विकिपीडिया के अनुसार, बल्क इंसर्ट एक डेटाबेस प्रबंधन प्रणाली द्वारा डेटाबेस तालिका में डेटा की कई पंक्तियों को लोड करने के लिए प्रदान की जाने वाली एक प्रक्रिया या विधि है। यदि हम इस स्पष्टीकरण को बल्क इंसर्ट स्टेटमेंट में समायोजित करते हैं, तो बल्क इंसर्ट बाहरी डेटा फ़ाइलों को SQL सर्वर में आयात करने की अनुमति देता है।
मान लें कि हमारे संगठन में 1.500.000 पंक्तियों की एक CSV फ़ाइल है, और हम SQL सर्वर में बल्क INSERT कथन का उपयोग करने के लिए इसे SQL सर्वर में किसी विशेष तालिका में आयात करना चाहते हैं। हम इस कार्य को संभालने के लिए कई तरीके खोज सकते हैं। यह बीसीपी का उपयोग कर रहा हो सकता है (b ulk c opy p rogram), SQL सर्वर आयात और निर्यात विज़ार्ड, या SQL सर्वर एकीकरण सेवा पैकेज। हालाँकि, BULK INSERT कथन बहुत तेज़ और शक्तिशाली है। एक और फायदा यह है कि यह कई पैरामीटर प्रदान करता है जो बल्क इंसर्ट प्रक्रिया सेटिंग्स को निर्धारित करने में मदद करता है।
आइए एक बुनियादी नमूने से शुरू करें। फिर हम और अधिक परिष्कृत परिदृश्यों से गुजरेंगे।
तैयारी
सबसे पहले, हमें एक नमूना CSV फ़ाइल की आवश्यकता है। हम एक्सेल वेबसाइट के लिए ई से एक नमूना सीएसवी फ़ाइल डाउनलोड करते हैं (एक अलग पंक्ति संख्या के साथ नमूना सीएसवी फाइलों का संग्रह)। यहां, हम 1.500,000 बिक्री रिकॉर्ड का उपयोग करने जा रहे हैं।
एक ज़िप फ़ाइल डाउनलोड करें, एक CSV फ़ाइल प्राप्त करने के लिए इसे अनज़िप करें, और इसे अपने स्थानीय ड्राइव में रखें।
सीएसवी फ़ाइल को SQL सर्वर तालिका में आयात करें
