कुछ दिलचस्प चर्चाएँ हमेशा बंटवारे के तार के विषय के आसपास विकसित होती हैं। पिछले दो ब्लॉग पोस्ट में, "स्प्लिट स्ट्रिंग्स द राइट वे - या नेक्स्ट बेस्ट वे" और "स्प्लिटिंग स्ट्रिंग्स:ए फॉलो-अप," मुझे आशा है कि मैंने यह प्रदर्शित किया है कि "सर्वश्रेष्ठ प्रदर्शन करने वाले" टी-एसक्यूएल स्प्लिट फ़ंक्शन का पीछा करना बेकार है। . जब विभाजन वास्तव में आवश्यक होता है, तो सीएलआर हमेशा जीतता है, और अगला सबसे अच्छा विकल्प वास्तविक कार्य के आधार पर भिन्न हो सकता है। लेकिन उन पोस्टों में मैंने संकेत दिया कि डेटाबेस पक्ष पर विभाजन पहली जगह में आवश्यक नहीं हो सकता है।
एसक्यूएल सर्वर 2008 ने टेबल-वैल्यू पैरामीटर पेश किए, एक स्ट्रिंग को बनाने और पार्स करने, एक्सएमएल को क्रमबद्ध करने, या इस विभाजन पद्धति से निपटने के बिना किसी एप्लिकेशन से "टेबल" को संग्रहीत प्रक्रिया में पास करने का एक तरीका। इसलिए मैंने सोचा कि मैं जांच करूंगा कि यह विधि हमारे पिछले परीक्षणों के विजेता की तुलना कैसे करती है - क्योंकि यह एक व्यवहार्य विकल्प हो सकता है, चाहे आप सीएलआर का उपयोग कर सकें या नहीं। (TVPs पर अंतिम बाइबल के लिए, कृपया साथी SQL सर्वर MVP Erland Somarskog का विस्तृत लेख देखें।)
परीक्षा
इस परीक्षण के लिए मैं दिखावा करने जा रहा हूं कि हम वर्जन स्ट्रिंग्स के एक सेट के साथ काम कर रहे हैं। एक सी # एप्लिकेशन की कल्पना करें जो इन स्ट्रिंग्स के एक सेट में गुजरता है (कहें, जो कि उपयोगकर्ताओं के एक सेट से एकत्र किए गए हैं) और हमें एक टेबल के खिलाफ संस्करणों से मिलान करने की आवश्यकता है (कहें, जो एक विशिष्ट सेट पर लागू होने वाली सेवा रिलीज को इंगित करता है संस्करणों के)। स्पष्ट रूप से एक वास्तविक एप्लिकेशन में इससे अधिक कॉलम होंगे, लेकिन बस कुछ वॉल्यूम बनाने के लिए और फिर भी टेबल को पतला रखने के लिए (मैं भी NVARCHAR का उपयोग करता हूं क्योंकि सीएलआर स्प्लिट फ़ंक्शन यही लेता है और मैं निहित रूपांतरण के कारण किसी भी अस्पष्टता को खत्म करना चाहता हूं) :
टेबल डीबीओ बनाएं। वर्जनस्ट्रिंग्स (बाएं_पोस्ट NVARCHAR (5), राइट_पोस्ट NVARCHAR (5)); dbo.VersionStrings (बाएं_पोस्ट, दाएं_पोस्ट) पर क्लस्टर इंडेक्स एक्स बनाएं;;एक्स एएस के साथ (चुनें एलपी =कन्वर्ट (दशमलव(4,3), राइट (आरटीआरआईएम (एस1। [ऑब्जेक्ट_आईडी]), 3)/1000.0 एस 1 क्रॉस जॉइन sys.all_objects एएस 2) डीबीओ डालें। वर्जनस्ट्रिंग्स (बाएं_पोस्ट, दाएं_पोस्ट) एलपी चुनें - केस जब एलपी> =0.9 फिर 0.1 ईएलएसई 0 END, एलपी + (0.1 * केस जब एलपी> =0.9 फिर -1 ईएलएसई 1 END) x से;
