ROW_NUMBER विंडो फ़ंक्शन में कई व्यावहारिक अनुप्रयोग हैं, जो केवल स्पष्ट रैंकिंग आवश्यकताओं से परे हैं। अधिकांश समय, जब आप पंक्ति संख्याओं की गणना करते हैं, तो आपको कुछ क्रम के आधार पर उनकी गणना करने की आवश्यकता होती है, और आप फ़ंक्शन के विंडो ऑर्डर क्लॉज में वांछित ऑर्डरिंग विनिर्देश प्रदान करते हैं। हालांकि, ऐसे मामले हैं जहां आपको किसी विशेष क्रम में पंक्ति संख्याओं की गणना करने की आवश्यकता नहीं है; दूसरे शब्दों में, nondeterministic क्रम के आधार पर। यह संपूर्ण क्वेरी परिणाम में, या विभाजन के भीतर हो सकता है। उदाहरणों में परिणाम पंक्तियों के लिए अद्वितीय मान निर्दिष्ट करना, डेटा को डुप्लिकेट करना और प्रति समूह किसी भी पंक्ति को वापस करना शामिल है।
ध्यान दें कि नोडेटर्मिनिस्टिक ऑर्डर के आधार पर पंक्ति संख्या असाइन करने की आवश्यकता यादृच्छिक क्रम के आधार पर उन्हें असाइन करने की आवश्यकता से भिन्न होती है। पूर्व के साथ, आपको इस बात की परवाह नहीं है कि उन्हें किस क्रम में सौंपा गया है, और क्या क्वेरी के बार-बार निष्पादन समान पंक्तियों को समान पंक्तियों को निर्दिष्ट करते रहते हैं या नहीं। उत्तरार्द्ध के साथ, आप बार-बार निष्पादन की अपेक्षा करते हैं कि कौन सी पंक्तियों को किस पंक्ति संख्या के साथ असाइन किया जाए। यह लेख गैर-नियतात्मक क्रम के साथ पंक्ति संख्याओं की गणना के लिए विभिन्न तकनीकों की खोज करता है। आशा एक ऐसी तकनीक खोजने की है जो विश्वसनीय और इष्टतम दोनों हो।
पॉल व्हाइट को निरंतर फोल्डिंग से संबंधित टिप के लिए, रनटाइम निरंतर तकनीक के लिए, और हमेशा जानकारी का एक बड़ा स्रोत होने के लिए विशेष धन्यवाद!
जब आदेश मायने रखता है
मैं उन मामलों से शुरू करूंगा जहां पंक्ति संख्या क्रम मायने रखता है।
मैं अपने उदाहरणों में T1 नामक तालिका का उपयोग करूँगा। इस तालिका को बनाने और नमूना डेटा के साथ इसे भरने के लिए निम्न कोड का उपयोग करें:
SET NOCOUNT ON; USE tempdb; DROP TABLE IF EXISTS dbo.T1; GO CREATE TABLE dbo.T1 ( id INT NOT NULL CONSTRAINT PK_T1 PRIMARY KEY, grp VARCHAR(10) NOT NULL, datacol INT NOT NULL ); INSERT INTO dbo.T1(id, grp, datacol) VALUES (11, 'A', 50), ( 3, 'B', 20), ( 5, 'A', 40), ( 7, 'B', 10), ( 2, 'A', 50);
निम्नलिखित प्रश्न पर विचार करें (हम इसे प्रश्न 1 कहेंगे):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
यहां आप कॉलम डेटाकॉल द्वारा ऑर्डर किए गए कॉलम जीआरपी द्वारा पहचाने गए प्रत्येक समूह के भीतर पंक्ति संख्या असाइन करना चाहते हैं। जब मैंने इस क्वेरी को अपने सिस्टम पर चलाया, तो मुझे निम्न आउटपुट मिला:
id grp datacol n --- ---- -------- --- 5 A 40 1 2 A 50 2 11 A 50 3 7 B 10 1 3 B 20 2
पंक्ति संख्याएं यहां आंशिक रूप से नियतात्मक और आंशिक रूप से गैर-नियतात्मक क्रम में असाइन की गई हैं। इससे मेरा तात्पर्य यह है कि आपके पास एक आश्वासन है कि उसी विभाजन के भीतर, अधिक डेटाकॉल मान वाली पंक्ति को अधिक पंक्ति संख्या मान प्राप्त होगा। हालाँकि, चूंकि डेटाकॉल जीआरपी विभाजन के भीतर अद्वितीय नहीं है, इसलिए समान जीआरपी और डेटाकॉल मानों वाली पंक्तियों के बीच पंक्ति संख्याओं के असाइनमेंट का क्रम गैर-निर्धारक है। आईडी मान 2 और 11 के साथ पंक्तियों के मामले में ऐसा ही है। दोनों में जीआरपी मान ए और डेटाकॉल मान 50 है। जब मैंने पहली बार अपने सिस्टम पर इस क्वेरी को निष्पादित किया, तो आईडी 2 वाली पंक्ति को पंक्ति संख्या 2 मिली और आईडी 11 के साथ पंक्ति को पंक्ति संख्या 3 मिली। SQL सर्वर में अभ्यास में ऐसा होने की संभावना पर कभी ध्यान न दें; अगर मैं फिर से क्वेरी चलाता हूं, सैद्धांतिक रूप से, आईडी 2 वाली पंक्ति को पंक्ति संख्या 3 के साथ असाइन किया जा सकता है और आईडी 11 वाली पंक्ति को पंक्ति संख्या 2 के साथ असाइन किया जा सकता है।
