अब से तीन साल पहले, मैंने स्प्लिटिंग स्ट्रिंग्स पर तीन-भाग की श्रृंखला पोस्ट की थी:
- स्ट्रिंग्स को सही तरीके से विभाजित करें - या अगला सबसे अच्छा तरीका
- स्प्लिटिंग स्ट्रिंग्स:एक फॉलो-अप
- स्प्लिटिंग स्ट्रिंग्स :अब कम टी-एसक्यूएल के साथ
फिर जनवरी में वापस, मैंने थोड़ी अधिक विस्तृत समस्या पर विचार किया:
- स्ट्रिंग विभाजन / संयोजन विधियों की तुलना करना
पूरे समय में, मेरा निष्कर्ष यही रहा है:T-SQL में ऐसा करना बंद करें . सीएलआर का उपयोग करें या, बेहतर अभी तक, अपनी प्रक्रियाओं में डेटाटेबल्स जैसे डेटाटेबल्स को अपनी प्रक्रियाओं में टेबल-वैल्यू पैरामीटर (टीवीपी) से पास करें, सभी स्ट्रिंग निर्माण और डीकंस्ट्रक्शन से पूरी तरह से परहेज करें - जो वास्तव में समाधान का हिस्सा है जो प्रदर्शन समस्याओं का कारण बनता है।
और फिर SQL Server 2016 साथ आया...
जब RC0 जारी किया गया था, तो बिना किसी धूमधाम के एक नया फ़ंक्शन प्रलेखित किया गया था:STRING_SPLIT . एक त्वरित उदाहरण:
चुनें * STRING_SPLIT से ('ए, बी, सीडी', ','); /* परिणाम:मान -------- a b cd*/ इसने डेव बैलेंटाइन सहित कुछ सहयोगियों की नज़रें खींचीं, जिन्होंने मुख्य विशेषताओं के बारे में लिखा था - लेकिन प्रदर्शन की तुलना पर मुझे इनकार करने का पहला अधिकार देने के लिए पर्याप्त था।
यह ज्यादातर एक अकादमिक अभ्यास है, क्योंकि सुविधा के पहले पुनरावृत्ति में सीमाओं के एक बड़े सेट के साथ, यह शायद बड़ी संख्या में उपयोग के मामलों के लिए संभव नहीं है। यहां उन टिप्पणियों की सूची दी गई है जो डेव और मैंने की हैं, जिनमें से कुछ निश्चित परिदृश्यों में डील-ब्रेकर हो सकती हैं:
- फ़ंक्शन के लिए आवश्यक है कि डेटाबेस संगतता स्तर 130 में हो;
- यह केवल एकल-वर्ण सीमांकक स्वीकार करता है;
- आउटपुट कॉलम जोड़ने का कोई तरीका नहीं है (जैसे एक कॉलम जो स्ट्रिंग के भीतर क्रमिक स्थिति दर्शाता है);
- संबंधित, छँटाई को नियंत्रित करने का कोई तरीका नहीं है - केवल विकल्प मनमाने और वर्णानुक्रम में हैं
ORDER BY value;
- संबंधित, छँटाई को नियंत्रित करने का कोई तरीका नहीं है - केवल विकल्प मनमाने और वर्णानुक्रम में हैं
- अब तक, यह हमेशा 50 आउटपुट पंक्तियों का अनुमान लगाता है;
