जब SQL सर्वर किसी क्वेरी का अनुकूलन करता है, तो एक अन्वेषण चरण के दौरान यह उम्मीदवार योजनाएँ तैयार करता है और उनमें से सबसे कम लागत वाली योजना को चुनता है। चुनी गई योजना को खोजी गई योजनाओं में सबसे कम चलने का समय माना जाता है। बात यह है कि, ऑप्टिमाइज़र केवल उन रणनीतियों के बीच चयन कर सकता है जो इसमें एन्कोड किए गए थे। उदाहरण के लिए, इस लेखन की तिथि पर समूहीकरण और एकत्रीकरण का अनुकूलन करते समय, अनुकूलक केवल स्ट्रीम एग्रीगेट और हैश एग्रीगेट रणनीतियों के बीच चयन कर सकता है। मैंने इस श्रृंखला के पहले के हिस्सों में उपलब्ध रणनीतियों को कवर किया। भाग 1 में मैंने पहले से ऑर्डर की गई स्ट्रीम एग्रीगेट रणनीति, भाग 2 में सॉर्ट + स्ट्रीम एग्रीगेट रणनीति, भाग 3 में हैश एग्रीगेट रणनीति, और भाग 4 समानांतरवाद के विचारों को कवर किया।
SQL सर्वर अनुकूलक वर्तमान में अनुकूलन और कृत्रिम बुद्धिमत्ता का समर्थन नहीं करता है। यही है, यदि आप एक रणनीति का पता लगा सकते हैं कि कुछ शर्तों के तहत अनुकूलक द्वारा समर्थित लोगों की तुलना में अधिक इष्टतम है, तो आप इसका समर्थन करने के लिए अनुकूलक को नहीं बढ़ा सकते हैं, और अनुकूलक इसका उपयोग करना नहीं सीख सकता है। हालांकि, आप क्या कर सकते हैं, वैकल्पिक क्वेरी तत्वों का उपयोग करके क्वेरी को फिर से लिखना है जिसे आपके मन में रणनीति के साथ अनुकूलित किया जा सकता है। श्रृंखला के इस पांचवें और अंतिम भाग में मैं क्वेरी संशोधन का उपयोग करके क्वेरी ट्यूनिंग की इस तकनीक का प्रदर्शन करता हूं।
इस लेख में प्रस्तुत कुछ लागत गणनाओं में मदद करने के लिए पॉल व्हाइट (@SQL_Kiwi) को बहुत-बहुत धन्यवाद!
श्रृंखला के पिछले भागों की तरह, मैं PerformanceV3 नमूना डेटाबेस का उपयोग करूँगा। आदेश तालिका से अनावश्यक अनुक्रमणिका छोड़ने के लिए निम्न कोड का उपयोग करें:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
डिफ़ॉल्ट अनुकूलन रणनीति
निम्नलिखित बुनियादी समूहीकरण और एकत्रीकरण कार्यों पर विचार करें:
प्रत्येक शिपर, कर्मचारी और ग्राहक के लिए अधिकतम ऑर्डर तिथि लौटाएं।
इष्टतम प्रदर्शन के लिए, आप निम्नलिखित सहायक अनुक्रमणिकाएँ बनाते हैं:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate); CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate); CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
अनुमानित सबट्री लागतों के साथ-साथ I/O, CPU और बीता हुआ समय के आंकड़ों के साथ इन कार्यों को संभालने के लिए आप निम्नलिखित तीन प्रश्नों का उपयोग करेंगे:
-- Query 1 -- Estimated Subtree Cost: 3.5344 -- logical reads: 2484, CPU time: 281 ms, elapsed time: 279 ms SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid; -- Query 2 -- Estimated Subtree Cost: 3.62798 -- logical reads: 2610, CPU time: 250 ms, elapsed time: 283 ms SELECT empid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY empid; -- Query 3 -- Estimated Subtree Cost: 4.27624 -- logical reads: 3479, CPU time: 406 ms, elapsed time: 506 ms SELECT custid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY custid;
चित्र 1 इन प्रश्नों की योजना दिखाता है:
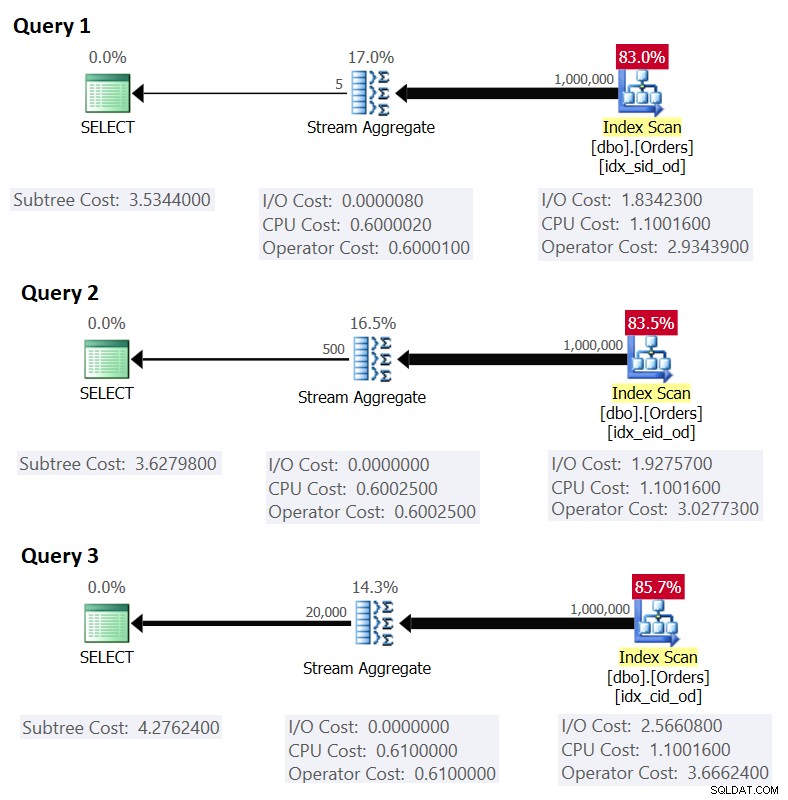 चित्र 1:के लिए योजनाएं समूहीकृत प्रश्न
चित्र 1:के लिए योजनाएं समूहीकृत प्रश्न
याद रखें कि यदि आपके पास एक कवरिंग इंडेक्स है, जिसमें ग्रुपिंग कॉलम को प्रमुख कुंजी कॉलम के रूप में सेट किया गया है, उसके बाद एग्रीगेशन कॉलम है, तो SQL सर्वर एक ऐसी योजना चुनने की संभावना है जो स्ट्रीम एग्रीगेट रणनीति का समर्थन करने वाले कवरिंग इंडेक्स का ऑर्डर स्कैन करता है। . जैसा कि चित्र 1 में योजनाओं में स्पष्ट है, इंडेक्स स्कैन ऑपरेटर अधिकांश योजना लागत के लिए जिम्मेदार है, और इसके भीतर I/O भाग सबसे प्रमुख है।
