डेटाबेस उच्च उपलब्धता में लोड बैलेंसर एक आवश्यक घटक हैं; विशेष रूप से जब टोपोलॉजी को अनुप्रयोगों के लिए पारदर्शी बनाते हैं और रीड-राइट स्प्लिट कार्यक्षमता को लागू करते हैं। ClusterControl उद्योग की अग्रणी ओपन सोर्स लोड बैलेंसिंग तकनीकों को सुरक्षित रूप से तैनात, मॉनिटर और कॉन्फ़िगर करने के लिए सुविधाओं की एक सरणी प्रदान करता है।
पिछले एक साल में हमने ProxySQL के लिए समर्थन जोड़ा है और HAProxy और MariaDB के Maxscale के लिए कई एन्हांसमेंट जोड़े हैं। हम इस परंपरा को ClusterControl 1.5 की नवीनतम रिलीज़ के साथ जारी रखते हैं।
हमें अपने उपयोगकर्ताओं से प्राप्त फीडबैक के आधार पर, हमने सुधार किया है कि प्रॉक्सीएसक्यूएल कैसे प्रबंधित किया जाता है। हमने PostgreSQL क्लस्टर के शीर्ष पर चलने के लिए HAProxy और Keepalived के लिए समर्थन भी जोड़ा।
इस ब्लॉग पोस्ट में, हम इन सुधारों पर एक नज़र डालेंगे...
ProxySQL - उपयोगकर्ता प्रबंधन संवर्द्धन
पहले, UI आपको केवल एक नया उपयोगकर्ता बनाने या मौजूदा एक को एक बार में जोड़ने की अनुमति देता था। हमें अपने उपयोगकर्ताओं से एक प्रतिक्रिया मिली कि बड़ी संख्या में उपयोगकर्ताओं को प्रबंधित करना काफी कठिन है। हमने सुना और ClusterControl 1.5 में, अब उपयोगकर्ताओं के बड़े बैच को आयात करना संभव है। आइए देखें कि आप यह कैसे कर सकते हैं। सबसे पहले, आपको अपने ProxySQL को परिनियोजित करने की आवश्यकता है। फिर, प्रॉक्सीएसक्यूएल नोड पर जाएं, और उपयोगकर्ता टैब में, आपको "उपयोगकर्ता आयात करें" बटन देखना चाहिए।

इस पर क्लिक करने के बाद एक नया डायलॉग बॉक्स खुलेगा:

यहां आप उन सभी उपयोगकर्ताओं को देख सकते हैं जिन्हें आपके क्लस्टर पर ClusterControl का पता चला है। आप उनके माध्यम से स्क्रॉल कर सकते हैं और जिन्हें आप आयात करना चाहते हैं उन्हें चुन सकते हैं। आप वर्तमान दृश्य से सभी उपयोगकर्ताओं का चयन या चयन रद्द भी कर सकते हैं।

