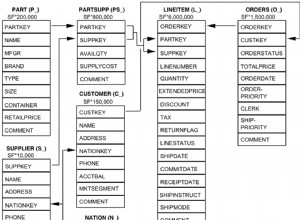
लोड बैलेंसर किसी भी अत्यधिक उपलब्ध डेटाबेस सेटअप का एक अनिवार्य घटक है। उनका उपयोग किसी एक सर्वर को अतिभारित होने से रोककर आपके महत्वपूर्ण सिस्टम और एप्लिकेशन की क्षमता और विश्वसनीयता बढ़ाने के लिए किया जाता है। हम कई तरह के ब्लॉग पर उनके बारे में बात करते हैं, जैसे कि आपको उनकी आवश्यकता क्यों है और वे कैसे काम करते हैं। MySQL और MariaDB के लिए उपलब्ध सबसे लोकप्रिय लोड बैलेंसरों में से एक HAProxy है।
सुविधा-वार, HAProxy, ProxySQL या MaxScale से तुलनीय नहीं है। हालांकि, HAProxy एक तेज, मजबूत लोड बैलेंसर है जो किसी भी वातावरण में पूरी तरह से ठीक काम करेगा जब तक कि एप्लिकेशन रीड/राइट स्प्लिट को निष्पादित कर सकता है और एक बैकएंड को SELECT क्वेरी भेज सकता है और सभी लिखता है और चुनें ... अद्यतन के लिए एक अलग बैकएंड।