हम अपनी CSV फ़ाइल को सरलतम रूप में गंतव्य तालिका में आयात करते हैं। मैंने अपना नमूना CSV फ़ाइल C:ड्राइव पर रखा। अब हम इसमें CSV फ़ाइल डेटा आयात करने के लिए एक तालिका बनाते हैं:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
निम्न बल्क INSERT कथन CSV फ़ाइल को विक्रय तालिका में आयात करता है:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); आपने शायद उपरोक्त बल्क इंसर्ट स्टेटमेंट के विशिष्ट मापदंडों को नोट कर लिया है। आइए उन्हें स्पष्ट करें:
- FIRSTROW इन्सर्ट स्टेटमेंट के शुरुआती बिंदु को निर्दिष्ट करता है। नीचे दिए गए उदाहरण में, हम कॉलम हेडर को छोड़ना चाहते हैं, इसलिए हम इस पैरामीटर को 2 पर सेट करते हैं।

- FIELDTERMINATOR उस चरित्र को परिभाषित करता है जो फ़ील्ड को एक दूसरे से अलग करता है। SQL सर्वर इस तरह प्रत्येक फ़ील्ड का पता लगाता है।
- रोटरमिनेटर FIELDTERMINATOR से बहुत अलग नहीं है। यह पंक्तियों के पृथक्करण चरित्र को परिभाषित करता है।
नमूना CSV फ़ाइल में, FIELDTERMINATOR बहुत स्पष्ट है, और यह एक अल्पविराम (,) है। इस पैरामीटर का पता लगाने के लिए, Notepad++ में CSV फ़ाइल खोलें और View -> Show Symbol -> Show All Charters पर नेविगेट करें। CRLF वर्ण प्रत्येक फ़ील्ड के अंत में होते हैं।
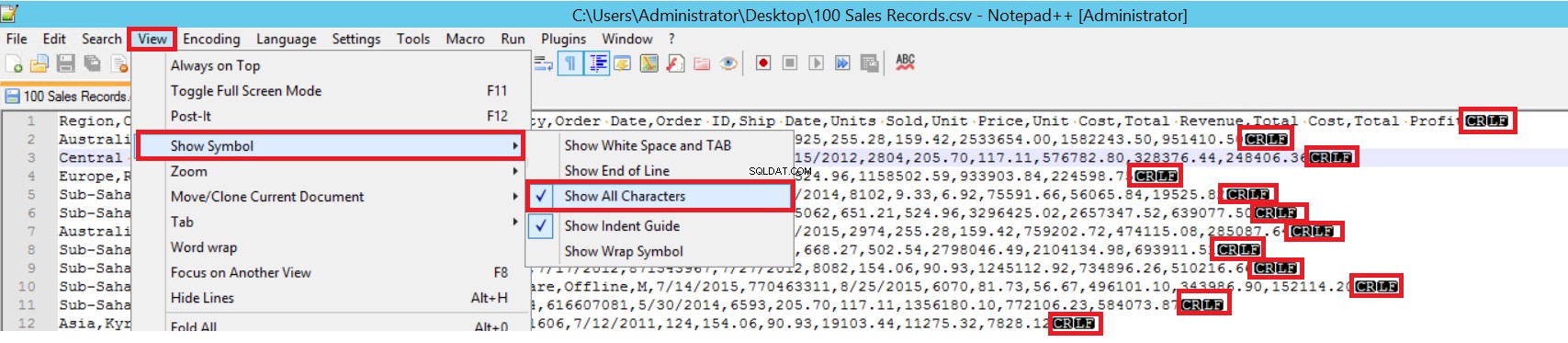
सीआर =कैरिज रिटर्न और एलएफ =लाइन फीड। उनका उपयोग टेक्स्ट फ़ाइल में लाइन ब्रेक को चिह्नित करने के लिए किया जाता है। बल्क इंसर्ट स्टेटमेंट में संकेतक "\n" है।
एक CSV फ़ाइल को बल्क इंसर्ट वाली तालिका में आयात करने का दूसरा तरीका FORMAT पैरामीटर का उपयोग करना है। ध्यान दें कि यह पैरामीटर केवल SQL Server 2017 और बाद के संस्करणों में उपलब्ध है।
