2015 में ClusterControl 1.2.11 जारी होने के बाद से, MariaDB MaxScale को डेटाबेस लोड बैलेंसर के रूप में समर्थन दिया गया है। पिछले कुछ वर्षों में MaxScale कई समृद्ध सुविधाओं को जोड़ते हुए विकसित और परिपक्व हुआ है। हाल ही में MariaDB MaxScale 2.2 जारी किया गया था और यह प्रतिकृति क्लस्टर विफलता प्रबंधन सहित कई नई सुविधाएँ पेश करता है।
MariaDB MaxScale उच्च उपलब्धता, स्वचालित विफलता, मैन्युअल स्विचओवर, और स्वचालित रीजॉइन के साथ मास्टर/स्लेव परिनियोजन की अनुमति देता है। यदि मास्टर विफल हो जाता है, तो मारियाडीबी मैक्सस्केल स्वचालित रूप से मास्टर के लिए सबसे अद्यतित दास को बढ़ावा दे सकता है। यदि विफल मास्टर को पुनः प्राप्त कर लिया जाता है, तो MariaDB MaxScale इसे नए मास्टर के दास के रूप में स्वचालित रूप से पुन:कॉन्फ़िगर कर सकता है। इसके अलावा, व्यवस्थापक मांग पर मास्टर को बदलने के लिए मैन्युअल स्विचओवर कर सकते हैं।
हमारे पिछले ब्लॉगों में हमने चर्चा की थी कि कैसे क्लस्टरकंट्रोल का उपयोग करके मैक्सस्केल को डिप्लॉय किया जाए और साथ ही डॉकर पर मारियाडीबी मैक्सस्केल को कैसे डिप्लॉय किया जाए। जो लोग अभी तक MariaDB MaxScale से परिचित नहीं हैं, उनके लिए यह MariaDB डेटाबेस सर्वर के लिए एक उन्नत, प्लग-इन, डेटाबेस प्रॉक्सी है। Maxscale क्लाइंट एप्लिकेशन और डेटाबेस सर्वर के बीच बैठता है, क्लाइंट क्वेरी और सर्वर प्रतिक्रियाओं को रूट करता है। यह सर्वर पर भी नज़र रखता है, सर्वर की स्थिति या प्रतिकृति टोपोलॉजी में किसी भी बदलाव को तुरंत नोटिस करता है।
हालांकि मैक्सस्केल अन्य लोड बैलेंसिंग तकनीकों जैसे प्रॉक्सीएसक्यूएल की कुछ विशेषताओं को साझा करता है, यह नया फेलओवर फीचर (जो इसकी निगरानी और ऑटोडिटेक्शन तंत्र का हिस्सा है) बाहर खड़ा है। इस ब्लॉग में हम मैक्सस्केल के इस रोमांचक नए कार्य पर चर्चा करने जा रहे हैं।
MariaDB MaxScale Failover Mechanism का अवलोकन
मास्टर डिटेक्शन
मॉनिटर अब मास्टर सर्वर को अचानक बदलने की संभावना कम है, भले ही किसी अन्य सर्वर में वर्तमान मास्टर की तुलना में अधिक दास हों। DBA वर्तमान मास्टर को केवल-पढ़ने के लिए सेट करके, या मास्टर के डाउन होने पर उसके सभी दासों को हटाकर एक मास्टर के चयन को बाध्य कर सकता है।
मल्टीमास्टर सेटअप में भी, एक समय में केवल एक सर्वर के पास मास्टर स्थिति ध्वज हो सकता है। मल्टीमास्टर समूह के अन्य सर्वरों को रिले मास्टर और स्लेव स्थिति फ़्लैग दिया जाता है।
नया मास्टर स्वतः चयन स्विच करें
स्विचओवर कमांड को अब केवल मॉनिटर इंस्टेंस नाम के साथ पैरामीटर के रूप में कहा जा सकता है। इस मामले में मॉनिटर स्वचालित रूप से प्रचार के लिए एक सर्वर का चयन करेगा।