यदि आपको पूरी तरह से नियतात्मक क्रम के आधार पर पंक्ति संख्या निर्दिष्ट करने की आवश्यकता है, तो क्वेरी के निष्पादन में दोहराए जाने योग्य परिणामों की गारंटी देता है जब तक कि अंतर्निहित डेटा नहीं बदलता है, आपको विंडो विभाजन और ऑर्डरिंग क्लॉज में तत्वों के संयोजन की आवश्यकता होती है। यह हमारे मामले में एक टाईब्रेकर के रूप में विंडो ऑर्डर क्लॉज में कॉलम आईडी जोड़कर हासिल किया जा सकता है। तब ओवर क्लॉज होगा:
OVER (PARTITION BY grp ORDER BY datacol, id)
किसी भी दर पर, क्वेरी 1 जैसे कुछ सार्थक ऑर्डरिंग विनिर्देश के आधार पर पंक्ति संख्याओं की गणना करते समय, SQL सर्वर को विंडो विभाजन और ऑर्डरिंग तत्वों के संयोजन द्वारा ऑर्डर की गई पंक्तियों को संसाधित करने की आवश्यकता होती है। यह या तो किसी इंडेक्स से पहले से ऑर्डर किए गए डेटा को खींचकर या डेटा को सॉर्ट करके प्राप्त किया जा सकता है। फिलहाल क्वेरी 1 में ROW_NUMBER गणना का समर्थन करने के लिए T1 पर कोई अनुक्रमणिका नहीं है, इसलिए SQL सर्वर को डेटा सॉर्ट करने का विकल्प चुनना होगा। इसे चित्र 1 में दिखाए गए प्रश्न 1 की योजना में देखा जा सकता है।
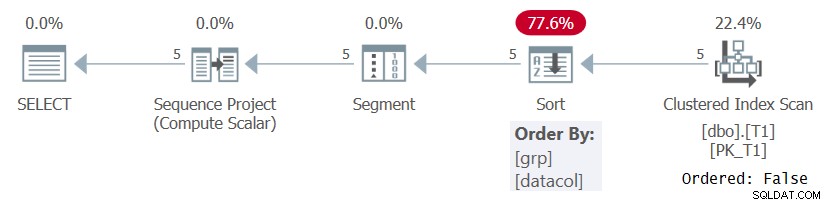 चित्र 1:एक सहायक अनुक्रमणिका के बिना प्रश्न 1 की योजना बनाएं
चित्र 1:एक सहायक अनुक्रमणिका के बिना प्रश्न 1 की योजना बनाएं
ध्यान दें कि योजना क्लस्टर्ड इंडेक्स से डेटा को ऑर्डर की गई:झूठी संपत्ति के साथ स्कैन करती है। इसका मतलब है कि स्कैन को इंडेक्स कुंजी द्वारा ऑर्डर की गई पंक्तियों को वापस करने की आवश्यकता नहीं है। ऐसा इसलिए है क्योंकि क्लस्टर्ड इंडेक्स का उपयोग यहां सिर्फ इसलिए किया जाता है क्योंकि यह क्वेरी को कवर करने के लिए होता है न कि इसके मुख्य क्रम के कारण। योजना तब एक प्रकार लागू करती है, जिसके परिणामस्वरूप अतिरिक्त लागत, एन लॉग एन स्केलिंग, और विलंबित प्रतिक्रिया समय होता है। सेगमेंट ऑपरेटर एक ध्वज उत्पन्न करता है जो दर्शाता है कि पंक्ति विभाजन में पहली है या नहीं। अंत में, सीक्वेंस प्रोजेक्ट ऑपरेटर प्रत्येक विभाजन में 1 से शुरू होने वाली पंक्ति संख्या निर्दिष्ट करता है।
यदि आप छँटाई की आवश्यकता से बचना चाहते हैं, तो आप एक प्रमुख सूची के साथ एक कवरिंग इंडेक्स तैयार कर सकते हैं जो कि विभाजन और ऑर्डरिंग तत्वों पर आधारित है, और एक सूची शामिल है जो कवरिंग तत्वों पर आधारित है। मैं इस अनुक्रमणिका को एक POC अनुक्रमणिका (विभाजन के लिए . के रूप में सोचना पसंद करता हूँ) , आदेश देना और कवर करना ) यहां POC की परिभाषा दी गई है जो हमारी क्वेरी का समर्थन करती है:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
क्वेरी 1 फिर से चलाएँ:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
इस निष्पादन की योजना चित्र 2 में दिखाई गई है।
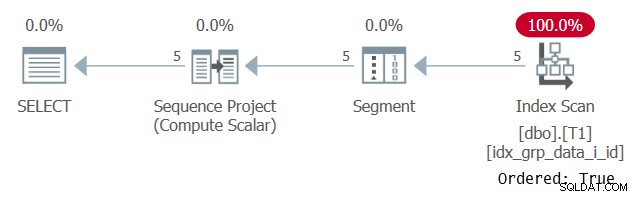 चित्र 2:POC अनुक्रमणिका के साथ प्रश्न 1 की योजना बनाएं
चित्र 2:POC अनुक्रमणिका के साथ प्रश्न 1 की योजना बनाएं