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
यह सबसे सरल परिदृश्य था जहां गंतव्य तालिका और सीएसवी फ़ाइल में समान संख्या में कॉलम होते हैं। हालाँकि, जब गंतव्य तालिका में अधिक कॉलम होते हैं, तो CSV फ़ाइल विशिष्ट होती है। आइए इस पर विचार करें।
समानता कॉलम मैपिंग को तोड़ने के लिए हम बिक्री तालिका में प्राथमिक कुंजी जोड़ते हैं। हम प्राथमिक कुंजी के साथ बिक्री तालिका बनाते हैं और CSV फ़ाइल को बल्क इंसर्ट कमांड के माध्यम से आयात करते हैं।
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); लेकिन यह एक त्रुटि उत्पन्न करता है:
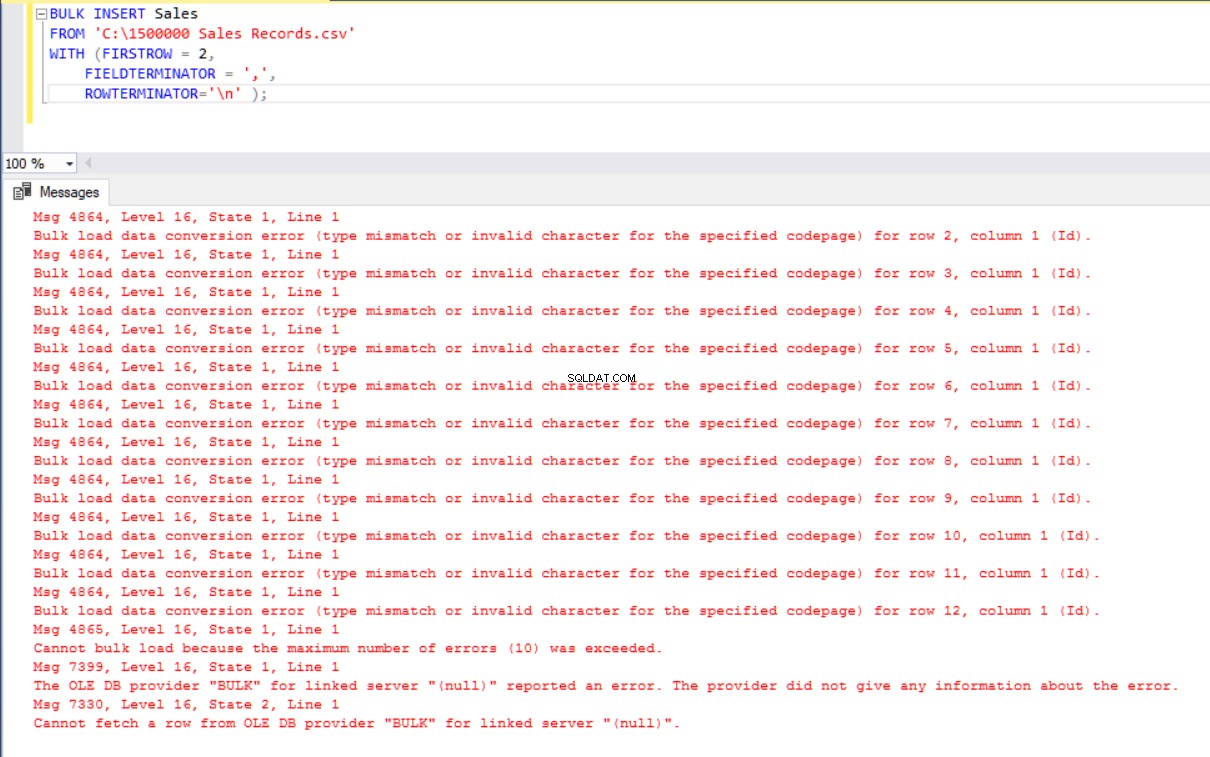
त्रुटि को दूर करने के लिए, हम CSV फ़ाइल में मैपिंग कॉलम के साथ बिक्री तालिका का एक दृश्य बनाते हैं। फिर हम इस दृश्य पर CSV डेटा को बिक्री तालिका में आयात करते हैं:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); एक बड़ी CSV फ़ाइल को छोटे बैच आकार में अलग और लोड करें
SQL सर्वर बल्क इंसर्ट ऑपरेशन के दौरान गंतव्य तालिका में लॉक प्राप्त करता है। डिफ़ॉल्ट रूप से, यदि आप BATCHSIZE पैरामीटर सेट नहीं करते हैं, तो SQL सर्वर एक लेनदेन खोलता है और इसमें संपूर्ण CSV डेटा सम्मिलित करता है। इस पैरामीटर के साथ, SQL सर्वर CSV डेटा को पैरामीटर मान के अनुसार विभाजित करता है।
आइए संपूर्ण CSV डेटा को 300,000 पंक्तियों के कई सेटों में विभाजित करें।
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); डेटा को पांच बार भागों में आयात किया जाएगा।
