SQL सर्वर में तालिका विभाजन अनिवार्य रूप से एक ही तालिका की तरह कई भौतिक तालिकाओं (पंक्तियों) को बनाने का एक तरीका है। यह अमूर्तन पूरी तरह से क्वेरी प्रोसेसर द्वारा किया जाता है, एक ऐसा डिज़ाइन जो उपयोगकर्ताओं के लिए चीजों को सरल बनाता है, लेकिन जो क्वेरी ऑप्टिमाइज़र की जटिल माँगों को पूरा करता है। यह पोस्ट दो उदाहरणों को देखती है जो SQL सर्वर 2008 में ऑप्टिमाइज़र की क्षमताओं से आगे निकल जाते हैं।
कॉलम ऑर्डर मामलों में शामिल हों
यह पहला उदाहरण दिखाता है कि ON . का टेक्स्ट क्रम कैसा है खंड की स्थिति विभाजित तालिकाओं में शामिल होने पर उत्पन्न क्वेरी योजना को प्रभावित कर सकती है। आरंभ करने के लिए, हमें एक विभाजन योजना, एक विभाजन फ़ंक्शन और दो तालिकाओं की आवश्यकता होती है:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); इसके बाद, हम दोनों तालिकाओं को 150,000 पंक्तियों के साथ लोड करते हैं। डेटा बहुत ज्यादा मायने नहीं रखता; यह उदाहरण एक मानक संख्या तालिका का उपयोग करता है जिसमें डेटा स्रोत के रूप में 1 से 150,000 तक के सभी पूर्णांक मान होते हैं। दोनों टेबल एक ही डेटा से भरी हुई हैं।
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
हमारी परीक्षण क्वेरी इन दो तालिकाओं का एक साधारण आंतरिक जुड़ाव करती है। फिर, क्वेरी महत्वपूर्ण नहीं है या विशेष रूप से यथार्थवादी होने का इरादा नहीं है, इसका उपयोग विभाजित तालिकाओं में शामिल होने पर एक अजीब प्रभाव प्रदर्शित करने के लिए किया जाता है। क्वेरी का पहला रूप ON . का उपयोग करता है c3, c2, c1 कॉलम क्रम में लिखा गया क्लॉज:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; इस क्वेरी के लिए तैयार की गई निष्पादन योजना (एसक्यूएल सर्वर 2008 और बाद में) में समानांतर हैश जॉइन की सुविधा है, जिसकी अनुमानित लागत 2.6953 है। :
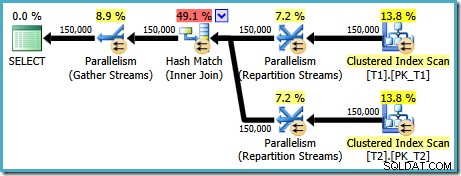
यह थोड़ा अप्रत्याशित है। दोनों तालिकाओं में (c1, c2, c3) क्रम में एक संकुल अनुक्रमणिका है, जो c1 द्वारा विभाजित है, इसलिए हम अनुक्रमणिका क्रम का लाभ उठाते हुए विलय में शामिल होने की अपेक्षा करेंगे। आइए ONलिखने का प्रयास करें इसके बजाय (c1, c2, c3) क्रम में खंड:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; निष्पादन योजना अब अपेक्षित मर्ज जॉइन का उपयोग करती है, जिसकी अनुमानित लागत 1.64119 . है (2.6953 . से नीचे ) ऑप्टिमाइज़र यह भी तय करता है कि यह समानांतर निष्पादन का उपयोग करने लायक नहीं है:
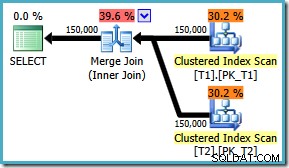
