विकिपीडिया के अनुसार, "एक बल्क इंसर्ट एक डेटाबेस प्रबंधन प्रणाली द्वारा डेटाबेस तालिका में डेटा की कई पंक्तियों को लोड करने के लिए प्रदान की जाने वाली एक प्रक्रिया या विधि है।" यदि हम इस स्पष्टीकरण को BULK INSERT कथन के अनुसार समायोजित करते हैं, तो बल्क इंसर्ट बाहरी डेटा फ़ाइलों को SQL सर्वर में आयात करने की अनुमति देता है। मान लें कि हमारे संगठन में 1.500.000 पंक्तियों की एक CSV फ़ाइल है और हम इस फ़ाइल को SQL सर्वर में किसी विशेष तालिका में आयात करना चाहते हैं, इसलिए हम SQL सर्वर में BULK INSERT कथन का आसानी से उपयोग कर सकते हैं। निश्चित रूप से, हम इस सीएसवी फ़ाइल आयात प्रक्रिया को संभालने के लिए कई आयात पद्धतियां पा सकते हैं, उदा। हम bcp का उपयोग कर सकते हैं (b ulk c opy p rogram), SQL सर्वर आयात और निर्यात विज़ार्ड या SQL सर्वर एकीकरण सेवा पैकेज। हालाँकि, BULK INSERT कथन अन्य पद्धतियों का उपयोग करने की तुलना में बहुत तेज़ और मजबूत है। बल्क इंसर्ट स्टेटमेंट का एक अन्य लाभ यह है कि यह कई पैरामीटर प्रदान करता है जो बल्क इंसर्ट प्रक्रिया की सेटिंग्स को निर्धारित करने में मदद करता है।
सबसे पहले, हम एक बहुत ही बुनियादी नमूना शुरू करेंगे और फिर हम विभिन्न परिष्कृत परिदृश्यों से गुजरेंगे।
तैयारी
नमूने शुरू करने से पहले, हमें एक नमूना सीएसवी फ़ाइल की आवश्यकता है। इसलिए, हम एक्सेल वेबसाइट के लिए ई से एक नमूना सीएसवी फ़ाइल डाउनलोड करेंगे, जहां आप एक अलग पंक्ति संख्या के साथ विभिन्न नमूना सीएसवी फाइलें पा सकते हैं। आप लेख के अंत में लिंक पा सकते हैं। हमारे परिदृश्यों में, हम 1.500,000 बिक्री रिकॉर्ड का उपयोग करेंगे। एक ज़िप फ़ाइल डाउनलोड करें और फिर CSV फ़ाइल को अनज़िप करें, और इसे अपने स्थानीय ड्राइव में रखें।

