जब एक निष्पादन योजना में बी-ट्री इंडेक्स संरचना का स्कैन शामिल होता है, तो स्टोरेज इंजन हो सकता है योजना के क्रियान्वित होने पर दो भौतिक पहुँच रणनीतियों के बीच चयन करने में सक्षम हो:
- इंडेक्स बी-ट्री संरचना का पालन करें; या,
- आंतरिक पृष्ठ आवंटन जानकारी का उपयोग करके पृष्ठों का पता लगाएं।
जहां एक विकल्प उपलब्ध है, स्टोरेज इंजन प्रत्येक निष्पादन पर रनटाइम निर्णय लेता है। एक योजना पुनर्संकलन नहीं है इसके लिए अपना विचार बदलना आवश्यक है।
बी-ट्री रणनीति पेड़ की जड़ से शुरू होती है, पत्ती के स्तर के चरम किनारे तक उतरती है (इस पर निर्भर करता है कि स्कैन आगे या पीछे है), फिर पत्ती-स्तरीय पृष्ठ लिंक का अनुसरण करता है जब तक कि सूचकांक के दूसरे छोर तक नहीं पहुंच जाता . आवंटन रणनीति इंडेक्स को आवंटित डेटाबेस पेजों का पता लगाने के लिए इंडेक्स आवंटन मानचित्र (आईएएम) संरचनाओं का उपयोग करती है। प्रत्येक IAM पृष्ठ आवंटन को एक भौतिक डेटाबेस फ़ाइल में 4GB अंतराल पर मैप करता है, इसलिए किसी अनुक्रमणिका से संबद्ध IAM श्रृंखलाओं को स्कैन करने से भौतिक फ़ाइल क्रम में अनुक्रमणिका पृष्ठों तक पहुँचने की प्रवृत्ति होती है (कम से कम जहाँ तक SQL सर्वर बता सकता है)।
दो रणनीतियों के बीच मुख्य अंतर हैं:
- बी-पेड़ स्कैन इंडेक्स कुंजी क्रम में क्वेरी प्रोसेसर को पंक्तियां वितरित कर सकता है; IAM-संचालित स्कैन नहीं कर सकता;
- एक बी-ट्री स्कैन बड़े रीड-फ़ॉरवर्ड I/O अनुरोध जारी करने में सक्षम नहीं हो सकता है यदि तार्किक रूप से सन्निहित अनुक्रमणिका पृष्ठ भौतिक रूप से सन्निहित नहीं हैं (उदा. अनुक्रमणिका में पृष्ठ विभाजन के परिणामस्वरूप)।
इंडेक्स के लिए बी-ट्री स्कैन हमेशा उपलब्ध होता है। आवंटन आदेश स्कैन के उपलब्ध होने के लिए अक्सर जिन शर्तों का हवाला दिया जाता है वे हैं:
- क्वेरी प्लान को इंडेक्स के अनियंत्रित स्कैन की अनुमति देनी चाहिए;
- सूचकांक कम से कम 64 पृष्ठों का होना चाहिए; और,
- या तो
TABLOCKयाNOLOCKसंकेत निर्दिष्ट किया जाना चाहिए।
पहली शर्त का सीधा सा मतलब है कि क्वेरी ऑप्टिमाइज़र ने स्कैन को Ordered:False के साथ चिह्नित किया होगा। संपत्ति। स्कैन को चिह्नित करना Ordered:False इसका अर्थ है कि निष्पादन योजना के सही परिणामों की आवश्यकता नहीं है अनुक्रमणिका कुंजी क्रम में पंक्तियों को वापस करने के लिए स्कैन (हालांकि यह सुविधाजनक या अन्यथा आवश्यक होने पर ऐसा कर सकता है)।
दूसरी शर्त (आकार) केवल SQL सर्वर 2005 और बाद में लागू होती है। यह इस तथ्य को दर्शाता है कि आईएएम-संचालित स्कैन करने के लिए एक निश्चित स्टार्ट-अप लागत है, इसलिए प्रारंभिक निवेश को चुकाने के लिए संभावित बचत के लिए पृष्ठों की न्यूनतम संख्या होनी चाहिए। "64 पेज" data_pages . के मान को दर्शाता है IN_ROW_DATA . के लिए केवल आवंटन इकाई, जैसा कि sys.allocation_units में रिपोर्ट किया गया है।