ध्यान दें कि इस बार प्लान POC इंडेक्स को ऑर्डर्ड:ट्रू प्रॉपर्टी के साथ स्कैन करता है। इसका मतलब है कि स्कैन गारंटी देता है कि पंक्तियों को अनुक्रमणिका कुंजी क्रम में वापस कर दिया जाएगा। चूंकि डेटा को इंडेक्स से प्रीऑर्डर किया जाता है जैसे विंडो फ़ंक्शन की आवश्यकता होती है, इसलिए स्पष्ट सॉर्टिंग की कोई आवश्यकता नहीं है। इस योजना का विस्तार रैखिक है और प्रतिक्रिया समय अच्छा है।
जब ऑर्डर कोई मायने नहीं रखता
चीजें थोड़ी मुश्किल हो जाती हैं जब आपको पूरी तरह से गैर-निर्धारिती क्रम के साथ पंक्ति संख्या असाइन करने की आवश्यकता होती है। ऐसे मामले में स्वाभाविक बात यह है कि विंडो ऑर्डर क्लॉज को निर्दिष्ट किए बिना ROW_NUMBER फ़ंक्शन का उपयोग करना है। सबसे पहले, आइए देखें कि SQL मानक इसकी अनुमति देता है या नहीं। विंडो फ़ंक्शंस के लिए सिंटैक्स नियमों को परिभाषित करने वाले मानक का प्रासंगिक हिस्सा यहां दिया गया है:
वाक्यविन्यास नियम…
5) WNS को <विंडो नाम या विनिर्देश> होने दें। WDX को एक विंडो संरचना डिस्क्रिप्टर होने दें जो WNS द्वारा परिभाषित विंडो का वर्णन करता है।
6) यदि
a) यदि
…
f) ROW_NUMBER() ओवर WNS <विंडो फ़ंक्शन> के बराबर है:COUNT (*) OVER (WNS1 ROWS UNBOUNDED PRECEDING)
…
ध्यान दें कि आइटम 6 में <एनटाइल फ़ंक्शन>, <लीड या लैग फ़ंक्शन>, <रैंक फ़ंक्शन प्रकार> या ROW_NUMBER फ़ंक्शन सूचीबद्ध हैं, और फिर आइटम 6a कहता है कि फ़ंक्शन के लिए
तो, आइए इसे आज़माएं, और SQL सर्वर में बिना विंडो ऑर्डरिंग के पंक्ति संख्याओं की गणना करने का प्रयास करें:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
इस प्रयास के परिणामस्वरूप निम्न त्रुटि होती है:
संदेश 4112, स्तर 15, राज्य 1, पंक्ति 53फ़ंक्शन 'ROW_NUMBER' में ORDER BY के साथ एक ओवर क्लॉज़ होना चाहिए।
वास्तव में, यदि आप ROW_NUMBER फ़ंक्शन के SQL सर्वर के दस्तावेज़ीकरण की जाँच करते हैं, तो आपको निम्न पाठ मिलेगा:
“order_by_clauseORDER BY क्लॉज उस क्रम को निर्धारित करता है जिसमें पंक्तियों को एक निर्दिष्ट विभाजन के भीतर अपना अनूठा ROW_NUMBER सौंपा जाता है। यह आवश्यक है।"
तो स्पष्ट रूप से SQL सर्वर में ROW_NUMBER फ़ंक्शन के लिए विंडो ऑर्डर क्लॉज अनिवार्य है। वैसे Oracle में भी ऐसा ही है।
मुझे कहना होगा कि मुझे यकीन नहीं है कि मैं इस आवश्यकता के पीछे के तर्क को समझता हूं। याद रखें कि आप आंशिक रूप से nondeterministic क्रम के आधार पर पंक्ति संख्याओं को परिभाषित करने की अनुमति दे रहे हैं, जैसे कि प्रश्न 1 में। तो क्यों न सभी तरह से nondeterminism की अनुमति दें? शायद कोई कारण है जिसके बारे में मैं नहीं सोच रहा हूँ। यदि आप ऐसा कोई कारण सोच सकते हैं, तो कृपया साझा करें।
किसी भी दर पर, आप यह तर्क दे सकते हैं कि यदि आपको ऑर्डर की परवाह नहीं है, यह देखते हुए कि विंडो ऑर्डर क्लॉज अनिवार्य है, आप किसी भी ऑर्डर को निर्दिष्ट कर सकते हैं। इस दृष्टिकोण के साथ समस्या यह है कि यदि आप क्वेरी की गई तालिका से कुछ कॉलम द्वारा ऑर्डर करते हैं तो इसमें एक अनावश्यक प्रदर्शन जुर्माना शामिल हो सकता है। जब कोई सहायक अनुक्रमणिका नहीं होती है, तो आप स्पष्ट छँटाई के लिए भुगतान करेंगे। जब एक सपोर्टिंग इंडेक्स मौजूद होता है, तो आप स्टोरेज इंजन को इंडेक्स ऑर्डर स्कैन स्ट्रैटेजी (इंडेक्स लिंक्ड लिस्ट के बाद) तक सीमित कर रहे होते हैं। आप इसे और अधिक लचीलेपन की अनुमति नहीं देते हैं, जैसा कि आमतौर पर तब होता है जब ऑर्डर इंडेक्स ऑर्डर स्कैन और आवंटन ऑर्डर स्कैन (IAM पेजों पर आधारित) के बीच चयन करने में कोई फर्क नहीं पड़ता।