- यदि आपके बल्क इंसर्ट स्टेटमेंट में BATCHSIZE पैरामीटर शामिल नहीं है, तो एक त्रुटि होगी, और SQL सर्वर पूरी बल्क इंसर्ट प्रक्रिया को वापस रोल कर देगा।
- बल्क इंसर्ट स्टेटमेंट पर सेट इस पैरामीटर के साथ, SQL सर्वर केवल उस हिस्से को वापस रोल करता है जहां त्रुटि हुई थी।
इस पैरामीटर के लिए कोई इष्टतम या सर्वोत्तम मूल्य नहीं है क्योंकि इसका मान आपके डेटाबेस सिस्टम आवश्यकताओं के अनुसार बदल सकता है।
त्रुटियों के मामले में व्यवहार सेट करें
यदि कुछ बल्क कॉपी परिदृश्यों में कोई त्रुटि होती है, तो हम या तो बल्क कॉपी प्रक्रिया को रद्द कर सकते हैं या इसे जारी रख सकते हैं। MAXERRORS पैरामीटर हमें त्रुटियों की अधिकतम संख्या निर्दिष्ट करने की अनुमति देता है। यदि बल्क इंसर्ट प्रक्रिया इस अधिकतम त्रुटि मान तक पहुँच जाती है, तो यह बल्क इंपोर्ट ऑपरेशन को रद्द कर देती है और वापस रोल हो जाती है। इस पैरामीटर के लिए डिफ़ॉल्ट मान 10 है।
उदाहरण के लिए, हमने CSV फ़ाइल की 3 पंक्तियों में डेटा प्रकारों को दूषित कर दिया है। MAXERRORS पैरामीटर 2 पर सेट है।

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); MAXERRORS पैरामीटर मान से अधिक त्रुटियां होने के कारण संपूर्ण बल्क इंसर्ट ऑपरेशन रद्द कर दिया जाएगा।
यदि हम MAXERRORS पैरामीटर को 4 में बदलते हैं, तो बल्क इंसर्ट स्टेटमेंट इन पंक्तियों को त्रुटियों के साथ छोड़ देगा और सही डेटा संरचित पंक्तियों को सम्मिलित करेगा। बल्क इंसर्ट की प्रक्रिया पूरी हो जाएगी।