एक बार जब आप खोज बॉक्स में टाइप करना शुरू कर देते हैं, तो ClusterControl गैर-मिलान परिणामों को फ़िल्टर कर देगा, सूची को केवल आपकी खोज के लिए प्रासंगिक उपयोगकर्ताओं तक सीमित कर देगा।
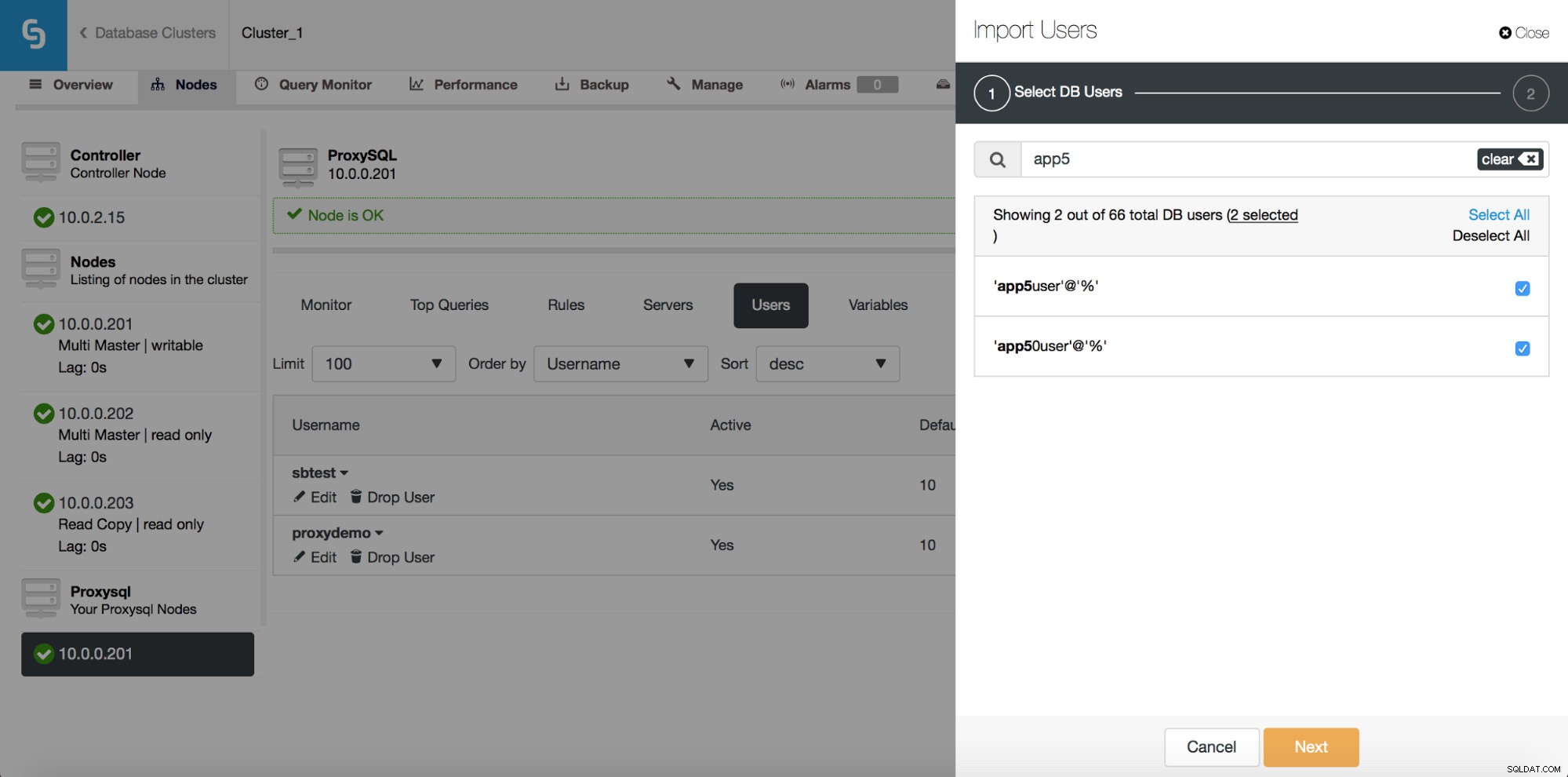
आप अपनी खोज से मेल खाने वाले सभी उपयोगकर्ताओं का चयन करने के लिए "सभी का चयन करें" बटन का उपयोग कर सकते हैं। बेशक, उन उपयोगकर्ताओं को चुनने के बाद जिन्हें आप आयात करना चाहते हैं, आप खोज बॉक्स को साफ़ कर सकते हैं और दूसरी खोज शुरू कर सकते हैं:

कृपया ध्यान दें "(7 चयनित)" - यह आपको बताता है कि कुल कितने उपयोगकर्ता (केवल इस खोज से नहीं), आपने आयात करने के लिए चुना है। आप केवल उन उपयोगकर्ताओं को देखने के लिए भी उस पर क्लिक कर सकते हैं जिन्हें आपने आयात करने के लिए चुना है।