एक विचार जो कोशिश करने लायक है, वह है विंडो ऑर्डर क्लॉज में 1 की तरह एक स्थिरांक निर्दिष्ट करना। यदि समर्थित है, तो आप आशा करते हैं कि ऑप्टिमाइज़र यह महसूस करने के लिए पर्याप्त स्मार्ट है कि सभी पंक्तियों का समान मूल्य है, इसलिए कोई वास्तविक ऑर्डरिंग प्रासंगिकता नहीं है और इसलिए किसी सॉर्ट या इंडेक्स ऑर्डर स्कैन को बाध्य करने की कोई आवश्यकता नहीं है। इस दृष्टिकोण का प्रयास करने वाला एक प्रश्न यहां दिया गया है:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
दुर्भाग्य से, SQL सर्वर इस समाधान का समर्थन नहीं करता है। यह निम्न त्रुटि उत्पन्न करता है:
Msg 5308, Level 16, State 1, Line 56विंडो वाले फंक्शन, एग्रीगेट और फंक्शन के लिए NEXT VALUE ORDER BY क्लॉज एक्सप्रेशन के रूप में पूर्णांक सूचकांकों का समर्थन नहीं करते हैं।
जाहिरा तौर पर, SQL सर्वर मानता है कि यदि आप विंडो ऑर्डर क्लॉज में एक पूर्णांक स्थिरांक का उपयोग कर रहे हैं, तो यह SELECT सूची में किसी तत्व की एक क्रमिक स्थिति का प्रतिनिधित्व करता है, जैसे कि जब आप प्रस्तुति में एक पूर्णांक निर्दिष्ट करते हैं ORDER BY क्लॉज। अगर ऐसा है, तो एक और विकल्प जो कोशिश करने लायक है, वह है एक गैर-पूर्णांक स्थिरांक निर्दिष्ट करना, जैसे:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No Order') AS n FROM dbo.T1;
यह पता चला है कि यह समाधान भी असमर्थित है। SQL सर्वर निम्न त्रुटि उत्पन्न करता है:
Msg 5309, Level 16, State 1, Line 65विंडो वाले फंक्शन, एग्रीगेट और फंक्शन के लिए NEXT VALUE ORDER BY क्लॉज एक्सप्रेशन के रूप में स्थिरांक का समर्थन नहीं करते हैं।
जाहिर है, विंडो ऑर्डर क्लॉज किसी भी प्रकार के स्थिरांक का समर्थन नहीं करता है।
अब तक हमने SQL सर्वर में ROW_NUMBER फ़ंक्शन की विंडो ऑर्डरिंग प्रासंगिकता के बारे में निम्नलिखित सीखा है:
- आदेश देना आवश्यक है।
- एक पूर्णांक स्थिरांक द्वारा आदेश नहीं दिया जा सकता क्योंकि SQL सर्वर को लगता है कि आप चयन में एक क्रमिक स्थिति निर्दिष्ट करने का प्रयास कर रहे हैं।
- किसी भी प्रकार के स्थिरांक द्वारा आदेश नहीं दिया जा सकता।
निष्कर्ष यह है कि आपको उन भावों द्वारा क्रमित करना चाहिए जो स्थिरांक नहीं हैं। जाहिर है, आप क्वेरी की गई तालिका (तालिकाओं) से कॉलम सूची द्वारा ऑर्डर कर सकते हैं। लेकिन हम एक कुशल समाधान खोजने की तलाश में हैं जहां अनुकूलक यह महसूस कर सके कि ऑर्डरिंग प्रासंगिकता नहीं है।
लगातार तह करना
अब तक का निष्कर्ष यह है कि आप ROW_NUMBER के विंडो ऑर्डर क्लॉज में स्थिरांक का उपयोग नहीं कर सकते हैं, लेकिन स्थिरांक पर आधारित अभिव्यक्तियों के बारे में क्या, जैसे कि निम्नलिखित क्वेरी में:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
हालांकि, यह प्रयास निरंतर तह के रूप में जानी जाने वाली प्रक्रिया का शिकार होता है, जिसका सामान्य रूप से प्रश्नों पर सकारात्मक प्रदर्शन प्रभाव पड़ता है। इस तकनीक के पीछे का विचार क्वेरी प्रोसेसिंग के प्रारंभिक चरण में स्थिरांक के आधार पर कुछ अभिव्यक्ति को उनके परिणाम स्थिरांक में जोड़कर क्वेरी प्रदर्शन में सुधार करना है। आप यहां विवरण पा सकते हैं कि किस प्रकार के भावों को लगातार मोड़ा जा सकता है। हमारे व्यंजक 1+0 को 1 से मोड़ा जाता है, जिसके परिणामस्वरूप वही त्रुटि होती है जो आपको स्थिरांक 1 को सीधे निर्दिष्ट करते समय मिली थी:
Msg 5308, Level 16, State 1, Line 79विंडो वाले फंक्शन, एग्रीगेट और फंक्शन के लिए NEXT VALUE ORDER BY क्लॉज एक्सप्रेशन के रूप में पूर्णांक सूचकांकों का समर्थन नहीं करते हैं।
दो वर्ण स्ट्रिंग शाब्दिकों को संयोजित करने का प्रयास करते समय आपको एक समान स्थिति का सामना करना पड़ेगा, जैसे:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No' + ' Order') AS n FROM dbo.T1;
आपको वही त्रुटि मिलती है जो आपको शाब्दिक 'नो ऑर्डर' को सीधे निर्दिष्ट करते समय मिली थी:
Msg 5309, Level 16, State 1, Line 55विंडो वाले फंक्शन, एग्रीगेट और फंक्शन के लिए NEXT VALUE ORDER BY क्लॉज एक्सप्रेशन के रूप में स्थिरांक का समर्थन नहीं करते हैं।
विचित्र दुनिया - त्रुटियां जो त्रुटियों को रोकती हैं
जीवन आश्चर्यों से भरा है…
एक चीज जो निरंतर फोल्डिंग को रोकती है वह यह है कि जब अभिव्यक्ति सामान्य रूप से त्रुटि में होती है। उदाहरण के लिए, व्यंजक 2147483646+1 को लगातार मोड़ा जा सकता है क्योंकि इसके परिणामस्वरूप एक मान्य INT-टाइप किया गया मान प्राप्त होता है। परिणामस्वरूप, निम्न क्वेरी को चलाने का प्रयास विफल हो जाता है:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 109
विंडो वाले फंक्शन, एग्रीगेट और फंक्शन के लिए NEXT VALUE ORDER BY क्लॉज एक्सप्रेशन के रूप में पूर्णांक सूचकांकों का समर्थन नहीं करते हैं।
हालाँकि, व्यंजक 2147483647+1 को लगातार मोड़ा नहीं जा सकता क्योंकि इस तरह के प्रयास के परिणामस्वरूप INT-ओवरफ़्लो त्रुटि हो सकती थी। आदेश देने पर निहितार्थ काफी दिलचस्प है। निम्न क्वेरी आज़माएं (हम इसे एक प्रश्न 2 कहेंगे):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
अजीब तरह से, यह क्वेरी सफलतापूर्वक चलती है! क्या होता है कि एक तरफ, SQL सर्वर निरंतर फोल्डिंग लागू करने में विफल रहता है, और इसलिए ऑर्डरिंग एक अभिव्यक्ति पर आधारित है जो एक स्थिर नहीं है। दूसरी ओर, ऑप्टिमाइज़र बताता है कि सभी पंक्तियों के लिए ऑर्डरिंग वैल्यू समान है, इसलिए यह ऑर्डरिंग एक्सप्रेशन को पूरी तरह से अनदेखा कर देता है। चित्र 3 में दिखाए गए अनुसार इस क्वेरी के लिए योजना की जांच करते समय इसकी पुष्टि की जाती है।
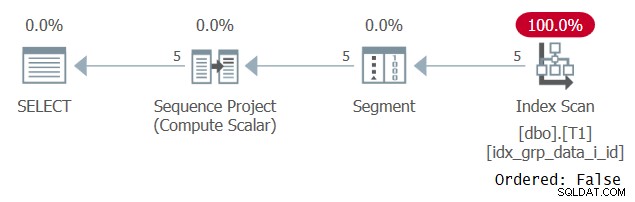 चित्र 3:प्रश्न 2 के लिए योजना
चित्र 3:प्रश्न 2 के लिए योजना
ध्यान दें कि योजना कुछ कवरिंग इंडेक्स को ऑर्डर किए गए:झूठी संपत्ति के साथ स्कैन करती है। यह वास्तव में हमारा प्रदर्शन लक्ष्य था।
इसी तरह, निम्न क्वेरी में एक सफल निरंतर फोल्डिंग प्रयास शामिल है, और इसलिए विफल रहता है:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 123
विंडो वाले फंक्शन, एग्रीगेट और फंक्शन के लिए NEXT VALUE ORDER BY क्लॉज एक्सप्रेशन के रूप में पूर्णांक सूचकांकों का समर्थन नहीं करते हैं।
निम्नलिखित क्वेरी में एक असफल निरंतर फोल्डिंग प्रयास शामिल है, और इसलिए सफल होता है, चित्र 3 में पहले दिखाई गई योजना को उत्पन्न करता है:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
निम्नलिखित क्वेरी में एक सफल निरंतर फोल्डिंग प्रयास शामिल है (VARCHAR शाब्दिक '1' परोक्ष रूप से INT 1 में परिवर्तित हो जाता है, और फिर 1 + 1 को 2 में जोड़ दिया जाता है), और इसलिए विफल हो जाता है:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'1') AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 134
विंडो वाले फंक्शन, एग्रीगेट और फंक्शन के लिए NEXT VALUE ORDER BY क्लॉज एक्सप्रेशन के रूप में पूर्णांक सूचकांकों का समर्थन नहीं करते हैं।