इससे पहले कि मैं एक वैकल्पिक रणनीति प्रस्तुत करूं और उन परिस्थितियों की व्याख्या करूं जिनके तहत यह डिफ़ॉल्ट रणनीति से अधिक इष्टतम है, आइए मौजूदा रणनीति की लागत का मूल्यांकन करें। चूंकि इस डिफ़ॉल्ट रणनीति की योजना लागत निर्धारित करने में I/O भाग सबसे प्रभावशाली है, आइए पहले अनुमान लगाएं कि कितने तार्किक पृष्ठ पढ़ने की आवश्यकता होगी। बाद में हम योजना लागत का भी अनुमान लगाएंगे।
इंडेक्स स्कैन ऑपरेटर के लिए आवश्यक तार्किक रीड्स की संख्या का अनुमान लगाने के लिए, आपको यह जानना होगा कि आपके पास तालिका में कितनी पंक्तियाँ हैं, और पंक्ति आकार के आधार पर एक पृष्ठ में कितनी पंक्तियाँ फिट होती हैं। एक बार जब आपके पास ये दो ऑपरेंड हो जाते हैं, तो इंडेक्स के लीफ स्तर में आवश्यक पृष्ठों की संख्या के लिए आपका सूत्र तब CEILING(1e0 * @numrows / @rowsperpage) होता है। यदि आपके पास केवल तालिका संरचना है और काम करने के लिए कोई मौजूदा नमूना डेटा नहीं है, तो आप इस लेख का उपयोग यह अनुमान लगाने के लिए कर सकते हैं कि आपके पास सहायक सूचकांक के लीफ स्तर में कितने पृष्ठ होंगे। यदि आपके पास अच्छा प्रतिनिधि नमूना डेटा है, भले ही उत्पादन परिवेश के समान पैमाने पर न हो, तो आप कैटलॉग और डायनेमिक प्रबंधन ऑब्जेक्ट्स को क्वेरी करके पेज में फिट होने वाली पंक्तियों की औसत संख्या की गणना कर सकते हैं, जैसे:
SELECT I.name, row_count, in_row_data_page_count,
CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage
FROM sys.indexes AS I
INNER JOIN sys.dm_db_partition_stats AS P
ON I.object_id = P.object_id
AND I.index_id = P.index_id
WHERE I.object_id = OBJECT_ID('dbo.Orders')
AND I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); यह क्वेरी हमारे नमूना डेटाबेस में निम्न आउटपुट उत्पन्न करती है:
name row_count in_row_data_page_count avgrowsperpage ----------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
अब जब आपके पास इंडेक्स के लीफ पेज में फिट होने वाली पंक्तियों की संख्या है, तो आप इंडेक्स में लीफ पेजों की कुल संख्या का अनुमान उन पंक्तियों की संख्या के आधार पर लगा सकते हैं, जिनकी आप अपनी प्रोडक्शन टेबल में होने की उम्मीद करते हैं। यह इंडेक्स स्कैन ऑपरेटर द्वारा लागू किए जाने वाले तार्किक रीड्स की अपेक्षित संख्या भी होगी। व्यवहार में, इंडेक्स के लीफ स्तर में पृष्ठों की संख्या की तुलना में पढ़ने की संख्या अधिक हो सकती है, जैसे कि आगे पढ़ें तंत्र द्वारा उत्पादित अतिरिक्त पठन, लेकिन हम अपनी चर्चा को सरल रखने के लिए उन पर ध्यान नहीं देंगे ।
उदाहरण के लिए, पंक्तियों की अपेक्षित संख्या के संबंध में क्वेरी 1 के लिए तार्किक रीड की अनुमानित संख्या CEILING(1e0 * @numorws / 404) है। 1,000,000 पंक्तियों के साथ तार्किक पठन की अपेक्षित संख्या 2476 है। 2476 के बीच का अंतर और 2473 की पंक्ति पृष्ठ संख्या में रिपोर्ट की गई संख्या को उस पूर्णांकन के लिए जिम्मेदार ठहराया जा सकता है जो मैंने प्रति पृष्ठ पंक्तियों की औसत संख्या की गणना करते समय किया था।
जहां तक योजना की लागत का सवाल है, मैंने श्रृंखला के भाग 1 में स्ट्रीम एग्रीगेट ऑपरेटर की लागत को रिवर्स इंजीनियर करने का तरीका बताया। इसी तरह, आप इंडेक्स स्कैन ऑपरेटर की लागत को रिवर्स इंजीनियर कर सकते हैं। योजना लागत तब इंडेक्स स्कैन और स्ट्रीम एग्रीगेट ऑपरेटरों की लागत का योग है।
इंडेक्स स्कैन ऑपरेटर की लागत की गणना करने के लिए, आप कुछ महत्वपूर्ण लागत मॉडल स्थिरांक रिवर्स इंजीनियरिंग से शुरू करना चाहते हैं:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