HAProxy द्वारा उपलब्ध कराए गए सभी मीट्रिक का ट्रैक रखना बहुत महत्वपूर्ण है; आपको अपने प्रॉक्सी की स्थिति जानने में सक्षम होना चाहिए, विशेष रूप से यह जानने के लिए कि क्या आपको किसी समस्या का सामना करना पड़ा है।
ClusterControl ने हमेशा वास्तविक समय में प्रॉक्सी की स्थिति दिखाते हुए एक HAProxy स्थिति पृष्ठ उपलब्ध कराया है। अब, नए प्रोमेथियस-आधारित SCUMM (सेवरलिन्स क्लस्टरकंट्रोल यूनिफाइड मॉनिटरिंग एंड मैनेजमेंट) डैशबोर्ड के साथ, यह आसानी से ट्रैक करना संभव है कि वे मेट्रिक्स समय के साथ कैसे बदलते हैं।
यह ब्लॉग पोस्ट HAProxy SCUMM डैशबोर्ड में प्रस्तुत विभिन्न मेट्रिक की खोज करेगा।
ClusterControl में HAProxy डैशबोर्ड को एक्सप्लोर करना
सभी Prometheus और SCUMM डैशबोर्ड डिफ़ॉल्ट रूप से ClusterControl में अक्षम होते हैं। हालांकि, किसी दिए गए क्लस्टर के लिए उन्हें तैनात करना केवल एक क्लिक की बात है। यदि आप ClusterControl के साथ कई क्लस्टर की निगरानी करते हैं, तो आप प्रत्येक क्लस्टर के लिए समान प्रोमेथियस इंस्टेंस का पुन:उपयोग कर सकते हैं।
एक बार परिनियोजित होने के बाद, आप HAProxy डैशबोर्ड तक पहुंच सकते हैं। आइए डैशबोर्ड में उपलब्ध डेटा पर एक नज़र डालें:
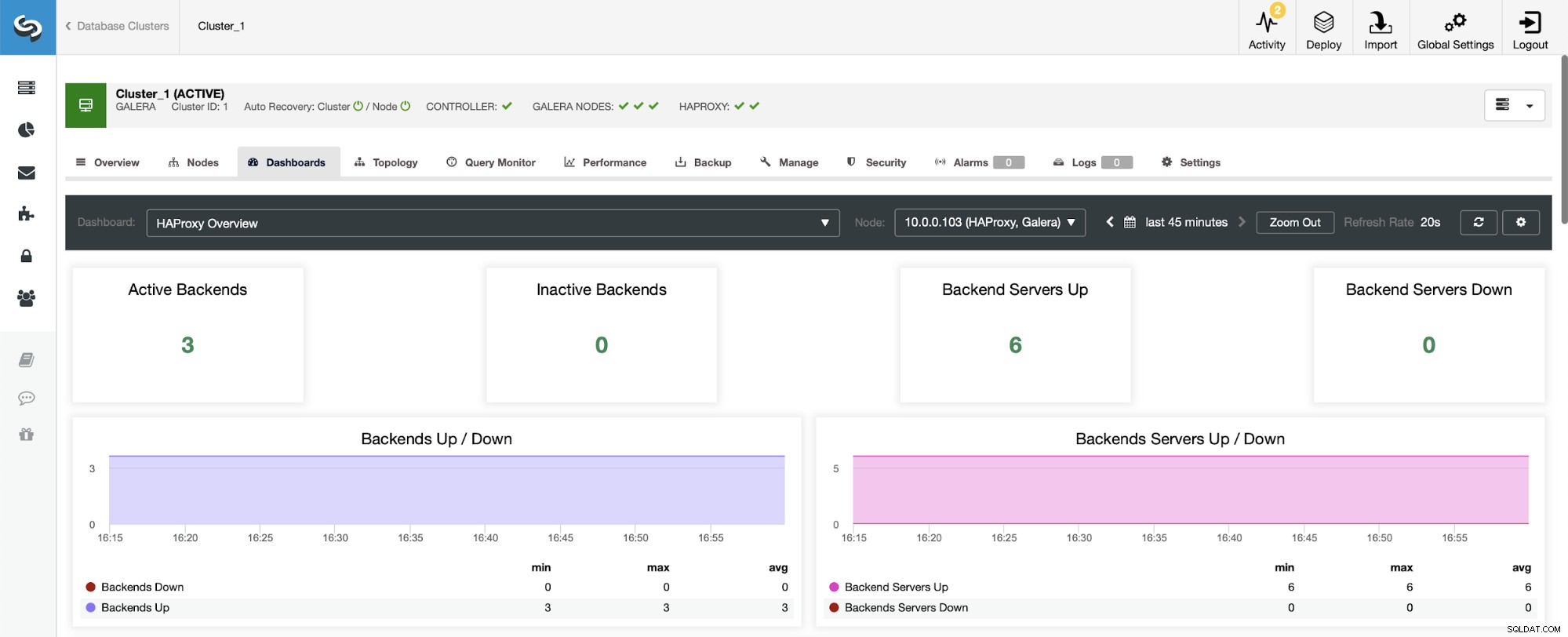
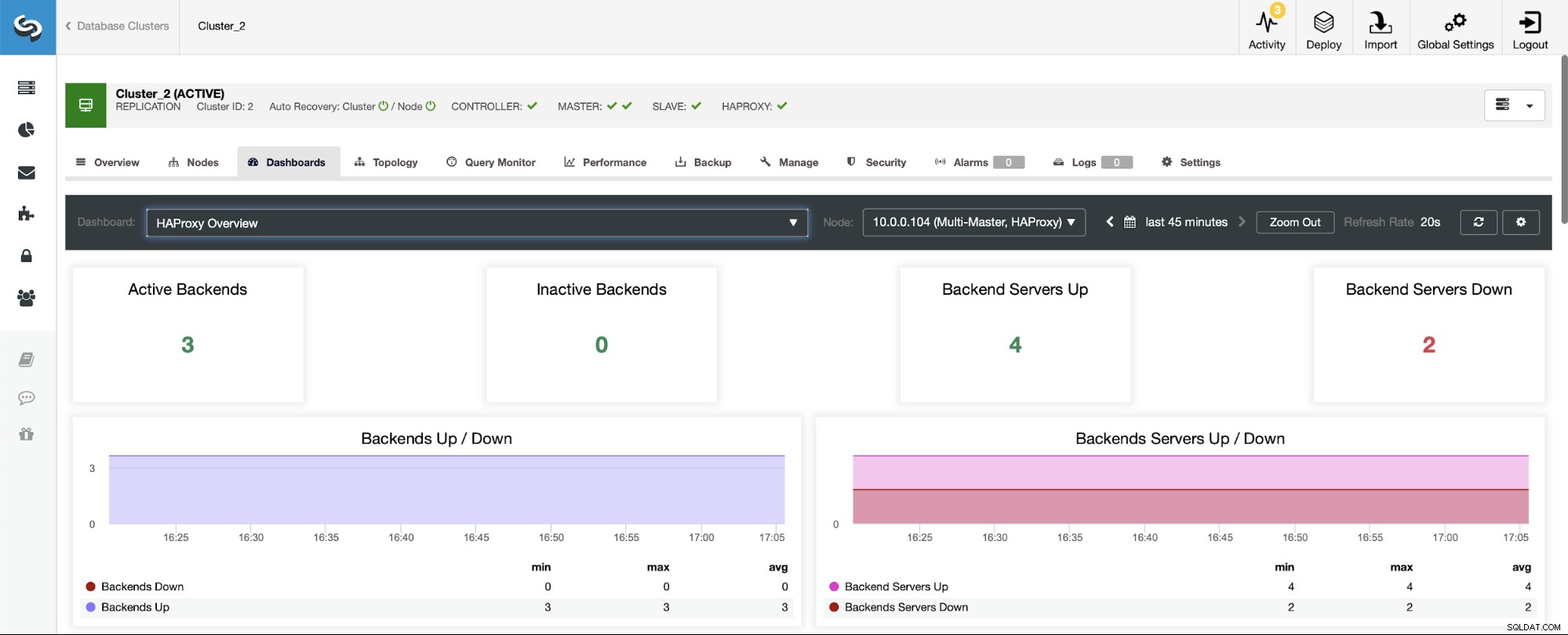
जब आप HAProxy डैशबोर्ड पर नेविगेट करते हैं तो सबसे पहली चीज़ आपको दिखाई देगी आपके बैकएंड की स्थिति के बारे में जानकारी। यहां, कृपया ध्यान दें कि आप जो देखते हैं वह क्लस्टर प्रकार पर निर्भर करता है और आपने HAProxy को कैसे तैनात किया है। इस मामले में, हमने एक गैलेरा