SQL Server 2005 और SQL Server 2008 के बीच विभाजित तालिकाओं के आंतरिक प्रतिनिधित्व में परिवर्तन के परिणामस्वरूप अधिकांश मामलों में बेहतर क्वेरी योजना और प्रदर्शन हुआ (विशेषकर जब समानांतर निष्पादन शामिल है)। दुर्भाग्य से, उन्हीं परिवर्तनों के कारण कुछ चीजें जो SQL सर्वर 2005 में अच्छी तरह से काम करती थीं, अचानक SQL Server 2008 और बाद में इतनी अच्छी तरह से काम नहीं करती थीं। यह पोस्ट एक ऐसे उदाहरण को देखता है जहां SQL सर्वर 2005 क्वेरी ऑप्टिमाइज़र ने बाद के संस्करणों की तुलना में बेहतर निष्पादन योजना तैयार की।
नमूना तालिका और डेटा
इस पोस्ट के उदाहरण निम्न विभाजित तालिका और डेटा का उपयोग करते हैं:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); विभाजित डेटा लेआउट
हमारी तालिका में एक विभाजित क्लस्टर इंडेक्स है। इस मामले में, क्लस्टरिंग कुंजी विभाजन कुंजी के रूप में भी कार्य करती है (हालांकि यह सामान्य रूप से एक आवश्यकता नहीं है)। अलग-अलग भौतिक भंडारण इकाइयों (रोसेट्स) में विभाजन का परिणाम होता है जो क्वेरी प्रोसेसर उपयोगकर्ताओं को एक इकाई के रूप में प्रस्तुत करता है।
नीचे दिया गया आरेख हमारी तालिका के पहले तीन विभाजन दिखाता है (विस्तार करने के लिए क्लिक करें):
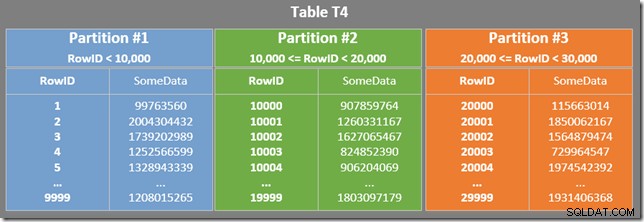
गैर-संकुल सूचकांक को उसी तरह विभाजित किया गया है (यह "गठबंधन" है):

गैर-संकुल सूचकांक के प्रत्येक विभाजन में RowID मानों की एक श्रृंखला शामिल होती है। प्रत्येक विभाजन के भीतर, डेटा SomeData द्वारा आदेशित किया जाता है (लेकिन RowID मानों को सामान्य रूप से आदेशित नहीं किया जाएगा)।
न्यूनतम/अधिकतम समस्या
यह सर्वविदित है कि MIN और MAX समुच्चय विभाजित तालिकाओं पर अच्छी तरह से अनुकूलित नहीं होते हैं (जब तक कि स्तंभ को एकत्रित किया जाना भी विभाजन स्तंभ नहीं होता है)। यह सीमा (जो अभी भी SQL Server 2014 CTP 1 में मौजूद है) वर्षों में कई बार लिखी गई है; मेरा पसंदीदा कवरेज इत्ज़िक बेन-गण के इस लेख में है। इस मुद्दे को संक्षेप में स्पष्ट करने के लिए, निम्नलिखित प्रश्न पर विचार करें:
SELECT MIN(SomeData) FROM dbo.T4;
SQL Server 2008 या इसके बाद के संस्करण पर निष्पादन योजना इस प्रकार है:

यह योजना सूचकांक से सभी 150,000 पंक्तियों को पढ़ती है और एक स्ट्रीम एग्रीगेट न्यूनतम मूल्य की गणना करता है (यदि हम इसके बजाय अधिकतम मूल्य का अनुरोध करते हैं तो निष्पादन योजना अनिवार्य रूप से समान है)। SQL सर्वर 2005 निष्पादन योजना थोड़ी अलग है (हालांकि बेहतर नहीं):
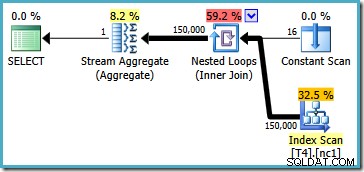
यह योजना विभाजन संख्या (स्थिर स्कैन में सूचीबद्ध) पर एक बार में पूरी तरह से एक विभाजन को स्कैन करती है। सभी 150,000 पंक्तियों को अब भी अंततः स्ट्रीम एग्रीगेट द्वारा पढ़ा और संसाधित किया जाता है।
