव कार्यों का एक हिस्सा रहा है, न केवल SQL सर्वर में, बल्कि कई प्लेटफार्मों पर। सूचकांक विखंडन कई कारणों से प्रदर्शन को प्रभावित करता है, और अधिकांश लोग I/O के यादृच्छिक छोटे ब्लॉकों के प्रभावों के बारे में बात करते हैं जो डिस्क आधारित भंडारण के लिए भौतिक रूप से हो सकते हैं क्योंकि इससे बचा जाना चाहिए। इंडेक्स फ़्रेग्मेंटेशन के बारे में सामान्य चिंता यह है कि यह रीड-फ़ॉरवर्ड I/Os के आकार को सीमित करके स्कैन के प्रदर्शन को प्रभावित करता है। यह उन समस्याओं की सीमित समझ पर आधारित है जो इंडेक्स फ़्रेग्मेंटेशन के कारण कुछ लोगों ने इस विचार को प्रसारित करना शुरू कर दिया है कि इंडेक्स फ़्रेग्मेंटेशन सॉलिड स्टेट स्टोरेज डिवाइस (एसएसडी) के साथ कोई फर्क नहीं पड़ता है और आप आगे चलकर इंडेक्स फ़्रेग्मेंटेशन को अनदेखा कर सकते हैं।
हालांकि, कई कारणों से ऐसा नहीं है। यह लेख उन कारणों में से एक को समझाएगा और प्रदर्शित करेगा:कि सूचकांक विखंडन प्रश्नों के निष्पादन योजना विकल्प पर प्रतिकूल प्रभाव डाल सकता है। ऐसा इसलिए होता है क्योंकि इंडेक्स फ़्रेग्मेंटेशन आम तौर पर एक इंडेक्स की ओर ले जाता है जिसमें अधिक पेज होते हैं (ये अतिरिक्त पेज पेज स्प्लिट से आते हैं। ऑपरेशन, जैसा कि इस साइट पर इस पोस्ट में वर्णित है), और इसलिए उस इंडेक्स के उपयोग को SQL सर्वर के क्वेरी ऑप्टिमाइज़र द्वारा उच्च लागत माना जाता है।
आइए एक उदाहरण देखें।
