
व्यावसायिक सफलता के लिए डेटा की उपलब्धता, पहुंच और प्रदर्शन महत्वपूर्ण हैं। प्रदर्शन ट्यूनिंग और SQL क्वेरी ऑप्टिमाइज़ेशन मुश्किल हैं, लेकिन डेटाबेस पेशेवरों के लिए आवश्यक अभ्यास हैं। उन्हें कुछ नाम रखने के लिए विस्तारित ईवेंट, परफ़ॉर्म, निष्पादन योजना, सांख्यिकी और अनुक्रमणिका का उपयोग करके डेटा के विभिन्न संग्रहों को देखने की आवश्यकता होती है। कभी-कभी, एप्लिकेशन के मालिक सिस्टम के प्रदर्शन को बेहतर बनाने के लिए सिस्टम संसाधनों (सीपीयू और मेमोरी) को बढ़ाने के लिए कहते हैं। हालांकि, हो सकता है कि आपको इन अतिरिक्त संसाधनों की आवश्यकता न हो और उनके साथ जुड़ी लागत हो सकती है। कभी-कभी, क्वेरी व्यवहार को बदलने के लिए केवल मामूली सुधार करने की आवश्यकता होती है।
इस लेख में, हम SQL क्वेरी लिखते समय लागू करने के लिए कुछ SQL क्वेरी ऑप्टिमाइज़ेशन सर्वोत्तम प्रथाओं पर चर्चा करेंगे।
चुनें * बनाम कॉलम सूची चुनें
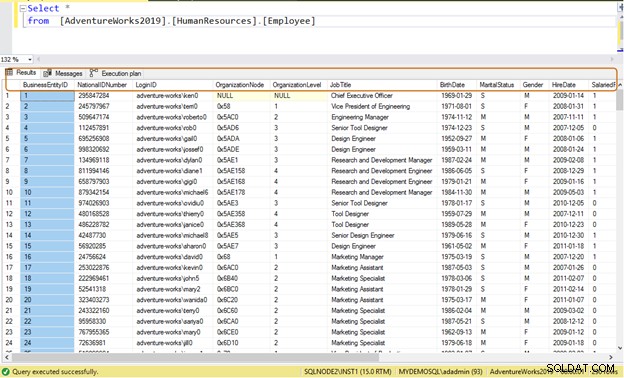
आमतौर पर, डेवलपर किसी तालिका से डेटा पढ़ने के लिए SELECT * कथन का उपयोग करते हैं। यह तालिका में कॉलम के सभी उपलब्ध डेटा को पढ़ता है। मान लीजिए एक टेबल [AdventureWorks2019].[HumanResources].[कर्मचारी] 290 कर्मचारियों के लिए डेटा स्टोर करता है और आपको निम्नलिखित जानकारी प्राप्त करने की आवश्यकता है:
- कर्मचारी राष्ट्रीय आईडी नंबर
- जन्मतिथि
- लिंग
- किराया तिथि
अक्षम क्वेरी: यदि आप SELECT * स्टेटमेंट का उपयोग करते हैं, तो यह सभी 290 कर्मचारियों के लिए सभी कॉलम का डेटा लौटाता है।
[AdventureWorks2019] सेचुनें।[HumanResources].[कर्मचारी]
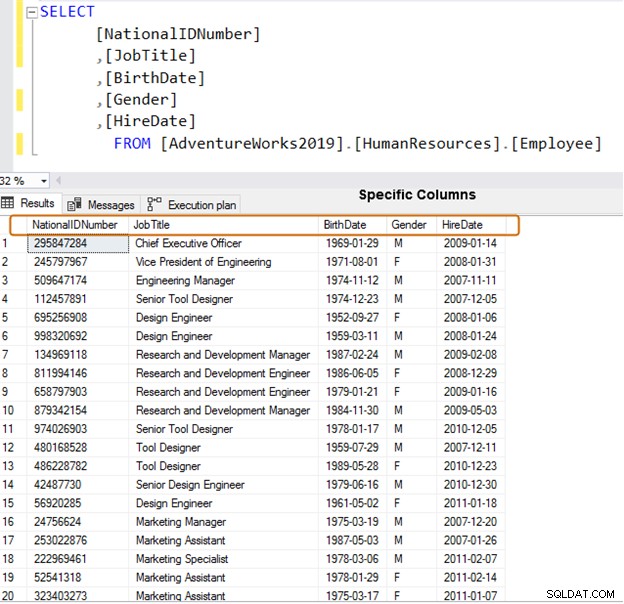
इसके बजाय, डेटा पुनर्प्राप्ति के लिए विशिष्ट कॉलम नामों का उपयोग करें।
चुनें [NationalIDNumber],[JobTitle],[BirthDate],[Gender],[HireDate]FROM [AdventureWorks2019]।[HumanResources].[कर्मचारी]
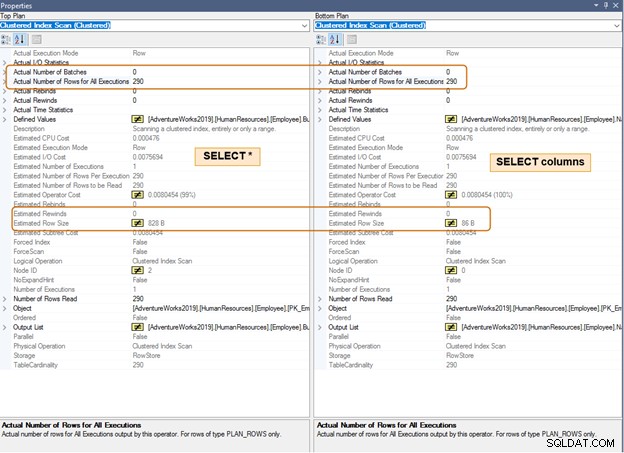