विभाजित तालिका और अनुक्रमणिका आरेखों को देखें और सोचें कि हमारे डेटा सेट पर क्वेरी को अधिक कुशलता से कैसे संसाधित किया जा सकता है। गैर-संकुल अनुक्रमणिका क्वेरी को हल करने के लिए एक अच्छा विकल्प लगता है क्योंकि इसमें कुछ डेटा मान एक क्रम में होते हैं जिनका उपयोग समग्र की गणना करते समय किया जा सकता है।
अब, यह तथ्य कि सूचकांक का विभाजन किया गया है, थोड़ा जटिल है:प्रत्येक विभाजन इंडेक्स का कुछ डेटा कॉलम द्वारा आदेश दिया गया है, लेकिन हम किसी भी विशेष से न्यूनतम मान को आसानी से नहीं पढ़ सकते हैं पूरे प्रश्न का सही उत्तर पाने के लिए विभाजन।
एक बार जब समस्या की आवश्यक प्रकृति को समझ लिया जाता है, तो एक इंसान यह देख सकता है कि एक कुशल रणनीति यह होगी कि प्रत्येक विभाजन में के एकल न्यूनतम मूल्य का पता लगाया जाए सूचकांक का, और फिर प्रति-विभाजन परिणामों से न्यूनतम मान लें।
यह अनिवार्य रूप से समाधान है जिसे इत्ज़िक अपने लेख में प्रस्तुत करता है; कुल प्रति-विभाजन की गणना करने के लिए क्वेरी को फिर से लिखें (APPLY . का उपयोग करके सिंटैक्स) और फिर उन प्रति-विभाजन परिणामों पर फिर से एकत्रित करें। उस दृष्टिकोण का उपयोग करते हुए, फिर से लिखा गया MIN query इस निष्पादन योजना का निर्माण करता है (सटीक सिंटैक्स के लिए इट्ज़िक का लेख देखें):
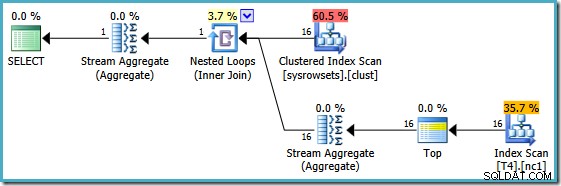
यह योजना सिस्टम तालिका से विभाजन संख्याओं को पढ़ती है, और प्रत्येक विभाजन में SomeData के निम्नतम मान को पुनः प्राप्त करती है। अंतिम स्ट्रीम एग्रीगेट प्रति-विभाजन परिणामों पर न्यूनतम गणना करता है।
इस योजना की महत्वपूर्ण विशेषता यह है कि यह एक एकल पंक्ति . को पढ़ता है प्रत्येक विभाजन से (प्रत्येक विभाजन के भीतर अनुक्रमणिका के क्रमबद्ध क्रम का शोषण)। यह अनुकूलक की योजना से कहीं अधिक कुशल है जिसने तालिका में सभी 150,000 पंक्तियों को संसाधित किया।
एक ही विभाजन में MIN और MAX
अब कुछ डेटा कॉलम में न्यूनतम मान खोजने के लिए निम्न क्वेरी पर विचार करें, जो कि पंक्तिबद्ध मानों की एक श्रेणी के लिए है जो एकल विभाजन के भीतर शामिल हैं। :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
हमने देखा है कि अनुकूलक को MIN के साथ समस्या है और MAX कई विभाजनों पर, लेकिन हम उम्मीद करेंगे कि वे सीमाएँ एकल विभाजन क्वेरी पर लागू न हों।
एकल विभाजन वह है जो RowID मान 10,000 और 20,000 से घिरा है (विभाजन फ़ंक्शन परिभाषा को देखें)। विभाजन फ़ंक्शन को RANGE RIGHT . के रूप में परिभाषित किया गया था , इसलिए 10,000 सीमा मान विभाजन #2 से संबंधित है और 20,000 सीमा विभाजन #3 से संबंधित है। इसलिए हमारी नई क्वेरी द्वारा निर्दिष्ट RowID मानों की श्रेणी अकेले विभाजन 2 के भीतर समाहित है।
इस क्वेरी के लिए ग्राफिकल निष्पादन योजना 2005 से सभी SQL सर्वर संस्करणों पर समान दिखती है:
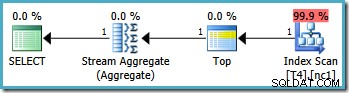
योजना विश्लेषण
अनुकूलक ने WHERE . में निर्दिष्ट RowID श्रेणी को लिया खंड और इसकी तुलना विभाजन फ़ंक्शन परिभाषा के साथ यह निर्धारित करने के लिए कि गैर-संकुल सूचकांक के केवल विभाजन 2 को एक्सेस करने की आवश्यकता है। इंडेक्स स्कैन के लिए SQL सर्वर 2005 योजना गुण एकल-विभाजन पहुँच को स्पष्ट रूप से दिखाता है:
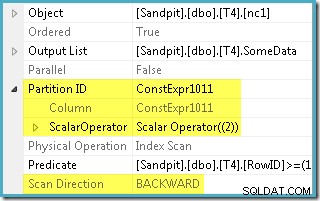
अन्य हाइलाइट की गई संपत्ति स्कैन दिशा है। स्कैन का क्रम इस बात पर निर्भर करता है कि क्वेरी न्यूनतम या अधिकतम SomeData मान की तलाश में है या नहीं। गैर-संकुलित अनुक्रमणिका का आदेश दिया गया है (प्रति विभाजन, याद रखें) आरोही SomeData मानों पर, इसलिए अनुक्रमणिका स्कैन दिशा FORWARD है यदि क्वेरी न्यूनतम मान मांगती है, और BACKWARD यदि अधिकतम मूल्य की आवश्यकता है (उपरोक्त स्क्रीन शॉट MAX . से लिया गया था क्वेरी योजना)।
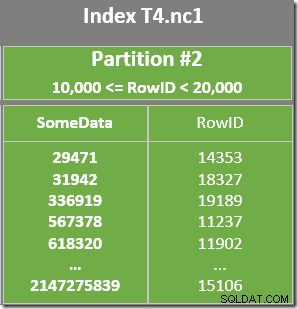
यह जांचने के लिए कि विभाजन 2 से स्कैन किए गए RowID मान WHERE से मेल खाते हैं, इंडेक्स स्कैन पर एक अवशिष्ट विधेय भी है। खंड विधेय। ऑप्टिमाइज़र मानता है कि RowID मान गैर-संकुल सूचकांक के माध्यम से बहुत बेतरतीब ढंग से वितरित किए जाते हैं, इसलिए यह पहली पंक्ति खोजने की अपेक्षा करता है जो WHERE से मेल खाती है खंड बहुत जल्दी भविष्यवाणी करता है। विभाजित डेटा लेआउट आरेख से पता चलता है कि RowID मान वास्तव में इंडेक्स में काफी यादृच्छिक रूप से वितरित किए जाते हैं (जिसे कुछ डेटा कॉलम याद रखने का आदेश दिया जाता है):
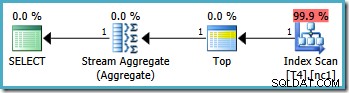
क्वेरी प्लान में शीर्ष ऑपरेटर इंडेक्स स्कैन को एक पंक्ति तक सीमित करता है (स्कैन दिशा के आधार पर इंडेक्स के निचले या उच्च अंत से)। क्वेरी योजनाओं में इंडेक्स स्कैन समस्याग्रस्त हो सकते हैं, लेकिन शीर्ष ऑपरेटर इसे यहां एक कुशल विकल्प बनाता है:स्कैन केवल एक पंक्ति उत्पन्न कर सकता है, फिर यह बंद हो जाता है। शीर्ष और ऑर्डर किया गया इंडेक्स स्कैन संयोजन प्रभावी रूप से इंडेक्स में उच्चतम या निम्नतम मान की तलाश करता है जो WHERE से भी मेल खाता है। खंड भविष्यवाणी करता है। यह सुनिश्चित करने के लिए योजना में एक स्ट्रीम एग्रीगेट भी दिखाई देता है कि एक NULL यदि इंडेक्स स्कैन द्वारा कोई पंक्तियाँ नहीं लौटाई जाती हैं तो उत्पन्न होता है। स्केलर MIN और MAX समुच्चय को NULL return लौटाने के लिए परिभाषित किया गया है जब इनपुट एक खाली सेट हो।
कुल मिलाकर, यह एक बहुत ही कुशल रणनीति है, और योजनाओं की अनुमानित लागत केवल 0.0032921 है परिणामस्वरूप इकाइयों। अब तक बहुत अच्छा।
सीमा मान समस्या
यह अगला उदाहरण RowID श्रेणी के शीर्ष सिरे को संशोधित करता है:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