प्रतिकृति अंतराल का पता लगाना
प्रतिकृति अंतराल माप अब केवल Seconds_Behind_Master पढ़ता है दास की दास स्थिति उत्पादन का क्षेत्र। दास इस मान की गणना बिनलॉग इवेंट में टाइम स्टैम्प की तुलना करके करता है जो दास वर्तमान में दास की अपनी घड़ी में संसाधित कर रहा है। अगर एक गुलाम के पास कई गुलाम कनेक्शन हैं, तो सबसे छोटे अंतराल का उपयोग किया जाता है।
डिस्क स्थान कम होने के बाद स्वचालित स्विचओवर
हाल के मारियाडीबी सर्वर संस्करणों के साथ, मॉनिटर अब बैकएंड पर डिस्क स्थान की जांच कर सकता है और पता लगा सकता है कि सर्वर कम चल रहा है या नहीं। जब ऐसा होता है, तो मॉनिटर को डिस्क स्थान पर मास्टर लो से स्वचालित रूप से स्विचओवर पर सेट किया जा सकता है। दासों को रखरखाव मोड पर भी सेट किया जा सकता है। डिस्क स्थान भी एक कारक है जिस पर विचार किया जाता है कि किस नए मास्टर को बढ़ावा देना है।
अधिक जानकारी के लिए स्विचओवर_ऑन_लो_डिस्क_स्पेस और मेंटेनेंस_ऑन_लो_डिस्क_स्पेस देखें।
प्रतिकृति रीसेट सुविधा
रीसेट-प्रतिकृति मॉनिटर कमांड सभी गुलाम कनेक्शन और बाइनरी लॉग को हटा देता है, और फिर प्रतिकृति सेट करता है। तब उपयोगी होता है जब डेटा सिंक में हो लेकिन gtid नहीं हो।
फेलओवर/स्विचओवर/फिर से शामिल होने में शेड्यूल किए गए ईवेंट हैंडलिंग
इवेंट शेड्यूलर थ्रेड द्वारा लॉन्च किए गए सर्वर इवेंट को अब क्लस्टर संशोधन संचालन के दौरान नियंत्रित किया जाता है। अधिक जानकारी के लिए हैंडल_सर्वर_इवेंट देखें।
बाहरी मास्टर सहायता
मॉनिटर यह पता लगा सकता है कि क्लस्टर में एक सर्वर बाहरी मास्टर (एक सर्वर जिसे मैक्सस्केल मॉनिटर द्वारा मॉनिटर नहीं किया जा रहा है) से नकल कर रहा है या नहीं। यदि रेप्लिकेटिंग सर्वर क्लस्टर मास्टर सर्वर है, तो क्लस्टर को ही बाहरी मास्टर माना जाता है।
यदि कोई फ़ेलओवर/स्विचओवर होता है, तो नया मास्टर सर्वर क्लस्टर बाहरी मास्टर सर्वर से दोहराने के लिए सेट होता है। प्रतिकृति के लिए उपयोगकर्ता नाम और पासवर्ड प्रतिकृति_यूसर और प्रतिकृति_पासवर्ड में परिभाषित किए गए हैं। उपयोग किया गया पता और पोर्ट पुराने क्लस्टर मास्टर सर्वर पर SHOW ALL SLAVES STATUS द्वारा दिखाया गया है। स्विचओवर के मामले में, पुराना मास्टर टोपोलॉजी को संरक्षित करने के लिए बाहरी सर्वर से नकल करना भी बंद कर देता है।
फेलओवर के बाद नया मास्टर बाहरी मास्टर से नकल कर रहा है। यदि विफल पुराना मास्टर ऑनलाइन वापस आता है, तो वह बाहरी सर्वर से भी नकल कर रहा है। स्थिति को सामान्य करने के लिए, या तो auto_rejoin चालू करें या मैन्युअल रूप से फिर से शामिल हों। यह पुराने मास्टर को वर्तमान क्लस्टर मास्टर पर रीडायरेक्ट करेगा।
विफलता कैसे उपयोगी और लागू होती है?