उपरोक्त लागत मॉडल स्थिरांक के साथ, आप इंडेक्स स्कैन ऑपरेटर के लिए I/O लागत, CPU लागत, और कुल ऑपरेटर लागत के लिए सूत्रों को रिवर्स इंजीनियर करने के लिए आगे बढ़ सकते हैं:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.003125 + (@numpages - 1e0) * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011 Operator cost: 0.002541259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000011
उदाहरण के लिए, क्वेरी 1 के लिए इंडेक्स स्कैन ऑपरेटर की लागत 2473 पृष्ठों और 1,000,000 पंक्तियों के साथ है:
0.002541259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000011 = 2.93439
स्ट्रीम एग्रीगेट ऑपरेटर लागत के लिए रिवर्स इंजीनियर फॉर्मूला निम्नलिखित है:
0.000008 + @numrows * 0.0000006 + @numgroups * 0.0000005
उदाहरण के तौर पर, प्रश्न 1 के लिए हमारे पास 1,000,000 पंक्तियां और 5 समूह हैं, इसलिए अनुमानित लागत 0.6000105 है।
दो ऑपरेटरों की लागतों को मिलाकर, यहां संपूर्ण योजना लागत का सूत्र दिया गया है:
0.002549259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
प्रश्न 1 के लिए 2473 पृष्ठों, 1,000,000 पंक्तियों और 5 समूहों के साथ, आपको मिलता है:
0.002549259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5344
यह चित्र 1 क्वेरी 1 की अनुमानित लागत से मेल खाता है।
यदि आप प्रति पृष्ठ पंक्तियों की अनुमानित संख्या पर भरोसा करते हैं, तो आपका सूत्र होगा:
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
उदाहरण के तौर पर, क्वेरी 1 के लिए, 1,000,000 पंक्तियों, प्रति पृष्ठ 404 पंक्तियों और 5 समूहों के साथ, अनुमानित लागत है:
0.002549259259259 + CEILING(1e0 * 1000000 / 404) * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5366
एक अभ्यास के रूप में, आप हमारे सूत्र में क्वेरी 2 (1,000,000 पंक्तियाँ, 385 पंक्तियाँ प्रति पृष्ठ, 500 समूह) और क्वेरी 3 (1,000,000 पंक्तियाँ, 289 पंक्तियाँ प्रति पृष्ठ, 20,000 समूह) के लिए संख्याओं को लागू कर सकते हैं, और देख सकते हैं कि परिणाम किससे मेल खाते हैं चित्र 1 दिखाता है।
क्वेरी पुनर्लेखन के साथ क्वेरी ट्यूनिंग
प्रति समूह MIN/MAX कुल की गणना के लिए डिफ़ॉल्ट प्रीऑर्डर की गई स्ट्रीम एग्रीगेट रणनीति एक सहायक कवरिंग इंडेक्स (या कुछ अन्य प्रारंभिक गतिविधि जो ऑर्डर की गई पंक्तियों को उत्सर्जित करती है) के ऑर्डर किए गए स्कैन पर निर्भर करती है। एक वैकल्पिक रणनीति, जिसमें सपोर्टिंग कवरिंग इंडेक्स मौजूद हो, प्रति समूह इंडेक्स सीक करना होगा। यहां एक क्वेरी के लिए ऐसी रणनीति पर आधारित एक छद्म योजना का विवरण दिया गया है जो grpcol द्वारा समूहीकृत होती है और एक MAX(aggcol) लागू करती है:
set @curgrpcol = grpcol from first row obtained by a scan of the index, ordered forward;
while end of index not reached
begin
set @curagg = aggcol from row obtained by a seek to the last point
where grpcol = @curgrpcol, ordered backward;
emit row (@curgrpcol, @curagg);
set @curgrpcol = grpcol from row to the right of last row for current group;
end; यदि आप इसके बारे में सोचते हैं, तो डिफ़ॉल्ट स्कैन-आधारित रणनीति इष्टतम होती है जब ग्रुपिंग सेट में कम घनत्व होता है (बड़ी संख्या में समूह, औसतन प्रति समूह पंक्तियों की एक छोटी संख्या के साथ)। तलाश-आधारित रणनीति इष्टतम होती है जब समूह सेट में उच्च घनत्व होता है (समूहों की छोटी संख्या, औसतन प्रति समूह बड़ी संख्या में पंक्तियों के साथ)। चित्र 2 दोनों रणनीतियों को दिखाता है कि प्रत्येक कब इष्टतम है।
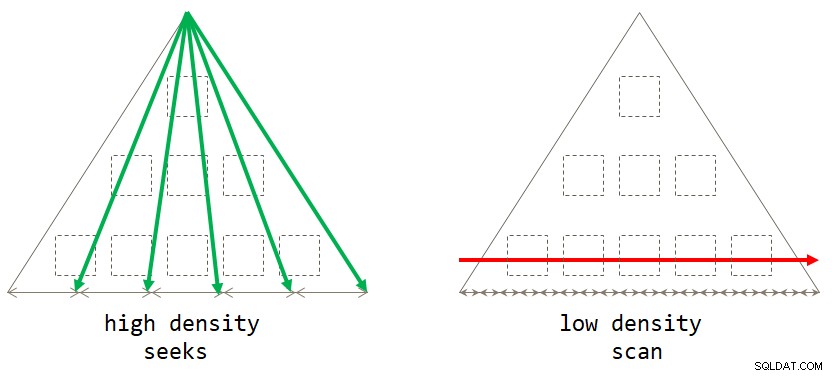 चित्र 2:इष्टतम रणनीति समूह घनत्व के आधार पर
चित्र 2:इष्टतम रणनीति समूह घनत्व के आधार पर