अब जब डेटा जगह पर है, तो अगली चीज़ जो हमें करने की ज़रूरत है वह एक उपयोगकर्ता-परिभाषित तालिका प्रकार बनाना है जो स्ट्रिंग्स का एक सेट रख सकता है। इस स्ट्रिंग को होल्ड करने के लिए प्रारंभिक तालिका प्रकार बहुत आसान है:
क्रिएट टाइप dbo.VersionStringsTVP as TABLE (VersionString NVARCHAR(5));
फिर हमें सी # से सूचियों को स्वीकार करने के लिए कुछ संग्रहित प्रक्रियाओं की आवश्यकता है। सरलता के लिए, फिर से, हम केवल एक गिनती लेंगे ताकि हम एक पूर्ण स्कैन करना सुनिश्चित कर सकें, और हम एप्लिकेशन में गिनती को अनदेखा कर देंगे:
CREATE PROCEDURE dbo.SplitTest_UsingCLR @list NVARCHAR(MAX)ASBEGIN SET NOCOUNT ON; dbo से c =COUNT(*) चुनें। dbo.VersionStringsTVP READONLYASBEGIN SET NOCOUNT ON; dbo से c =COUNT(*) चुनें।ध्यान दें कि एक संग्रहित प्रक्रिया में पारित एक टीवीपी को केवल पढ़ने के रूप में चिह्नित किया जाना चाहिए - वर्तमान में डेटा पर डीएमएल करने का कोई तरीका नहीं है जैसे आप तालिका चर या अस्थायी तालिका के लिए करेंगे। हालाँकि, एरलैंड ने एक बहुत लोकप्रिय अनुरोध प्रस्तुत किया है कि Microsoft इन मापदंडों को और अधिक लचीला (और यहाँ उनके तर्क के पीछे बहुत गहरी अंतर्दृष्टि) बनाए।
यहां सुंदरता यह है कि SQL सर्वर को अब एक स्ट्रिंग को विभाजित करने से निपटना नहीं पड़ता है - न तो टी-एसक्यूएल में और न ही इसे सीएलआर को सौंपने में - क्योंकि यह पहले से ही एक सेट संरचना में है जहां यह उत्कृष्ट है।
इसके बाद, एक C# कंसोल एप्लिकेशन जो निम्न कार्य करता है:
- एक संख्या को एक तर्क के रूप में स्वीकार करता है यह इंगित करने के लिए कि कितने स्ट्रिंग तत्वों को परिभाषित किया जाना चाहिए
- सीएलआर संग्रहित प्रक्रिया को पास करने के लिए स्ट्रिंगबिल्डर का उपयोग करके उन तत्वों की एक सीएसवी स्ट्रिंग बनाता है
- TVP संग्रहीत कार्यविधि को पास करने के लिए समान तत्वों के साथ एक डेटाटेबल बनाता है
- उपयुक्त संग्रहीत कार्यविधियों को कॉल करने से पहले CSV स्ट्रिंग को डेटाटेबल और इसके विपरीत में कनवर्ट करने के ओवरहेड का भी परीक्षण करता है
C# ऐप के लिए कोड लेख के अंत में मिलता है। मैं C# वर्तनी कर सकता हूं, लेकिन मैं किसी भी तरह से गुरु नहीं हूं; मुझे यकीन है कि ऐसी अक्षमताएं हैं जिन्हें आप वहां देख सकते हैं जो कोड को थोड़ा बेहतर प्रदर्शन कर सकते हैं। लेकिन इस तरह के किसी भी बदलाव से परीक्षणों के पूरे सेट पर समान प्रभाव पड़ना चाहिए।
मैंने 100, 1,000, 2,500 और 5,000 तत्वों का उपयोग करके 10 बार एप्लिकेशन चलाया। परिणाम इस प्रकार थे (यह औसत अवधि, सेकंड में, 10 परीक्षणों में दिखा रहा है):
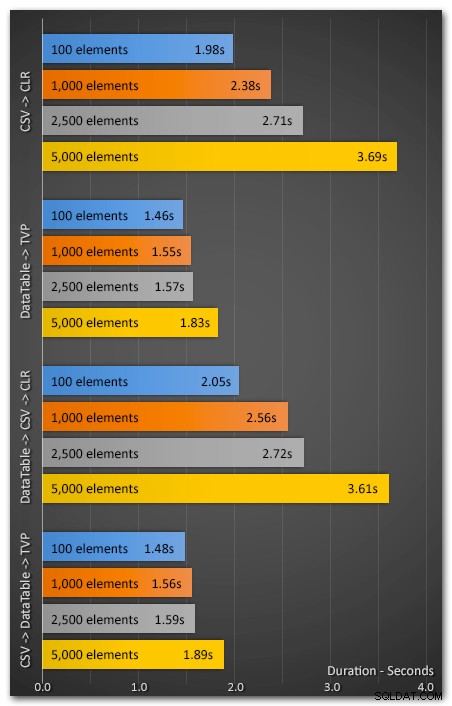
एक तरफ प्रदर्शन...