पहली चीज जो हमें करने की ज़रूरत है वह है एक उपयुक्त परीक्षण डेटाबेस और डेटा सेट का उपयोग करने के लिए यह जांचने के लिए कि कैसे इंडेक्स विखंडन SQL सर्वर में क्वेरी प्लान पसंद को प्रभावित कर सकता है। निम्न स्क्रिप्ट समान डेटा वाली दो तालिकाओं के साथ एक डेटाबेस बनाएगी, एक अत्यधिक खंडित और एक न्यूनतम खंडित।
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO अनुक्रमणिका के पुनर्निर्माण के बाद, हम निम्न क्वेरी के साथ विखंडन स्तरों को देख सकते हैं:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO परिणाम:

यहां हम देख सकते हैं कि हमारा GuidHighFragmentation तालिका 99% खंडित है और GuidLowFragmentation की तुलना में 31% अधिक पृष्ठ स्थान का उपयोग करती है डेटाबेस में तालिका, उनके पास डेटा की समान 7,000,000 पंक्तियाँ होने के बावजूद। यदि हम प्रत्येक तालिका के लिए एक बुनियादी एकत्रीकरण क्वेरी करते हैं और सेंट्रीऑन प्लान एक्सप्लोरर का उपयोग करके SQL सर्वर के डिफ़ॉल्ट इंस्टॉलेशन (डिफ़ॉल्ट कॉन्फ़िगरेशन विकल्पों और मानों के साथ) पर निष्पादन योजनाओं की तुलना करते हैं:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


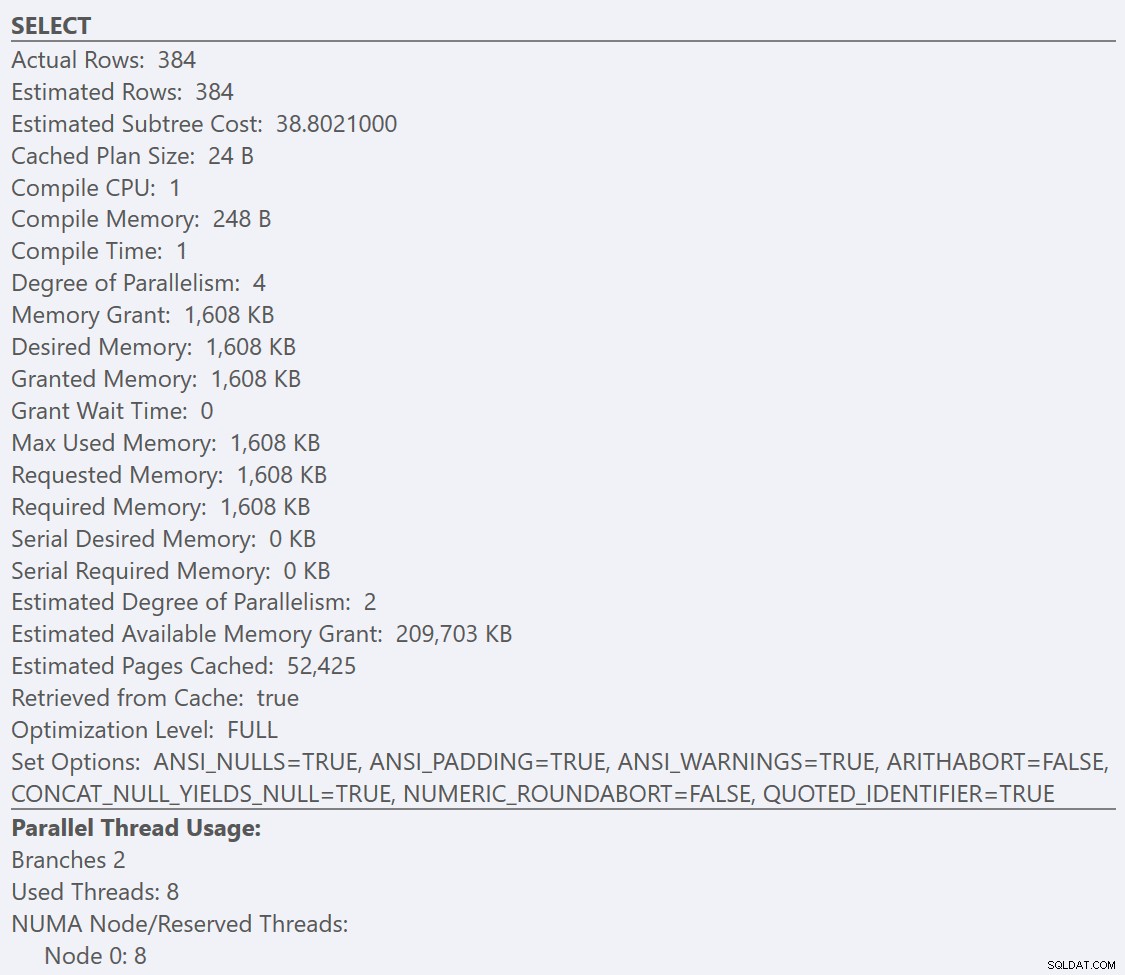

अगर हम चुनें . के टूलटिप्स को देखें तो प्रत्येक योजना के लिए ऑपरेटर, GuidLowFragmentation . के लिए योजना तालिका की क्वेरी लागत 38.80 (टूलटिप के शीर्ष से नीचे की ओर तीसरी-पंक्ति) की तुलना में 54.14 की क्वेरी लागत है जो कि GuidHighFragmentation योजना के लिए योजना के लिए है।