बेशक, आवंटन ऑर्डर स्कैन से केवल तभी भुगतान हो सकता है जब संभावित रूप से बड़े रीड-फ़ॉरवर्ड विचार वास्तव में हों चलन में आता है, लेकिन SQL सर्वर वर्तमान में इस कारक पर विचार नहीं करता है। विशेष रूप से, यह इस बात का हिसाब नहीं देता कि वर्तमान में कितनी मेमोरी मेमोरी में है, और न ही यह परवाह करता है कि इंडेक्स कितना खंडित है।
तीसरी शर्त शायद सूची में सबसे कम पूर्ण विवरण है। संकेत वास्तव में आवश्यक नहीं हैं , हालांकि उनका उपयोग वास्तविक आवश्यकताओं को पूरा करने के लिए किया जा सकता है:डेटा को बदलने की गारंटी होना चाहिए स्कैन के दौरान, या (अधिक विवादास्पद रूप से) हमें यह इंगित करना चाहिए कि हमें परवाह नहीं है रीड अनकमिटेड आइसोलेशन स्तर पर स्कैन करके संभावित रूप से गलत परिणामों के बारे में।
इन स्पष्टीकरणों के बावजूद, आवंटन-आदेशित स्कैन के लिए शर्तों की सूची अभी भी पूरी नहीं हुई है। कई महत्वपूर्ण चेतावनी और अपवाद हैं, जिन पर हम शीघ्र ही विचार करेंगे।
डेमो
निम्नलिखित क्वेरी एडवेंचरवर्क्स नमूना डेटाबेस का उपयोग करती है:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; ध्यान दें कि व्यक्ति तालिका में 3,869 पृष्ठ हैं। निष्पादन के बाद (वास्तविक) योजना इस प्रकार है (एसक्यूएल संतरी योजना एक्सप्लोरर में दिखाया गया है):
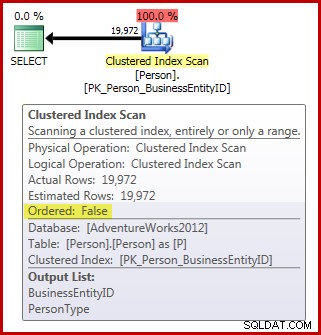
आवंटन-आदेश स्कैनिंग आवश्यकताओं के संदर्भ में हमारे पास अब तक है:
- योजना में आवश्यक
Ordered:False. है संपत्ति; और, - तालिका में 64 से अधिक पृष्ठ हैं; लेकिन,
- हमने यह सुनिश्चित करने के लिए कुछ नहीं किया है कि स्कैन के दौरान डेटा नहीं बदल सकता है। यह मानते हुए कि हमारा सत्र डिफ़ॉल्ट पढ़ने के लिए प्रतिबद्ध . का उपयोग कर रहा है अलगाव स्तर, स्कैन बिना पढ़े पर नहीं किया जा रहा है अलगाव स्तर या तो।
परिणामस्वरूप, हम उम्मीद करेंगे कि यह स्कैन आईएएम-चालित होने के बजाय बी-ट्री को स्कैन करके किया जाएगा। क्वेरी के नतीजे बताते हैं कि यह सच हो सकता है:
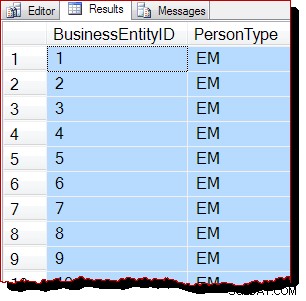
पंक्तियों को क्लस्टर्ड इंडेक्स कुंजी क्रम में लौटाया जाता है (BusinessEntityID . द्वारा) ) मुझे स्पष्ट रूप से बताना चाहिए कि यह परिणाम आदेश बिल्कुल गारंटी नहीं है , और इस पर भरोसा नहीं किया जाना चाहिए। आदेशित परिणामों की गारंटी केवल एक उपयुक्त शीर्ष-स्तरीय ORDER BY . द्वारा दी जाती है खंड।
फिर भी, देखा गया आउटपुट ऑर्डर परिस्थितिजन्य साक्ष्य है कि इस बार क्लस्टर इंडेक्स बी-ट्री संरचना का पालन करके स्कैन किया गया था। यदि अधिक साक्ष्य की आवश्यकता है, तो हम एक डिबगर संलग्न कर सकते हैं और कोड पथ को देख सकते हैं SQL सर्वर स्कैन के दौरान निष्पादित कर रहा है:

कॉल स्टैक स्पष्ट रूप से बी-पेड़ के बाद स्कैन दिखाता है।
टेबल लॉक हिंट जोड़ना
अब हम टेबल-लॉक हिंट को शामिल करने के लिए क्वेरी को संशोधित करते हैं:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); डिफ़ॉल्ट लॉकिंग रीड कमिटेड आइसोलेशन स्तर पर, साझा टेबल-लेवल लॉक डेटा में किसी भी संभावित समवर्ती संशोधन को रोकता है। IAM-संचालित स्कैन के लिए सभी तीन पूर्व शर्त पूरी होने के साथ, अब हम SQL सर्वर से आबंटन-आदेश स्कैन का उपयोग करने की अपेक्षा करेंगे। निष्पादन योजना पहले की तरह ही है, इसलिए मैं इसे नहीं दोहराऊंगा, लेकिन क्वेरी के परिणाम निश्चित रूप से अलग दिखते हैं:
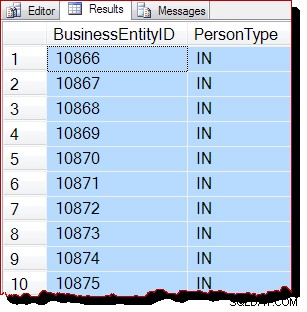
परिणाम अभी भी स्पष्ट रूप से BusinessEntityID . द्वारा आदेशित हैं , लेकिन शुरुआती बिंदु (10866) अलग है। वास्तव में, यदि हम परिणामों को नीचे स्क्रॉल करते हैं, तो हम जल्द ही उन अनुभागों का सामना करते हैं जो स्पष्ट रूप से महत्वपूर्ण क्रम से बाहर हैं:
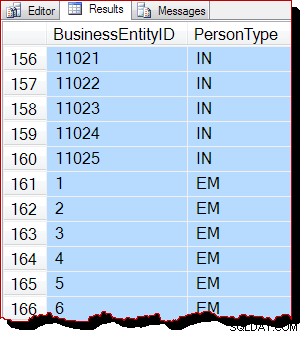
आंशिक क्रम आवंटन-आदेश स्कैन के कारण एक बार में संपूर्ण अनुक्रमणिका पृष्ठ को संसाधित करने के कारण होता है। परिणाम एक पृष्ठ के भीतर सूचकांक कुंजी द्वारा आदेशित किया जाना होता है, लेकिन स्कैन किए गए पृष्ठों का क्रम अब अलग है। फिर से, मुझे इस बात पर जोर देना चाहिए कि परिणाम आपके लिए अलग दिख सकते हैं:शीर्ष-स्तरीय ORDER BY के बिना, पृष्ठ के भीतर भी, आउटपुट ऑर्डर की कोई गारंटी नहीं है। मूल क्वेरी पर।
पहले दिखाए गए कॉल स्टैक के साथ तुलना के लिए, यह एक स्टैक ट्रेस प्राप्त किया गया है जब SQL सर्वर TABLOCK के साथ क्वेरी को संसाधित कर रहा था। संकेत:
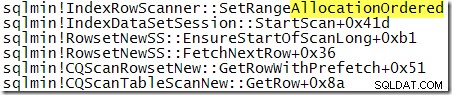
निष्पादन के माध्यम से थोड़ा और आगे बढ़ना:

तालिका लॉक निर्दिष्ट होने पर स्पष्ट रूप से, SQL सर्वर आवंटन-आदेशित स्कैन कर रहा है। यह शर्म की बात है कि निष्पादन के बाद की योजना में कोई संकेत नहीं है कि रनटाइम पर किस प्रकार के स्कैन का उपयोग किया गया था। एक अनुस्मारक के रूप में, स्टोरेज इंजन द्वारा स्कैन के प्रकार को चुना जाता है, और योजना के पुनर्संकलन के बिना निष्पादन के बीच बदल सकता है।
तीसरी शर्त को पूरा करने के अन्य तरीके
मैंने उससे पहले कहा था कि IAM-संचालित स्कैन प्राप्त करने के लिए, हमें यह सुनिश्चित करने की आवश्यकता है कि डेटा स्कैन के नीचे नहीं बदल सकता है, जबकि यह प्रगति पर है, या हमें क्वेरी को बिना पढ़े आइसोलेशन स्तर पर चलाने की आवश्यकता है। हमने देखा है कि पढ़ने के लिए प्रतिबद्ध अलगाव को लॉक करने पर एक टेबल लॉक संकेत उन आवश्यकताओं में से पहली को पूरा करने के लिए पर्याप्त है, और यह दिखाना आसान है कि NOLOCK/READUNCOMMITTED का उपयोग करना संकेत डेमो क्वेरी के साथ आवंटन-आदेश स्कैन को भी सक्षम बनाता है।