स्पष्ट प्रदर्शन अंतर के अलावा, टीवीपी का एक और फायदा है - टेबल प्रकार सीएलआर असेंबली की तुलना में तैनात करने के लिए बहुत आसान हैं, खासकर ऐसे वातावरण में जहां सीएलआर को अन्य कारणों से मना किया गया है। मैं उम्मीद कर रहा हूं कि सीएलआर की बाधाएं धीरे-धीरे गायब हो रही हैं, और नए उपकरण परिनियोजन और रखरखाव को कम दर्दनाक बना रहे हैं, लेकिन मुझे संदेह है कि सीएलआर के लिए प्रारंभिक परिनियोजन की आसानी कभी भी देशी तरीकों की तुलना में आसान होगी।
दूसरी ओर, केवल-पढ़ने की सीमा के शीर्ष पर, तालिका प्रकार उपनाम प्रकार की तरह होते हैं, जिसमें तथ्य के बाद उन्हें संशोधित करना मुश्किल होता है। यदि आप किसी कॉलम का आकार बदलना चाहते हैं या एक कॉलम जोड़ना चाहते हैं, तो कोई ALTER TYPE कमांड नहीं है, और टाइप को DROP करने और इसे फिर से बनाने के लिए, आपको पहले उन सभी प्रक्रियाओं से टाइप के संदर्भों को हटाना होगा जो इसका उपयोग कर रही हैं। . तो उदाहरण के लिए उपरोक्त मामले में यदि हमें संस्करणस्ट्रिंग कॉलम को NVARCHAR (32) तक बढ़ाने की आवश्यकता है, तो हमें एक डमी प्रकार बनाना होगा और संग्रहीत प्रक्रिया को बदलना होगा (और कोई अन्य प्रक्रिया जो इसका उपयोग कर रही है):
क्रिएट टाइप dbo.VersionStringsTVPटेबल के रूप में कॉपी करें (VersionString NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVPC कॉपी रीडोनलीएएस ... NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVP READONLYAS... GO DROP TYPE dbo.VersionStringsTVPCopy;GO
(या वैकल्पिक रूप से, प्रक्रिया को छोड़ दें, प्रकार को छोड़ दें, प्रकार को फिर से बनाएं और प्रक्रिया को फिर से बनाएं।)
निष्कर्ष
टीवीपी पद्धति ने लगातार सीएलआर बंटवारे की पद्धति से बेहतर प्रदर्शन किया, और तत्वों की संख्या में वृद्धि के रूप में अधिक प्रतिशत से। मौजूदा सीएसवी स्ट्रिंग को डेटाटेबल में कनवर्ट करने के ऊपरी हिस्से में जोड़ने से भी बेहतर एंड-टू-एंड प्रदर्शन प्राप्त हुआ। तो मुझे उम्मीद है कि, अगर मैंने आपको पहले से ही सीएलआर के पक्ष में अपनी टी-एसक्यूएल स्ट्रिंग स्प्लिटिंग तकनीकों को छोड़ने के लिए आश्वस्त नहीं किया था, तो मैंने आपसे टेबल-मूल्यवान पैरामीटर को एक शॉट देने का आग्रह किया है। यदि आप वर्तमान में डेटाटेबल (या कुछ समकक्ष) का उपयोग नहीं कर रहे हैं, तो भी इसका परीक्षण करना आसान होना चाहिए।
इन परीक्षणों के लिए प्रयुक्त C# कोड
जैसा कि मैंने कहा, मैं कोई C# गुरु नहीं हूं, इसलिए शायद मैं यहां बहुत सारी भोली-भाली चीजें कर रहा हूं, लेकिन कार्यप्रणाली बिल्कुल स्पष्ट होनी चाहिए।