SQL सर्वर के लिए एक डिफ़ॉल्ट कॉन्फ़िगरेशन के तहत, ये दोनों प्रश्न समानांतर निष्पादन योजना उत्पन्न करते हैं क्योंकि अनुमानित क्वेरी लागत 'समानांतरता के लिए लागत सीमा' sp_configure विकल्प डिफ़ॉल्ट 5 से अधिक है। ऐसा इसलिए है क्योंकि क्वेरी ऑप्टिमाइज़र पहले एक सीरियल उत्पन्न करता है योजना (जिसे केवल एक थ्रेड द्वारा निष्पादित किया जा सकता है) जब एक प्रश्न के लिए योजना संकलित करते हैं। यदि उस सीरियल प्लान की अनुमानित लागत कॉन्फ़िगर की गई 'समानांतरता के लिए लागत सीमा' मान से अधिक है, तो इसके बजाय एक समानांतर योजना तैयार की जाती है और कैश की जाती है।
हालांकि, क्या होगा यदि 'समानांतरता के लिए लागत सीमा' sp_configure विकल्प 5 के डिफ़ॉल्ट पर सेट नहीं है और अधिक सेट है? छोटे प्रश्नों को समानांतर होने के अतिरिक्त ओवरहेड होने से रोकने के लिए इस विकल्प को 5 के निम्न डिफ़ॉल्ट से कहीं भी 25 से 50 (या इससे भी अधिक) तक बढ़ाने के लिए यह एक सर्वोत्तम अभ्यास (और एक सही एक) है।
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
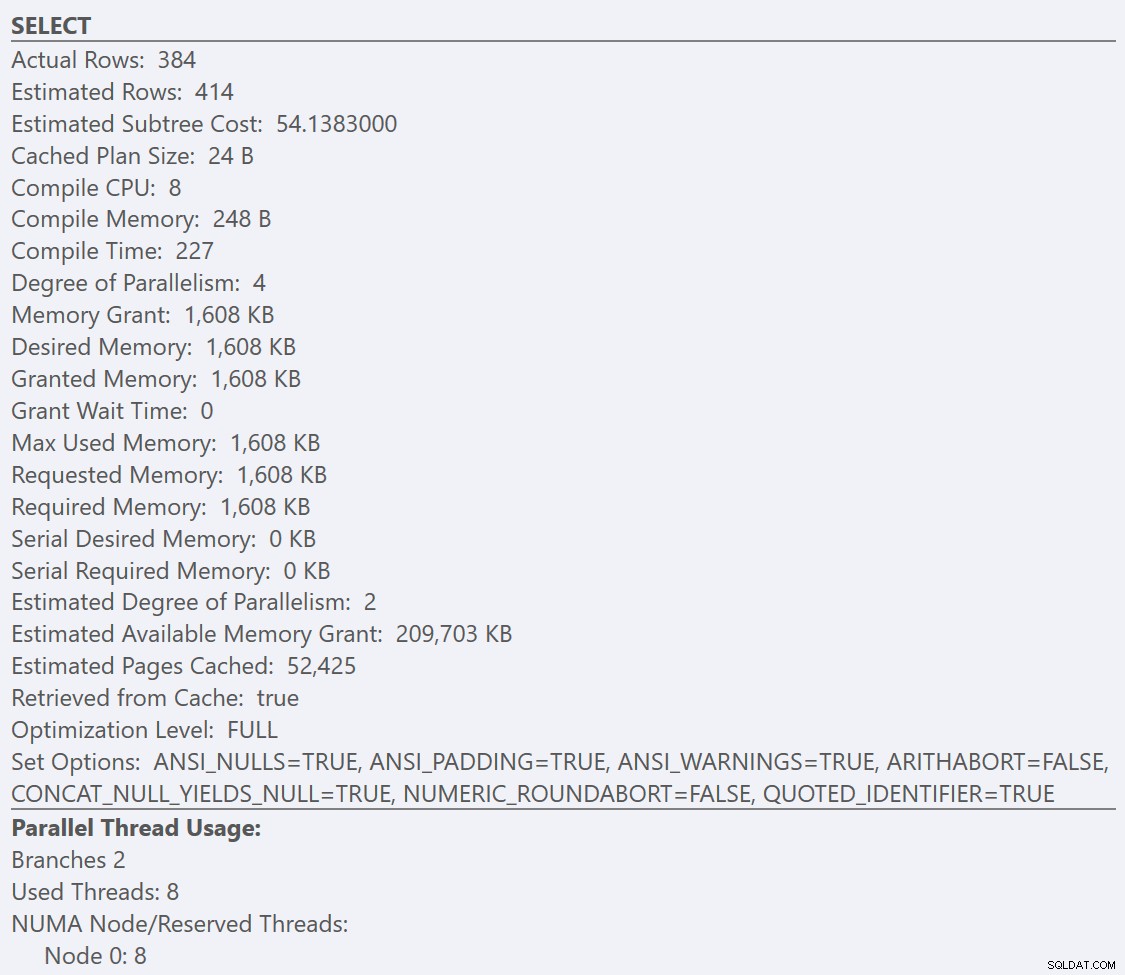
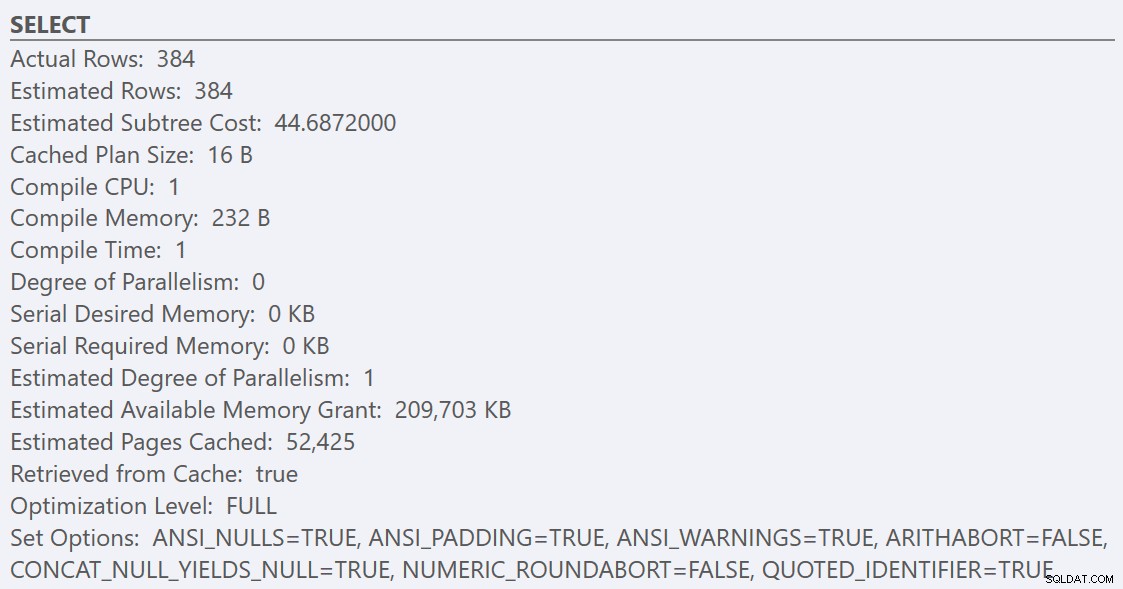