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales यदि हम BATCHSIZE और MAXERRORS दोनों का एक साथ उपयोग करते हैं, तो बल्क कॉपी प्रक्रिया पूरे इंसर्ट ऑपरेशन को रद्द नहीं करेगी। यह केवल विभाजित भाग को रद्द कर देगा।
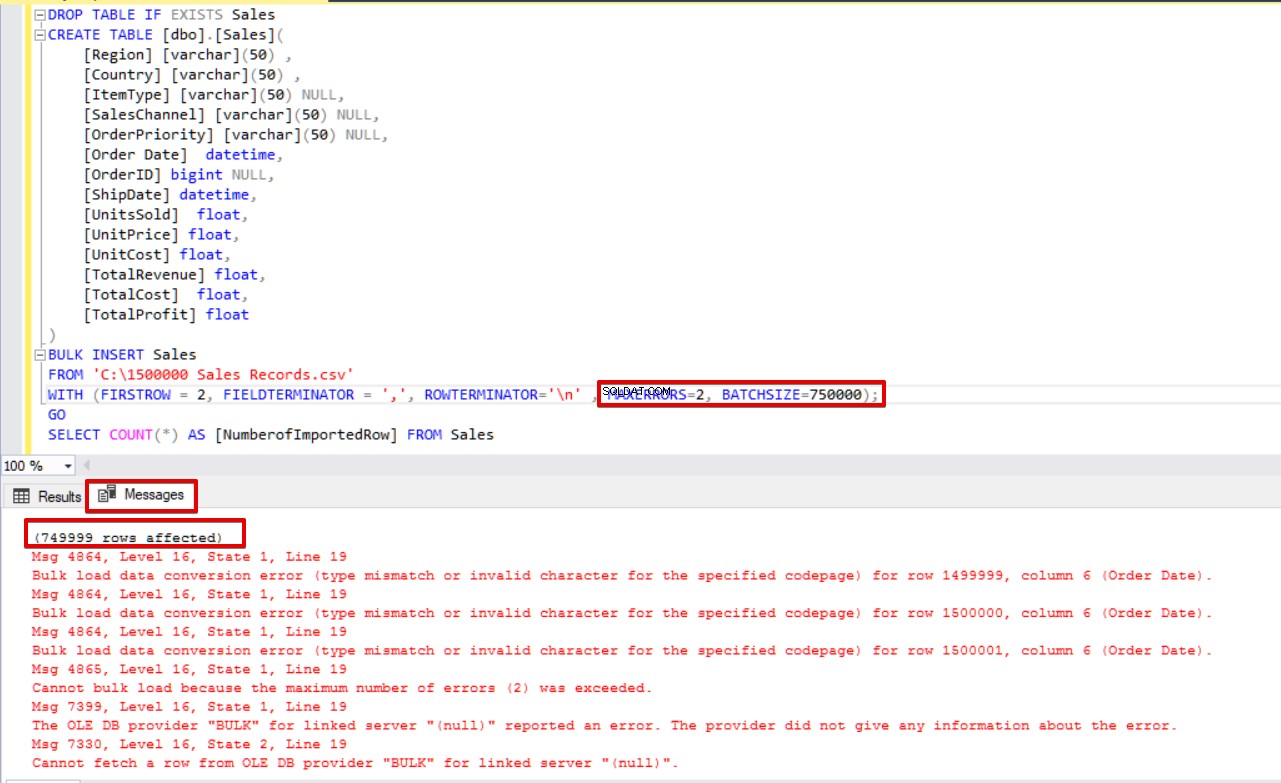
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
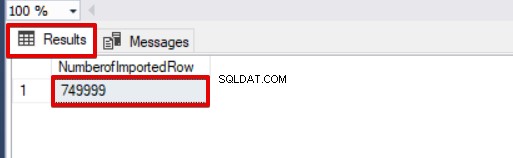
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales नीचे दी गई छवि पर एक नज़र डालें जो स्क्रिप्ट निष्पादन परिणाम दिखाती है:
बल्क इंसर्ट प्रक्रिया के अन्य विकल्प
FIRE_TRIGGERS - बल्क इंसर्ट ऑपरेशन के दौरान गंतव्य तालिका में ट्रिगर सक्षम करें
डिफ़ॉल्ट रूप से, बल्क इंसर्ट प्रक्रिया के दौरान, लक्ष्य तालिका में निर्दिष्ट इंसर्ट ट्रिगर सक्रिय नहीं होते हैं। फिर भी, कुछ स्थितियों में, हम उन्हें सक्षम करना चाह सकते हैं।
समाधान बल्क इंसर्ट स्टेटमेंट में FIRE_TRIGGERS विकल्प का उपयोग कर रहा है। लेकिन कृपया ध्यान दें कि यह बल्क इंसर्ट ऑपरेशन प्रदर्शन को प्रभावित और घटा सकता है। ऐसा इसलिए है क्योंकि ट्रिगर/ट्रिगर डेटाबेस में अलग-अलग संचालन कर सकते हैं।
सबसे पहले, हम FIRE_TRIGGERS पैरामीटर सेट नहीं करते हैं, और बल्क इंसर्ट प्रक्रिया इंसर्ट ट्रिगर को सक्रिय नहीं करेगी। नीचे दी गई टी-एसक्यूएल स्क्रिप्ट देखें:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogजब यह स्क्रिप्ट निष्पादित होती है, तो सम्मिलित ट्रिगर सक्रिय नहीं होगा क्योंकि FIRE_TRIGGERS विकल्प सेट नहीं है।
अब, आइए बल्क इंसर्ट स्टेटमेंट में FIRE_TRIGGERS विकल्प जोड़ें:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 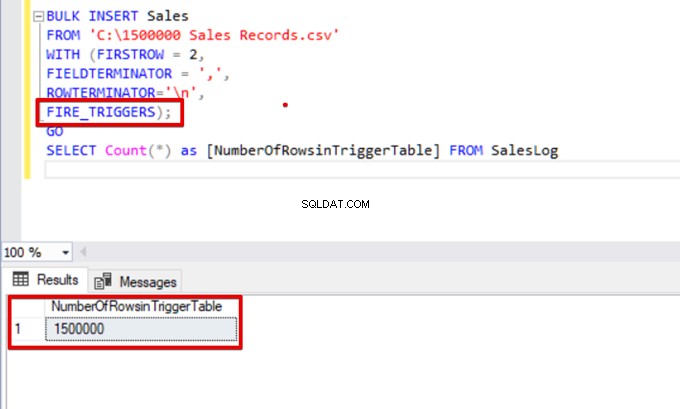