जब तक आप समूहीकृत क्वेरी के रूप में समाधान लिखते हैं, वर्तमान में SQL सर्वर केवल स्कैन रणनीति पर विचार करेगा। यह आपके लिए तब अच्छा काम करेगा जब समूहन समुच्चय का घनत्व कम हो। जब आपके पास उच्च घनत्व होता है, तो खोज की रणनीति प्राप्त करने के लिए, आपको एक क्वेरी पुनर्लेखन लागू करने की आवश्यकता होगी। इसे प्राप्त करने का एक तरीका समूह को रखने वाली तालिका को क्वेरी करना है, और कुल प्राप्त करने के लिए मुख्य तालिका के विरुद्ध एक स्केलर कुल उपश्रेणी का उपयोग करना है। उदाहरण के लिए, प्रत्येक शिपर के लिए अधिकतम ऑर्डर तिथि की गणना करने के लिए, आप निम्न कोड का उपयोग करेंगे:
SELECT shipperid,
( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS maxod
FROM dbo.Shippers AS S; मुख्य तालिका के लिए अनुक्रमण दिशानिर्देश वही हैं जो डिफ़ॉल्ट रणनीति का समर्थन करते हैं। उपरोक्त तीन कार्यों के लिए हमारे पास पहले से ही वे अनुक्रमणिकाएं हैं। आप संभवत:उस तालिका के विरुद्ध I/O लागत को कम करने के लिए समूह धारण करने वाली तालिका में समूह सेट के स्तंभों पर एक सहायक अनुक्रमणिका भी चाहते हैं। हमारे तीन कार्यों के लिए ऐसी सहायक अनुक्रमणिका बनाने के लिए निम्नलिखित कोड का उपयोग करें:
CREATE INDEX idx_sid ON dbo.Shippers(shipperid); CREATE INDEX idx_eid ON dbo.Employees(empid); CREATE INDEX idx_cid ON dbo.Customers(custid);
हालांकि एक छोटी सी समस्या यह है कि सबक्वायरी पर आधारित समाधान समूहबद्ध क्वेरी के आधार पर समाधान का सटीक तार्किक-समतुल्य नहीं है। यदि आपके पास मुख्य तालिका में कोई उपस्थिति नहीं है, तो पूर्व समूह को कुल के रूप में NULL के साथ वापस कर देगा, जबकि बाद वाला समूह को बिल्कुल वापस नहीं करेगा। समूहित क्वेरी के लिए एक वास्तविक तार्किक समकक्ष प्राप्त करने का एक आसान तरीका चयन खंड में स्केलर सबक्वायरी का उपयोग करने के बजाय FROM क्लॉज में क्रॉस लागू ऑपरेटर का उपयोग करके सबक्वायरी को आमंत्रित करना है। याद रखें कि यदि लागू की गई क्वेरी एक खाली सेट लौटाती है, तो CROSS APPLY बाईं पंक्ति नहीं लौटाएगा। हमारे तीन कार्यों के लिए इस रणनीति को लागू करने वाले तीन समाधान प्रश्न यहां उनके प्रदर्शन आंकड़ों के साथ दिए गए हैं:
-- Query 4
-- Estimated Subtree Cost: 0.0072299
-- logical reads: 2 + 15, CPU time: 0 ms, elapsed time: 43 ms
SELECT S.shipperid, A.orderdate AS maxod
FROM dbo.Shippers AS S
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS A;
-- Query 5
-- Estimated Subtree Cost: 0.089694
-- logical reads: 2 + 1620, CPU time: 0 ms, elapsed time: 148 ms
SELECT E.empid, A.orderdate AS maxod
FROM dbo.Employees AS E
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.empid = E.empid
ORDER BY O.orderdate DESC ) AS A;
-- Query 6
-- Estimated Subtree Cost: 3.5227
-- logical reads: 45 + 63777, CPU time: 171 ms, elapsed time: 306 ms
SELECT C.custid, A.orderdate AS maxod
FROM dbo.Customers AS C
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.custid = C.custid
ORDER BY O.orderdate DESC ) AS A; इन प्रश्नों की योजना चित्र 3 में दिखाई गई है।
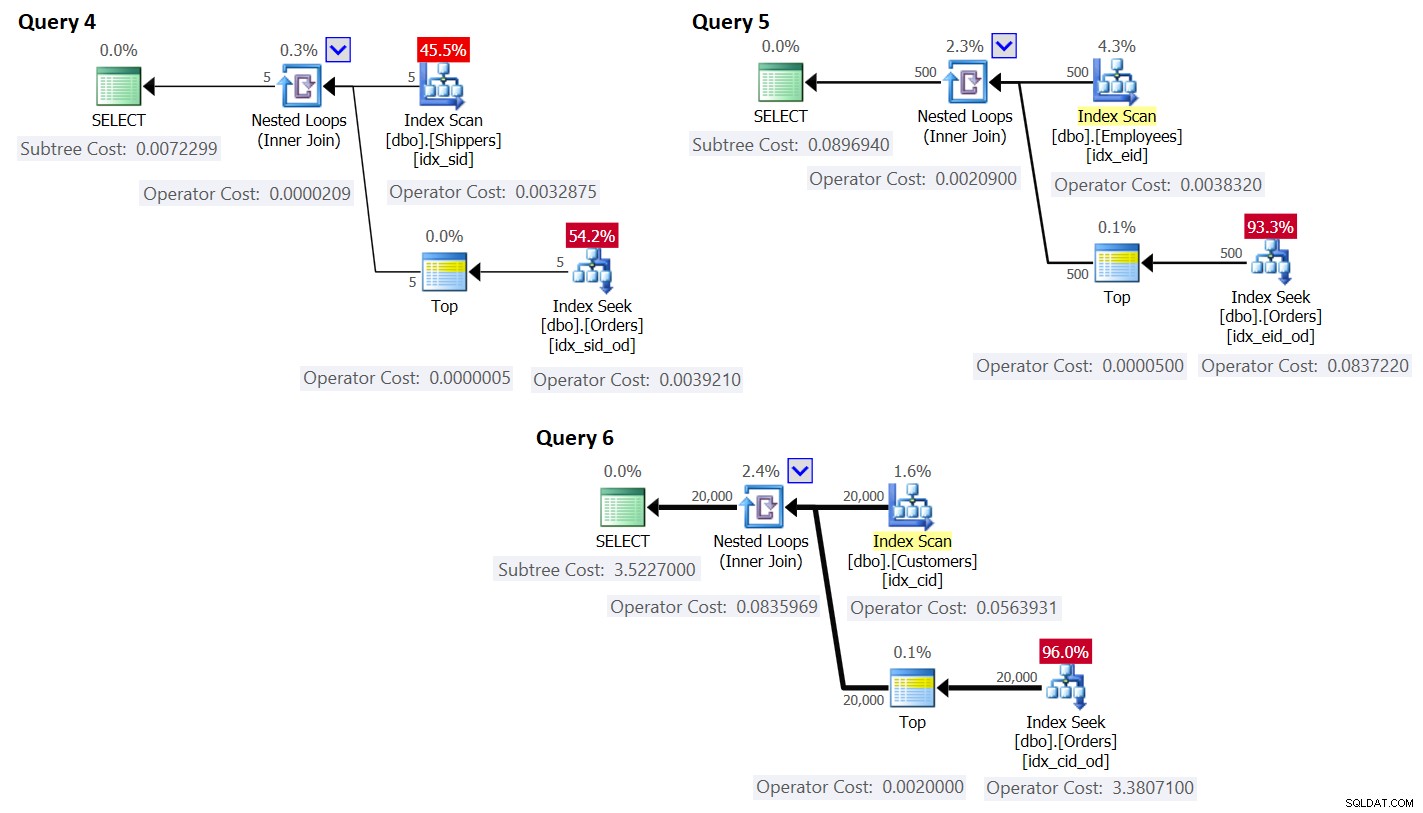 चित्र 3:के लिए योजनाएं पुनर्लेखन के साथ प्रश्न
चित्र 3:के लिए योजनाएं पुनर्लेखन के साथ प्रश्न
जैसा कि आप देख सकते हैं, समूह तालिका पर सूचकांक को स्कैन करके समूह प्राप्त किए जाते हैं, और मुख्य तालिका पर सूचकांक में खोज लागू करके कुल प्राप्त किया जाता है। ग्रुपिंग सेट का घनत्व जितना अधिक होगा, इस योजना की तुलना समूहीकृत क्वेरी के लिए डिफ़ॉल्ट रणनीति से की जाएगी।
जैसा कि हमने पहले डिफ़ॉल्ट स्कैन रणनीति के लिए किया था, आइए तार्किक पढ़ने की संख्या और तलाश रणनीति के लिए योजना लागत का अनुमान लगाएं। तार्किक पढ़ने की अनुमानित संख्या इंडेक्स स्कैन ऑपरेटर के एकल निष्पादन के लिए पढ़ने की संख्या है जो समूहों को पुनर्प्राप्त करता है, साथ ही इंडेक्स सीक ऑपरेटर के सभी निष्पादन के लिए पढ़ता है।