सीएसवी फ़ाइल को SQL सर्वर तालिका में आयात करें
परिदृश्य-1:गंतव्य और CSV फ़ाइल में समान संख्या में स्तंभ हैं
इस पहले परिदृश्य में, हम CSV फ़ाइल को सबसे सरल रूप में गंतव्य तालिका में आयात करेंगे। मैंने अपनी नमूना CSV फ़ाइल को C:ड्राइव पर रखा और अब हम एक तालिका बनाएंगे जिसे हम CSV फ़ाइल से डेटा आयात करेंगे।
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
निम्न बल्क INSERT कथन CSV फ़ाइल को विक्रय तालिका में आयात करता है।
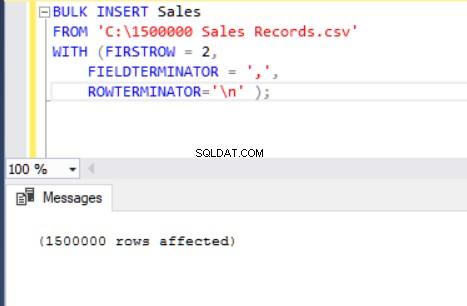
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
अब, हम उपरोक्त बल्क इंसर्ट स्टेटमेंट के मापदंडों की व्याख्या करेंगे।
FIRSTROW पैरामीटर इन्सर्ट स्टेटमेंट के शुरुआती बिंदु को निर्दिष्ट करता है। नीचे दिए गए उदाहरण में, हम कॉलम हेडर को छोड़ना चाहते हैं, इसलिए हम इस पैरामीटर को 2 पर सेट करते हैं।

FIELDTERMINATOR उस वर्ण को परिभाषित करता है जो फ़ील्ड को एक दूसरे से अलग करता है। SQL सर्वर प्रत्येक फ़ील्ड को इस तरह से पहचानता है। ROWTERMINATOR FIELDTERMINATOR से बहुत अलग नहीं है। यह पंक्तियों के पृथक्करण चरित्र को परिभाषित करता है। नमूना CSV फ़ाइल में, फ़ील्डटर्मिनेटर बहुत स्पष्ट है और यह एक अल्पविराम (,) है। लेकिन हम एक फील्ड टर्मिनेटर का पता कैसे लगा सकते हैं? CSV फ़ाइल को Notepad++ में खोलें और फिर View->Show Symbol->Show All Charters पर नेविगेट करें, और फिर प्रत्येक फ़ील्ड के अंत में CRLF वर्णों का पता लगाएं।