निम्नलिखित क्वेरी में एक असफल निरंतर फोल्डिंग प्रयास शामिल है ('ए' को आईएनटी में परिवर्तित नहीं किया जा सकता है), और इसलिए सफल होता है, चित्र 3 में पहले दिखाए गए योजना को उत्पन्न करता है:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'A') AS n FROM dbo.T1;
सच कहूं, भले ही यह विचित्र तकनीक हमारे मूल प्रदर्शन लक्ष्य को प्राप्त कर लेती है, मैं यह नहीं कह सकता कि मैं इसे सुरक्षित मानता हूं और इसलिए मैं इस पर भरोसा करने में सहज नहीं हूं।
कार्यों के आधार पर रनटाइम स्थिरांक
नॉनडेटर्मिनिस्टिक क्रम के साथ पंक्ति संख्याओं की गणना के लिए एक अच्छे समाधान की खोज जारी रखते हुए, कुछ तकनीकें हैं जो अंतिम विचित्र समाधान की तुलना में अधिक सुरक्षित लगती हैं:कार्यों के आधार पर रनटाइम स्थिरांक का उपयोग करना, एक स्थिरांक के आधार पर एक सबक्वेरी का उपयोग करना, एक अलियास कॉलम का उपयोग करना एक स्थिर और एक चर का उपयोग करना।
जैसा कि मैं टी-एसक्यूएल बग, नुकसान, और सर्वोत्तम प्रथाओं में व्याख्या करता हूं - नियतत्ववाद, टी-एसक्यूएल में अधिकांश कार्यों का मूल्यांकन केवल एक बार प्रति संदर्भ क्वेरी में किया जाता है-प्रति पंक्ति एक बार नहीं। GETDATE और RAND जैसे अधिकांश गैर-निर्धारिती कार्यों के साथ भी यही स्थिति है। इस नियम के बहुत कम अपवाद हैं, जैसे फ़ंक्शन NEWID और CRYPT_GEN_RANDOM, जिनका मूल्यांकन प्रति पंक्ति एक बार किया जाता है। अधिकांश फ़ंक्शन, जैसे GETDATE, @@ SPID और कई अन्य, का मूल्यांकन क्वेरी की शुरुआत में एक बार किया जाता है, और फिर उनके मानों को रनटाइम स्थिरांक माना जाता है। ऐसे कार्यों का संदर्भ लगातार मुड़ा नहीं जाता है। ये विशेषताएं एक रनटाइम स्थिरांक बनाती हैं जो एक फ़ंक्शन पर आधारित होता है जो विंडो ऑर्डरिंग तत्व के रूप में एक अच्छा विकल्प होता है, और वास्तव में, ऐसा लगता है कि टी-एसक्यूएल इसका समर्थन करता है। साथ ही, ऑप्टिमाइज़र को पता चलता है कि व्यवहार में कोई ऑर्डरिंग प्रासंगिकता नहीं है, अनावश्यक प्रदर्शन दंड से बचना।
यहां GETDATE फ़ंक्शन का उपयोग करके एक उदाहरण दिया गया है:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
इस क्वेरी को वही योजना मिलती है जो पहले चित्र 3 में दिखाई गई थी।
यहां @@ SPID फ़ंक्शन का उपयोग करके एक और उदाहरण दिया गया है (वर्तमान सत्र आईडी लौटाते हुए):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
समारोह पीआई के बारे में क्या? निम्न क्वेरी का प्रयास करें:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
यह निम्न त्रुटि के साथ विफल रहता है:
Msg 5309, Level 16, State 1, Line 153विंडो वाले फंक्शन, एग्रीगेट और फंक्शन के लिए NEXT VALUE ORDER BY क्लॉज एक्सप्रेशन के रूप में स्थिरांक का समर्थन नहीं करते हैं।
GETDATE और @@ SPID जैसे कार्यों का योजना के निष्पादन के अनुसार एक बार पुनर्मूल्यांकन किया जाता है, इसलिए वे लगातार फोल्ड नहीं हो सकते। पीआई हमेशा एक ही स्थिरांक का प्रतिनिधित्व करता है, और इसलिए लगातार मुड़ा हुआ होता है।
जैसा कि पहले उल्लेख किया गया है, बहुत कम फ़ंक्शन हैं जिनका प्रति पंक्ति एक बार मूल्यांकन किया जाता है, जैसे NEWID और CRYPT_GEN_RANDOM। यह उन्हें विंडो ऑर्डरिंग तत्व के रूप में एक खराब विकल्प बनाता है यदि आपको नोडेटर्मिनिस्टिक ऑर्डर की आवश्यकता होती है-यादृच्छिक क्रम से भ्रमित न होने के लिए। अनावश्यक सॉर्ट पेनल्टी का भुगतान क्यों करें?
