जैसा कि आपने मेरे पिछले ब्लॉग से देखा होगा, पिछले कुछ महीने पोस्टग्रेज-एक्सएल को पोस्टग्रेएसक्यूएल की नवीनतम 9.5 रिलीज के साथ अप-टू-डेट करने में व्यस्त थे। एक बार जब हमारे पास Postgres-XL 9.5 का एक उचित रूप से स्थिर संस्करण था, तो हमने अपना ध्यान Postgres-XL के इस ब्रांड के नए संस्करण के प्रदर्शन को मापने के लिए स्थानांतरित कर दिया। बेंचमार्क की हमारी पसंद काफी हद तक अनुदान समझौते 318633 के तहत यूरोपीय संघ द्वारा वित्त पोषित एक्सल परियोजना पर चल रहे काम से प्रभावित है। चूंकि हम इस परियोजना के तहत किए गए अन्य सभी कार्यों के प्रदर्शन को मापने के लिए टीपीसी बेंचमार्क ™ एच का उपयोग कर रहे हैं, इसलिए हमने फैसला किया Postgres-XL के मूल्यांकन के लिए समान बेंचमार्क का उपयोग करें। यह पोस्टग्रेस-एक्सएल के लिए भी उपयुक्त है क्योंकि टीपीसी-एच ओएलएपी वर्कलोड को मापने की कोशिश करता है, कुछ पोस्टग्रेस-एक्सएल को अच्छा करना चाहिए।
<एच2>1. Postgres-XL क्लस्टर सेटअपएक बार बेंचमार्क तय हो जाने के बाद, परीक्षण के लिए सही संसाधन खोजने की एक और बड़ी चुनौती थी। हमारे पास भौतिक मशीनों के बड़े समूह तक पहुंच नहीं थी। इसलिए हमने वही किया जो ज्यादातर करेंगे। हमने Postgres-XL क्लस्टर स्थापित करने के लिए Amazon AWS का उपयोग करने का निर्णय लिया। एडब्ल्यूएस इंस्टेंस की एक विस्तृत श्रृंखला पेश करता है, जिसमें प्रत्येक इंस्टेंस प्रकार अलग-अलग कंप्यूट या आईओ पावर प्रदान करता है।
एडब्ल्यूएस पर यह पेज विभिन्न उपलब्ध इंस्टेंस प्रकार, उपलब्ध संसाधनों और विभिन्न क्षेत्रों के लिए उनके मूल्य निर्धारण को दर्शाता है। यह ध्यान दिया जाना चाहिए कि कीमतें और उपलब्धता एक क्षेत्र से दूसरे क्षेत्र में भिन्न हो सकती हैं, इसलिए यह महत्वपूर्ण है कि आप सभी क्षेत्रों की जांच करें। चूंकि Postgres-XL को अपने घटकों के बीच कम विलंबता और उच्च थ्रूपुट की आवश्यकता होती है, इसलिए उसी क्षेत्र में सभी उदाहरणों को तत्काल करना भी महत्वपूर्ण है। हमारे 3TB TPC-H के लिए हमने i2.xlarge AWS इंस्टेंस के 16-डेटानोड क्लस्टर के लिए जाने का फैसला किया। इन उदाहरणों में 4 वीसीपीयू, 30 जीबी रैम और 800 जीबी एसएसडी प्रत्येक है, सभी वितरित तालिकाओं को रखने के लिए पर्याप्त भंडारण, प्रतिकृति टेबल (जो क्लस्टर के बढ़ते आकार के साथ अधिक स्थान लेते हैं), उन पर अनुक्रमणिका और अभी भी पर्याप्त खाली जगह छोड़ रहे हैं क्रिएट इंडेक्स और अन्य प्रश्नों के लिए अस्थायी टेबलस्पेस में।