इंडेक्स स्कैन ऑपरेटर के लिए तार्किक रीड की अनुमानित संख्या तलाश की तुलना में नगण्य है; फिर भी, यह सीलिंग (1e0 * @numgroups / @rowsperpage) है। एक उदाहरण के रूप में प्रश्न 4 को लें; मान लें कि सूचकांक idx_sid प्रति पत्ती पृष्ठ लगभग 600 पंक्तियों में फिट बैठता है (वास्तविक संख्या वास्तविक शिपरिड मूल्यों पर निर्भर करती है क्योंकि डेटाटाइप VARCHAR(5) है)। 5 समूहों के साथ, सभी पंक्तियाँ एक पत्ती वाले पृष्ठ में फ़िट हो जाती हैं। यदि आपके पास 5,000 समूह होते, तो वे 9 पृष्ठों में फ़िट हो जाते।
इंडेक्स सीक ऑपरेटर के सभी निष्पादन के लिए तार्किक रीड की अनुमानित संख्या @numgroups * @indexdepth है। सूचकांक की गहराई की गणना इस प्रकार की जा सकती है:
CEILING(LOG(CEILING(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1
एक उदाहरण के रूप में क्वेरी 4 का उपयोग करते हुए, मान लें कि हम इंडेक्स idx_sid_od के प्रति लीफ पेज पर लगभग 404 पंक्तियों और नॉनलीफ पेज पर लगभग 352 पंक्तियों को फिट कर सकते हैं। फिर से, वास्तविक संख्या शिपरिड कॉलम में संग्रहीत वास्तविक मूल्यों पर निर्भर करेगी क्योंकि इसका डेटाटाइप VARCHAR(5) है)। अनुमानों के लिए, याद रखें कि आप यहां वर्णित गणनाओं का उपयोग कर सकते हैं। अच्छे प्रतिनिधि नमूना डेटा उपलब्ध होने के साथ, आप निम्न क्वेरी का उपयोग करके उन पंक्तियों की संख्या का पता लगा सकते हैं जो दिए गए इंडेक्स के लीफ और नॉनलीफ पेजों में फिट हो सकती हैं:
SELECT
CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype,
FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage
FROM (SELECT *
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.Orders')
AND name = 'idx_sid_od') AS I
CROSS APPLY sys.dm_db_index_physical_stats
(DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P
WHERE P.index_level <= 1; मुझे निम्न आउटपुट मिला:
pagetype rowsperpage -------- ---------------------- leaf 404 nonleaf 352
इन संख्याओं के साथ, तालिका में पंक्तियों की संख्या के संबंध में सूचकांक की गहराई है:
CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1
तालिका में 1,000,000 पंक्तियों के साथ, इसका परिणाम 3 की अनुक्रमणिका गहराई में होता है। लगभग 50 मिलियन पंक्तियों में, अनुक्रमणिका की गहराई 4 स्तरों तक बढ़ जाती है, और लगभग 17.62 बिलियन पंक्तियों में यह 5 स्तरों तक बढ़ जाती है।
किसी भी दर पर, समूहों की संख्या और पंक्तियों की संख्या के संबंध में, प्रति पृष्ठ पंक्तियों की उपरोक्त संख्या को मानते हुए, निम्न सूत्र क्वेरी 4 के लिए तार्किक रीड की अनुमानित संख्या की गणना करता है:
CEILING(1e0 * @numgroups / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)
उदाहरण के लिए, 5 समूहों और 1,00,000 पंक्तियों के साथ, आपको कुल 16 रीड्स मिलते हैं! याद रखें कि समूहबद्ध क्वेरी के लिए डिफ़ॉल्ट स्कैन-आधारित रणनीति में CEILING(1e0 * @numrows / @rowsperpage) के रूप में कई तार्किक रीड शामिल हैं। एक उदाहरण के रूप में क्वेरी 1 का उपयोग करना, और इंडेक्स idx_sid_od के प्रति पृष्ठ लगभग 404 पंक्तियों को मानते हुए, 1,000,000 की समान पंक्तियों के साथ, आपको लगभग 2,476 रीड मिलते हैं। तालिका में पंक्तियों की संख्या 1,000 से 1,00,000,000 तक बढ़ाएं, लेकिन समूहों की संख्या निश्चित रखें। सीक्स रणनीति के लिए आवश्यक रीड्स की संख्या 21 से बहुत कम बदल जाती है, जबकि स्कैन रणनीति के साथ आवश्यक रीड्स की संख्या रैखिक रूप से बढ़कर 2,475,248 हो जाती है।