- DML के लिए इसका उपयोग करते समय, कई मामलों में आपको एक टेबल स्पूल (Hallowe'en सुरक्षा के लिए) मिलेगी;
NULLइनपुट एक खाली परिणाम की ओर ले जाता है;- विधियों को नीचे धकेलने का कोई तरीका नहीं है, जैसे लगातार सीमांकक के कारण डुप्लीकेट या खाली स्ट्रिंग को हटाना;
- तथ्य के बाद तक आउटपुट मानों के विरुद्ध संचालन करने का कोई तरीका नहीं है (उदाहरण के लिए, कई विभाजन कार्य
LTRIM/RTRIMकरते हैं या आपके लिए स्पष्ट रूपांतरण –STRING_SPLITसभी बदसूरतों को पीछे छोड़ देता है, जैसे प्रमुख स्थान)।
तो खुले में उन सीमाओं के साथ, हम कुछ प्रदर्शन परीक्षण के लिए आगे बढ़ सकते हैं। कवर के तहत सीएलआर का लाभ उठाने वाले अंतर्निहित कार्यों के साथ माइक्रोसॉफ्ट के ट्रैक रिकॉर्ड को देखते हुए (खांसी FORMAT() खांसी ), मुझे इस बात पर संदेह था कि क्या यह नया फ़ंक्शन मेरे द्वारा अब तक परीक्षण किए गए सबसे तेज़ तरीकों के करीब आ सकता है।
आइए स्ट्रिंग स्प्लिटर्स का उपयोग संख्याओं के कॉमा-सेपरेटेड स्ट्रिंग्स को अलग करने के लिए करें, इस तरह हमारा नया दोस्त JSON साथ आ सकता है और खेल भी सकता है। और हम कहेंगे कि कोई भी सूची 8,000 वर्णों से अधिक नहीं हो सकती है, इसलिए कोई MAX नहीं है प्रकारों की आवश्यकता होती है, और चूंकि वे संख्याएं हैं, इसलिए हमें यूनिकोड जैसी किसी विदेशी चीज़ से निपटने की आवश्यकता नहीं है।
सबसे पहले, आइए अपने कार्यों का निर्माण करें, जिनमें से कई मैंने ऊपर के पहले लेख से अनुकूलित किए हैं। मैंने एक जोड़े को छोड़ दिया जो मुझे नहीं लगता था कि प्रतिस्पर्धा करेंगे; मैं इसे पाठक पर परीक्षण करने के लिए एक अभ्यास के रूप में छोड़ दूंगा।
संख्या तालिका
इसे फिर से कुछ सेटअप की आवश्यकता है, लेकिन हमारे द्वारा लगाई गई कृत्रिम सीमाओं के कारण यह एक बहुत छोटी तालिका हो सकती है:
नोकाउंट चालू करें; DECLARE @UpperLimit INT =8000;;एन एएस के साथ (सेलेक्ट x =ROW_NUMBER() ओवर (एस1 द्वारा ऑर्डर करें। @UpperLimit;GOCREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number);
फिर समारोह:
CREATE FUNCTION dbo.SplitStrings_Numbers(@List varchar(8000), @Delimiter char(1))SCHEMABINDINGAS रिटर्न के साथ रिटर्न टेबल (चुनें [मान] =सबस्ट्रिंग (@ सूची, [संख्या], CHARINDEX(@Delimiter, @List) + @Delimiter, [Number]) - [Number]) dbo.Numbers से जहां नंबर <=LEN(@List) और SubSTRING(@Delimiter + @List, [Number], 1) =@Delimiter);