फ़ेलओवर आपको डाउनटाइम को कम करने, दैनिक रखरखाव करने, या विनाशकारी और अवांछित रखरखाव को संभालने में मदद करता है जो कभी-कभी दुर्भाग्यपूर्ण समय पर हो सकता है। मैक्सस्केल की बैकएंड डेटाबेस सर्वर से क्लाइंट एप्लिकेशन को इंसुलेट करने की क्षमता के साथ, यह मूल्यवान कार्यक्षमता जोड़ता है जो डाउनटाइम को कम करने में मदद करता है।
MaxScale मॉनिटरिंग प्लगइन बैकएंड डेटाबेस सर्वर की स्थिति की लगातार निगरानी करता है। मैक्सस्केल का रूटिंग प्लगइन तब इस स्थिति की जानकारी का उपयोग हमेशा क्वेरी को बैकएंड डेटाबेस सर्वर पर रूट करने के लिए करता है जो सेवा में हैं। यह तब बैकएंड डेटाबेस क्लस्टर को क्वेरी भेजने में सक्षम होता है, भले ही क्लस्टर के कुछ सर्वर रखरखाव से गुजर रहे हों या विफलता का अनुभव कर रहे हों।
MaxScale की उच्च विन्यास क्षमता क्लाइंट अनुप्रयोगों के लिए पारदर्शी बने रहने के लिए क्लस्टर कॉन्फ़िगरेशन में परिवर्तन को सक्षम बनाती है। उदाहरण के लिए, यदि किसी नए सर्वर को मास्टर-स्लेव क्लस्टर से प्रशासनिक रूप से जोड़ने या हटाने की आवश्यकता है, तो आप बस मैक्सएडमिन सीएलआई कंसोल के माध्यम से मॉनिटर और राउटर प्लगइन्स की सर्वर सूची में मैक्सस्केल कॉन्फ़िगरेशन जोड़ सकते हैं। क्लाइंट एप्लिकेशन इस बदलाव से पूरी तरह अनजान होगा और मैक्सस्केल के लिसनिंग पोर्ट को डेटाबेस क्वेरी भेजना जारी रखेगा।
रखरखाव में डेटाबेस सर्वर सेट करना सरल और आसान है। बस maxctrl का उपयोग करके निम्न आदेश करें और MaxScale इस सर्वर पर कोई भी प्रश्न भेजना बंद कर देगा। उदाहरण के लिए,
maxctrl: set server DB_785 maintenance
OKफिर सर्वर की स्थिति की जाँच इस प्रकार करें,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘एक बार रखरखाव मोड में, मैक्सस्केल सर्वर पर किसी भी नए अनुरोध को रूट करना बंद कर देगा। वर्तमान अनुरोधों के लिए, मैक्सस्केल इन सत्रों को समाप्त नहीं करेगा, बल्कि इसे इसके निष्पादन को पूरा करने की अनुमति देगा और रखरखाव मोड में किसी भी चल रहे प्रश्नों को बाधित नहीं करेगा। साथ ही, ध्यान दें कि रखरखाव मोड स्थायी