क्लस्टर तैनात किया, और HAProxy को राउंड-रॉबिन फैशन में तैनात किया गया था। इसलिए, आप तीन बैकएंड पढ़ने के लिए और तीन लिखने के लिए देखते हैं - कुल छह। यही कारण है कि आप सभी बैकएंड को "ऊपर" के रूप में चिह्नित देखते हैं।
एक प्रतिकृति क्लस्टर के साथ एक परिदृश्य में, चीजें अलग दिखाई देंगी क्योंकि HAProxy को रीड/राइट स्प्लिट में तैनात किया जाएगा, और स्क्रिप्ट केवल एक होस्ट (मास्टर) को लेखक के ऊपर और चालू रखेगी। बैकएंड।
ध्यान दें, यही कारण है कि नीचे आपको दो बैकएंड सर्वर "डाउन" के रूप में चिह्नित दिखाई देते हैं:
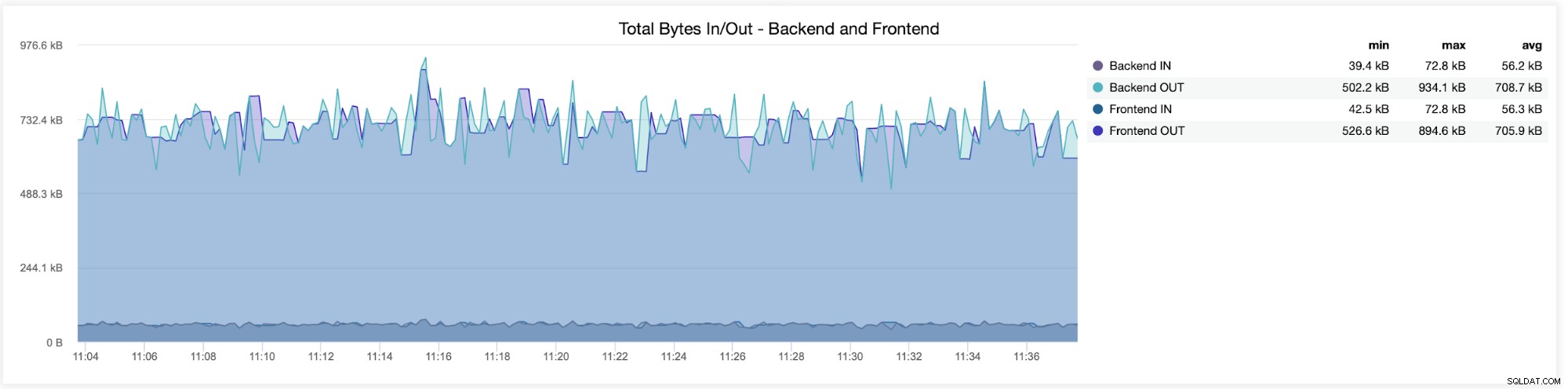
निम्न ग्राफ़ में, आप दोनों द्वारा भेजे और प्राप्त किए गए डेटा को देखेंगे बैकएंड (HAProxy से डेटाबेस सर्वर तक) और फ्रंटएंड (HAProxy और क्लाइंट होस्ट के बीच):