नीचे दी गई निष्पादन योजना में, पंक्तियों की समान संख्या के लिए अनुमानित पंक्ति आकार में अंतर पर ध्यान दें। आपको बड़ी संख्या में पंक्तियों के लिए CPU और IO में भी अंतर दिखाई देगा।
COUNT() बनाम EXISTS का उपयोग
मान लीजिए कि आप जांचना चाहते हैं कि SQL तालिका में कोई विशिष्ट रिकॉर्ड मौजूद है या नहीं। आमतौर पर, हम रिकॉर्ड की जांच के लिए COUNT (*) का उपयोग करते हैं, और यह आउटपुट में रिकॉर्ड की संख्या लौटाता है।
हालाँकि, हम इस उद्देश्य के लिए IF EXISTS() फ़ंक्शन का उपयोग कर सकते हैं। तुलना के लिए, मैंने प्रश्नों को निष्पादित करने से पहले आँकड़ों को सक्षम किया।
COUNT () के लिए क्वेरी
[AdventureWorks2019] से [SalesOrderDetail] जहां [SalesOrderDetailID] =44824 SET Statistics IO OFFअगर EXISTS के लिए क्वेरी ()
सेट सांख्यिकी IO ONIF EXISTS([AdventureWorks2019] से [CarrierTrackingNumber] चुनें।मैंने दोनों प्रश्नों के आंकड़ों के परिणामों का विश्लेषण करने के लिए सांख्यिकी पार्सर का उपयोग किया। नीचे परिणाम देखें। COUNT(*) के साथ क्वेरी में 276 लॉजिकल रीड हैं जबकि IF EXISTS() में 83 लॉजिकल रीड हैं। आप IF EXISTS() के साथ तार्किक पठन में और भी महत्वपूर्ण कमी प्राप्त कर सकते हैं। इसलिए, आपको इसका उपयोग बेहतर प्रदर्शन के लिए SQL क्वेरी को अनुकूलित करने के लिए करना चाहिए।
SQL DISTINCT का उपयोग करने से बचें
जब भी हम क्वेरी से अद्वितीय रिकॉर्ड चाहते हैं, हम आदतन SQL DISTINCT क्लॉज का उपयोग करते हैं। मान लीजिए कि आप दो तालिकाओं को एक साथ जोड़ते हैं, और आउटपुट में यह डुप्लिकेट पंक्तियों को लौटाता है। एक त्वरित समाधान DISTINCT ऑपरेटर को निर्दिष्ट करना है जो डुप्लिकेट पंक्ति को दबा देता है।
आइए सरल सेलेक्ट स्टेटमेंट देखें और निष्पादन योजनाओं की तुलना करें। दोनों प्रश्नों के बीच केवल एक DISTINCT ऑपरेटर का अंतर है।