JSON
स्टोरेज इंजन टीम द्वारा पहले बताए गए दृष्टिकोण के आधार पर, मैंने OPENJSON के आसपास एक समान आवरण बनाया , बस ध्यान दें कि इस मामले में सीमांकक को अल्पविराम होना चाहिए, या मूल फ़ंक्शन में मान पास करने से पहले आपको कुछ भारी शुल्क स्ट्रिंग प्रतिस्थापन करना होगा:
CREATE FUNCTION dbo.SplitStrings_JSON(@List varchar(8000), @Delimiter char(1) - अनदेखा किया गया लेकिन स्वचालित परीक्षण को आसान बना दिया) SCHEMABINDINGAS रिटर्न के साथ रिटर्न टेबल (OPENJSON से चयन मूल्य (CHAR(91) + @List + CHAR(93) ));
CHAR(91)/CHAR(93) स्वरूपण संबंधी समस्याओं के कारण क्रमशः [ और ] की जगह ले रहे हैं।
XML
CREATE FUNCTION dbo.SplitStrings_XML(@List varchar(8000), @Delimiter char(1))SCHEMABINDINGAS RETURN के साथ रिटर्न टेबल (चुनें [value] =y.i.value('(./text())[1]', 'varchar(8000)') FROM (सेलेक्ट x =CONVERT(XML, '' + REPLACE(@List, @Delimiter, '') + '').query ('.') ) एक क्रॉस के रूप में x.nodes('i') AS y(i)); सीएलआर
मैंने एक बार फिर से एडम मचानिक के भरोसेमंद विभाजन कोड को लगभग सात साल पहले उधार लिया था, भले ही यह यूनिकोड का समर्थन करता हो, MAX प्रकार, और बहु-वर्ण सीमांकक (और वास्तव में, क्योंकि मैं फ़ंक्शन कोड के साथ बिल्कुल भी गड़बड़ नहीं करना चाहता, यह हमारे इनपुट स्ट्रिंग्स को 8,000 के बजाय 4,000 वर्णों तक सीमित करता है):
CREATE FUNCTION dbo.SplitStrings_CLR(@List nvarchar(MAX), @Delimiter nvarchar(255))RETURNS TABLE (value nvarchar(4000))EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi;
STRING_SPLIT
केवल एकरूपता के लिए, मैंने STRING_SPLIT . के आसपास एक आवरण लगाया है :
CREATE FUNCTION dbo.SplitStrings_Native(@List varchar(8000), @Delimiter char(1))SCHEMABINDINGAS RETURN के साथ रिटर्न टेबल (STRING_SPLIT(@List, @Delimiter) से चयन मान);
स्रोत डेटा और विवेक जांच
मैंने इस तालिका को कार्यों के लिए इनपुट स्ट्रिंग्स के स्रोत के रूप में काम करने के लिए बनाया है:
टेबल डीबीओ बनाएं। सोर्सटेबल (रोउनम इंट पहचान (1,1) प्राथमिक कुंजी, स्ट्रिंगवैल्यू वर्कर (8000));;एक्स एएस के साथ (सेलेक्ट टॉप (60000) x =स्टफ ((सेलेक्ट टॉप (ABS(o.[object_id]% 20)) ',' + CONVERT(varchar(12), c.[object_id]) sys.all_columns से एएस सी जहां सी। [ऑब्जेक्ट_आईडी] <ओ। [ऑब्जेक्ट_आईडी] NEWID द्वारा ऑर्डर (''), एक्सएमएल पाथ (''), टाइप) के लिए। वैल्यू (एन' (./ टेक्स्ट ()) [1]', एन'वर्कर ( 8000)'),1,1,'') sys.all_objects से o क्रॉस जॉइन sys.all_objects AS o2 ORDER BY NEWID ()) INSERT dbo.SourceTable(StringValue) सेलेक्ट टॉप (50000) x से x जहां x नहीं है NEWID द्वारा पूर्ण आदेश (); केवल संदर्भ के लिए, मान लें कि 50,000 पंक्तियों ने इसे तालिका में बनाया है, और स्ट्रिंग की औसत लंबाई और प्रति स्ट्रिंग तत्वों की औसत संख्या की जांच करें:
चुनें [मान] =COUNT(*), औसतस्ट्रिंग लम्बाई =औसत (1.0 * एलईएन (स्ट्रिंगवैल्यू)), औसत एलिमेंटकाउंट =औसत (1.0 * एलईएन (स्ट्रिंगवैल्यू) -एलईएन (प्रतिस्थापन (स्ट्रिंगवैल्यू, ',', ''))) ) डीबीओ से। सोर्सटेबल; /* परिणाम:मान AvgStringLength AbgElementCount ------ --------------- --------------- 50000 108.476380 8.911840*/
और अंत में, आइए सुनिश्चित करें कि प्रत्येक फ़ंक्शन किसी दिए गए RowNum . के लिए सही डेटा लौटाता है , इसलिए हम केवल एक यादृच्छिक रूप से चुनेंगे और प्रत्येक विधि से प्राप्त मानों की तुलना करेंगे। आपके परिणाम निश्चित रूप से भिन्न होंगे।
dbo से f.value चुनें।निश्चित रूप से, सभी फ़ंक्शन अपेक्षित रूप से काम करते हैं (सॉर्टिंग संख्यात्मक नहीं है; याद रखें, फ़ंक्शन आउटपुट स्ट्रिंग्स):
प्रत्येक फ़ंक्शन से आउटपुट का नमूना सेट
प्रदर्शन परीक्षण
SYSDATETIME (); GODECLARE @x VARCHAR (8000) का चयन करें; dbo से @x =f.value चुनें। सोर्सटेबल के रूप में क्रॉस लागू करें dbo.SplitStrings_/* विधि */(s.StringValue,',') AS f;गो 100चुनें SYSDATETIME ();मैंने उपरोक्त कोड को प्रत्येक विधि के लिए 10 बार चलाया, और प्रत्येक के लिए औसत समय निकाला। और यहीं से मेरे लिए सरप्राइज आया। मूल
STRING_SPLIT. में सीमाओं को देखते हुए समारोह, मेरी धारणा यह थी कि इसे जल्दी से एक साथ फेंक दिया गया था, और यह प्रदर्शन उस पर भरोसा करेगा। लड़का मेरी अपेक्षा से भिन्न परिणाम था:
अन्य विधियों की तुलना में STRING_SPLIT की औसत अवधि