2. बेंचमार्क सेटअप
2.1 टीपीसी बेंचमार्क™ एच
बेंचमार्क में बड़ी मात्रा में डेटा की जांच करने, उच्च स्तर की जटिलता के साथ प्रश्नों को निष्पादित करने और महत्वपूर्ण व्यावसायिक प्रश्नों के उत्तर देने के उद्देश्य से 22 प्रश्न हैं। हम यह नोट करना चाहेंगे कि संपूर्ण टीपीसी बेंचमार्क ™ एच विनिर्देश विभिन्न प्रकार के परीक्षणों से संबंधित है जैसे कि लोड, पावर और थ्रूपुट परीक्षण। हमारे परीक्षण के लिए, हमने केवल व्यक्तिगत प्रश्नों को चलाया है, संपूर्ण परीक्षण सूट को नहीं। TPC Benchmark™ H जटिल व्यावसायिक विश्लेषण अनुप्रयोगों के प्रतिनिधि के रूप में सिस्टम कार्यात्मकताओं का प्रयोग करने के लिए डिज़ाइन किए गए व्यावसायिक प्रश्नों का एक सेट शामिल है। इन प्रश्नों को एक वास्तविक संदर्भ दिया गया है, जो पाठक को बेंचमार्क के घटकों से सहजता से जोड़ने में मदद करने के लिए एक थोक आपूर्तिकर्ता की गतिविधि को चित्रित करता है।
2.2 डेटाबेस इकाइयां, संबंध और विशेषताएं
टीपीसी-एच डेटाबेस के घटकों को आठ अलग और अलग-अलग टेबल (बेस टेबल) से मिलकर परिभाषित किया गया है। इन तालिकाओं के स्तंभों के बीच संबंधों को निम्नलिखित आरेख में दिखाया गया है। 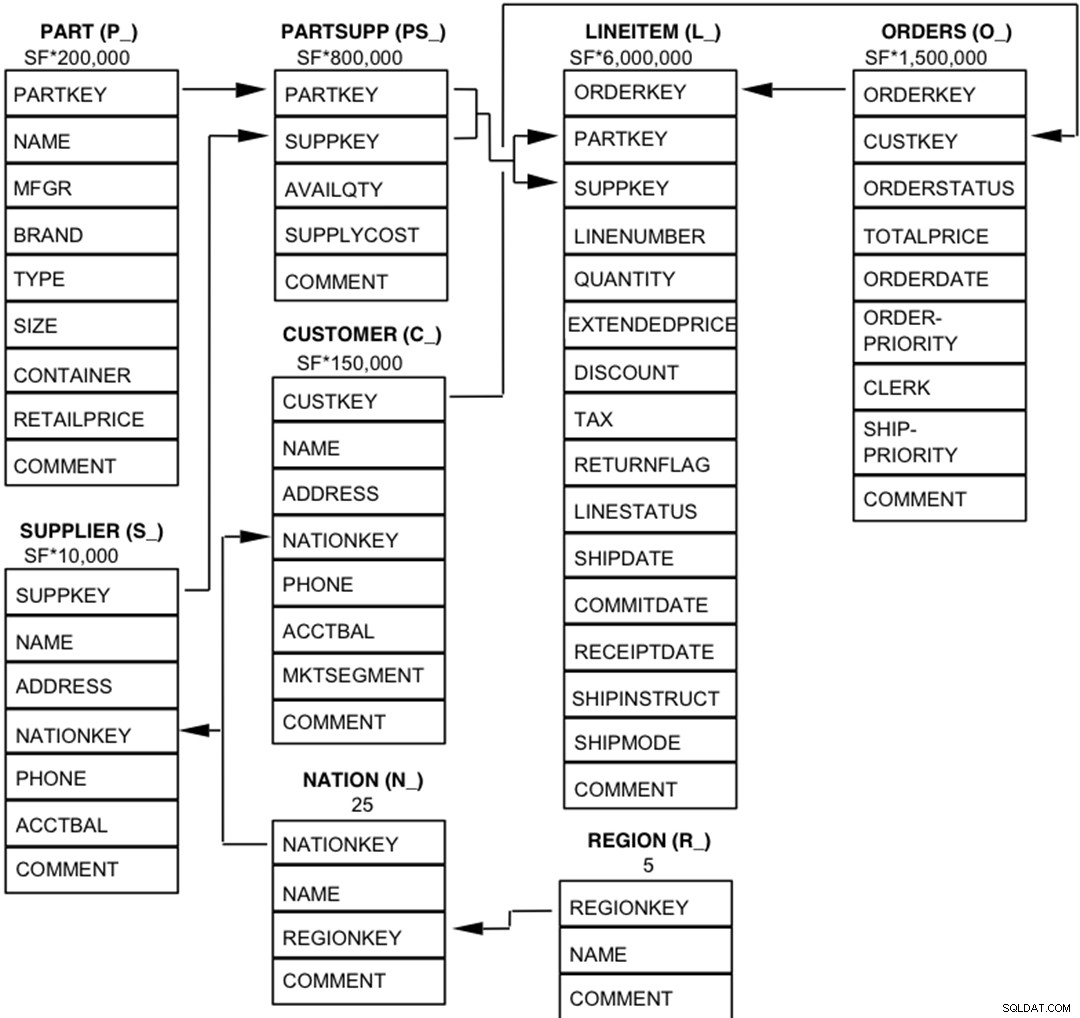 लीजेंड :
लीजेंड :
- प्रत्येक तालिका नाम का अनुसरण करने वाले कोष्ठक में उस तालिका के स्तंभ नामों का उपसर्ग होता है;
- तीर तालिकाओं के बीच एक-से-कई संबंधों की दिशा में इंगित करते हैं
- प्रत्येक तालिका नाम के नीचे की संख्या/सूत्र तालिका की कार्डिनैलिटी (पंक्तियों की संख्या) को दर्शाता है। चुने हुए डेटाबेस आकार को प्राप्त करने के लिए कुछ को एसएफ, स्केल फैक्टर द्वारा फैक्टर किया जाता है। LINEITEM तालिका की प्रमुखता अनुमानित है
2.3 Postgres-XL के लिए डेटा वितरण
हमने बेंचमार्क में सभी 22 प्रश्नों का विश्लेषण किया और बेंचमार्क में विभिन्न तालिकाओं के लिए निम्नलिखित डेटा वितरण रणनीति के साथ आए।
| तालिका का नाम | वितरण रणनीति |
| LINEITEM | HASH (l_orderkey) |
| आदेश | HASH (o_orderkey) |
| भाग | HASH (p_partkey) |
| पार्टसूप | HASH (ps_partkey) |
| ग्राहक | प्रतिकृति |
| आपूर्तिकर्ता | प्रतिकृति |
| राष्ट्र | प्रतिकृति |
| क्षेत्र | प्रतिकृति |