SalesOrderDetailGo से SalesOrderDetailGoSELECT DISTINCT SalesOrderID को Sales.SalesOrderDetailGo से चुनें।DISTINCT ऑपरेटर के साथ, क्वेरी लागत 77% है, जबकि पिछली क्वेरी (DISTINCT के बिना) में केवल 23% बैच लागत है।
आप परिणाम सेट से अलग मान प्राप्त करने के लिए DISTINCT का उपयोग करने के बजाय कुशल SQL कोड लिखने के लिए GROUP BY, CTE या एक सबक्वेरी का उपयोग कर सकते हैं। इसके अतिरिक्त, आप विशिष्ट परिणाम सेट के लिए अतिरिक्त कॉलम पुनः प्राप्त कर सकते हैं।
SalesOrderID से SalesOrderID का चयन करें। SalesOrderID द्वारा SalesOrderDetail GroupSQL क्वेरी में वाइल्डकार्ड का उपयोग
मान लीजिए कि आप निर्दिष्ट स्ट्रिंग से शुरू होने वाले नामों वाले विशिष्ट रिकॉर्ड खोजना चाहते हैं। डेवलपर मेल खाने वाले रिकॉर्ड खोजने के लिए वाइल्डकार्ड का उपयोग करते हैं।
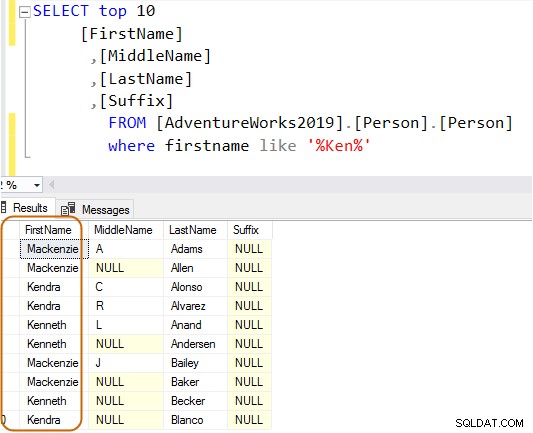
नीचे दी गई क्वेरी में, यह प्रथम नाम कॉलम में स्ट्रिंग केन की खोज करता है। यह क्वेरी केन . के अपेक्षित परिणाम पुनर्प्राप्त करती है ड्रा और केन नेथ। लेकिन, यह अप्रत्याशित परिणाम भी प्रदान करता है, उदाहरण के लिए, मैककेन ज़ी और एनकेन जीई।
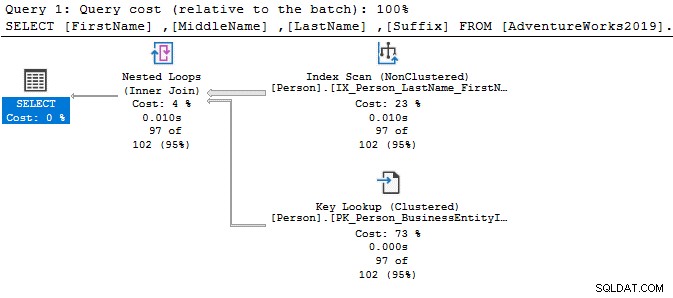
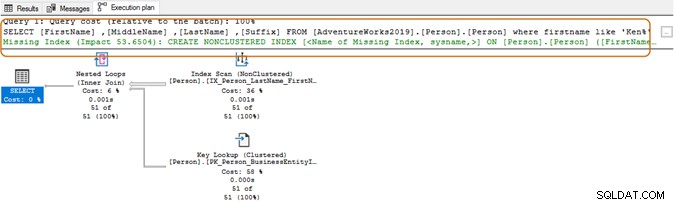
निष्पादन योजना में, आप उपरोक्त क्वेरी के लिए इंडेक्स स्कैन और की लुकअप देखते हैं।
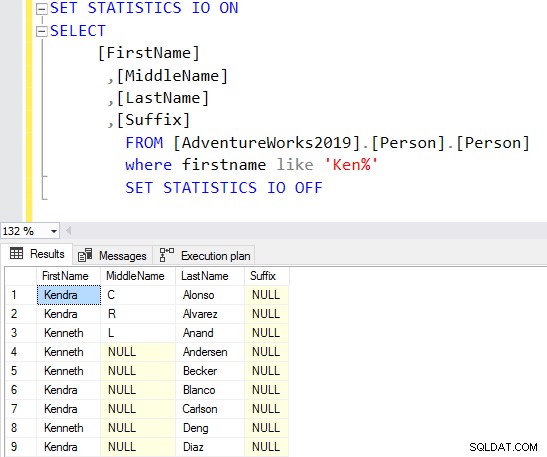
आप स्ट्रिंग के अंत में वाइल्डकार्ड वर्ण का उपयोग करके अप्रत्याशित परिणाम से बच सकते हैं।
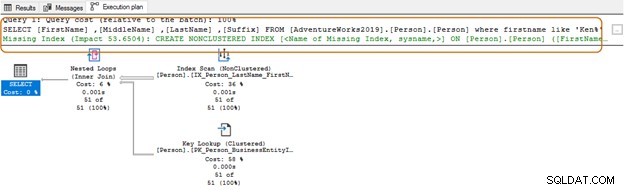
चुनें शीर्ष 10[प्रथम नाम],[मध्य नाम],[अंतिम नाम],[प्रत्यय] [AdventureWorks2019] से।[व्यक्ति]।[व्यक्ति]जहां पहला नाम 'केन%' जैसा हैअब, आप अपनी आवश्यकताओं के आधार पर फ़िल्टर किए गए परिणाम प्राप्त करते हैं।
शुरुआत में वाइल्डकार्ड कैरेक्टर का उपयोग करने में, क्वेरी ऑप्टिमाइज़र उपयुक्त इंडेक्स का उपयोग करने में सक्षम नहीं हो सकता है। जैसा कि नीचे दिए गए स्क्रीनशॉट में दिखाया गया है, एक अनुगामी जंगली चरित्र के साथ, क्वेरी ऑप्टिमाइज़र एक अनुपलब्ध अनुक्रमणिका का भी सुझाव देता है।