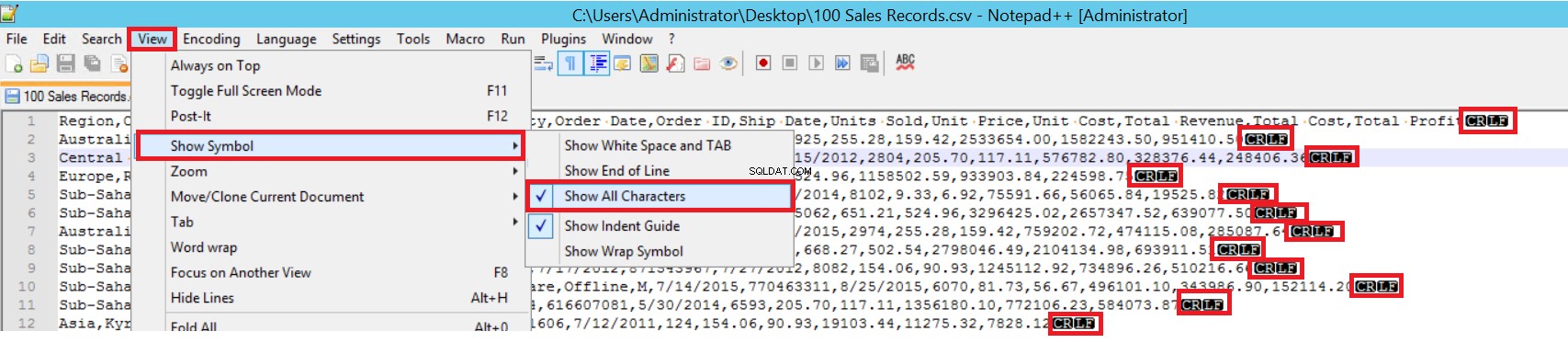
सीआर =कैरिज रिटर्न और एलएफ =लाइन फीड। उनका उपयोग टेक्स्ट फ़ाइल में लाइन ब्रेक को चिह्नित करने के लिए किया जाता है और यह बल्क इंसर्ट स्टेटमेंट में "\n" कैरेक्टर द्वारा दर्शाया जाता है।
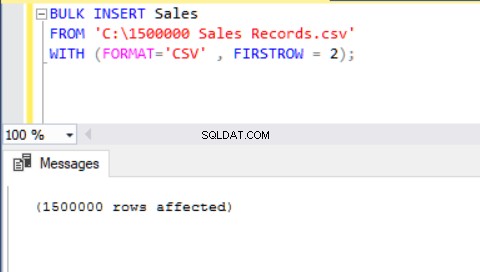
एक CSV फ़ाइल को बल्क इंसर्ट की सहायता से तालिका में आयात करने का एक अन्य तरीका FORMAT पैरामीटर का उपयोग करना है। कृपया ध्यान दें कि FORMAT पैरामीटर केवल SQL Server 2017 और बाद के संस्करणों में उपलब्ध है।
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
अब हम दूसरे परिदृश्य का विश्लेषण करेंगे।
परिदृश्य-2:गंतव्य तालिका में CSV फ़ाइल की तुलना में अधिक स्तंभ हैं
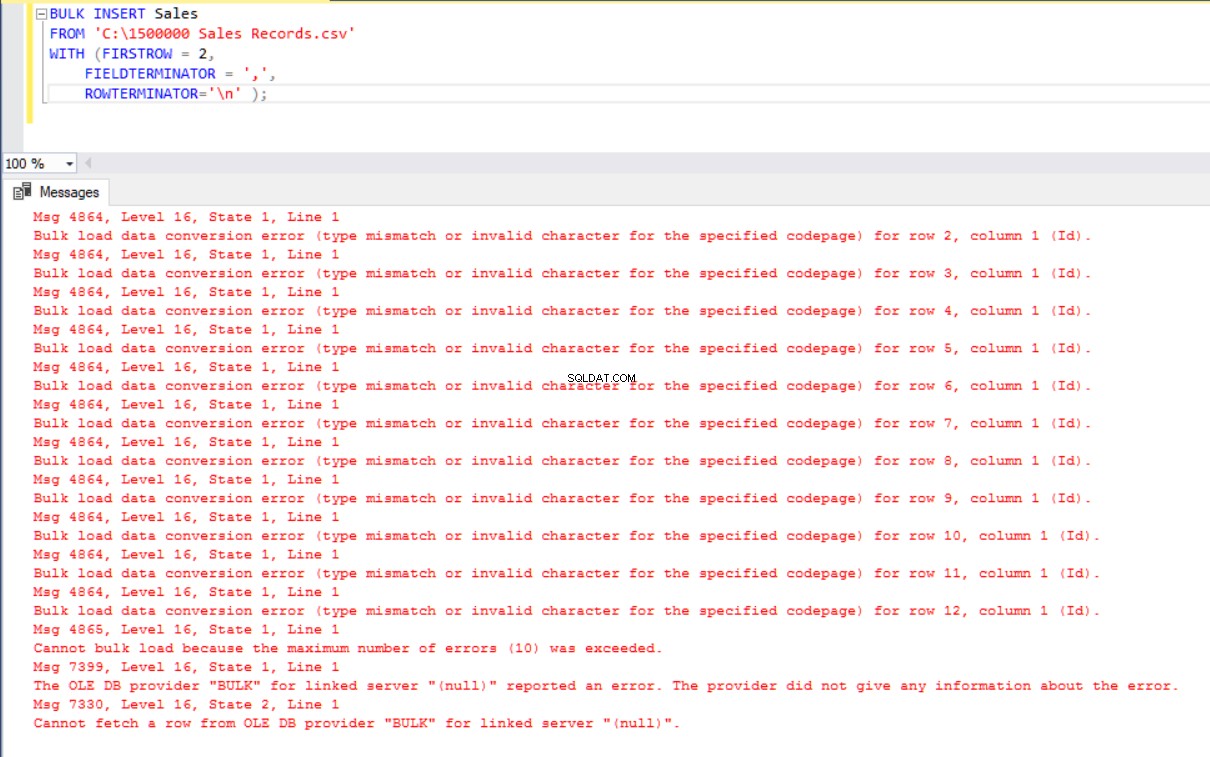
इस परिदृश्य में, हम बिक्री तालिका में प्राथमिक कुंजी जोड़ देंगे और यह मामला समानता कॉलम मैपिंग को तोड़ देता है। अब, हम प्राथमिक कुंजी के साथ बिक्री तालिका बनाएंगे, बल्क इंसर्ट कमांड के माध्यम से CSV फ़ाइल आयात करने का प्रयास करेंगे, और फिर हमें एक त्रुटि मिलेगी।
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
इस त्रुटि को दूर करने के लिए, हम CSV फ़ाइल में मैपिंग कॉलम के साथ बिक्री तालिका का एक दृश्य बनाएंगे और इस दृश्य पर CSV डेटा को बिक्री तालिका में आयात करेंगे।
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); परिदृश्य-3:CSV फ़ाइल को छोटे बैच आकार में कैसे अलग और लोड करें?