यह देखते हुए कि मर्ज में शामिल होने की योजना स्पष्ट रूप से अधिक कुशल है, हम मूल ON के लिए मर्ज में शामिल होने के लिए बाध्य करने का प्रयास कर सकते हैं एक क्वेरी संकेत का उपयोग करते हुए क्लॉज ऑर्डर:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); परिणामी योजना अनुरोध के अनुसार मर्ज जॉइन का उपयोग करती है, लेकिन इसमें दोनों इनपुट पर प्रकार भी शामिल हैं, और समांतरता का उपयोग करने के लिए वापस चला जाता है। इस योजना की अनुमानित लागत बहुत अधिक है 8.71063 :
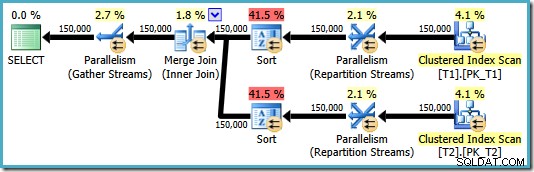
दोनों प्रकार के ऑपरेटरों में समान गुण होते हैं:
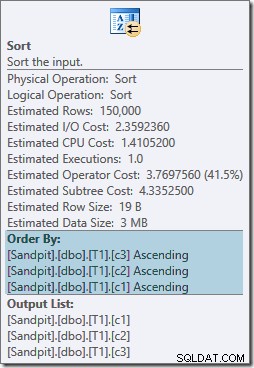
ऑप्टिमाइज़र को लगता है कि मर्ज जॉइन को इसके इनपुट्स को ON के सख्त लिखित क्रम में क्रमबद्ध करने की आवश्यकता है खंड, एक परिणाम के रूप में स्पष्ट प्रकार का परिचय। ऑप्टिमाइज़र इस बात से अवगत है कि मर्ज जॉइन के लिए उसके इनपुट को उसी तरह सॉर्ट करने की आवश्यकता होती है, लेकिन यह भी जानता है कि कॉलम ऑर्डर कोई मायने नहीं रखता। मर्ज जॉइन ऑन (c1, c2, c3) (c3, c2, c1) पर सॉर्ट किए गए इनपुट से भी उतना ही खुश है जितना कि इनपुट (c2, c1, c3) या किसी अन्य संयोजन पर सॉर्ट किए गए इनपुट के साथ।
दुर्भाग्य से, विभाजन शामिल होने पर यह तर्क क्वेरी ऑप्टिमाइज़र में टूट जाता है। यह एक अनुकूलक बग है जिसे SQL Server 2008 R2 और बाद के संस्करणों में ठीक किया गया है, हालांकि ट्रेस फ़्लैग 4199 सुधार को सक्रिय करने के लिए आवश्यक है:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
आप आमतौर पर DBCC TRACEON . का उपयोग करके इस ट्रेस फ़्लैग को सक्षम करेंगे या एक स्टार्ट-अप विकल्प के रूप में, क्योंकि QUERYTRACEON संकेत 4199 के साथ उपयोग के लिए प्रलेखित नहीं है। SQL Server 2008 R2, SQL Server 2012 और SQL Server 2014 CTP1 में ट्रेस ध्वज की आवश्यकता है।
वैसे भी, ध्वज को कभी भी सक्षम किया जाता है, क्वेरी अब इष्टतम मर्ज उत्पन्न करती है जो भी ON क्लॉज ऑर्डरिंग:
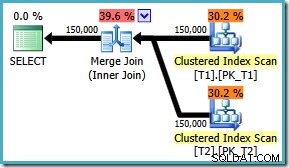
SQL Server 2008 के लिए कोई समाधान नहीं है , समाधान ON . लिखना है 'सही' क्रम में खंड! यदि आप SQL Server 2008 पर इस तरह की एक क्वेरी का सामना करते हैं, तो मर्ज में शामिल होने का प्रयास करें और अपनी क्वेरी के ON लिखने के 'सही' तरीके को निर्धारित करने के लिए प्रकारों को देखें। खंड।
SQL सर्वर 2005 में यह समस्या उत्पन्न नहीं होती है क्योंकि उस रिलीज़ ने APPLY . का उपयोग करके विभाजित प्रश्नों को लागू किया है मॉडल:

SQL सर्वर 2005 क्वेरी योजना एक इन-मेमोरी टेबल (कॉन्स्टेंट स्कैन) का उपयोग करके एक समय में प्रत्येक तालिका से एक पार्टीशन में शामिल होती है, जिसमें प्रोसेस करने के लिए पार्टीशन नंबर होते हैं। प्रत्येक पार्टिशन को जॉइन के अंदरूनी हिस्से पर अलग से मर्ज किया जाता है, और 2005 ऑप्टिमाइज़र यह देखने के लिए पर्याप्त स्मार्ट है कि ON क्लॉज कॉलम ऑर्डर कोई मायने नहीं रखता।
यह नवीनतम योजना कोलोकेटेड मर्ज जॉइन . का एक उदाहरण है , एक सुविधा जो SQL Server 2005 से SQL Server 2008 में नए विभाजन कार्यान्वयन के लिए जाने पर खो गई थी। कोलोकेटेड मर्ज जॉइन को पुनर्स्थापित करने के लिए कनेक्ट पर एक सुझाव को ठीक नहीं किया गया है।
ग्रुप बाय ऑर्डर मैटर्स
दूसरी ख़ासियत जिसे मैं देखना चाहता हूं, एक समान विषय का अनुसरण करता है, लेकिन एक GROUP BY में कॉलम के क्रम से संबंधित है। ON . के बजाय खंड एक आंतरिक जुड़ाव का खंड। प्रदर्शित करने के लिए हमें एक नई तालिका की आवश्यकता होगी:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; तालिका में एक संरेखित गैर-संकुल सूचकांक है, जहां 'संरेखित' का सीधा सा अर्थ है कि यह उसी तरह से विभाजित है जैसे कि संकुल सूचकांक (या ढेर):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
हमारी परीक्षण क्वेरी तीन गैर-संकुल अनुक्रमणिका स्तंभों में डेटा समूहित करती है और प्रत्येक समूह के लिए एक गणना लौटाती है:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
क्वेरी प्लान गैर-क्लस्टर इंडेक्स को स्कैन करता है और प्रत्येक समूह में पंक्तियों की गणना करने के लिए हैश मैच एग्रीगेट का उपयोग करता है:
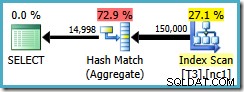
हैश एग्रीगेट के साथ दो समस्याएं हैं:
- यह एक ब्लॉकिंग ऑपरेटर है। क्लाइंट को तब तक कोई पंक्तियाँ नहीं लौटाई जाती हैं जब तक कि सभी पंक्तियों को एकत्र नहीं कर लिया जाता।
- हैश टेबल को होल्ड करने के लिए मेमोरी ग्रांट की जरूरत होती है।
कई वास्तविक दुनिया के परिदृश्यों में, हम यहां एक स्ट्रीम एग्रीगेट पसंद करेंगे क्योंकि वह ऑपरेटर केवल प्रति समूह अवरुद्ध कर रहा है, और उसे स्मृति अनुदान की आवश्यकता नहीं है। इस विकल्प का उपयोग करते हुए, क्लाइंट एप्लिकेशन को पहले डेटा प्राप्त करना शुरू हो जाएगा, उसे मेमोरी प्रदान करने की प्रतीक्षा नहीं करनी होगी, और SQL सर्वर अन्य उद्देश्यों के लिए मेमोरी का उपयोग कर सकता है।
हम एक OPTION (ORDER GROUP) जोड़कर इस क्वेरी के लिए एक स्ट्रीम एग्रीगेट का उपयोग करने के लिए क्वेरी ऑप्टिमाइज़र की आवश्यकता कर सकते हैं प्रश्न संकेत। इसका परिणाम निम्नलिखित निष्पादन योजना में होता है:

सॉर्ट ऑपरेटर पूरी तरह से ब्लॉक कर रहा है और इसके लिए मेमोरी ग्रांट की भी आवश्यकता होती है, इसलिए यह योजना केवल हैश एग्रीगेट का उपयोग करने से भी बदतर प्रतीत होती है। लेकिन इस तरह की जरूरत क्यों है? गुण बताते हैं कि पंक्तियों को हमारे GROUP BY . द्वारा निर्दिष्ट क्रम में क्रमबद्ध किया जा रहा है खंड:
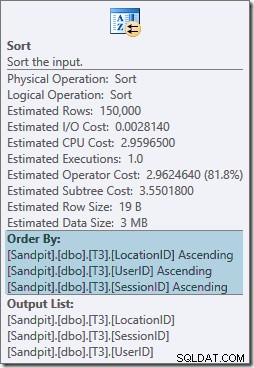
यह क्रम अपेक्षित है क्योंकि विभाजन-संरेखण सूचकांक (एसक्यूएल सर्वर 2008 में आगे) का अर्थ है कि विभाजन संख्या को सूचकांक के प्रमुख कॉलम के रूप में जोड़ा जाता है। वास्तव में, विभाजन के कारण गैर-संकुल सूचकांक कुंजियाँ (विभाजन, उपयोगकर्ता, सत्र, स्थान) हैं। अनुक्रमणिका में पंक्तियाँ अभी भी उपयोगकर्ता, सत्र और स्थान के अनुसार क्रमबद्ध हैं, लेकिन केवल प्रत्येक विभाजन के भीतर।
यदि हम क्वेरी को एक ही पार्टीशन तक सीमित रखते हैं, तो ऑप्टिमाइज़र को बिना सॉर्ट किए स्ट्रीम एग्रीगेट को फीड करने के लिए इंडेक्स का उपयोग करने में सक्षम होना चाहिए। यदि इसके लिए कुछ स्पष्टीकरण की आवश्यकता होती है, तो एकल विभाजन निर्दिष्ट करने का अर्थ है कि क्वेरी योजना गैर-संकुल सूचकांक स्कैन से अन्य सभी विभाजनों को समाप्त कर सकती है, जिसके परिणामस्वरूप पंक्तियों की एक धारा (उपयोगकर्ता, सत्र, स्थान) द्वारा क्रमबद्ध होती है।
हम स्पष्ट रूप से $PARTITION . का उपयोग करके इस विभाजन उन्मूलन को प्राप्त कर सकते हैं समारोह:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
दुर्भाग्य से, यह क्वेरी अभी भी हैश एग्रीगेट का उपयोग करती है, जिसकी अनुमानित योजना लागत 0.287878 है :
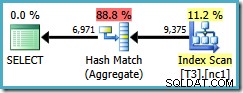
स्कैन अब केवल एक विभाजन से अधिक है, लेकिन (उपयोगकर्ता, सत्र, स्थान) क्रम ने अनुकूलक को स्ट्रीम एग्रीगेट का उपयोग करने में मदद नहीं की है। आपको इस बात पर आपत्ति हो सकती है कि (उपयोगकर्ता, सत्र, स्थान) आदेश देना सहायक नहीं है क्योंकि GROUP BY क्लॉज है (स्थान, उपयोगकर्ता, सत्र), लेकिन समूह संचालन के लिए कुंजी क्रम मायने नहीं रखता।
आइए एक ORDER BY . जोड़ें बिंदु को साबित करने के लिए इंडेक्स कीज़ के क्रम में क्लॉज:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
ध्यान दें कि ORDER BY क्लॉज गैर-संकुल सूचकांक कुंजी क्रम से मेल खाता है, हालांकि GROUP BY उपवाक्य नहीं है। इस क्वेरी के लिए निष्पादन योजना है:
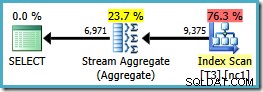
0.0423925 की अनुमानित योजना लागत के साथ अब हमारे पास वह स्ट्रीम एग्रीगेट है जिसके बाद हम थे (0.287878 . की तुलना में) हैश एग्रीगेट प्लान के लिए - लगभग 7 गुना अधिक)।
यहां स्ट्रीम एग्रीगेट हासिल करने का दूसरा तरीका है GROUP BY को फिर से व्यवस्थित करना गैर-संकुल अनुक्रमणिका कुंजियों से मेल खाने वाले स्तंभ:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