यहां, आप अपनी आवेदन आवश्यकताओं का मूल्यांकन करना चाहेंगे। आपको खोज स्ट्रिंग में वाइल्डकार्ड वर्ण का उपयोग करने से बचने का प्रयास करना चाहिए, क्योंकि यह क्वेरी अनुकूलक को तालिका स्कैन का उपयोग करने के लिए बाध्य कर सकता है। यदि तालिका बहुत बड़ी है, तो उसे IO, CPU और मेमोरी के लिए उच्च सिस्टम संसाधनों की आवश्यकता होगी, और आपकी SQL क्वेरी के लिए प्रदर्शन समस्याएँ पैदा कर सकता है।
WHERE और HAVING क्लॉज का उपयोग
WHERE और HAVING क्लॉज़ का उपयोग डेटा पंक्ति फ़िल्टर के रूप में किया जाता है। WHERE क्लॉज ग्रुपिंग लॉजिक को लागू करने से पहले डेटा को फ़िल्टर करता है, जबकि HAVING क्लॉज़ कुल गणना के बाद पंक्तियों को फ़िल्टर करता है।
उदाहरण के लिए, नीचे दी गई क्वेरी में, हम WHERE क्लॉज़ के बिना HAVING क्लॉज़ में डेटा फ़िल्टर का उपयोग करते हैं।
SalesOrderID,SUM(UnitPrice* OrderQty) को OrderTotal से Sales.salesOrderDetailGROUP BY SalesOrderIDHAVING SalesOrderID>30000 और SalesOrderID<55555 और SUM(UnitPrice* OrderQty)>1Goके रूप में चुनेंनिम्न क्वेरी डेटा को पहले WHERE क्लॉज में फ़िल्टर करती है और फिर एग्रीगेट डेटा फ़िल्टर के लिए HAVING क्लॉज़ का उपयोग करती है।
SalesOrderID,SUM(UnitPrice* OrderQty) को OrderTotal के रूप में Sales.salesOrderDetailwhere SalesOrderID>30000 और SalesOrderID<55555GROUP BY SalesOrderIDHAVING SUM(UnitPrice* OrderQty)>1000Goसे चुनेंमैं डेटा फ़िल्टरिंग के लिए WHERE क्लॉज़ और आपके एग्रीगेट डेटा फ़िल्टर के लिए HAVING क्लॉज़ को सर्वोत्तम अभ्यास के रूप में उपयोग करने की सलाह देता हूँ।
IN और EXISTS क्लॉज का उपयोग
आपको अपने SQL प्रश्नों के लिए IN-ऑपरेटर क्लॉज का उपयोग करने से बचना चाहिए। उदाहरण के लिए, नीचे दी गई क्वेरी में, हमें पहले [उत्पादन].[लेन-देन इतिहास]) तालिका से उत्पाद आईडी मिली और फिर [उत्पादन] [उत्पाद] तालिका में संबंधित रिकॉर्ड की तलाश की।