ध्यान दें कि LINEITEM और ORDERS जो कि बेंचमार्क में सबसे बड़ी तालिकाएं हैं, अक्सर ORDERKEY पर जुड़ जाते हैं। इसलिए ORDERKEY पर इन तालिकाओं को व्यवस्थित करने का बहुत अर्थ है। इसी तरह, PART और PARTSUPP को अक्सर PARTKEY पर जोड़ा जाता है और इसलिए उन्हें PARTKEY कॉलम पर रखा जाता है। बाकी तालिकाओं को दोहराया जाता है ताकि यह सुनिश्चित किया जा सके कि जरूरत पड़ने पर उन्हें स्थानीय रूप से जोड़ा जा सके।
3. बेंचमार्क परिणाम
3.1 लोड परीक्षण
हमने PostgreSQL 9.6 पर 3TB TPC-H लोड टेस्ट चलाकर प्राप्त परिणामों की तुलना 16-नोड Postgres-XL क्लस्टर से की। निम्नलिखित चार्ट Postgres-XL की प्रदर्शन विशेषताओं को प्रदर्शित करते हैं।
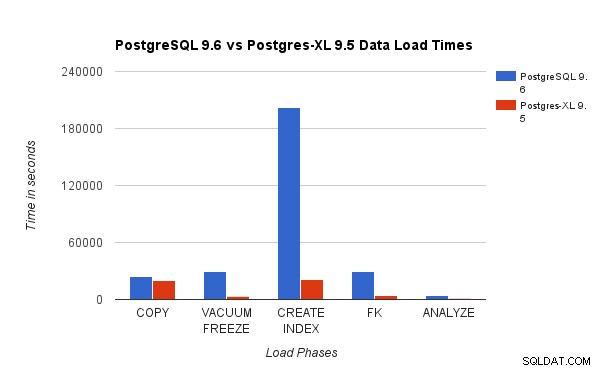 उपरोक्त चार्ट PostgreSQL और Postgres-XL के साथ लोड टेस्ट के विभिन्न चरणों को पूरा करने में लगने वाले समय को दर्शाता है। जैसा कि देखा गया है, Postgres-XL COPY के लिए थोड़ा बेहतर प्रदर्शन करता है और अन्य सभी मामलों के लिए बहुत बेहतर करता है। नोट :हमने देखा कि कॉपी चरण के दौरान समन्वयक को बहुत अधिक गणना शक्ति की आवश्यकता होती है, खासकर जब एक से अधिक कॉपी स्ट्रीम एक साथ चल रही हों। इसे संबोधित करने के लिए, समन्वयक को 16 वीसीपीयू के साथ एक कंप्यूट अनुकूलित एडब्ल्यूएस इंस्टेंस पर चलाया गया था। वैकल्पिक रूप से, हम कई समन्वयकों को भी चला सकते थे और उनके बीच कंप्यूट लोड वितरित कर सकते थे।
उपरोक्त चार्ट PostgreSQL और Postgres-XL के साथ लोड टेस्ट के विभिन्न चरणों को पूरा करने में लगने वाले समय को दर्शाता है। जैसा कि देखा गया है, Postgres-XL COPY के लिए थोड़ा बेहतर प्रदर्शन करता है और अन्य सभी मामलों के लिए बहुत बेहतर करता है। नोट :हमने देखा कि कॉपी चरण के दौरान समन्वयक को बहुत अधिक गणना शक्ति की आवश्यकता होती है, खासकर जब एक से अधिक कॉपी स्ट्रीम एक साथ चल रही हों। इसे संबोधित करने के लिए, समन्वयक को 16 वीसीपीयू के साथ एक कंप्यूट अनुकूलित एडब्ल्यूएस इंस्टेंस पर चलाया गया था। वैकल्पिक रूप से, हम कई समन्वयकों को भी चला सकते थे और उनके बीच कंप्यूट लोड वितरित कर सकते थे।
3.2 पावर टेस्ट
हमने PostgreSQL 9.6 और Postgres-XL 9.5 पर 3TB बेंचमार्क के लिए क्वेरी रन टाइम की भी तुलना की। निम्न चार्ट दो सेटअपों पर क्वेरी निष्पादन की प्रदर्शन विशेषताओं को दिखाता है।