तलाश की रणनीति की सुंदरता यह है कि जब तक समूहों की संख्या छोटी और निश्चित होती है, तब तक तालिका में पंक्तियों की संख्या के संबंध में लगभग निरंतर स्केलिंग होती है। ऐसा इसलिए है क्योंकि खोज की संख्या समूहों की संख्या से निर्धारित होती है, और सूचकांक की गहराई एक लॉगरिदमिक फैशन में तालिका में पंक्तियों की संख्या से संबंधित होती है, जहां लॉग बेस उन पंक्तियों की संख्या होती है जो एक नॉनलीफ पेज में फिट होती हैं। इसके विपरीत, स्कैन-आधारित रणनीति में शामिल पंक्तियों की संख्या के संबंध में रैखिक स्केलिंग है।
चित्र 4 दो रणनीतियों के लिए अनुमानित रीड की संख्या को दर्शाता है, जिसे क्वेरी 1 और क्वेरी 4 द्वारा लागू किया गया है, जिसमें 5 के समूहों की एक निश्चित संख्या दी गई है, और मुख्य तालिका में पंक्तियों की अलग-अलग संख्या है।
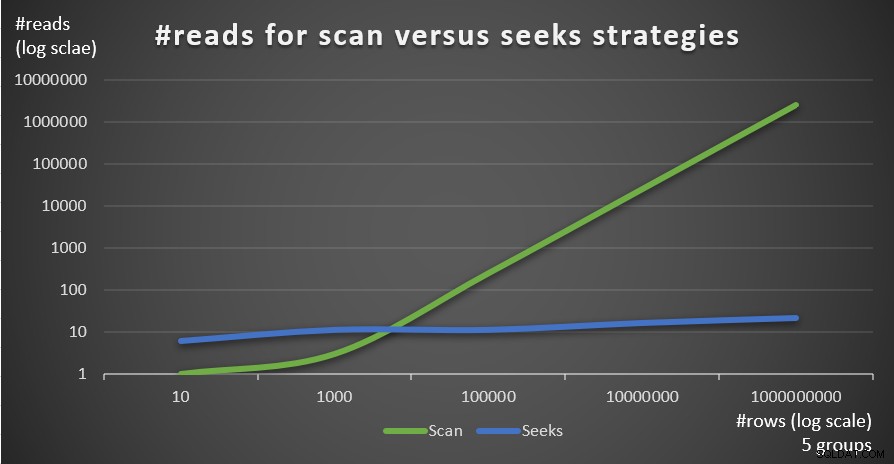 चित्र 4:#पढ़ें स्कैन बनाम तलाश रणनीतियों के लिए (5 समूह)
चित्र 4:#पढ़ें स्कैन बनाम तलाश रणनीतियों के लिए (5 समूह)
चित्र 5 दो रणनीतियों के लिए अनुमानित रीड की संख्या को दर्शाता है, मुख्य तालिका में 1,000,000 की पंक्तियों की एक निश्चित संख्या और समूहों की अलग-अलग संख्या दी गई है।
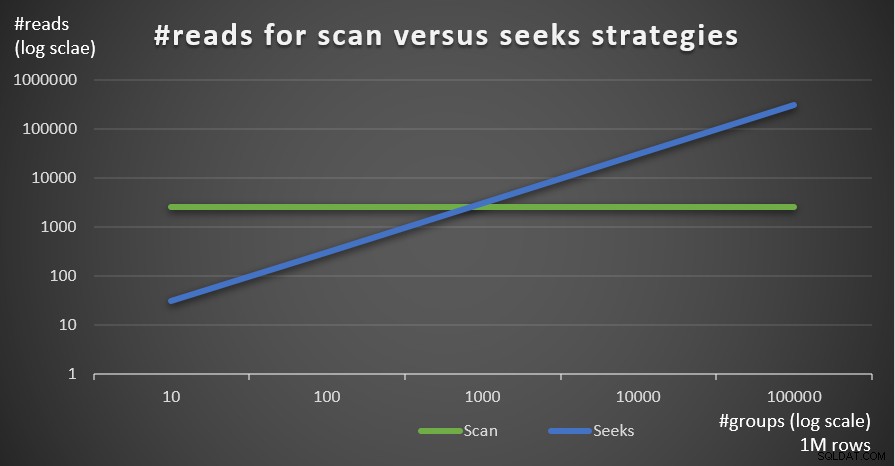 चित्र 5:#पढ़ें स्कैन बनाम सीक्स रणनीतियों के लिए (1M पंक्तियाँ)
चित्र 5:#पढ़ें स्कैन बनाम सीक्स रणनीतियों के लिए (1M पंक्तियाँ)
आप बहुत स्पष्ट रूप से देख सकते हैं कि ग्रुपिंग सेट (समूहों की छोटी संख्या) का घनत्व जितना अधिक होता है और मुख्य तालिका जितनी बड़ी होती है, पढ़ने की संख्या के संदर्भ में उतनी ही अधिक रणनीति को प्राथमिकता दी जाती है। यदि आप प्रत्येक रणनीति द्वारा उपयोग किए जाने वाले I/O पैटर्न के बारे में सोच रहे हैं; निश्चित रूप से, इंडेक्स सीक ऑपरेशंस यादृच्छिक I/O करते हैं, जबकि एक इंडेक्स स्कैन ऑपरेशन अनुक्रमिक I/O करता है। फिर भी, यह बहुत स्पष्ट है कि अधिक चरम मामलों में कौन सी रणनीति अधिक इष्टतम है।
जहां तक क्वेरी प्लान की लागत का सवाल है, एक उदाहरण के रूप में चित्र 3 में क्वेरी 4 के लिए योजना का उपयोग करते हुए, आइए इसे योजना में अलग-अलग ऑपरेटरों के लिए तोड़ दें।
इंडेक्स स्कैन ऑपरेटर की लागत के लिए रिवर्स इंजीनियर फॉर्मूला है:
0.002541259259259 + @numpages * 0.000740740740741 + @numgroups * 0.0000011
हमारे मामले में, 5 समूहों के साथ, जिनमें से सभी एक पृष्ठ में फिट होते हैं, लागत है:
0.002541259259259 + 1 * 0.000740740740741 + 5 * 0.0000011 = 0.0032875
योजना में दिखाई गई लागत समान है।
पहले की तरह, आप सूत्र CEILING(1e0 * @numrows / @rowsperpage) का उपयोग करके प्रति पृष्ठ पंक्तियों की अनुमानित संख्या के आधार पर सूचकांक के लीफ स्तर में पृष्ठों की संख्या का अनुमान लगा सकते हैं, जो हमारे मामले में CEILING(1e0 * @) है। अंक समूह / @groupsperpage)। मान लें कि सूचकांक idx_sid प्रति पत्ती पृष्ठ में लगभग 600 पंक्तियों में फिट बैठता है, 5 समूहों के साथ आपको एक पृष्ठ पढ़ने की आवश्यकता होगी। किसी भी दर पर, इंडेक्स स्कैन ऑपरेटर के लिए लागत सूत्र बन जाता है:
0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011
नेस्टेड लूप्स ऑपरेटर के लिए रिवर्स इंजीनियर कॉस्टिंग फॉर्मूला है:
@executions * 0.00000418
हमारे मामले में, इसका अनुवाद होता है:
@numgroups * 0.00000418
प्रश्न 4 के लिए, 5 समूहों के साथ, आपको मिलता है:
5 * 0.00000418 = 0.0000209
योजना में दिखाई गई लागत समान है।
शीर्ष ऑपरेटर के लिए रिवर्स इंजीनियर कॉस्टिंग फॉर्मूला है:
@executions * @toprows * 0.00000001
हमारे मामले में, इसका अनुवाद होता है:
@numgroups * 1 * 0.00000001
5 समूहों के साथ, आपको मिलता है:
5 * 0.0000001 = 0.0000005
योजना में दिखाई गई लागत समान है।