नहीं है। यदि नोड रखरखाव मोड में होने पर MaxScale पुनरारंभ होता है, तो MariaDB MaxScale का एक नया उदाहरण इस मोड का सम्मान नहीं करेगा। यदि एकाधिक MariaDB MaxScale इंस्टेंस को नोड का उपयोग करने के लिए कॉन्फ़िगर किया गया है, तो उन्हें प्रत्येक MariaDB MaxScale इंस्टेंस के भीतर रखरखाव मोड सेट किया जाना चाहिए। हालाँकि, यदि एक MariaDB MaxScale इंस्टेंस के भीतर कई सेवाएँ सर्वर का उपयोग कर रही हैं, तो आपको मोड परिवर्तन पर ध्यान देने के लिए सभी सेवाओं के लिए सर्वर पर केवल एक बार रखरखाव मोड सेट करने की आवश्यकता है।
एक बार अपने रखरखाव के साथ, बस निम्न आदेश के साथ सर्वर को साफ़ करें। उदाहरण के लिए,
maxctrl: clear server DB_785 maintenance
OKजाँच कर रहा है कि क्या यह वापस सामान्य पर सेट है, बस कमांड चलाएँ सर्वर सूचीबद्ध करें ।
आप ClusterControl UI के माध्यम से भी कुछ प्रशासनिक कार्रवाइयाँ लागू कर सकते हैं। नीचे उदाहरण स्क्रीनशॉट देखें:
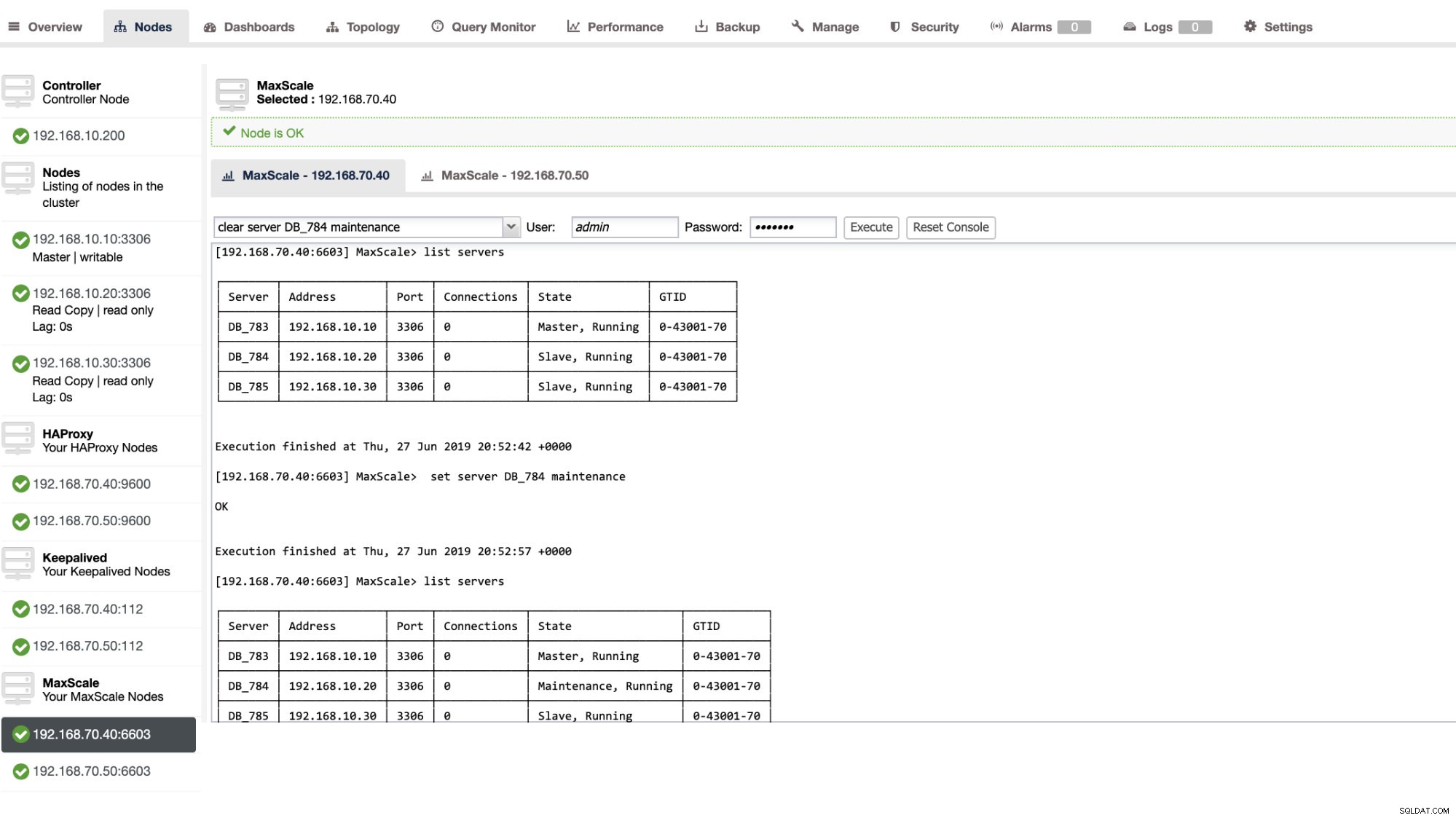
MaxScale Failover In-Action
स्वचालित विफलता
मारियाडीबी का मैक्सस्केल फेलओवर बहुत कुशलता से प्रदर्शन करता है और उम्मीद के मुताबिक दास को फिर से कॉन्फ़िगर करता है। इस परीक्षण में, हमारे पास निम्न कॉन्फ़िगरेशन फ़ाइल सेट है जिसे ClusterControl द्वारा बनाया और प्रबंधित किया गया था। नीचे देखें:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonध्यान दें कि, केवल auto_failover और auto_rejoin एक बार जब आप मैक्सस्केल लोड बैलेंसर सेट करते हैं तो क्लस्टरकंट्रोल डिफ़ॉल्ट रूप से इसे नहीं जोड़ेगा (क्लस्टरकंट्रोल का उपयोग करके मैक्सस्केल को कैसे सेटअप करें, इस ब्लॉग को देखें)। यह न भूलें कि अपनी कॉन्फ़िगरेशन फ़ाइल में परिवर्तन लागू करने के बाद आपको MariaDB MaxScale को पुनरारंभ करने की आवश्यकता है। बस दौड़ो,
systemctl restart maxscaleऔर आप जाने के लिए तैयार हैं।
विफलता परीक्षण आगे बढ़ने से पहले, आइए पहले क्लस्टर के स्वास्थ्य की जांच करें:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘बहुत अच्छा लग रहा है!