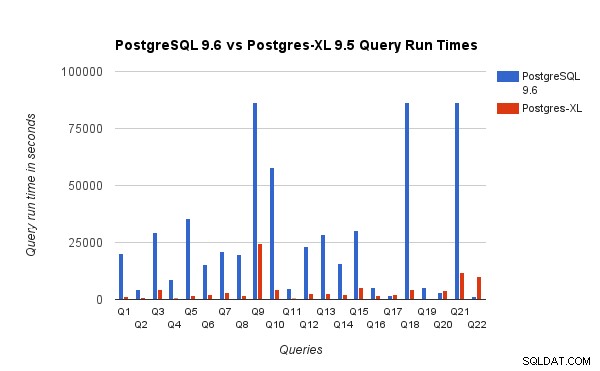 हमने देखा कि Postgres-XL पर औसतन क्वेरीज़ लगभग 6.4 गुना तेज़ी से चलती हैं और कम से कम 25% क्वेरीज़ प्रदर्शन में लगभग रैखिक सुधार दिखाया, दूसरे शब्दों में उन्होंने इस 16-नोड पोस्टग्रेज-एक्सएल क्लस्टर पर लगभग 16 गुना तेजी से प्रदर्शन किया। इसके अलावा कम से कम 50% प्रश्नों ने प्रदर्शन में 10 गुना सुधार दिखाया। हमने आगे क्वेरी प्रदर्शन का विश्लेषण किया और निष्कर्ष निकाला कि सभी उपलब्ध डेटानोड्स में अच्छी तरह से विभाजित किए गए प्रश्न, जैसे कि नोड्स के बीच डेटा का न्यूनतम आदान-प्रदान होता है और पोस्टग्रेज-एक्सएल में बार-बार रिमोट निष्पादन कॉल के बिना स्केल बहुत अच्छी तरह से होता है। इस तरह के प्रश्नों में आमतौर पर शीर्ष पर रिमोट सबक्वायरी स्कैन नोड होता है और नोड के नीचे उपट्री समानांतर में एक या अधिक नोड्स पर निष्पादित होती है। रिमोट सबक्वेरी स्कैन नोड के शीर्ष पर कुछ अन्य नोड्स जैसे लिमिट नोड या एग्रीगेट नोड होना भी आम है। पोस्टग्रेज-एक्सएल पर भी ऐसे प्रश्न बहुत अच्छा प्रदर्शन करते हैं। क्वेरी Q1 एक क्वेरी का एक उदाहरण है जिसे Postgres-XL के साथ बहुत अच्छी तरह से स्केल करना चाहिए। दूसरी ओर, जिन प्रश्नों के लिए डेटानोड-डेटानोड और/या समन्वयक-डेटानोड के बीच ट्यूपल्स के बहुत सारे आदान-प्रदान की आवश्यकता होती है, वे पोस्टग्रेज़-एक्सएल में अच्छा नहीं कर सकते हैं। इसी तरह, जिन प्रश्नों के लिए कई क्रॉस नोड कनेक्शन की आवश्यकता होती है, वे भी खराब प्रदर्शन दिखा सकते हैं। उदाहरण के लिए, आप देखेंगे कि Q22 का प्रदर्शन सिंगल नोड PostgreSQL सर्वर की तुलना में खराब है। जब हमने Q22 के लिए क्वेरी प्लान का विश्लेषण किया, तो हमने देखा कि क्वेरी प्लान में नेस्टेड रिमोट सबक्वेरी स्कैन नोड्स के तीन स्तर हैं, जहां प्रत्येक नोड डेटानोड्स के लिए समान संख्या में कनेक्शन खोलता है। इसके अलावा, नेस्ट लूप एंटी जॉइन का एक शीर्ष स्तर के रिमोट सबक्वेरी स्कैन नोड के साथ एक आंतरिक संबंध है और इसलिए बाहरी संबंध के प्रत्येक टपल के लिए इसे एक दूरस्थ सबक्वेरी निष्पादित करना होगा। इसके परिणामस्वरूप क्वेरी निष्पादन का खराब प्रदर्शन होता है।
हमने देखा कि Postgres-XL पर औसतन क्वेरीज़ लगभग 6.4 गुना तेज़ी से चलती हैं और कम से कम 25% क्वेरीज़ प्रदर्शन में लगभग रैखिक सुधार दिखाया, दूसरे शब्दों में उन्होंने इस 16-नोड पोस्टग्रेज-एक्सएल क्लस्टर पर लगभग 16 गुना तेजी से प्रदर्शन किया। इसके अलावा कम से कम 50% प्रश्नों ने प्रदर्शन में 10 गुना सुधार दिखाया। हमने आगे क्वेरी प्रदर्शन का विश्लेषण किया और निष्कर्ष निकाला कि सभी उपलब्ध डेटानोड्स में अच्छी तरह