सिस्टम का उपयोग करना; System.IO का उपयोग करना; System.Data का उपयोग करना; System.Data.SqlClient का उपयोग करना; System.Text का उपयोग करना; System.Collections का उपयोग करना; नेमस्पेस स्प्लिटटेस्टर {वर्ग स्प्लिट टेस्टर {स्थिर शून्य मुख्य (स्ट्रिंग [] तर्क) {डेटाटेबल dt_pure =नया डेटाटेबल (); dt_pure.Columns.Add("Item", typeof(string)); स्ट्रिंगबिल्डर sb_pure =नया स्ट्रिंगबिल्डर (); रैंडम आर =नया रैंडम (); के लिए (int i =1; i <=Int32.Parse(args[0]); i++) {स्ट्रिंग x =r.NextDouble ()। ToString ()। सबस्ट्रिंग (0,5); sb_pure.Append(x).Append(","); dt_pure.rows.Add(x); } का उपयोग कर (एसक्लकनेक्शन कॉन =नया एसक्यूएलकनेक्शन (@ "डेटा स्रोत =।; Trusted_Connection =हाँ; प्रारंभिक कैटलॉग =स्प्लिटर")) {conn.Open (); // चार मामले:// (1) CSV स्ट्रिंग को सीधे CLR स्प्लिट प्रक्रिया में पास करें // (2) डेटाटेबल को सीधे TVP प्रक्रिया में पास करें // (3) डेटाटेबल से CSV स्ट्रिंग को क्रमबद्ध करें और CSV को CLR प्रक्रिया में पास करें // (4) सीएसवी स्ट्रिंग से डेटाटेबल को पॉप्युलेट करें और डेटाटेबल को टीसीपी प्रक्रिया में पास करें // *********** (1) ********* // लिखें (पर्यावरण। न्यूलाइन + "प्रारंभ (1)" ); SqlCommand c1 =नया SqlCommand ("dbo.SplitTest_UsingCLR", conn); c1.CommandType =CommandType.StoreedProcedure; c1.Parameters.AddWithValue("@list", sb_pure.ToString ()); c1.ExecuteNonQuery (); c1.निपटान (); लिखें ("समाप्त (1)"); // *********** (2) ********** // लिखें (पर्यावरण। न्यूलाइन + "प्रारंभ (2)"); SqlCommand c2 =नया SqlCommand ("dbo.SplitTest_UsingTVP", conn); c2.CommandType =CommandType.StoreedProcedure; SqlParameter tvp1 =c2.Parameters.AddWithValue("@list", dt_pure); tvp1.SqlDbType =SqlDbType.Structured; c2.ExecuteNonQuery (); c2.डिस्पोज (); लिखें ("समाप्त (2)"); // *********** (3) *********** // लिखें (पर्यावरण। न्यूलाइन + "प्रारंभ (3)"); स्ट्रिंगबिल्डर sb_fake =नया स्ट्रिंगबिल्डर (); foreach (DataRow dr in dt_pure.Rows) {sb_fake.Append(dr.ItemArray[0].ToString()).Append(","); } SqlCommand c3 =नया SqlCommand ("dbo.SplitTest_UsingCLR", conn); c3.CommandType =CommandType.StoreedProcedure; c3.Parameters.AddWithValue("@list", sb_fake.ToString ()); c3.ExecuteNonQuery (); c3.निपटान (); लिखें ("समाप्त (3)"); // *********** (4) *********** // लिखें (पर्यावरण। न्यूलाइन + "प्रारंभ (4)"); डेटाटेबल dt_fake =नया डेटाटेबल (); dt_fake.Columns.Add("Item", typeof(string)); स्ट्रिंग [] सूची =sb_pure.ToString ()। स्प्लिट (','); for (int i =0; i 0) { dt_fake.Rows.Add(list[i]); } } SqlCommand c4 =नया SqlCommand ("dbo.SplitTest_UsingTVP", conn); c4.CommandType =CommandType.StoreedProcedure; SqlParameter tvp2 =c4.Parameters.AddWithValue("@list", dt_fake); tvp2.SqlDbType =SqlDbType.Structured; c4.ExecuteNonQuery (); c4.निपटान (); लिखें ("समाप्त (4)"); } } स्थिर शून्य लिखना (स्ट्रिंग संदेश) {कंसोल। राइटलाइन (msg + ":" + डेटटाइम। UtcNow.ToString ("HH:मिमी:ss.fffff")); } }}