मैंने अपने मास्टर नोड में सिर्फ शुद्ध हत्यारा कमांड KILL -9 $(pidof mysqld) के साथ मास्टर को मार डाला और देखा, कोई आश्चर्य नहीं, मॉनिटर को यह नोटिस करने की जल्दी है और विफलता को ट्रिगर करता है। लॉग को इस प्रकार देखें:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]आइए अब इसके क्लस्टर के स्वास्थ्य पर एक नजर डालते हैं,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘नोड 192.168.10.10 जो पहले मास्टर था, डाउन हो गया है। मैंने पुनः आरंभ करने और यह देखने की कोशिश की कि क्या ऑटो-रिजॉइन ट्रिगर होगा, और जैसा कि आपने समय पर लॉग में देखा था 2019-06-28 06:39:20.165, यह नोड की स्थिति को पकड़ने के लिए बहुत जल्दी हो गया है और फिर डीबीए को इसे चालू करने के लिए बिना किसी परेशानी के कॉन्फ़िगरेशन को स्वचालित रूप से सेट करता है।
अब, अंत में अपने राज्य की जाँच करते हुए, यह उम्मीद के मुताबिक पूरी तरह से काम कर रहा है। नीचे देखें:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘मेरे पूर्व-मास्टर को ठीक कर दिया गया है और ठीक हो गए हैं और मैं स्विच ओवर करना चाहता हूं
अपने पिछले गुरु पर स्विच करने में भी कोई परेशानी नहीं है। आप इसे maxctrl (या MaxScale के पिछले संस्करणों में maxadmin) या ClusterControl UI (जैसा कि पहले दिखाया गया था) के माध्यम से संचालित कर सकते हैं।
आइए पहले प्रतिकृति क्लस्टर स्वास्थ्य की पिछली स्थिति का संदर्भ लें, और 192.168.10.10 (वर्तमान में दास) को वापस अपनी मास्टर स्थिति में बदलना चाहते हैं। इससे पहले कि हम आगे बढ़ें, आपको पहले उस मॉनिटर की पहचान करनी होगी जिसका आप उपयोग करने जा रहे हैं। आप इसे नीचे दिए गए कमांड से सत्यापित कर सकते हैं:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘एक बार आपके पास यह हो जाने के बाद, आप स्विच करने के लिए नीचे निम्न आदेश कर सकते हैं:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKफिर क्लस्टर की स्थिति फिर से जांचें,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘एकदम सही लग रहा है!