यहां NEWID फ़ंक्शन का उपयोग करने का एक उदाहरण दिया गया है:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
इस क्वेरी की योजना चित्र 4 में दिखाई गई है, यह पुष्टि करते हुए कि SQL सर्वर ने फ़ंक्शन के परिणाम के आधार पर स्पष्ट सॉर्टिंग जोड़ी है।
 चित्र 4:क्वेरी 3 के लिए योजना
चित्र 4:क्वेरी 3 के लिए योजना
यदि आप चाहते हैं कि पंक्ति संख्याओं को यादृच्छिक क्रम में हर तरह से असाइन किया जाए, तो यही वह तकनीक है जिसका आप उपयोग करना चाहते हैं। आपको बस इस बात से अवगत रहने की आवश्यकता है कि यह सॉर्ट की लागत वहन करता है।
सबक्वायरी का उपयोग करना
आप विंडो ऑर्डरिंग एक्सप्रेशन के रूप में स्थिरांक के आधार पर एक सबक्वायरी का भी उपयोग कर सकते हैं (उदाहरण के लिए, ऑर्डर द्वारा ('कोई ऑर्डर नहीं' चुनें))। इस समाधान के साथ, SQL सर्वर का ऑप्टिमाइज़र यह मानता है कि कोई ऑर्डरिंग प्रासंगिकता नहीं है, और इसलिए कोई अनावश्यक सॉर्ट नहीं करता है या स्टोरेज इंजन की पसंद को सीमित नहीं करता है जो ऑर्डर की गारंटी देता है। उदाहरण के तौर पर निम्न क्वेरी को चलाने का प्रयास करें:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'No Order')) AS n FROM dbo.T1;
आपको वही योजना पहले चित्र 3 में दिखाई गई है।
इस तकनीक के महान लाभों में से एक यह है कि आप अपना व्यक्तिगत स्पर्श जोड़ सकते हैं। हो सकता है कि आपको वास्तव में NULLs पसंद हों:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
हो सकता है कि आपको वास्तव में एक निश्चित संख्या पसंद हो:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
शायद आप किसी को संदेश भेजना चाहते हैं:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'Lilach, will you marry me?')) AS n FROM dbo.T1;
आपको बात समझ में आ गई।
करने योग्य, लेकिन अजीब
कुछ तकनीकें हैं जो काम करती हैं, लेकिन थोड़ी अजीब हैं। एक स्थिरांक के आधार पर अभिव्यक्ति के लिए कॉलम उपनाम को परिभाषित करना है, और उसके बाद उस कॉलम उपनाम को विंडो ऑर्डरिंग तत्व के रूप में उपयोग करना है। आप इसे या तो टेबल एक्सप्रेशन का उपयोग करके या क्रॉस एप्लाई ऑपरेटर और टेबल वैल्यू कंस्ट्रक्टर के साथ कर सकते हैं। बाद के लिए यहां एक उदाहरण दिया गया है:
SELECT id, grp, datacol,
ROW_NUMBER() OVER(ORDER BY [I'm a bit ugly]) AS n
FROM dbo.T1 CROSS APPLY ( VALUES('No Order') ) AS A([I'm a bit ugly]); आपको वही योजना पहले चित्र 3 में दिखाई गई है।
एक अन्य विकल्प एक वैरिएबल का उपयोग विंडो ऑर्डरिंग एलिमेंट के रूप में करना है:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
इस क्वेरी को पहले चित्र 3 में दिखाया गया प्लान भी मिलता है।
यदि मैं अपने स्वयं के UDF का उपयोग करूँ तो क्या होगा?
आप सोच सकते हैं कि जब आप नॉनडेटर्मिनिस्टिक ऑर्डर चाहते हैं, तो अपने स्वयं के यूडीएफ का उपयोग करना जो एक स्थिरांक देता है, विंडो ऑर्डरिंग तत्व के रूप में एक अच्छा विकल्प हो सकता है, लेकिन ऐसा नहीं है। एक उदाहरण के रूप में निम्नलिखित UDF परिभाषा पर विचार करें:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis; GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INT AS BEGIN RETURN NULL END; GO
यूडीएफ को विंडो ऑर्डरिंग क्लॉज के रूप में उपयोग करने का प्रयास करें, जैसे (हम इसे एक प्रश्न 4 कहेंगे):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
SQL सर्वर 2019 (या समानांतर संगतता स्तर <150) से पहले, उपयोगकर्ता परिभाषित कार्यों का मूल्यांकन प्रति पंक्ति किया जाता है। यहां तक कि अगर वे एक स्थिरांक लौटाते हैं, तो भी वे इनलाइन नहीं होते हैं। नतीजतन, एक तरफ आप ऐसे यूडीएफ का उपयोग विंडो ऑर्डरिंग तत्व के रूप में कर सकते हैं, लेकिन दूसरी ओर इसका परिणाम एक प्रकार का दंड है। इस क्वेरी के लिए योजना की जांच करके इसकी पुष्टि की जाती है, जैसा कि चित्र 5 में दिखाया गया है।