सर्वोत्तम अभ्यास दिशानिर्देशों का पालन करने और 'समानांतरता के लिए लागत सीमा' को बढ़ाकर 50 करने के बाद, क्वेरी को फिर से चलाने से GuidHighFragmentation के लिए समान निष्पादन योजना प्राप्त होती है। तालिका, लेकिन GuidLowFragmentation क्वेरी सीरियल लागत, 44.68, अब 'समानांतरता के लिए लागत सीमा' से कम है (याद रखें कि इसकी अनुमानित समानांतर लागत 38.80 थी), इसलिए हमें एक सीरियल निष्पादन योजना मिलती है:
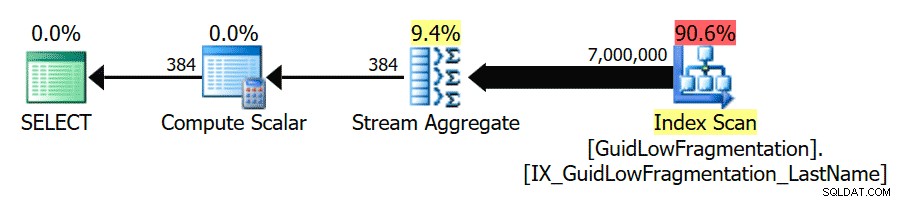
GuidHighFragmentation . में अतिरिक्त पृष्ठ स्थान क्लस्टर्ड इंडेक्स ने लागत को 'समानांतरता के लिए लागत सीमा' के लिए सर्वोत्तम अभ्यास सेटिंग से ऊपर रखा और इसके परिणामस्वरूप एक समानांतर योजना बनाई गई।
अब कल्पना करें कि यह एक ऐसी प्रणाली थी जहां आपने सर्वोत्तम अभ्यास मार्गदर्शन का पालन किया था और शुरुआत में 50 के मूल्य पर 'समानांतरता के लिए लागत सीमा' को कॉन्फ़िगर किया था। फिर बाद में आपने इंडेक्स विखंडन को पूरी तरह से अनदेखा करने की गुमराह सलाह का पालन किया।
यह एक बुनियादी क्वेरी होने के बजाय, यह अधिक जटिल है, लेकिन यदि यह आपके सिस्टम पर बहुत बार निष्पादित हो जाती है, और इंडेक्स फ़्रेग्मेंटेशन के परिणामस्वरूप, पृष्ठ गणना एक समानांतर योजना की लागत को इंगित करती है, तो यह अधिक CPU का उपयोग करेगी और परिणामस्वरूप समग्र कार्यभार प्रदर्शन को प्रभावित करता है।
आप क्या करते हैं? क्या आप 'समानांतरता के लिए लागत सीमा' बढ़ाते हैं ताकि क्वेरी एक सीरियल निष्पादन योजना बनाए रखे? क्या आप क्वेरी को OPTION(MAXDOP 1) के साथ संकेत देते हैं और इसे केवल एक सीरियल निष्पादन योजना के लिए बाध्य करते हैं?