वास्तव में तीसरी शर्त को पूरा करने के कई तरीके हैं, जिनमें शामिल हैं:
- सूचकांक को केवल टेबल लॉक की अनुमति देने के लिए बदलना;
- डेटाबेस को केवल-पढ़ने के लिए बनाना (इसलिए डेटा को बदलने की गारंटी नहीं है); या,
- सत्र को बदलना अलगाव का स्तर
READ UNCOMMITTED।
हालाँकि, इस विषय पर और भी दिलचस्प विविधताएँ हैं, जिसका अर्थ है कि हमें पहले बताई गई तीन शर्तों में संशोधन करने की आवश्यकता है…
पंक्ति-संस्करण अलगाव स्तर
एडवेंचरवर्क्स डेटाबेस पर रीड कमिटेड स्नैपशॉट आइसोलेशन (RCSI) सक्षम करें, और TABLOCK के साथ परीक्षण चलाएँ फिर से संकेत दें (पढ़ने के लिए प्रतिबद्ध अलगाव):
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
RCSI सक्रिय होने के साथ, एक अनुक्रमित क्रमांक स्कैन का उपयोग TABLOCK . के साथ किया जाता है , आवंटन-आदेश स्कैन नहीं जो हमने अभी पहले देखा था। इसका कारण है TABLOCK संकेत तालिका-स्तरीय साझा लॉक निर्दिष्ट करता है, लेकिन RCSI सक्षम होने के साथ, कोई साझा लॉक नहीं लिए जाते हैं। साझा टेबल लॉक के बिना, हमने स्कैन के दौरान डेटा में समवर्ती संशोधनों को रोकने की आवश्यकता को पूरा नहीं किया है, इसलिए आवंटन-आदेशित स्कैन का उपयोग नहीं किया जा सकता है।
हालाँकि, RCSI सक्षम होने पर आवंटन-आदेशित स्कैन प्राप्त करना संभव है। एक तरीका है TABLOCKX . का उपयोग करना संकेत (तालिका-स्तर के लिए अनन्य लॉक) के बजाय TABLOCK . हम TABLOCK . को भी बरकरार रख सकते हैं संकेत दें और दूसरा जोड़ें जैसे READCOMMITTEDLOCK , या REPEATABLE READ या SERIALIZABLE … और इसी तरह। ये सभी काम RCSI के लाभों को खोने की कीमत पर एक साझा टेबल लॉक लेकर समवर्ती संशोधनों की संभावना को रोकते हैं। . हम अभी भी एक NOLOCK . का उपयोग करके आवंटन-आदेश स्कैन प्राप्त कर सकते हैं या READUNCOMMITTED संकेत, बिल्कुल।
स्नैपशॉट आइसोलेशन (एसआई) के तहत स्थिति आरसीएसआई के समान ही है, और अंतरिक्ष कारणों से विस्तार से नहीं खोजा गया है।
TABLESAMPLE हमेशा* आवंटन-आदेश स्कैन करता है
TABLESAMPLE क्लॉज उन कई चीजों का एक दिलचस्प अपवाद है जिन पर हमने अब तक चर्चा की है।
एक TABLESAMPLE निर्दिष्ट करना क्लॉज हमेशा* के परिणामस्वरूप आवंटन-आदेश स्कैन होता है, यहां तक कि आरसीएसआई या एसआई के तहत, और यहां तक कि बिना संकेत के भी। इसके बारे में स्पष्ट होने के लिए, आवंटन-आदेश स्कैन जो TABLESAMPLE . का उपयोग करने के परिणामस्वरूप होता है RCSI/SI शब्दार्थ को बरकरार रखता है - स्कैन पंक्ति संस्करणों का उपयोग करता है और पढ़ना लेखन (और इसके विपरीत) को अवरुद्ध नहीं करता है।