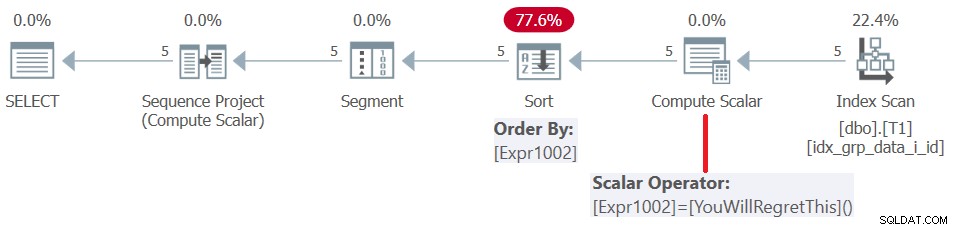 चित्र 5:क्वेरी 4 के लिए योजना
चित्र 5:क्वेरी 4 के लिए योजना
संगतता स्तर> =150 के तहत SQL सर्वर 2019 से शुरू होकर, ऐसे उपयोगकर्ता परिभाषित फ़ंक्शन इनलाइन हो जाते हैं, जो कि ज्यादातर एक अच्छी बात है, लेकिन हमारे मामले में एक त्रुटि होती है:
Msg 5309, Level 16, State 1, Line 217विंडो वाले फंक्शन, एग्रीगेट और फंक्शन के लिए NEXT VALUE ORDER BY क्लॉज एक्सप्रेशन के रूप में स्थिरांक का समर्थन नहीं करते हैं।
इसलिए विंडो ऑर्डरिंग एलिमेंट के रूप में एक स्थिरांक के आधार पर UDF का उपयोग करना आपके द्वारा उपयोग किए जा रहे SQL सर्वर के संस्करण और आपके डेटाबेस संगतता स्तर के आधार पर या तो एक सॉर्ट या त्रुटि को बाध्य करता है। संक्षेप में, ऐसा न करें।
पंक्ति संख्याओं को गैर-निर्धारिती क्रम के साथ विभाजित किया गया
गैर-निर्धारिती क्रम के आधार पर विभाजित पंक्ति संख्याओं के लिए एक सामान्य उपयोग का मामला प्रति समूह किसी भी पंक्ति को लौटा रहा है। यह देखते हुए कि परिभाषा के अनुसार इस परिदृश्य में एक विभाजन तत्व मौजूद है, आप सोचेंगे कि ऐसे मामले में एक सुरक्षित तकनीक विंडो विभाजन तत्व का उपयोग विंडो ऑर्डरिंग तत्व के रूप में भी करना होगा। पहले चरण के रूप में आप पंक्ति संख्याओं की गणना इस प्रकार करते हैं:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
इस क्वेरी की योजना चित्र 6 में दिखाई गई है।
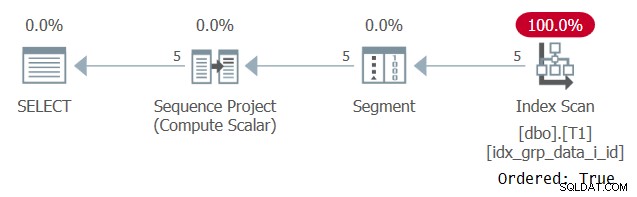 चित्र 6:प्रश्न 5 की योजना
चित्र 6:प्रश्न 5 की योजना
हमारे सपोर्टिंग इंडेक्स को ऑर्डर किए गए:ट्रू प्रॉपर्टी के साथ स्कैन करने का कारण यह है कि SQL सर्वर को प्रत्येक पार्टीशन की पंक्तियों को एक यूनिट के रूप में प्रोसेस करने की आवश्यकता होती है। छानने से पहले यही स्थिति है। यदि आप प्रति विभाजन केवल एक पंक्ति को फ़िल्टर करते हैं, तो आपके पास विकल्प के रूप में ऑर्डर-आधारित और हैश-आधारित एल्गोरिदम दोनों हैं।
दूसरा चरण क्वेरी को तालिका अभिव्यक्ति में पंक्ति संख्या गणना के साथ रखना है, और बाहरी क्वेरी में प्रत्येक विभाजन में पंक्ति संख्या 1 के साथ पंक्ति को फ़िल्टर करना है, जैसे:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; सैद्धांतिक रूप से इस तकनीक को सुरक्षित माना जाता है, लेकिन पॉल व्हाइट ने एक बग पाया जो दिखाता है कि इस पद्धति का उपयोग करके आप प्रति विभाजन परिणाम पंक्ति में विभिन्न स्रोत पंक्तियों से गुण प्राप्त कर सकते हैं। किसी फ़ंक्शन के आधार पर रनटाइम स्थिरांक का उपयोग करना या स्थिरांक पर आधारित सबक्वेरी का उपयोग करना क्योंकि इस परिदृश्य के साथ भी ऑर्डरिंग तत्व सुरक्षित प्रतीत होता है, इसलिए सुनिश्चित करें कि आप इसके बजाय निम्न जैसे समाधान का उपयोग करते हैं:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY (SELECT 'No Order')) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; मेरी अनुमति के बिना कोई भी इस रास्ते से नहीं गुजरेगा
गैर-नियतात्मक क्रम के आधार पर पंक्ति संख्याओं की गणना करने का प्रयास एक सामान्य आवश्यकता है। यह अच्छा होता अगर टी-एसक्यूएल ने केवल ROW_NUMBER फ़ंक्शन के लिए विंडो ऑर्डर क्लॉज को वैकल्पिक बना दिया, लेकिन ऐसा नहीं है। यदि नहीं, तो अच्छा होता अगर यह कम से कम एक स्थिरांक का उपयोग करने की अनुमति देता है, लेकिन यह एक समर्थित विकल्प भी नहीं है। लेकिन अगर आप किसी फ़ंक्शन के आधार पर स्थिर या रनटाइम स्थिरांक के आधार पर एक सबक्वायरी के रूप में अच्छी तरह से पूछते हैं, तो SQL सर्वर इसकी अनुमति देगा। ये दो विकल्प हैं जिनके साथ मैं सबसे अधिक सहज हूं। मैं वास्तव में विचित्र गलत अभिव्यक्तियों के साथ सहज महसूस नहीं करता जो काम करने लगती हैं इसलिए मैं इस विकल्प की अनुशंसा नहीं कर सकता।