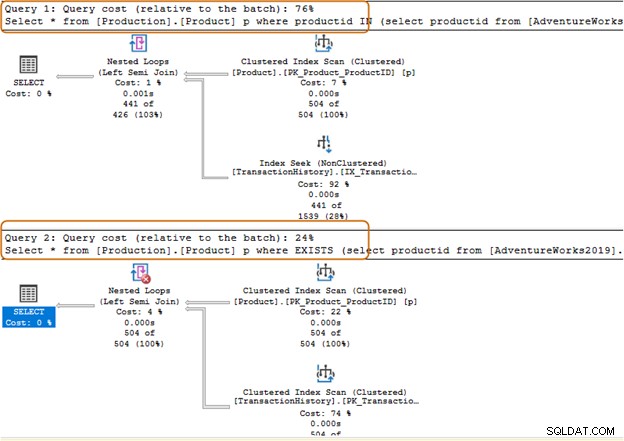
[Production] से * चुनें।[Product] p जहां productid IN ([AdventureWorks2019] से productid चुनें।नीचे दी गई क्वेरी में, हमने IN क्लॉज़ को EXISTS क्लॉज़ से बदल दिया है।
[Production] से * चुनें।अब, दोनों प्रश्नों को क्रियान्वित करने के बाद आँकड़ों की तुलना करते हैं।
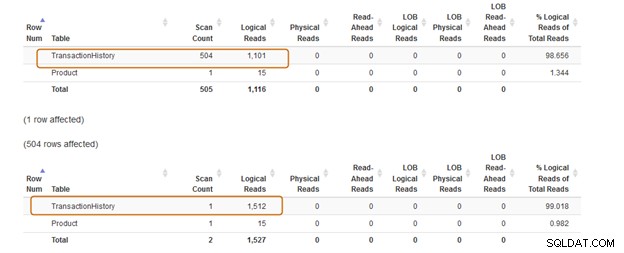
IN क्लॉज 504 स्कैन का उपयोग करता है, जबकि EXISTS क्लॉज [उत्पादन] के लिए 1 स्कैन का उपयोग करता है। [लेन-देन इतिहास]) तालिका]।
IN क्लॉज क्वेरी बैच की लागत 74% है, जबकि EXISTS क्लॉज की लागत 24% है। इसलिए, आपको IN क्लॉज से बचना चाहिए, खासकर अगर सबक्वेरी एक बड़ा डेटासेट देता है।
अनुक्रमणिका अनुपलब्ध
कभी-कभी, जब हम SQL क्वेरी निष्पादित करते हैं और SSMS में वास्तविक निष्पादन योजना की तलाश करते हैं, तो आपको एक इंडेक्स के बारे में एक सुझाव मिलता है जो आपकी SQL क्वेरी को बेहतर बना सकता है।
वैकल्पिक रूप से, आप अपने परिवेश में अनुपलब्ध अनुक्रमणिका के विवरण की जाँच करने के लिए गतिशील प्रबंधन दृश्यों का उपयोग कर सकते हैं।

- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
आमतौर पर, डीबीए एसएसएमएस की सलाह का पालन करते हैं और इंडेक्स बनाते हैं। यह फिलहाल के लिए क्वेरी प्रदर्शन में सुधार कर सकता है। हालांकि, आपको उन अनुशंसाओं के आधार पर सीधे इंडेक्स नहीं बनाना चाहिए। यह अन्य क्वेरी प्रदर्शन को प्रभावित कर सकता है और आपके INSERT और UPDATE स्टेटमेंट को धीमा कर सकता है।
- सबसे पहले, अपनी SQL तालिका के लिए मौजूदा अनुक्रमणिका की समीक्षा करें।
- ध्यान दें, ओवर-इंडेक्सिंग और अंडर-इंडेक्सिंग दोनों ही क्वेरी प्रदर्शन के लिए खराब हैं।
- अनुपलब्ध अनुक्रमणिका अनुशंसाओं को अपनी मौजूदा अनुक्रमणिकाओं की समीक्षा करने के बाद उच्चतम प्रभाव के साथ लागू करें और इसे अपने निचले परिवेश पर लागू करें। यदि आपका कार्यभार नई अनुपलब्ध अनुक्रमणिका को लागू करने के बाद अच्छी तरह से काम करता है, तो यह it. . जोड़ने लायक है