CHECK_CONSTRAINTS - बल्क इंसर्ट ऑपरेशन के दौरान एक चेक बाधा सक्षम करें
जाँच की कमी हमें SQL सर्वर तालिकाओं में डेटा अखंडता को लागू करने की अनुमति देती है। बाधा का उद्देश्य उनके सिंटैक्स विनियमन के अनुसार सम्मिलित, अद्यतन या हटाए गए मानों की जांच करना है। जैसे, NOT NULL बाधा यह प्रदान करती है कि NULL मान किसी निर्दिष्ट कॉलम को संशोधित नहीं कर सकता है।
यहां, हम बाधाओं और बल्क इंसर्ट इंटरैक्शन पर ध्यान केंद्रित करते हैं। डिफ़ॉल्ट रूप से, बल्क इंसर्ट प्रक्रिया के दौरान, किसी भी चेक और विदेशी कुंजी बाधाओं को अनदेखा कर दिया जाता है। लेकिन कुछ अपवाद भी हैं।
Microsoft के अनुसार, “अद्वितीय और प्राथमिक कुंजी प्रतिबंध हमेशा लागू होते हैं। जब एक वर्ण स्तंभ में आयात किया जाता है जिसके लिए NOT NULL बाधा परिभाषित की जाती है, जब पाठ फ़ाइल में कोई मान नहीं होता है, तो बल्क INSERT एक रिक्त स्ट्रिंग सम्मिलित करता है। ”
निम्नलिखित टी-एसक्यूएल स्क्रिप्ट में, हम ऑर्डरडेट कॉलम में एक चेक बाधा जोड़ते हैं, जो 01.01.2016 से अधिक ऑर्डर तिथि को नियंत्रित करता है।
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'नतीजतन, बल्क इंसर्ट प्रक्रिया चेक बाधा नियंत्रण को छोड़ देती है। हालांकि, SQL सर्वर चेक बाधा को अविश्वसनीय के रूप में इंगित करता है:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'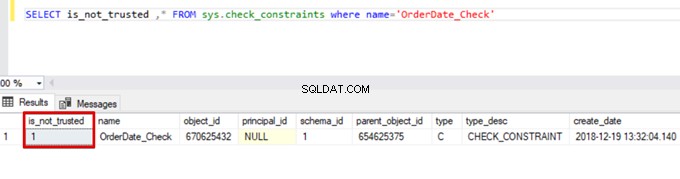
यह मान इंगित करता है कि किसी ने चेक बाधा को छोड़ कर इस कॉलम में कुछ डेटा डाला या अपडेट किया है। साथ ही, इस कॉलम में उस बाधा के संबंध में असंगत डेटा हो सकता है।