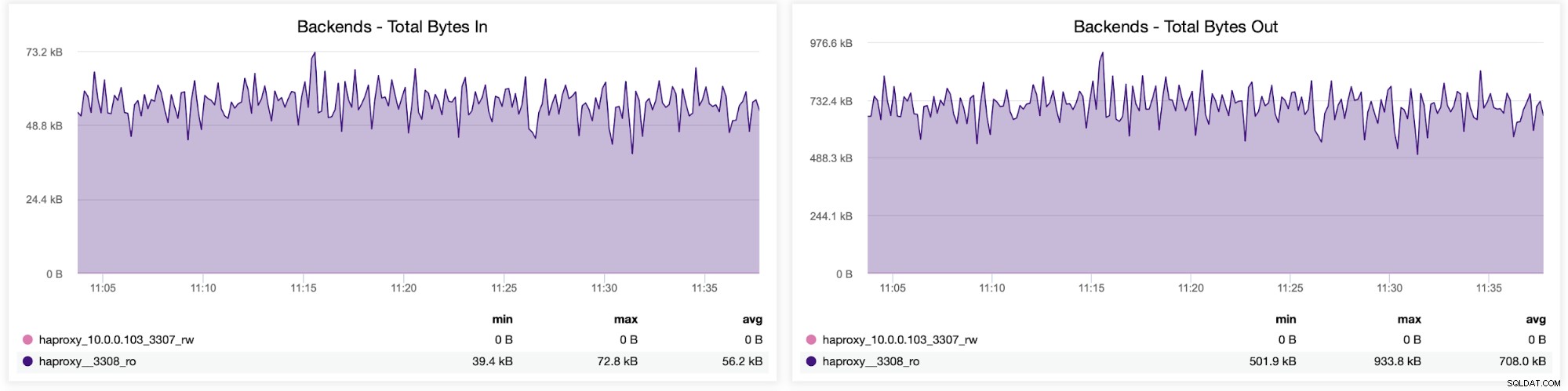
आप अपने HAProxy कॉन्फ़िगरेशन में बैकएंड के बीच ट्रैफ़िक वितरण की जांच भी कर सकते हैं। इस मामले में, हमारे पास दो बैकएंड हैं, और प्रश्न पोर्ट 3308 के माध्यम से भेजे जाते हैं, जो हमारे गैलेरा क्लस्टर के लिए राउंड-रॉबिन एक्सेस प्वाइंट के रूप में कार्य करता है:
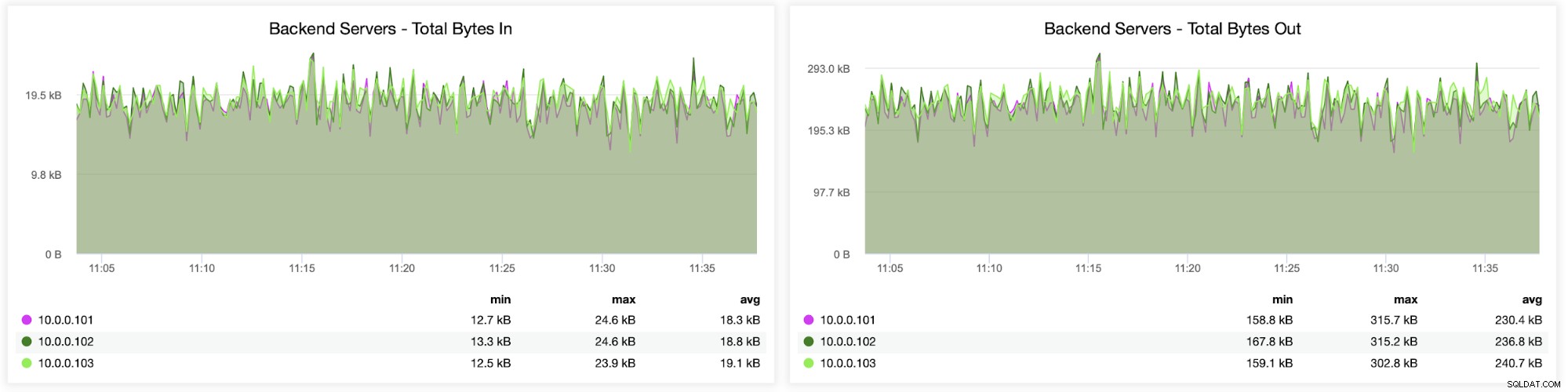
इसके बाद, आप देख सकते हैं कि ट्रैफ़िक सभी बैकएंड सर्वरों में कैसे वितरित किया गया था। इस परिदृश्य में - राउंड-रॉबिन एक्सेस पैटर्न के कारण - डेटा कमोबेश सभी तीन बैकएंड गैलेरा सर्वरों में समान रूप से वितरित किया गया था:
हैप्रोक्सी से बैकएंड तक कितने सत्र खोले गए, सहित सत्रों के बारे में जानकारी सर्वरों की भी निगरानी की जा सकती है, जैसा कि निम्नलिखित ग्राफ में देखा जा सकता है। आप यह भी ट्रैक कर