एक बार जब आप अपनी पसंद से खुश हो जाते हैं, तो आप अगली स्क्रीन पर जाने के लिए "अगला" पर क्लिक कर सकते हैं।

यहां आपको यह तय करने की आवश्यकता है कि प्रत्येक उपयोगकर्ता के लिए डिफ़ॉल्ट होस्टग्रुप क्या होना चाहिए। आप ऐसा प्रति-उपयोगकर्ता के आधार पर या वैश्विक रूप से, संपूर्ण सेट या किसी खोज के परिणामस्वरूप होने वाले उपयोगकर्ताओं के सबसेट के लिए कर सकते हैं।

एक बार जब आप "उपयोगकर्ताओं को आयात करें" बटन पर क्लिक करते हैं, तो उपयोगकर्ता आयात किए जाएंगे और वे उपयोगकर्ता टैब में दिखाई देंगे।
ProxySQL - शेड्यूलर प्रबंधन
ProxySQL का अनुसूचक एक क्रॉन जैसा मॉड्यूल है जो ProxySQL को नियमित अंतराल पर बाहरी स्क्रिप्ट शुरू करने की अनुमति देता है। शेड्यूल काफी बारीक हो सकता है - प्रत्येक मिलीसेकंड में एक निष्पादन तक। आमतौर पर, शेड्यूलर का उपयोग गैलेरा चेकर स्क्रिप्ट (जैसे proxysql_galera_checker.sh) को निष्पादित करने के लिए किया जाता है, लेकिन इसका उपयोग किसी अन्य स्क्रिप्ट को निष्पादित करने के लिए भी किया जा सकता है जिसे आप पसंद करते हैं। अतीत में, क्लस्टर कंट्रोल ने गैलेरा चेकर स्क्रिप्ट को तैनात करने के लिए शेड्यूलर का उपयोग किया था लेकिन यह यूआई में उजागर नहीं हुआ था। ClusterControl 1.5 शुरू करके, अब आपका पूरा नियंत्रण है।

जैसा कि आप देख सकते हैं, प्रत्येक 2 सेकंड (2000 मिलीसेकंड) में एक स्क्रिप्ट चलाने के लिए निर्धारित किया गया है - यह गैलेरा क्लस्टर के लिए डिफ़ॉल्ट कॉन्फ़िगरेशन है।

उपरोक्त स्क्रीनशॉट हमें मौजूदा प्रविष्टियों को संपादित करने के विकल्प दिखाता है। कृपया ध्यान दें कि ProxySQL उस स्क्रिप्ट के लिए अधिकतम 5 तर्कों का समर्थन करता है जिसे वह अनुसूचक के माध्यम से निष्पादित करेगा।

यदि आप शेड्यूलर में एक नई स्क्रिप्ट जोड़ना चाहते हैं, तो आप "नई स्क्रिप्ट जोड़ें" बटन पर क्लिक कर सकते हैं और आपको ऊपर की तरह एक स्क्रीन के साथ प्रस्तुत किया जाएगा। आप यह भी पूर्वावलोकन कर सकते हैं कि निष्पादित होने पर पूरी स्क्रिप्ट कैसी दिखेगी। सभी "तर्क" फ़ील्ड भरने और अंतराल को परिभाषित करने के बाद, आप "नई स्क्रिप्ट जोड़ें" बटन पर क्लिक कर सकते हैं।