SQL सर्वर बल्क इंसर्ट ऑपरेशन के दौरान लॉक टू डेस्टिनेशन टेबल प्राप्त करता है। डिफ़ॉल्ट रूप से, यदि आप BATCHSIZE पैरामीटर सेट नहीं करते हैं, तो SQL सर्वर एक लेनदेन खोलता है और इस लेनदेन में संपूर्ण CSV डेटा सम्मिलित करता है। हालाँकि, यदि आप BATCHSIZE पैरामीटर सेट करते हैं, तो SQL सर्वर CSV डेटा को इस पैरामीटर मान के अनुसार विभाजित करता है। निम्नलिखित नमूने में, हम संपूर्ण CSV डेटा को प्रत्येक 300,000 पंक्तियों के कई सेटों में विभाजित करेंगे। इस प्रकार डेटा 5 बार आयात किया जाएगा।
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
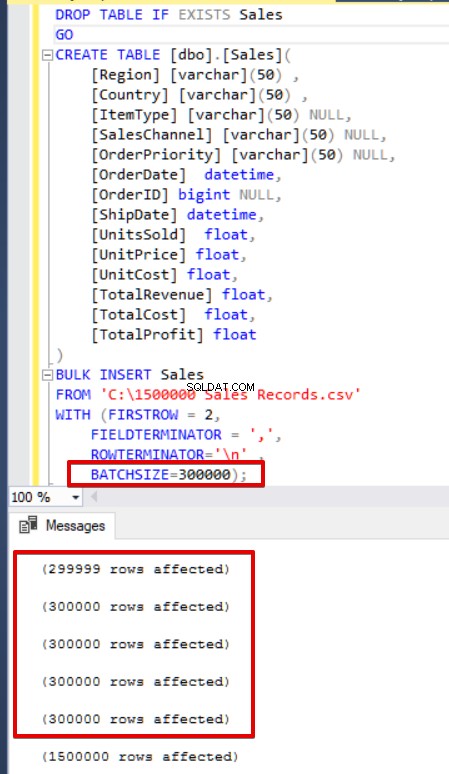
यदि आपके बल्क इंसर्ट स्टेटमेंट में बैच साइज़ (BATCHSIZE) पैरामीटर शामिल नहीं है, तो एक त्रुटि होगी, और SQL सर्वर पूरी बल्क इंसर्ट प्रक्रिया को रोलबैक करेगा। दूसरी ओर, यदि आप बैच आकार पैरामीटर को बल्क इंसर्ट स्टेटमेंट पर सेट करते हैं, तो SQL सर्वर केवल इस विभाजित भाग को रोलबैक करेगा जहाँ त्रुटि हुई थी। इस पैरामीटर के लिए कोई इष्टतम या सर्वोत्तम मान नहीं है क्योंकि इस पैरामीटर मान को आपके डेटाबेस सिस्टम आवश्यकताओं के अनुसार बदला जा सकता है।