से विभाजित किए गए प्रश्न, जैसे कि नोड्स के बीच डेटा का न्यूनतम आदान-प्रदान होता है और पोस्टग्रेज-एक्सएल में बार-बार रिमोट निष्पादन कॉल के बिना स्केल बहुत अच्छी तरह से होता है। इस तरह के प्रश्नों में आमतौर पर शीर्ष पर रिमोट सबक्वायरी स्कैन नोड होता है और नोड के नीचे उपट्री समानांतर में एक या अधिक नोड्स पर निष्पादित होती है। रिमोट सबक्वेरी स्कैन नोड के शीर्ष पर कुछ अन्य नोड्स जैसे लिमिट नोड या एग्रीगेट नोड होना भी आम है। पोस्टग्रेज-एक्सएल पर भी ऐसे प्रश्न बहुत अच्छा प्रदर्शन करते हैं। क्वेरी Q1 एक क्वेरी का एक उदाहरण है जिसे Postgres-XL के साथ बहुत अच्छी तरह से स्केल करना चाहिए। दूसरी ओर, जिन प्रश्नों के लिए डेटानोड-डेटानोड और/या समन्वयक-डेटानोड के बीच ट्यूपल्स के बहुत सारे आदान-प्रदान की आवश्यकता होती है, वे पोस्टग्रेज़-एक्सएल में अच्छा नहीं कर सकते हैं। इसी तरह, जिन प्रश्नों के लिए कई क्रॉस नोड कनेक्शन की आवश्यकता होती है, वे भी खराब प्रदर्शन दिखा सकते हैं। उदाहरण के लिए, आप देखेंगे कि Q22 का प्रदर्शन सिंगल नोड PostgreSQL सर्वर की तुलना में खराब है। जब हमने Q22 के लिए क्वेरी प्लान का विश्लेषण किया, तो हमने देखा कि क्वेरी प्लान में नेस्टेड रिमोट सबक्वेरी स्कैन नोड्स के तीन स्तर हैं, जहां प्रत्येक नोड डेटानोड्स के लिए समान संख्या में कनेक्शन खोलता है। इसके अलावा, नेस्ट लूप एंटी जॉइन का एक शीर्ष स्तर के रिमोट सबक्वेरी स्कैन नोड के साथ एक आंतरिक संबंध है और इसलिए बाहरी संबंध के प्रत्येक टपल के लिए इसे एक दूरस्थ सबक्वेरी निष्पादित करना होगा। इसके परिणामस्वरूप क्वेरी निष्पादन का खराब प्रदर्शन होता है।
4. कुछ एडब्ल्यूएस पाठ
Postgres-XL को बेंचमार्क करते समय हमने AWS के उपयोग के बारे में कुछ सबक सीखे। हमने सोचा कि वे उन सभी के लिए उपयोगी होंगे जो AWS पर Postgres-XL का उपयोग/परीक्षण करना चाहते हैं।
- AWS कई अलग-अलग प्रकार के उदाहरण प्रस्तुत करता है। किसी विशिष्ट इंस्टेंस प्रकार को चुनने से पहले आपको अपने कार्य भार और आवश्यक संग्रहण की मात्रा का सावधानीपूर्वक मूल्यांकन करना चाहिए।