अपडेट 2016-03-20
लार्स से नीचे दिए गए प्रश्न के आधार पर, मैंने कुछ बदलावों के साथ फिर से परीक्षण चलाए:
- मैंने परीक्षण के दौरान CPU प्रोफ़ाइल को कैप्चर करने के लिए SQL संतरी प्रदर्शन सलाहकार के साथ अपने उदाहरण की निगरानी की;
- मैंने प्रत्येक बैच के बीच सत्र-स्तरीय प्रतीक्षा आँकड़े कैप्चर किए;
- मैंने बैचों के बीच विलंब डाला ताकि गतिविधि प्रदर्शन सलाहकार डैशबोर्ड पर स्पष्ट रूप से भिन्न हो।
मैंने प्रतीक्षा स्थिति जानकारी कैप्चर करने के लिए एक नई तालिका बनाई:
टेबल डीबीओ बनाएं। समय (डीटी डेटाटाइम, टेस्ट वर्कर (64), प्वाइंट वर्कर (64), सेशन_आईडी स्मालिंट, वेट_टाइप नवरचर (60), वेट_टाइम_एमएस बिगिंट,);
फिर प्रत्येक परीक्षण के लिए कोड इस में बदल गया:
विलंब प्रतीक्षा करें '00:00:30'; DECLARE @d DATETIME =SYSDATETIME (); INSERT dbo.Timings(dt, test, point, wait_type, Wait_time_ms) सेलेक्ट @d, test =/* 'method' */, point ='Start', Wait_type, Wait_time_msFROM sys.dm_exec_session_wait_stats जहां से session_id =@@SPID; GO DECLARE @x VARCHAR(8000); dbo से @x =f.value चुनें। सोर्सटेबल के रूप में क्रॉस लागू dbo.SplitStrings_/* विधि */(s.StringValue, ',') AS fGO 100 DECLARE @d DATETIME =SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, Wait_time_ms) सेलेक्ट @d, /* 'method' */, 'End', Wait_type, Wait_time_msFROM sys.dm_exec_session_wait_stats जहां से session_id =@@SPID;
मैंने परीक्षण चलाया और फिर निम्नलिखित प्रश्नों को चलाया:
-- पुष्टि करें कि समय पिछले परीक्षणों के समान बॉलपार्क में था चयन परीक्षण, DATEDIFF(SECOND, MIN(dt), MAX(dt)) dbo से। टाइमिंग विद (NOLOCK) GROUP BY Test ORDER BY 2 DESC; - प्रदर्शन सलाहकार डैशबोर्ड पर लागू करने के लिए विंडो निर्धारित करें dbo.Timeings से MIN(dt), MAX(dt) चुनें; - प्रत्येक सत्र के लिए पंजीकृत प्रतीक्षा आँकड़े प्राप्त करें चयन परीक्षण, प्रतीक्षा_प्रकार, डेल्टा से (चुनें f.test, rn =RANK() ओवर (f.dt द्वारा f.point आदेश द्वारा विभाजन), f.wait_type, डेल्टा =f.wait_time_ms - COALESCE(s.wait_time_ms, 0) से dbo.Times as f LEFT OUTER JOIN dbo.Times as s ON s.test =f.test और s.wait_type =f.wait_type और s.point ='प्रारंभ' जहां f.point ='एंड') AS x WHERE डेल्टा> 0ORDER BY RN, Delta DESC;