परिदृश्य-4:कैसे रद्द करें त्रुटि मिलने पर आयात प्रक्रिया?
कुछ बल्क कॉपी परिदृश्यों में, यदि कोई त्रुटि होती है, तो हम या तो बल्क कॉपी प्रक्रिया को रद्द करना चाहते हैं या प्रक्रिया को जारी रखना चाहते हैं। MAXERRORS पैरामीटर हमें त्रुटियों की अधिकतम संख्या निर्दिष्ट करने की अनुमति देता है। यदि बल्क इंसर्ट प्रक्रिया इस अधिकतम त्रुटि मान तक पहुँच जाती है, तो बल्क इम्पोर्ट ऑपरेशन रद्द कर दिया जाएगा और रोलबैक किया जाएगा। इस पैरामीटर के लिए डिफ़ॉल्ट मान 10 है।
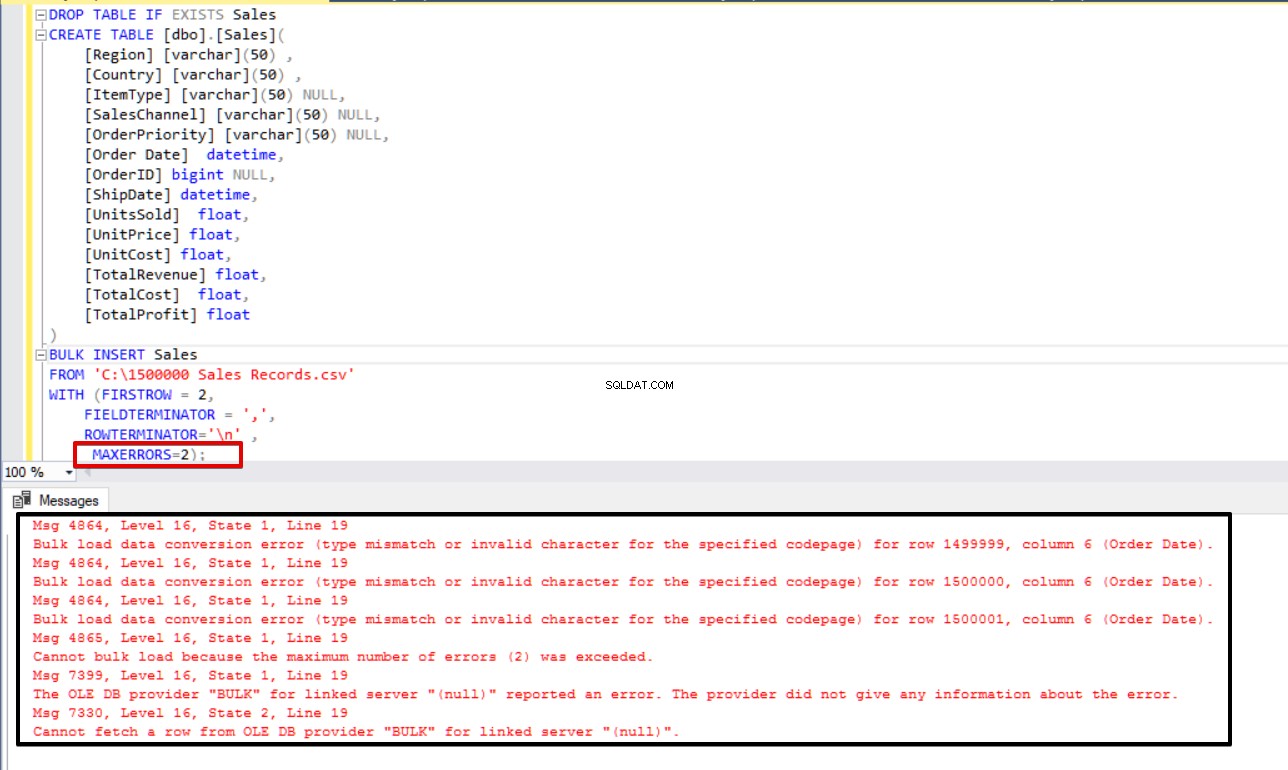
निम्नलिखित उदाहरण में, हम जानबूझकर CSV फ़ाइल की 3 पंक्तियों में डेटा प्रकार को दूषित करेंगे और MAXERRORS पैरामीटर को 2 पर सेट करेंगे। परिणामस्वरूप, संपूर्ण बल्क इंसर्ट ऑपरेशन रद्द कर दिया जाएगा क्योंकि त्रुटि संख्या अधिकतम त्रुटि पैरामीटर से अधिक है।

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
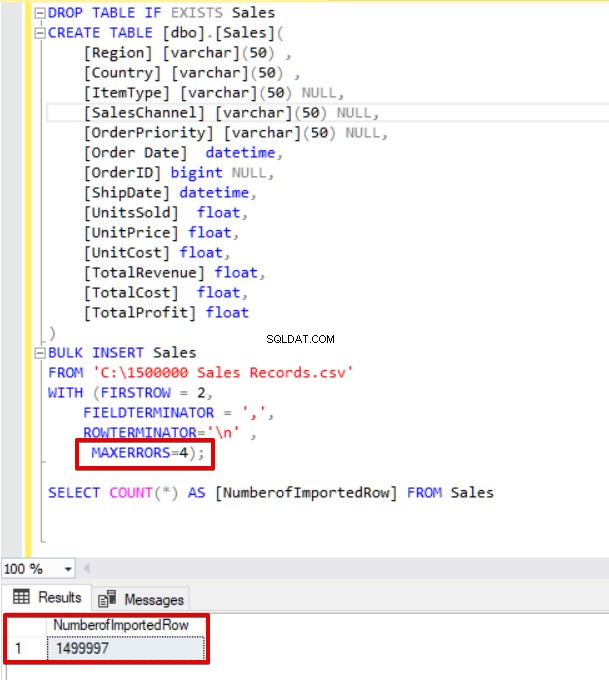