मेरा सुझाव है कि आप विस्तृत अनुक्रमण सर्वोत्तम प्रथाओं के लिए इस लेख को देखें: 11 SQL सर्वर अनुक्रमणिका बेहतर प्रदर्शन ट्यूनिंग के लिए सर्वोत्तम अभ्यास।
क्वेरी संकेत
डेवलपर्स अपने टी-एसक्यूएल स्टेटमेंट में स्पष्ट रूप से क्वेरी संकेत निर्दिष्ट करते हैं। ये क्वेरी संकेत क्वेरी ऑप्टिमाइज़र व्यवहार को ओवरराइड करते हैं और इसे आपके क्वेरी संकेत के आधार पर निष्पादन योजना तैयार करने के लिए बाध्य करते हैं। अक्सर उपयोग किए जाने वाले क्वेरी संकेत NOLOCK, ऑप्टिमाइज़ फॉर और रीकंपाइल मर्ज/हैश/लूप हैं। वे आपके प्रश्नों के लिए अल्पकालिक सुधार हैं। हालांकि, आपको स्थायी समाधान के लिए अपनी क्वेरी, इंडेक्स, आंकड़े और निष्पादन योजना का विश्लेषण करने पर काम करना चाहिए।
सर्वोत्तम प्रथाओं के अनुसार, आपको किसी भी क्वेरी संकेत का उपयोग कम से कम करना चाहिए। आप पहले SQL क्वेरी के निहितार्थों को समझने के बाद क्वेरी संकेतों का उपयोग करना चाहते हैं, और इसे अनावश्यक रूप से उपयोग नहीं करना चाहते हैं।
SQL क्वेरी ऑप्टिमाइज़ेशन रिमाइंडर
जैसा कि हमने चर्चा की, SQL क्वेरी ऑप्टिमाइज़ेशन एक ओपन-एंडेड रोड है। आप सर्वोत्तम प्रथाओं और छोटे सुधारों को लागू कर सकते हैं जो प्रदर्शन में काफी सुधार कर सकते हैं। बेहतर क्वेरी विकास के लिए निम्नलिखित युक्तियों पर विचार करें:
- हमेशा सिस्टम संसाधनों (डिस्क, सीपीयू, मेमोरी) आवंटन को देखें
- अपने स्टार्टअप ट्रेस फ़्लैग, इंडेक्स और डेटाबेस रखरखाव कार्यों की समीक्षा करें
- विस्तारित ईवेंट, प्रोफाइलर या तृतीय-पक्ष डेटाबेस निगरानी टूल का उपयोग करके अपने कार्यभार का विश्लेषण करें
- किसी भी समाधान को हमेशा पहले परीक्षण वातावरण पर लागू करें (भले ही आप 100% आश्वस्त हों) और उसके प्रभाव का विश्लेषण करें; एक बार जब आप संतुष्ट हो जाएं, तो उत्पादन कार्यान्वयन की योजना बनाएं