जहां तक इंडेक्स सीक ऑपरेटर का सवाल है, यहां मुझे पॉल व्हाइट से काफी मदद मिली; धन्यवाद मेरे दोस्त! पहले निष्पादन के लिए और रिबाइंड के लिए गणना अलग है (गैर-प्रथम निष्पादन जो पिछले निष्पादन के परिणाम का पुन:उपयोग नहीं करते हैं)। जैसा कि हमने इंडेक्स स्कैन ऑपरेटर के साथ किया था, आइए लागत मॉडल के स्थिरांक की पहचान करके शुरू करें:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
एक निष्पादन के लिए, एक पंक्ति लक्ष्य लागू किए बिना, I/O और CPU लागतें हैं:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.002384259259259 + @numpages * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011
चूंकि हम TOP (1) का उपयोग करते हैं, हमारे पास केवल एक पृष्ठ और एक पंक्ति शामिल है, इसलिए लागतें हैं:
I/O cost: 0.002384259259259 + 1 * 0.000740740740741 = 0.003125 CPU cost: 0.000157 + 1 * 0.0000011 = 0.0001581
तो हमारे मामले में इंडेक्स सीक ऑपरेटर के पहले निष्पादन की लागत है:
@firstexecution = 0.003125 + 0.0001581 = 0.0032831
रिबाइंड की लागत के लिए, हमेशा की तरह, यह CPU और I/O लागतों से बना है। आइए उन्हें क्रमशः @rebindcpu और @rebindio कहते हैं। प्रश्न 4 के साथ, 5 समूहों वाले, हमारे पास 4 रिबाइंड हैं (इसे @rebinds कहते हैं)। @rebindcpu लागत आसान हिस्सा है। सूत्र है:
@rebindcpu = @rebinds * (@cpubase + @cpurow)
हमारे मामले में, इसका अनुवाद होता है:
@rebindcpu = 4 * (0.000157 + 0.0000011) = 0.0006324
@rebindio भाग थोड़ा अधिक जटिल है। यहां, लागत सूत्र गणना करता है, सांख्यिकीय रूप से, अलग-अलग पृष्ठों की अपेक्षित संख्या जो कि रिबाइंड से प्रतिस्थापन के साथ नमूने का उपयोग करके पढ़ने की उम्मीद है। हम इस तत्व को @pswr (प्रतिस्थापन के साथ नमूने लिए गए अलग-अलग पृष्ठों के लिए) कहेंगे। विचार यह है कि, हमारे पास इंडेक्स में पृष्ठों की संख्या @indexdatapages है (हमारे मामले में, 2,473), और @rebinds की संख्या रिबाइंड (हमारे मामले में, 4)। यह मानते हुए कि हमारे पास प्रत्येक रिबाइंड के साथ किसी दिए गए पेज को पढ़ने की समान संभावना है, हमें कुल कितने अलग-अलग पेज पढ़ने की उम्मीद है? यह 2,473 गेंदों के साथ एक बैग रखने के समान है, और चार बार आँख बंद करके बैग से एक गेंद खींचकर बैग में वापस कर देता है। सांख्यिकीय रूप से, आपसे कुल कितनी अलग-अलग गेंदें निकालने की उम्मीद की जाती है? हमारे ऑपरेंड का उपयोग करते हुए इसके लिए सूत्र है:
@pswr = @indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))
हमारे नंबरों से आपको मिलता है:
@pswr = 2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) = 3.99757445099277
इसके बाद, आप प्रति समूह औसतन पंक्तियों और पृष्ठों की संख्या की गणना करते हैं:
@grouprows = @cardinality * @density @grouppages = CEILING(@indexdatapages * @density)
हमारे प्रश्न 4 में, कार्डिनैलिटी 1,000,000 है और घनत्व 1/5 =0.2 है। तो आपको मिलता है:
@grouprows = 1000000 * 0.2 = 200000 @numpages = CEILING(2473 * 0.2) = 495
फिर आप बिना फ़िल्टर किए I/O लागत की गणना करते हैं (इसे @io कहते हैं):
@io = @randomio + (@seqio * (@grouppages - 1e0))
हमारे मामले में, आपको मिलता है:
@io = 0.003125 + (0.000740740740741 * (495 - 1e0)) = 0.369050925926054
और अंत में, चूंकि सीक प्रत्येक रिबाइंड में केवल एक पंक्ति निकालता है, आप निम्न सूत्र का उपयोग करके @rebindio की गणना करते हैं:
@rebindio = (1e0 / @grouprows) * ((@pswr - 1e0) * @io)
हमारे मामले में, आपको मिलता है:
@rebindio = (1e0 / 200000) * ((3.99757445099277 - 1e0) * 0.369050925926054) = 0.000005531288
अंत में, ऑपरेटर की लागत है:
Operator cost: @firstexecution + @rebindcpu + @rebindio = 0.0032831 + 0.0006324 + 0.000005531288 = 0.003921031288
यह क्वेरी 4 की योजना में दिखाई गई इंडेक्स सीक ऑपरेटर लागत के समान है।