सकते हैं कि बैकएंड के लिए एक नया सत्र कितनी बार प्रति सेकंड खोला गया था और वे मीट्रिक प्रति बैकएंड सर्वर के आधार पर कैसे दिखते हैं।
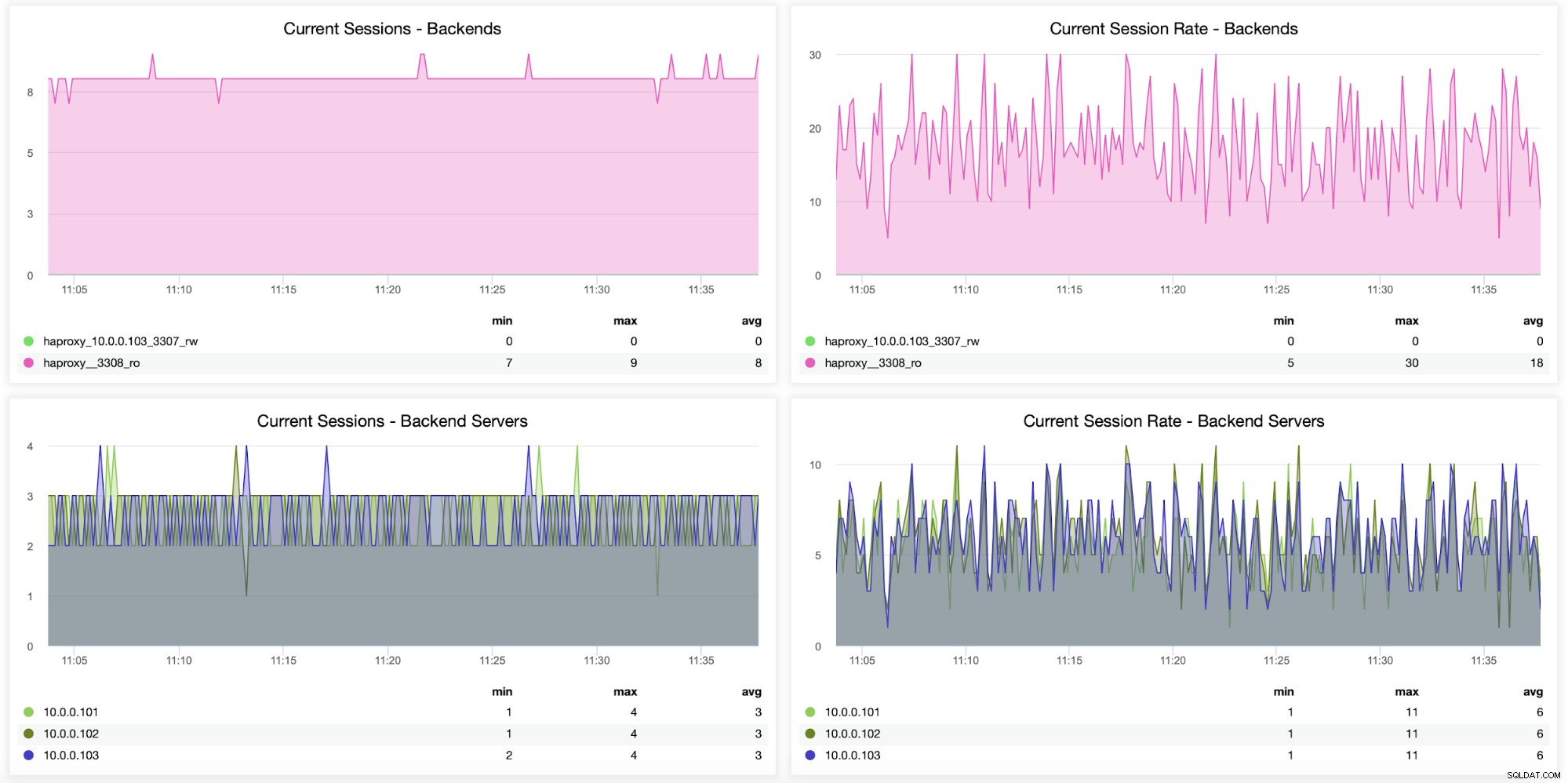
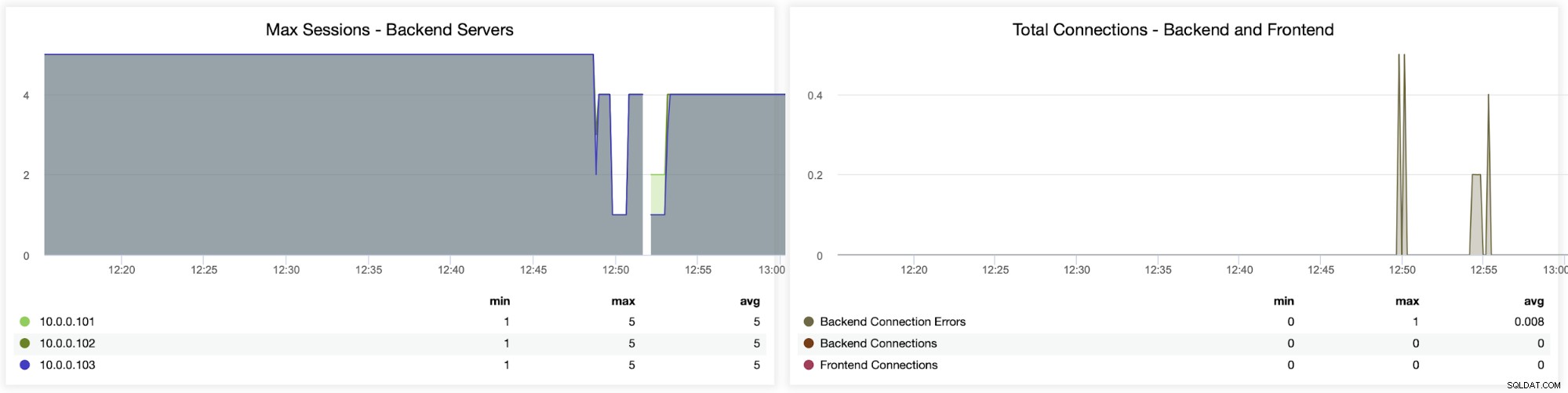
निम्न दो ग्राफ़ प्रति बैकएंड सर्वर पर सत्रों की अधिकतम संख्या और कब दिखाते हैं कनेक्टिविटी मुद्दे सामने आए। यह डिबगिंग उद्देश्यों के लिए काफी उपयोगी हो सकता है जहां आपने अपने HAProxy इंस्टेंस पर कॉन्फ़िगरेशन त्रुटि मारा, और कनेक्शन गिरने लगते हैं।
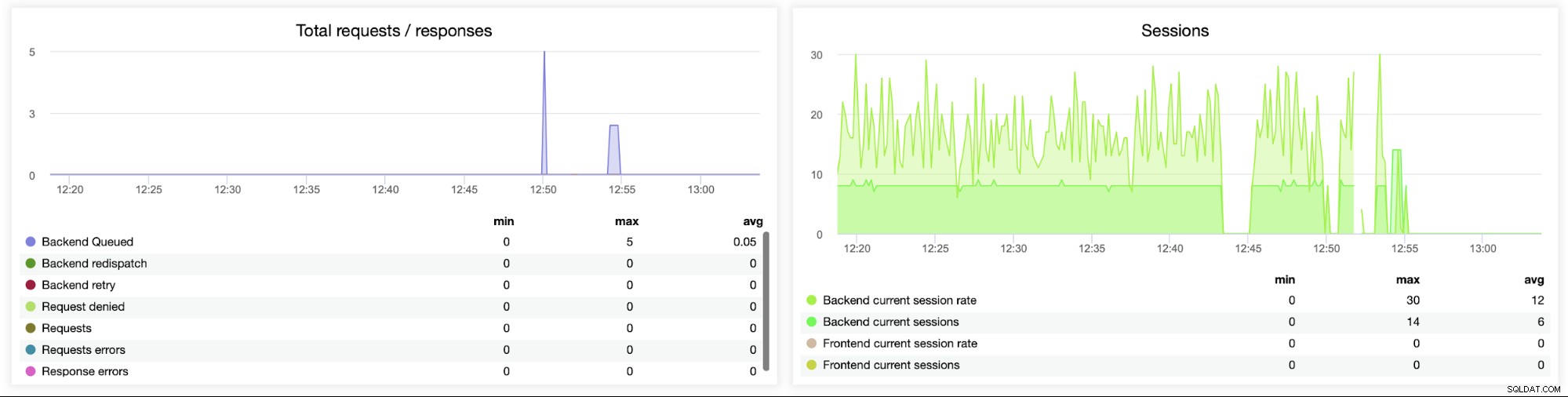
यह अगला ग्राफ़ संभावित रूप से अधिक मूल्यवान है क्योंकि यह त्रुटि से संबंधित विभिन्न मीट्रिक दिखाता है हैंडलिंग, जैसे कि त्रुटियां, अनुरोध त्रुटियां, बैकएंड साइड पर पुन:प्रयास, आदि। एक "सत्र" ग्राफ़ भी है जो सत्र मीट्रिक का अवलोकन दिखाता है।