लॉग्स आपको मौखिक रूप से दिखाएंगे कि स्विच ओवर के दौरान यह कैसे चला और इसकी कार्रवाई की श्रृंखला। नीचे विवरण देखें:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]गलत स्विच ओवर के मामले में, यह आगे नहीं बढ़ेगा और इसलिए यह एक त्रुटि उत्पन्न करेगा जैसा कि ऊपर लॉग में दिखाया गया है। तो आप सुरक्षित रहेंगे और कोई डरावना आश्चर्य नहीं होगा।
अपने MaxScale को अत्यधिक उपलब्ध कराना
हालांकि यह फेलओवर के संबंध में थोड़ा हटकर है, मैं उच्च उपलब्धता के संबंध में यहां कुछ मूल्यवान बिंदुओं को जोड़ना चाहता हूं और यह कैसे मारियाडीबी मैक्सस्केल फेलओवर से संबंधित है।
अपने मैक्सस्केल को अत्यधिक उपलब्ध कराना उस घटना में एक महत्वपूर्ण हिस्सा है जब आपका सिस्टम क्रैश हो जाता है, डिस्क भ्रष्टाचार का अनुभव होता है, या वर्चुअल मशीन भ्रष्टाचार होता है। ये स्थितियां अपरिहार्य हैं और इन अप्रत्याशित रखरखाव चक्रों के होने पर आपके स्वचालित विफलता सेटअप की स्थिति को प्रभावित कर सकती हैं।
एक प्रतिकृति क्लस्टर प्रकार के वातावरण के लिए, यह एक विशिष्ट MaxScale सेटअप के लिए बहुत फायदेमंद और अत्यधिक अनुशंसित है। इसका उद्देश्य यह है कि, किसी भी समय क्लस्टर को संशोधित करने के लिए केवल एक MaxScale उदाहरण की अनुमति दी जानी चाहिए। यदि आपने Keepalived के साथ सेटअप किया है, तो यह वह जगह है जहां मास्टर की स्थिति वाले उदाहरण हैं। MaxScale खुद अपनी स्थिति नहीं जानता, लेकिन maxctrl . के साथ (या अधिकतम व्यवस्थापक पिछले संस्करणों में) मैक्सस्केल इंस्टेंस को निष्क्रिय मोड में सेट कर सकता है। संस्करण 2.2.2 के अनुसार, एक निष्क्रिय मैक्सस्केल एक सक्रिय के समान व्यवहार करता है, इस अंतर के साथ कि यह फेलओवर, स्विचओवर या फिर से शामिल नहीं होगा। यहां तक कि इन आदेशों के मैन्युअल संस्करण भी त्रुटि में समाप्त हो जाएंगे। निष्क्रिय/सक्रिय मोड अंतर भविष्य में विस्तारित हो सकते हैं इसलिए MaxScale में ऐसे परिवर्तनों के साथ बने रहें। ऐसा करने के लिए, बस निम्न कार्य करें:
maxctrl: alter maxscale passive true
OKआप इसे बाद में नीचे दिए गए आदेश को चलाकर सत्यापित कर सकते हैं:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │यदि आप यह देखना चाहते हैं कि Keepalived के साथ अत्यधिक उपलब्ध सेटअप कैसे करें, तो कृपया इस पोस्ट को MariaDB से देखें।
वीआईपी हैंडलिंग
इसके अतिरिक्त, चूंकि MaxScale में VIP हैंडलिंग बिल्ट-इन नहीं है, इसलिए आप इसे अपने लिए संभालने के लिए Keepalived का उपयोग कर सकते हैं। आप मास्टर स्टेट नोड को असाइन किए गए virtual_ipaddress का उपयोग कर सकते हैं। यह वर्चुअल आईपी प्रबंधन के साथ आने की संभावना है जैसे एमएचए मास्टर_फेलओवर_स्क्रिप्ट वैरिएबल के साथ करता है। जैसा कि पहले उल्लेख किया गया है, इस Keepalived with MaxScale सेटअप ब्लॉग पोस्ट को MariaDB द्वारा देखें।
निष्कर्ष
MariaDB MaxScale सुविधा संपन्न है और इसमें बहुत सारी क्षमता है, न केवल एक प्रॉक्सी और लोड बैलेंसर होने तक सीमित है, बल्कि यह विफलता तंत्र भी प्रदान करता है जिसे बड़े संगठन ढूंढ रहे हैं। यह लगभग एक आकार-फिट-सभी सॉफ़्टवेयर है, लेकिन निश्चित रूप से सीमाओं के साथ आता है कि एक निश्चित एप्लिकेशन को अन्य लोड बैलेंसर्स जैसे कि ProxySQL के विपरीत की आवश्यकता हो सकती है।
ClusterControl एक ऑटो-फेलओवर और मास्टर ऑटो-डिटेक्शन मैकेनिज्म, प्लस क्लस्टर और नोड रिकवरी को मैक्सस्केल और अन्य लोड बैलेंसिंग तकनीकों को तैनात करने की क्षमता प्रदान करता है।
इनमें से प्रत्येक टूल की अपनी विविध विशेषताएं और कार्यक्षमता है, लेकिन MariaDB MaxScale ClusterControl के भीतर अच्छी तरह से समर्थित है और इसे Keepalived, HAProxy के साथ व्यावहारिक रूप से तैनात किया जा सकता है ताकि आप अपने दैनिक दिनचर्या के कार्य में तेजी ला सकें।