यह क्वेरी ठीक उसी लागत के साथ, ऊपर दिखाए गए समान स्ट्रीम एग्रीगेट प्लान तैयार करती है। GROUP BY . के प्रति यह संवेदनशीलता स्तंभ क्रम SQL Server 2008 और बाद में विभाजित तालिका प्रश्नों के लिए विशिष्ट है।
आप पहचान सकते हैं कि यहां समस्या का मूल कारण पिछले मामले के समान है जिसमें मर्ज जॉइन शामिल है। मर्ज जॉइन और स्ट्रीम एग्रीगेट दोनों को जॉइन या एग्रीगेशन कुंजियों पर सॉर्ट किए गए इनपुट की आवश्यकता होती है, लेकिन न तो उन चाबियों के क्रम की परवाह करता है। मर्ज जॉइन ऑन (x, y, z) ठीक उसी तरह है जैसे (y, z, x) या (z, y, x) द्वारा ऑर्डर की गई पंक्तियों को प्राप्त करना और स्ट्रीम एग्रीगेट के लिए भी यही सच है।
यह अनुकूलक सीमा DISTINCT . पर भी लागू होती है उन्हीं परिस्थितियों में। निम्न क्वेरी के परिणामस्वरूप 0.286539 . की अनुमानित लागत वाली हैश एग्रीगेट योजना बनती है :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
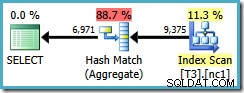
अगर हम DISTINCT . लिखते हैं गैर-संकुल अनुक्रमणिका कुंजियों के क्रम में स्तंभ…
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
…हमें 0.041455 . की लागत वाली स्ट्रीम एग्रीगेट योजना से पुरस्कृत किया गया है :

संक्षेप में, यह SQL Server 2008 और बाद में (SQL Server 2014 CTP 1 सहित) क्वेरी ऑप्टिमाइज़र की एक सीमा है जिसे ट्रेस फ़्लैग 4199 का उपयोग करके हल नहीं किया गया है जैसा कि मर्ज जॉइन उदाहरण के मामले में था। समस्या केवल GROUP BY . के साथ विभाजित तालिकाओं के साथ होती है या DISTINCT संरेखित विभाजन अनुक्रमणिका का उपयोग करते हुए तीन या अधिक स्तंभों से अधिक, जहां एकल विभाजन संसाधित किया जाता है।
मर्ज जॉइन उदाहरण के साथ, यह SQL सर्वर 2005 व्यवहार से एक पिछड़े कदम का प्रतिनिधित्व करता है। SQL Server 2005 ने APPLY का उपयोग करते हुए, विभाजित अनुक्रमणिका में एक अंतर्निहित अग्रणी कुंजी नहीं जोड़ी इसके बजाय तकनीक। SQL सर्वर 2005 में, $PARTITION . का उपयोग करके यहां प्रस्तुत सभी प्रश्न क्वेरी योजनाओं में एकल विभाजन परिणाम निर्दिष्ट करने के लिए जो विभाजन को समाप्त करता है और बिना किसी क्वेरी टेक्स्ट रीऑर्डरिंग के स्ट्रीम एग्रीगेट्स का उपयोग करता है।
SQL सर्वर 2008 में विभाजित तालिका प्रसंस्करण में परिवर्तन ने कई महत्वपूर्ण क्षेत्रों में प्रदर्शन में सुधार किया, मुख्य रूप से विभाजन के कुशल समानांतर प्रसंस्करण से संबंधित। दुर्भाग्य से, इन परिवर्तनों के दुष्प्रभाव थे जो बाद के रिलीज में सभी को हल नहीं किया गया है।