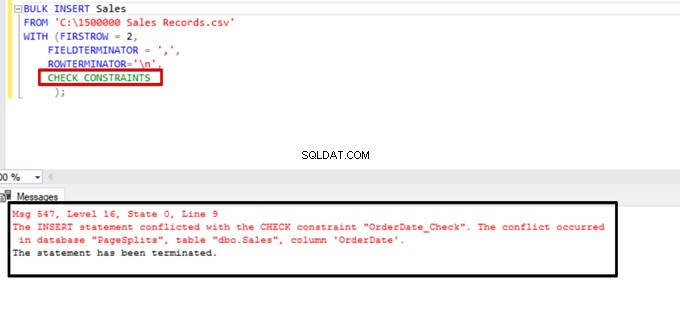
CHECK_CONSTRAINTS विकल्प के साथ बल्क इंसर्ट स्टेटमेंट को निष्पादित करने का प्रयास करें। परिणाम सीधा है:चेक बाधा अनुचित डेटा के कारण एक त्रुटि लौटाती है।
TABLOCK - एक गंतव्य तालिका में एकाधिक थोक प्रविष्टियों में प्रदर्शन बढ़ाएं
SQL सर्वर में लॉकिंग तंत्र का प्राथमिक उद्देश्य डेटा अखंडता की रक्षा करना और सुनिश्चित करना है। SQL सर्वर लॉकिंग आलेख की मुख्य अवधारणा में, आप लॉक तंत्र के बारे में विवरण प्राप्त कर सकते हैं।
हम बल्क इंसर्ट प्रक्रिया लॉकिंग विवरण पर ध्यान केंद्रित करेंगे।
यदि आप TABLELOCK विकल्प के बिना बल्क इंसर्ट स्टेटमेंट चलाते हैं, तो यह लॉक पदानुक्रम के अनुसार पंक्तियों या तालिकाओं के लॉक को प्राप्त कर लेता है। लेकिन कुछ मामलों में, हम एक गंतव्य तालिका के विरुद्ध कई बल्क इंसर्ट प्रक्रियाओं को निष्पादित करना चाह सकते हैं और इस प्रकार ऑपरेशन के समय को कम कर सकते हैं।
सबसे पहले, हम एक साथ दो बल्क इंसर्ट स्टेटमेंट निष्पादित करते हैं और लॉकिंग तंत्र के व्यवहार का विश्लेषण करते हैं। SQL सर्वर प्रबंधन स्टूडियो में दो क्वेरी विंडो खोलें और एक साथ निम्नलिखित बल्क इंसर्ट स्टेटमेंट चलाएँ।
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
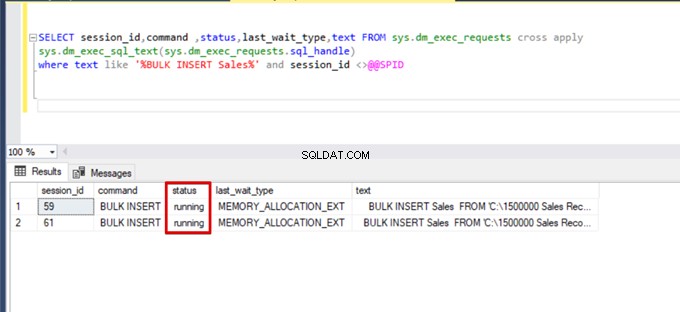
);निम्नलिखित DMV (डायनामिक मैनेजमेंट व्यू) क्वेरी निष्पादित करें - यह बल्क इंसर्ट प्रक्रिया स्थिति की निगरानी करने में मदद करती है:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID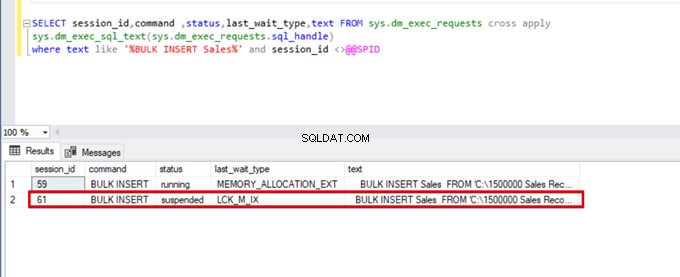