दूसरा आश्चर्य यह है कि TABLESAMPLE हमेशा* IAM-संचालित स्कैन करता है चाहे तालिका में 64 से कम पृष्ठ हों . यह कुछ समझ में आता है क्योंकि दस्तावेज़ीकरण कम से कम संकेत देता है कि SYSTEM नमूनाकरण विधि IAM संरचना का उपयोग करती है (इसलिए आवंटन-आदेश स्कैन करने के अलावा कोई विकल्प नहीं है):
सिस्टम आईएसओ मानकों द्वारा निर्दिष्ट एक कार्यान्वयन-निर्भर नमूनाकरण विधि है। SQL सर्वर में, यह एकमात्र उपलब्ध नमूना पद्धति है और डिफ़ॉल्ट रूप से लागू होती है। सिस्टम एक पृष्ठ-आधारित नमूनाकरण पद्धति लागू करता है जिसमें नमूने के लिए तालिका से पृष्ठों का एक यादृच्छिक सेट चुना जाता है, और उन पृष्ठों की सभी पंक्तियों को नमूना सबसेट के रूप में वापस कर दिया जाता है।
* एक अपवाद तब होता है जब ROWS या PERCENT TABLESAMPLE . में विशिष्टता क्लॉज का मतलब तालिका का 100% है। अधिक निर्दिष्ट करना ROWS मेटाडेटा से इंगित करता है कि वर्तमान में तालिका में हैं या तो काम नहीं करेंगे। TABLESAMPLE SYSTEM (100 PERCENT) . का उपयोग करना या समकक्ष नहीं . होगा आवंटन-आदेश स्कैन के लिए बाध्य करें।
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
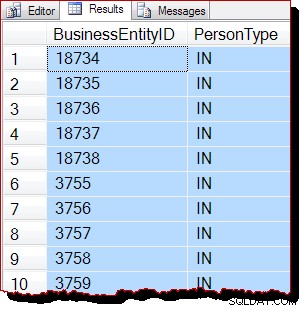
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); परिणाम:
TOP और SET ROWCOUNT का प्रभाव
संक्षेप में, इनमें से किसी का भी आवंटन-आदेश स्कैन का उपयोग करने या न करने के निर्णय पर कोई प्रभाव नहीं पड़ता है। यह उन मामलों में आश्चर्यजनक लग सकता है जहां यह "स्पष्ट" है कि 64 से कम पृष्ठों को स्कैन किया जाएगा।
उदाहरण के लिए, निम्न क्वेरी दोनों स्कैन से 5 पंक्तियों को वापस करने के लिए IAM-संचालित स्कैन का उपयोग करती हैं:
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; परिणाम दोनों के लिए समान हैं:
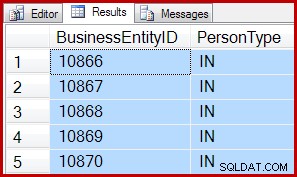
इसका मतलब है कि TOP और SET ROWCOUNT क्वेरी हो सकता है आबंटन-आदेश स्कैन को स्थापित करने के लिए ऊपरी खर्च उठाना पड़ता है, भले ही 64 से कम पृष्ठ स्कैन किए गए हों। शमन में, स्कैन में धकेले गए चयनात्मक विधेय के साथ अधिक जटिल TOP क्वेरी अभी भी आवंटन-आदेश स्कैन से लाभान्वित हो सकती हैं। यदि मिलान वाली पहली 5 पंक्तियों को खोजने के लिए स्कैन को 10,000 पृष्ठों को संसाधित करना होगा, तो आवंटन-आदेश स्कैन अभी भी एक जीत हो सकती है।
सभी* आवंटन-आदेश स्कैन को इंस्टेंस-वाइड रोकना
यह ऐसा कुछ नहीं है जो आप जानबूझकर कभी भी करेंगे, लेकिन एक सर्वर सेटिंग है जो सभी डेटाबेस में सभी * उपयोगकर्ता प्रश्नों के लिए आवंटन-आदेश स्कैन को रोक देगी।
ऐसा प्रतीत होने की संभावना नहीं है, विचाराधीन सेटिंग कर्सर थ्रेशोल्ड सर्वर कॉन्फ़िगरेशन विकल्प है, जिसका ऑनलाइन पुस्तकें में निम्नलिखित विवरण है:
<ब्लॉकक्वॉट स्टाइल ='मार्जिन-बॉटम:0 पीएक्स! इम्पोर्टेंट; पैडिंग-बॉटम:0 पीएक्स! इम्पोर्टेंट;'>कर्सर थ्रेशोल्ड विकल्प कर्सर सेट में पंक्तियों की संख्या निर्दिष्ट करता है जिस पर कर्सर कीसेट एसिंक्रोनस रूप से उत्पन्न होते हैं। जब कर्सर परिणाम सेट के लिए एक कीसेट उत्पन्न करते हैं, तो क्वेरी ऑप्टिमाइज़र उस परिणाम सेट के लिए वापस आने वाली पंक्तियों की संख्या का अनुमान लगाता है। यदि क्वेरी ऑप्टिमाइज़र का अनुमान है कि लौटाई गई पंक्तियों की संख्या इस सीमा से अधिक है, तो कर्सर अतुल्यकालिक रूप से उत्पन्न होता है, जिससे उपयोगकर्ता कर्सर से पंक्तियाँ प्राप्त कर सकता है जबकि कर्सर पॉप्युलेट होता रहता है। अन्यथा, कर्सर समकालिक रूप से उत्पन्न होता है, और क्वेरी सभी पंक्तियों के वापस आने तक प्रतीक्षा करती है।
यदि cursor threshold विकल्प -1 (डिफ़ॉल्ट) के अलावा किसी अन्य चीज़ पर सेट है, SQL सर्वर इंस्टेंस पर किसी भी डेटाबेस में उपयोगकर्ता प्रश्नों के लिए कोई आवंटन-आदेश स्कैन नहीं होगा।
दूसरे शब्दों में, यदि एसिंक्रोनस कर्सर जनसंख्या सक्षम है, तो आपके लिए कोई IAM-संचालित स्कैन नहीं है।
* अपवाद है (गैर-100%) TABLESAMPLE प्रश्न। सांख्यिकी निर्माण और सांख्यिकी अद्यतन के लिए सिस्टम द्वारा उत्पन्न आंतरिक प्रश्न भी आवंटन-क्रमित स्कैन का उपयोग करना जारी रखते हैं।
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; परिणाम (कोई आवंटन-आदेश स्कैन नहीं):
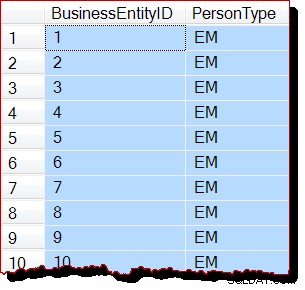
कोई केवल यह अनुमान लगा सकता है कि किसी कारण से एसिंक्रोनस कर्सर आबादी आवंटन-आदेश स्कैन के साथ अच्छी तरह से काम नहीं करती है। यह पूरी तरह से अप्रत्याशित है कि यह प्रतिबंध सभी गैर-कर्सर उपयोगकर्ता प्रश्नों को प्रभावित करेगा वैसे भी। शायद SQL सर्वर के लिए यह पता लगाना बहुत कठिन है कि कोई क्वेरी बाहरी रूप से जारी API कर्सर के हिस्से के रूप में चल रही है या नहीं? कौन जानता है।
यह अच्छा होगा यदि इस दुष्प्रभाव को आधिकारिक तौर पर कहीं प्रलेखित किया गया हो, हालांकि यह जानना कठिन है कि इसे बुक्स ऑनलाइन में कहाँ जाना चाहिए। मुझे आश्चर्य है कि इस वजह से कितने उत्पादन सिस्टम आवंटन-आदेश स्कैन का उपयोग नहीं कर रहे हैं? शायद बहुत से नहीं, लेकिन आप कभी नहीं जानते।
चीजों को लपेटने के लिए, यहाँ एक सारांश है। आवंटन-आदेशित स्कैन उपलब्ध है यदि:
- सर्वर विकल्प
cursor threshold-1 (डिफ़ॉल्ट) पर सेट है; और, - क्वेरी प्लान स्कैन ऑपरेटर के पास
Ordered:False. है संपत्ति; और, - कुल डेटा_पृष्ठ
IN_ROW_DATA. का आवंटन इकाइयाँ कम से कम 64 हैं; और, - या तो:
- SQL सर्वर की स्वीकार्य गारंटी है कि समवर्ती संशोधन असंभव हैं; या,
- स्कैन रीड अनकमिटेड आइसोलेशन स्तर पर चल रहा है।
उपरोक्त सभी के बावजूद, TABLESAMPLE . के साथ एक स्कैन क्लॉज हमेशा आवंटन-आदेशित स्कैन का उपयोग करता है (मुख्य पाठ में उल्लेखित एक तकनीकी अपवाद के साथ)।