परिणामस्वरूप, शेड्यूलर में एक स्क्रिप्ट जोड़ी जाएगी और यह शेड्यूल की गई स्क्रिप्ट की सूची में दिखाई देगी।
आज श्वेतपत्र डाउनलोड करें क्लस्टरकंट्रोल के साथ पोस्टग्रेएसक्यूएल प्रबंधन और स्वचालन इस बारे में जानें कि पोस्टग्रेएसक्यूएल को तैनात करने, मॉनिटर करने, प्रबंधित करने और स्केल करने के लिए आपको क्या जानना चाहिए। श्वेतपत्र डाउनलोड करेंPostgreSQL - उच्च उपलब्धता स्टैक का निर्माण
ऑटो फेलओवर के साथ प्रतिकृति सेट करना अच्छा है, लेकिन अनुप्रयोगों को लिखने योग्य मास्टर को ट्रैक करने के लिए एक आसान तरीका चाहिए। इसलिए हमने PostgreSQL क्लस्टर के शीर्ष पर HAProxy और Keepalived के लिए समर्थन जोड़ा। यह हमारे PostgreSQL उपयोगकर्ताओं को ClusterControl का उपयोग करके पूर्ण उच्च उपलब्धता स्टैक को परिनियोजित करने की अनुमति देता है।

लोड बैलेंसर उप टैब से, अब आप HAProxy को परिनियोजित कर सकते हैं - यदि आप इस बात से परिचित हैं कि ClusterControl MySQL प्रतिकृति को कैसे परिनियोजित करता है, तो यह एक बहुत ही परिचित सेटअप है। हम किसी दिए गए होस्ट पर HAProxy स्थापित करते हैं, दो बैकएंड, पोर्ट 3308 पर पढ़ते हैं और पोर्ट 3307 पर लिखते हैं। यह tcp-check का उपयोग करता है, एक विशेष स्ट्रिंग के वापस आने की उम्मीद करता है। उस स्ट्रिंग को बनाने के लिए, सभी डेटाबेस नोड्स पर निम्न चरणों को निष्पादित किया जाता है। सबसे पहले, xinet.d को पोर्ट 9201 पर एक सेवा चलाने के लिए कॉन्फ़िगर किया गया है (MySQL सेटअप के साथ भ्रम से बचने के लिए, जो पोर्ट 9200 का उपयोग करता है)।
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDसेवा /usr/local/sbin/postgreschk स्क्रिप्ट को निष्पादित करती है, जो PostgreSQL की स्थिति को मान्य करती है और बताती है कि क्या दिया गया होस्ट उपलब्ध है और यह किस प्रकार का होस्ट है (मास्टर या गुलाम)। यदि सब कुछ ठीक है, तो यह HAProxy द्वारा अपेक्षित स्ट्रिंग लौटाता है।
MySQL की तरह, PostgreSQL क्लस्टर में HAProxy नोड्स UI में देखे जाते हैं और स्थिति पृष्ठ तक पहुँचा जा सकता है:

यहां आप दोनों बैकएंड देख सकते हैं और सत्यापित कर सकते हैं कि केवल मास्टर r/w बैकएंड के लिए तैयार है और सभी नोड्स को रीड-ओनली बैकएंड के माध्यम से एक्सेस किया जा सकता है। आप ट्रैफ़िक और कनेक्शन के बारे में कुछ आंकड़े भी प्राप्त कर सकते हैं।
HAProxy उच्च उपलब्धता में सुधार करने में मदद करता है, लेकिन यह विफलता का एकल बिंदु बन सकता है। हमें अतिरिक्त मील जाने और Keepalived की सहायता से अतिरेक को कॉन्फ़िगर करने की आवश्यकता है।

मैनेज के तहत -> लोड बैलेंसर -> कीपलाइव्ड, आप उन HAProxy होस्ट्स को चुनते हैं जिनका आप उपयोग करना चाहते हैं और Keepalived को आपके पसंद के इंटरफ़ेस से जुड़े वर्चुअल आईपी के साथ उनके ऊपर तैनात किया जाएगा।
अब से, सभी कनेक्टिविटी VIP को मिलनी चाहिए, जो HAProxy नोड्स में से एक से जुड़ी होगी। यदि वह नोड नीचे चला जाता है, तो Keepalived उस नोड पर VIP को नीचे ले जाएगा और इसे दूसरे HAProxy नोड पर लाएगा।
यह ClusterControl 1.5 में पेश की गई लोड बैलेंसिंग सुविधाओं के लिए है। इन्हें आज़माएं और हमें बताएं कि आप कैसे हैं