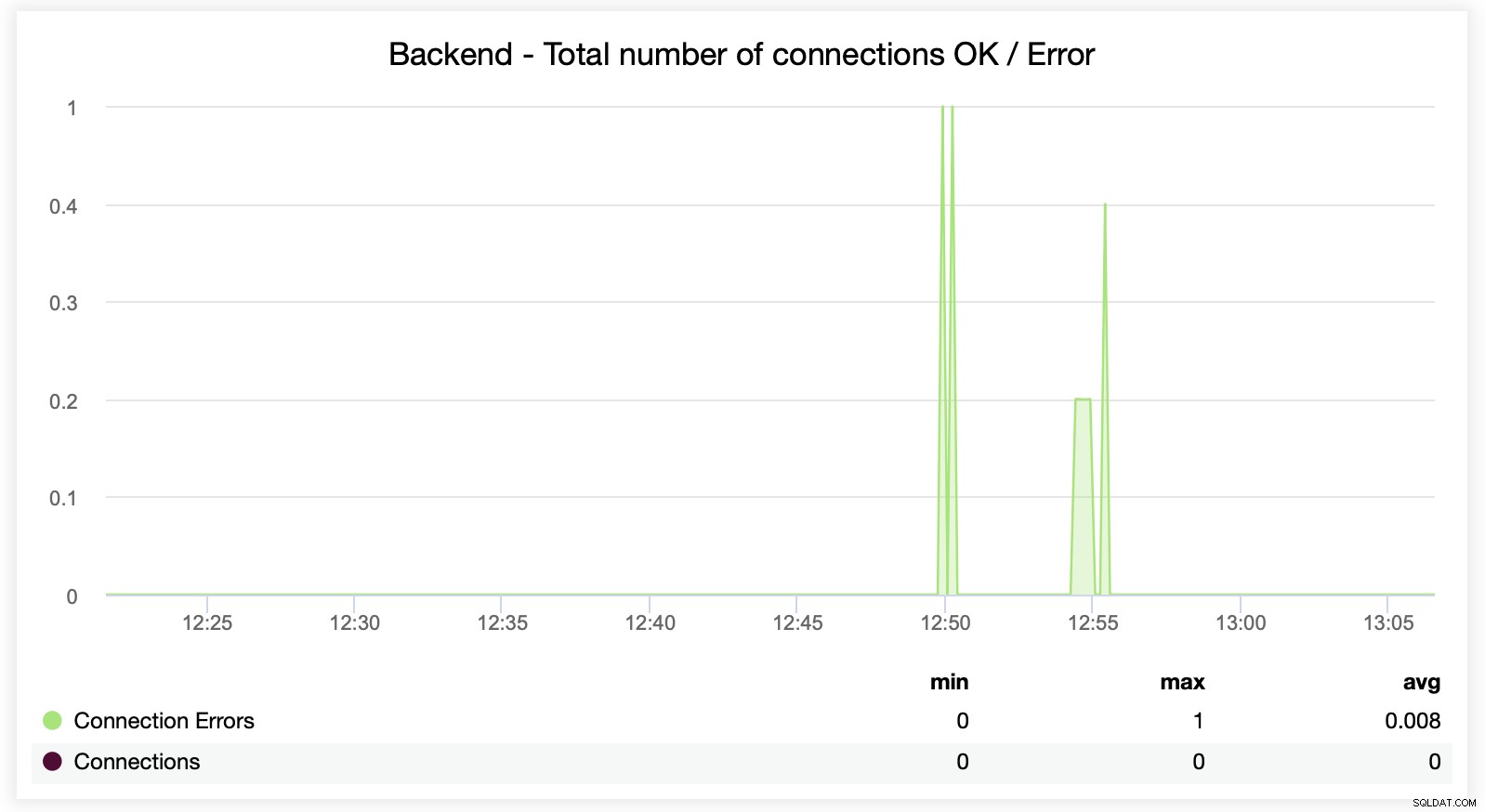
यहां आप देख सकते हैं कि ClusterControl वास्तविक समय में कनेक्शन त्रुटियों को ट्रैक करता है, जो उस सटीक समय को इंगित करने में मदद कर सकता है जब मुद्दे विकसित होने लगे।
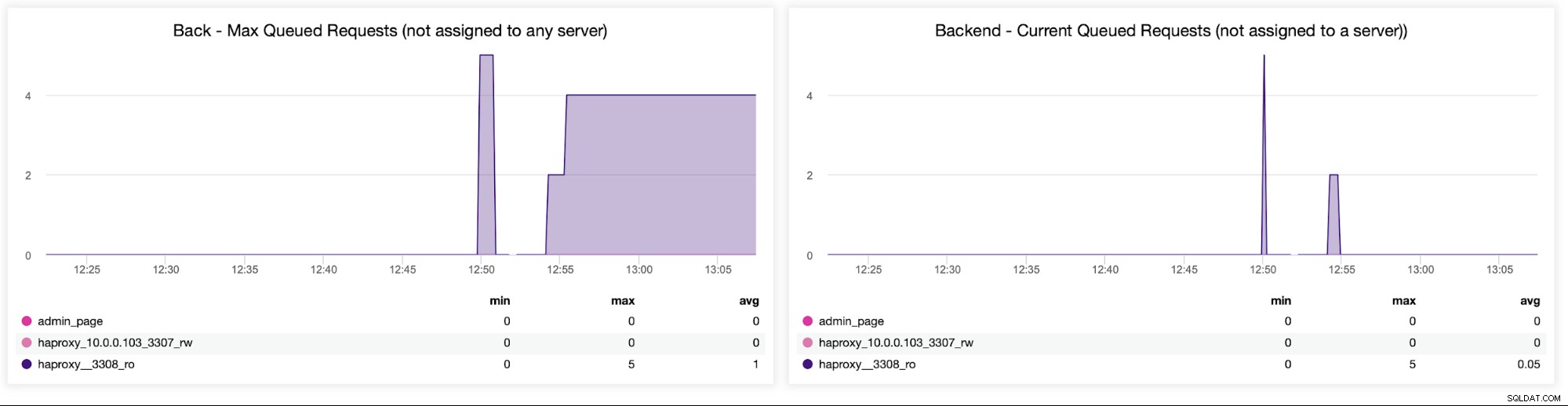
अंत में, हम कतारबद्ध अनुरोधों से संबंधित निम्नलिखित दो ग्राफ़ देखेंगे . HAProxy कतारें बैकएंड के लिए अनुरोध करती हैं यदि बैकएंड सर्वर ओवरसैचुरेटेड हैं। यह इंगित कर सकता है, उदाहरण के लिए, अतिभारित डेटाबेस सर्वर, जो और अधिक ट्रैफ़िक को संभाल नहीं सकता है।
रैपिंग अप
ClusterControl में अपने HAProxy लोड बैलेंसर को तैनात और मॉनिटर करने से आपके कनेक्शन के प्रबंधन और निगरानी का आसान काम करने में मदद मिल सकती है। आपके बैकएंड, ट्रैफ़िक वितरण, सत्र मीट्रिक, कनेक्शन त्रुटियों और कतारबद्ध अनुरोधों की संख्या के प्रदर्शन में स्पष्ट दृश्यता होने से किसी भी डेटाबेस सेटअप की उपलब्धता और मापनीयता सुनिश्चित करने में मदद मिल सकती है।
ClusterControl किसी भी डेटाबेस कॉन्फ़िगरेशन के लिए लोड बैलेंसर की स्थापना और निगरानी को आसान बनाता है। अभी तक ClusterControl का उपयोग नहीं कर रहे हैं? यदि आप स्वयं देखना चाहते हैं कि ClusterControl के साथ अपने HAProxy लोड बैलेंसर को तैनात करना और उसकी निगरानी करना कितना आसान है, तो हम आपको प्लेटफ़ॉर्म के 30-दिन के निःशुल्क परीक्षण के लिए आमंत्रित कर रहे हैं, जिसमें कोई स्ट्रिंग संलग्न नहीं है। लोड संतुलन के लिए HAProxy का उपयोग क्यों और कैसे करें, इस बारे में अधिक विस्तृत पूर्वाभ्यास के लिए, HAProxy के साथ MySQL लोड संतुलन पर हमारा ट्यूटोरियल देखें।