जैसा कि आप उपरोक्त छवि, सत्र 61 में देख सकते हैं, लॉकिंग के कारण बल्क इंसर्ट प्रक्रिया की स्थिति निलंबित है। यदि हम समस्या की पुष्टि करते हैं, तो सत्र 59 बल्क इंसर्ट डेस्टिनेशन टेबल को लॉक कर देता है। फिर, सत्र 61 बल्क इंसर्ट प्रक्रिया को जारी रखने के लिए इस लॉक को जारी करने की प्रतीक्षा करता है।
अब, हम बल्क इंसर्ट स्टेटमेंट में TABLOCK विकल्प जोड़ते हैं और प्रश्नों को निष्पादित करते हैं।
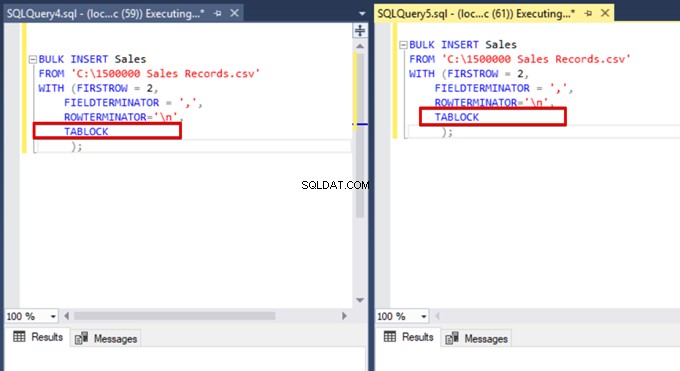
जब हम DMV मॉनिटरिंग क्वेरी को फिर से निष्पादित करते हैं, तो हम कोई निलंबित बल्क इंसर्ट प्रक्रिया नहीं देख सकते हैं क्योंकि SQL सर्वर एक विशेष लॉक प्रकार का उपयोग करता है जिसे बल्क अपडेट लॉक (BU) कहा जाता है। यह लॉक प्रकार एक ही टेबल पर एक साथ कई बल्क इंसर्ट ऑपरेशंस को प्रोसेस करने की अनुमति देता है। यह विकल्प बल्क इंसर्ट प्रक्रिया के कुल समय को भी कम करता है।
जब हम बल्क इंसर्ट प्रक्रिया के दौरान निम्नलिखित क्वेरी को निष्पादित करते हैं, तो हम लॉकिंग विवरण और लॉक प्रकारों की निगरानी कर सकते हैं:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()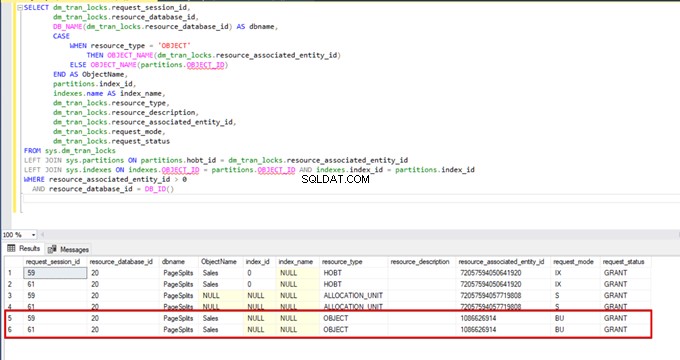
निष्कर्ष
वर्तमान आलेख ने SQL सर्वर में बल्क इंसर्ट ऑपरेशन के सभी विवरणों की खोज की। विशेष रूप से, हमने BULK INSERT कमांड और इसकी सेटिंग्स और विकल्पों का उल्लेख किया है। साथ ही, हमने वास्तविक जीवन की समस्याओं के निकट विभिन्न परिदृश्यों का विश्लेषण किया।
उपयोगी टूल:
dbForge डेटा पंप - SQL डेटाबेस को बाहरी स्रोत डेटा से भरने और सिस्टम के बीच डेटा माइग्रेट करने के लिए एक SSMS ऐड-इन।