अब आप संपूर्ण क्वेरी योजना लागत प्राप्त करने के लिए सभी ऑपरेटरों की लागतों को जोड़ सकते हैं। आपको मिलता है:
Query plan cost: 0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00000418
+ @numgroups * 0.00000001
+ 0.0032831 + (@numgroups - 1e0) * 0.0001581
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) सरलीकरण के बाद, आपको हमारी सीक्स रणनीति के लिए निम्नलिखित पूर्ण लागत सूत्र मिलता है:
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) एक उदाहरण के रूप में, टी-एसक्यूएल का उपयोग करते हुए, क्वेरी 4 के लिए हमारी सीक्स रणनीति के साथ क्वेरी योजना लागत की गणना यहां दी गई है:
DECLARE
@numrows AS FLOAT = 1000000,
@numgroups AS FLOAT = 5,
@rowsperpage AS FLOAT = 404,
@groupsperpage AS FLOAT = 600;
SELECT
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0)))
AS seeksplancost; यह गणना क्वेरी 4 के लिए लागत 0.0072295 की गणना करती है। चित्र 3 में दिखाई गई अनुमानित लागत 0.0072299 है। यह काफी करीब है! एक अभ्यास के रूप में, इस सूत्र का उपयोग करके प्रश्न 5 और प्रश्न 6 के लिए लागतों की गणना करें और सत्यापित करें कि आपको संख्याएँ चित्र 3 में दिखाई गई संख्याओं के करीब मिलती हैं।
याद रखें कि डिफ़ॉल्ट स्कैन-आधारित रणनीति के लिए लागत सूत्र है (इसे स्कैन करें . कहते हैं) रणनीति):
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
एक उदाहरण के रूप में क्वेरी 1 का उपयोग करना, और तालिका में 1,000,000 पंक्तियों, प्रति पृष्ठ 404 पंक्तियों और 5 समूहों को मानते हुए, स्कैन रणनीति की अनुमानित क्वेरी योजना लागत 3.5366 है।
चित्र 6 दो रणनीतियों के लिए अनुमानित क्वेरी योजना लागत दिखाता है, जिसे क्वेरी 1 (स्कैन) और क्वेरी 4 (तलाश) द्वारा लागू किया जाता है, जिसमें 5 के समूहों की एक निश्चित संख्या दी जाती है, और मुख्य तालिका में पंक्तियों की अलग-अलग संख्या होती है।
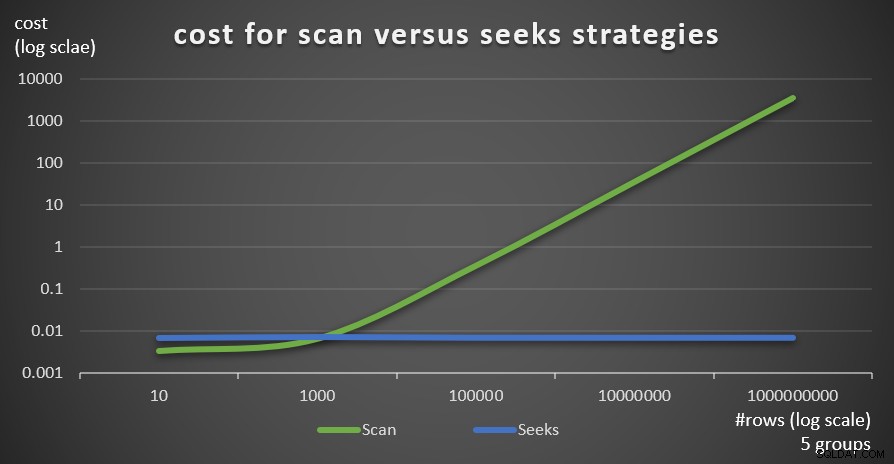 चित्र 6:लागत स्कैन बनाम सीक्स रणनीतियाँ (5 समूह)
चित्र 6:लागत स्कैन बनाम सीक्स रणनीतियाँ (5 समूह)
चित्र 7 दो रणनीतियों के लिए अनुमानित क्वेरी योजना लागत दिखाता है, 1,000,000 की मुख्य तालिका में पंक्तियों की एक निश्चित संख्या और समूहों की अलग-अलग संख्या दी गई है।
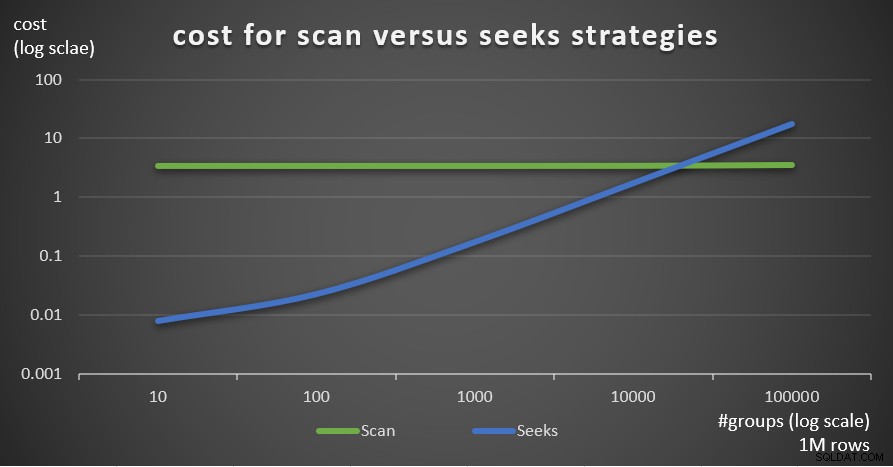 चित्र 7:लागत स्कैन बनाम सीक्स रणनीतियाँ (1M पंक्तियाँ)
चित्र 7:लागत स्कैन बनाम सीक्स रणनीतियाँ (1M पंक्तियाँ)
जैसा कि इन निष्कर्षों से स्पष्ट है, समूह घनत्व जितना अधिक होता है और मुख्य तालिका में जितनी अधिक पंक्तियाँ होती हैं, स्कैन रणनीति की तुलना में खोज रणनीति की तुलना में उतनी ही अधिक इष्टतम होती है। इसलिए, उच्च घनत्व वाले परिदृश्यों में, सुनिश्चित करें कि आप APPLY-आधारित समाधान का प्रयास करें। इस बीच, हम आशा कर सकते हैं कि Microsoft इस रणनीति को समूहबद्ध प्रश्नों के लिए एक अंतर्निहित विकल्प के रूप में जोड़ देगा।
निष्कर्ष
यह आलेख उन प्रश्नों के लिए क्वेरी ऑप्टिमाइज़ेशन थ्रेसहोल्ड पर पांच-भाग श्रृंखला का समापन करता है जो समूह और डेटा एकत्र करते हैं। श्रृंखला का एक लक्ष्य विभिन्न एल्गोरिदम की बारीकियों पर चर्चा करना था जो कि अनुकूलक उपयोग कर सकता है, जिन स्थितियों के तहत प्रत्येक एल्गोरिथ्म को प्राथमिकता दी जाती है, और जब आपको अपनी खुद की क्वेरी के साथ हस्तक्षेप करना चाहिए। एक अन्य लक्ष्य विभिन्न विकल्पों की खोज करने और उनकी तुलना करने की प्रक्रिया की व्याख्या करना था। जाहिर है, एक ही विश्लेषण प्रक्रिया को फ़िल्टरिंग, जॉइनिंग, विंडोिंग और क्वेरी ऑप्टिमाइज़ेशन के कई अन्य पहलुओं पर लागू किया जा सकता है। उम्मीद है, अब आप पहले की तुलना में क्वेरी ट्यूनिंग से निपटने के लिए अधिक सुसज्जित महसूस करेंगे।