पहली क्वेरी से, समय पिछले परीक्षणों के अनुरूप रहा (मैं उन्हें फिर से चार्ट करूंगा लेकिन इससे कुछ भी नया नहीं होगा)।
दूसरी क्वेरी से, मैं प्रदर्शन सलाहकार डैशबोर्ड पर इस श्रेणी को हाइलाइट करने में सक्षम था, और वहां से प्रत्येक बैच की पहचान करना आसान था:
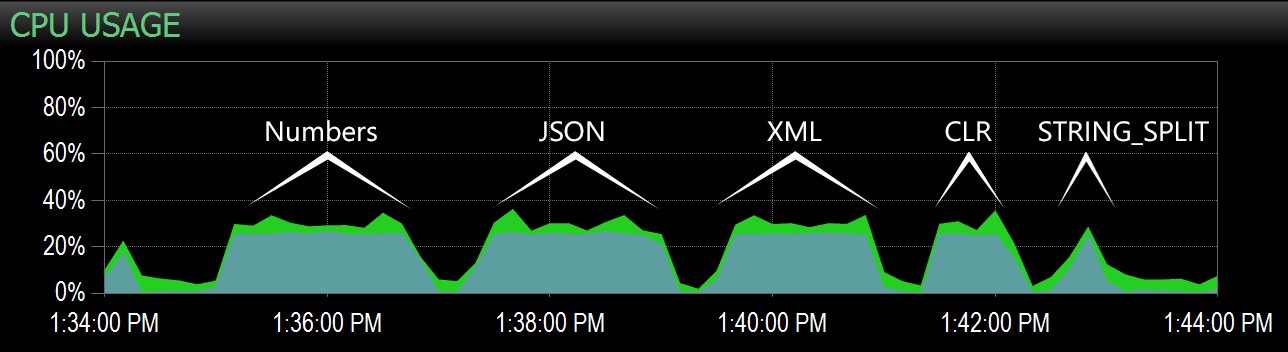 प्रदर्शन सलाहकार डैशबोर्ड पर CPU चार्ट पर कैप्चर किए गए बैच
प्रदर्शन सलाहकार डैशबोर्ड पर CPU चार्ट पर कैप्चर किए गए बैच
स्पष्ट रूप से, STRING_SPLIT . को छोड़कर *सभी विधियाँ* परीक्षण की अवधि के लिए एक एकल कोर आंकी गई (यह एक क्वाड-कोर मशीन है, और सीपीयू लगातार 25% पर था)। यह संभव है कि लार्स उस STRING_SPLIT . के नीचे संकेत कर रहे थे CPU को हथियाने की कीमत पर तेज़ है, लेकिन ऐसा नहीं लगता है कि यह मामला है।
अंत में, तीसरी क्वेरी से, मैं प्रत्येक बैच के बाद निम्नलिखित प्रतीक्षा आँकड़े देख पा रहा था:
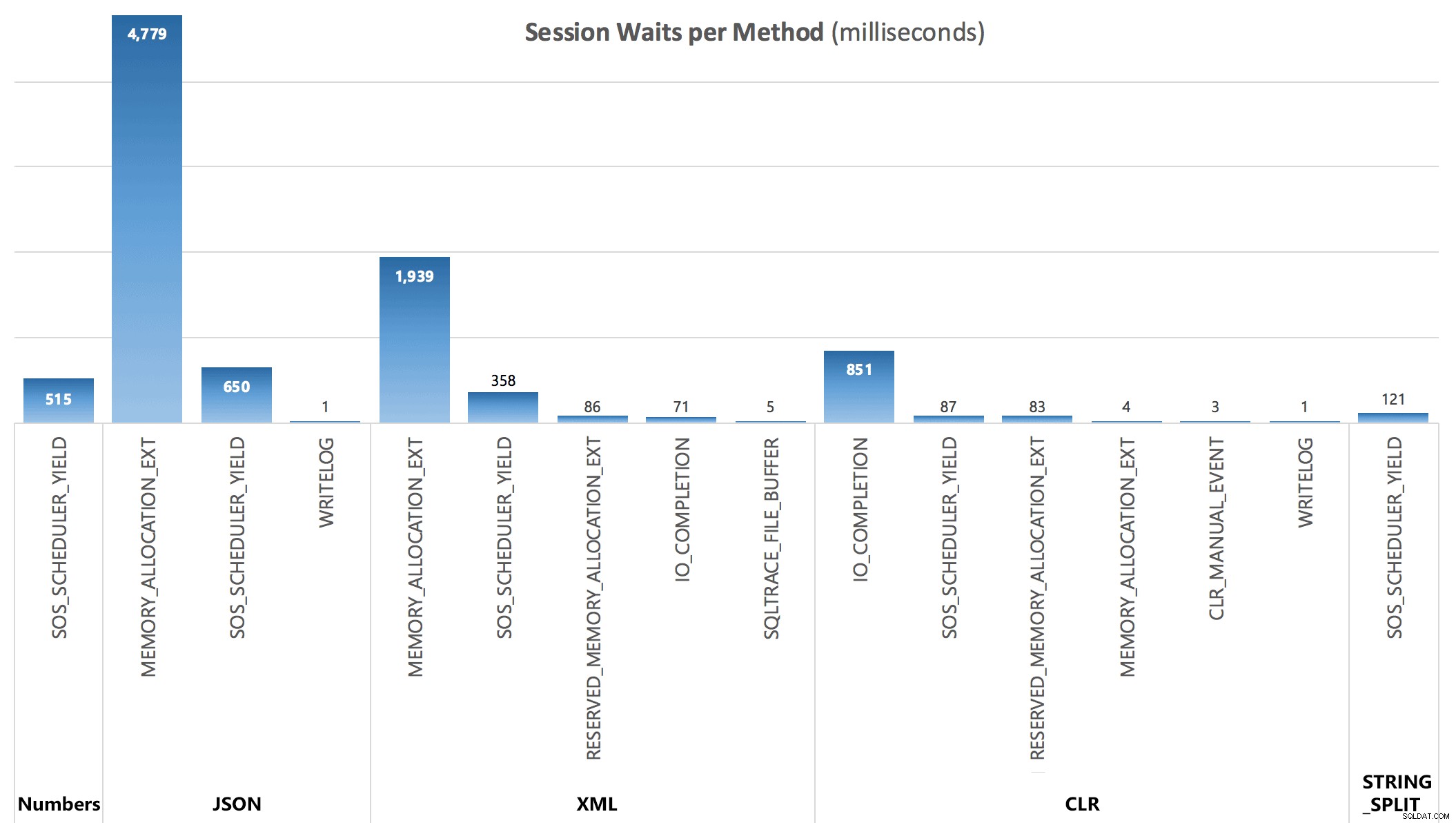 प्रति-सत्र प्रतीक्षा, मिलीसेकंड में
प्रति-सत्र प्रतीक्षा, मिलीसेकंड में
DMV द्वारा कैप्चर की गई प्रतीक्षा पूरी तरह से प्रश्नों की अवधि की व्याख्या नहीं करती है, लेकिन वे यह दिखाने का काम करती हैं कि अतिरिक्त कहां हैं प्रतीक्षा करनी पड़ती है।
निष्कर्ष
जबकि कस्टम सीएलआर अभी भी पारंपरिक टी-एसक्यूएल दृष्टिकोणों पर एक बड़ा लाभ दिखाता है, और इस कार्यक्षमता के लिए जेएसओएन का उपयोग करना एक नवीनता से ज्यादा कुछ नहीं है, STRING_SPLIT स्पष्ट विजेता था - एक मील से। इसलिए, यदि आपको केवल एक स्ट्रिंग को विभाजित करने की आवश्यकता है और इसकी सभी सीमाओं से निपट सकते हैं, तो ऐसा लगता है कि यह मेरी अपेक्षा से कहीं अधिक व्यवहार्य विकल्प है। उम्मीद है कि भविष्य के निर्माण में हम अतिरिक्त कार्यक्षमता देखेंगे, जैसे कि प्रत्येक तत्व की क्रमिक स्थिति को इंगित करने वाला एक आउटपुट कॉलम, डुप्लिकेट और खाली स्ट्रिंग्स को फ़िल्टर करने की क्षमता, और बहु-वर्ण सीमांकक।
मैं दो अनुवर्ती पोस्ट में नीचे कई टिप्पणियों को संबोधित करता हूं:
- SQL सर्वर 2016 में
- STRING_SPLIT() :फ़ॉलो-अप #1 SQL सर्वर 2016 में
- STRING_SPLIT ():फॉलो-अप #2