- अधिकांश भंडारण-अनुकूलित उदाहरणों में अल्पकालिक डिस्क जुड़ी होती हैं। आपको उन डिस्क के लिए कुछ भी अतिरिक्त भुगतान करने की आवश्यकता नहीं है, वे इंस्टेंस से जुड़े होते हैं और अक्सर ईबीएस से बेहतर प्रदर्शन करते हैं। लेकिन आपको उनका उपयोग करने में सक्षम होने के लिए उन्हें स्पष्ट रूप से माउंट करना होगा। हालांकि, ध्यान रखें कि इन डिस्क पर संग्रहीत डेटा स्थायी नहीं होता है और इंस्टेंस बंद होने पर मिटा दिया जाएगा। इसलिए सुनिश्चित करें कि आप उस स्थिति को संभालने के लिए तैयार हैं। चूंकि हम ज्यादातर बेंचमार्किंग के लिए AWS का उपयोग कर रहे थे, इसलिए हमने इन अल्पकालिक डिस्क का उपयोग करने का निर्णय लिया।
- यदि आप ईबीएस का उपयोग कर रहे हैं, तो सुनिश्चित करें कि आपने उपयुक्त प्रोविजन्ड आईओपीएस का चयन किया है। बहुत कम मान बहुत धीमे IO का कारण बनेगा, लेकिन बहुत अधिक मान आपके AWS बिल को काफी हद तक बढ़ा सकता है, खासकर जब बड़ी संख्या में नोड्स के साथ काम कर रहा हो।
- सुनिश्चित करें कि आप विलंबता को कम करने और उनके बीच कनेक्शन के लिए थ्रूपुट में सुधार करने के लिए एक ही क्षेत्र में उदाहरण शुरू करते हैं।
- सुनिश्चित करें कि आप इंस्टेंस को कॉन्फ़िगर करते हैं ताकि वे एक दूसरे से बात करने के लिए निजी नेटवर्क का उपयोग करें।
- स्पॉट इंस्टेंस देखें। वे अपेक्षाकृत सस्ते होते हैं। चूंकि AWS स्वेच्छा से स्पॉट इंस्टेंस को समाप्त कर सकता है, उदाहरण के लिए, यदि स्पॉट मूल्य आपकी अधिकतम बोली मूल्य से अधिक हो जाता है, तो उसके लिए तैयार रहें। पोस्टग्रेस-एक्सएल आंशिक रूप से या पूरी तरह से अनुपयोगी हो सकता है जिसके आधार पर नोड्स समाप्त हो जाते हैं। AWS launch_group की अवधारणा का समर्थन करता है। अगर एक ही launch_group, . में कई इंस्टेंस को समूह में रखा गया है यदि AWS एक उदाहरण को समाप्त करने का निर्णय लेता है, तो सभी उदाहरण समाप्त कर दिए जाएंगे।
5. निष्कर्ष
हम विभिन्न बेंचमार्क के माध्यम से यह दिखाने में सक्षम हैं कि Postgres-XL वास्तविक दुनिया, जटिल प्रश्नों के एक बड़े सेट के लिए वास्तव में अच्छी तरह से स्केल कर सकता है। ये बेंचमार्क हमें OLAP वर्कलोड के प्रभावी समाधान के रूप में Postgres-XL की क्षमता को प्रदर्शित करने में मदद करते हैं। हमारे प्रयोग यह भी दिखाते हैं कि Postgres-XL के साथ कुछ प्रदर्शन समस्याएं हैं, विशेष रूप से बहुत बड़े समूहों के लिए और जब योजनाकार किसी योजना का गलत चुनाव करता है। हमने यह भी देखा कि जब डेटानोड के साथ बहुत बड़ी संख्या में समवर्ती कनेक्शन होते हैं, तो प्रदर्शन खराब हो जाता है। हम इन प्रदर्शन समस्याओं पर काम करना जारी रखेंगे। हम उपयुक्त वर्कलोड का उपयोग करके OLTP समाधान के रूप में Postgres-XL की क्षमता का भी परीक्षण करना चाहेंगे।