ध्यान रखें कि इंडेक्स फ़्रेग्मेंटेशन संभवतः आपके डेटाबेस में केवल एक तालिका को प्रभावित नहीं कर रहा है, अब आप इसे पूरी तरह से अनदेखा कर रहे हैं; यह संभावना है कि कई क्लस्टर और गैर-क्लस्टर इंडेक्स खंडित हैं और पृष्ठों की आवश्यक संख्या से अधिक है, इसलिए व्यापक इंडेक्स विखंडन के परिणामस्वरूप कई I/O संचालन की लागत बढ़ रही है, जिससे संभावित रूप से कई अक्षम क्वेरी हो सकती हैं योजनाएं।
सारांश
आप इंडेक्स विखंडन को पूरी तरह से अनदेखा नहीं कर सकते क्योंकि कुछ लोग आपको विश्वास दिलाना चाहते हैं। ऐसा करने से अन्य कमियों के बीच, क्वेरी निष्पादन की संचित लागतें, क्वेरी योजना में बदलाव के साथ आपको पकड़ में आएंगी क्योंकि क्वेरी ऑप्टिमाइज़र एक लागत-आधारित अनुकूलक है और इसलिए उन खंडित अनुक्रमणिकाओं का उपयोग करना अधिक महंगा लगता है।
यहां प्रश्न और परिदृश्य स्पष्ट रूप से गढ़ा गया है, लेकिन हमने क्लाइंट सिस्टम पर वास्तविक जीवन में विखंडन के कारण निष्पादन योजना में बदलाव देखा है।
आपको यह सुनिश्चित करने की ज़रूरत है कि आप उन इंडेक्स के लिए इंडेक्स फ़्रेग्मेंटेशन को संबोधित कर रहे हैं जहां फ़्रेग्मेंटेशन वर्कलोड प्रदर्शन समस्याओं का कारण बनता है, इससे कोई फर्क नहीं पड़ता कि आप किस हार्डवेयर का उपयोग कर रहे हैं।