ध्यान दें कि क्वेरी बहिष्कृत "से कम" ऑपरेटर का उपयोग करके 20,000 मूल्य। याद रखें कि 20,000 मान विभाजन 3 (विभाजन 2 नहीं) से संबंधित है क्योंकि विभाजन फ़ंक्शन को RANGE RIGHT के रूप में परिभाषित किया गया है . SQL सर्वर 2005 अनुकूलक 0.0032878 की अनुमानित लागत के साथ इष्टतम एकल-विभाजन क्वेरी योजना तैयार करते हुए इस स्थिति को सही ढंग से संभालता है :
हालांकि, वही क्वेरी SQL सर्वर 2008 और बाद में . पर एक अलग योजना तैयार करती है (एसक्यूएल सर्वर 2014 सीटीपी 1 सहित):
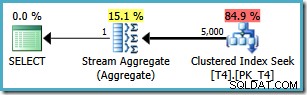
अब हमारे पास एक क्लस्टर्ड इंडेक्स सीक है (वांछित इंडेक्स स्कैन और टॉप ऑपरेटर संयोजन के बजाय)। WHERE . से मेल खाने वाली सभी 5,000 पंक्तियां इस नई निष्पादन योजना में क्लॉज को स्ट्रीम एग्रीगेट के माध्यम से संसाधित किया जाता है। इस योजना की अनुमानित लागत 0.0199319 . है इकाइयाँ – छह गुना . से अधिक SQL सर्वर 2005 योजना की लागत।
कारण
SQL सर्वर 2008 (और बाद में) ऑप्टिमाइज़र को एक अंतराल संदर्भ के दौरान आंतरिक तर्क ठीक से नहीं मिलता है, लेकिन इसमें शामिल नहीं है , एक अलग विभाजन से संबंधित एक सीमा मान। ऑप्टिमाइज़र गलत तरीके से सोचता है कि कई विभाजनों तक पहुँचा जा सकता है, और यह निष्कर्ष निकालता है कि यह MIN के लिए एकल-विभाजन अनुकूलन का उपयोग नहीं कर सकता है। और MAX समुच्चय।
समाधान
एक विकल्प है>=और <=ऑपरेटरों का उपयोग करके क्वेरी को फिर से लिखना ताकि हम किसी अन्य विभाजन से सीमा मान का संदर्भ न दें (यहां तक कि इसे बाहर करने के लिए भी!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;से मिन (कुछ डेटा) चुनें
इसका परिणाम इष्टतम योजना में होता है, एकल विभाजन को स्पर्श करना:
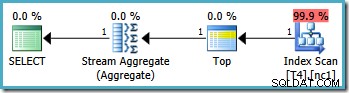
दुर्भाग्य से, इस तरह से सही सीमा मान निर्दिष्ट करना हमेशा संभव नहीं होता है (विभाजन कॉलम के प्रकार के आधार पर)। इसका एक उदाहरण दिनांक और समय प्रकारों के साथ है जहां आधे-खुले अंतराल का उपयोग करना सबसे अच्छा है। इस वर्कअराउंड पर एक और आपत्ति अधिक व्यक्तिपरक है:विभाजन फ़ंक्शन सीमा से एक सीमा को बाहर करता है, इसलिए ऐसा लगता है कि अर्ध-खुले अंतराल सिंटैक्स का उपयोग करके भी क्वेरी लिखना सबसे स्वाभाविक लगता है।
दूसरा समाधान स्पष्ट रूप से विभाजन संख्या निर्दिष्ट करना है (और आधे खुले अंतराल को बनाए रखना):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
यह इष्टतम योजना तैयार करता है, एक अतिरिक्त विधेय की आवश्यकता के खर्च पर और विभाजन संख्या क्या होनी चाहिए यह निर्धारित करने के लिए उपयोगकर्ता पर निर्भर है।
बेशक यह बेहतर होगा यदि 2008 और बाद के ऑप्टिमाइज़र ने वही इष्टतम योजना तैयार की जो SQL Server 2005 ने की थी। एक आदर्श दुनिया में, एक अधिक व्यापक समाधान बहु-विभाजन मामले को भी संबोधित करेगा, जिससे वर्कअराउंड इट्ज़िक अनावश्यक भी वर्णन करता है।