अब हम अधिकतम त्रुटि पैरामीटर को 4 में बदल देंगे। परिणामस्वरूप, बल्क इंसर्ट स्टेटमेंट इन पंक्तियों को छोड़ देगा और उचित डेटा संरचित पंक्तियों को सम्मिलित करेगा, और बल्क इंसर्ट प्रक्रिया को पूरा करेगा।
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
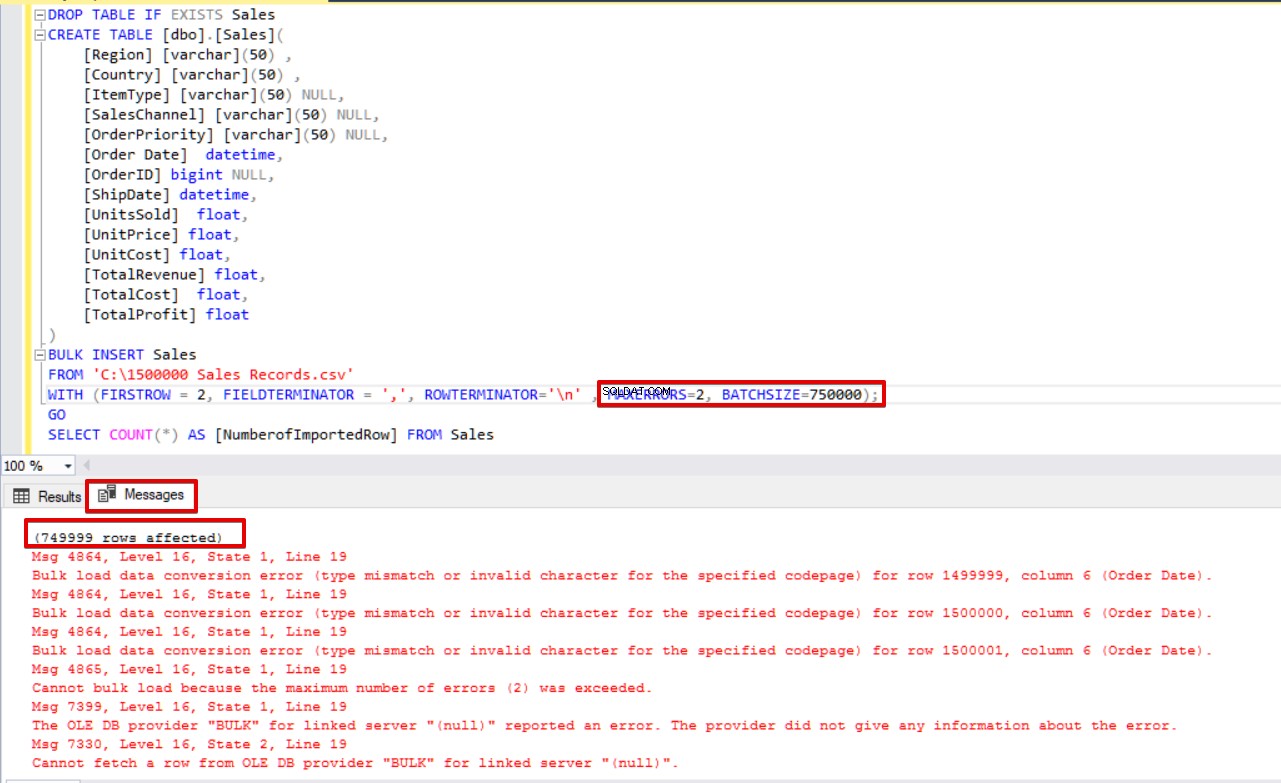
इसके अलावा, यदि हम एक ही समय में बैच आकार और अधिकतम त्रुटि पैरामीटर दोनों का उपयोग करते हैं, तो बल्क कॉपी प्रक्रिया पूरे इंसर्ट ऑपरेशन को रद्द नहीं करेगी, यह केवल विभाजित भाग को रद्द कर देगी।
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
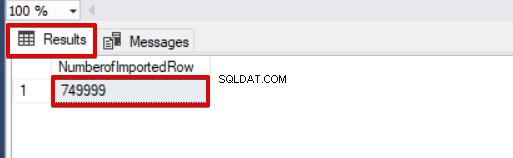
इस लेख श्रृंखला के इस पहले भाग में, हमने SQL सर्वर में बल्क इंसर्ट ऑपरेशन का उपयोग करने की मूल बातों पर चर्चा की और कई परिदृश्यों का विश्लेषण किया जो वास्तविक जीवन के मुद्दों के करीब हैं।
SQL सर्वर बल्क इंसर्ट - भाग 2
उपयोगी लिंक:
बल्क इंसर्ट
एक्सेल के लिए ई - नमूना सीएसवी फ़ाइलें / परीक्षण के लिए डेटा सेट (1.5 मिलियन रिकॉर्ड तक)
नोटपैड++ डाउनलोड
उपयोगी टूल:
dbForge डेटा पंप - SQL डेटाबेस को बाहरी स्रोत डेटा से भरने और सिस्टम के बीच डेटा माइग्रेट करने के लिए एक SSMS ऐड-इन।



