लोग आश्चर्य करते हैं कि क्या उन्हें अपवादों को रोकने के लिए अपना सर्वश्रेष्ठ प्रयास करना चाहिए, या बस सिस्टम को उन्हें संभालने देना चाहिए। मैंने कई चर्चाएँ देखी हैं जहाँ लोग बहस करते हैं कि क्या उन्हें अपवाद को रोकने के लिए जो कुछ भी करना चाहिए वह करना चाहिए, क्योंकि त्रुटि प्रबंधन "महंगा" है। इसमें कोई संदेह नहीं है कि त्रुटि प्रबंधन मुक्त नहीं है, लेकिन मैं भविष्यवाणी करता हूं कि एक बाधा उल्लंघन कम से कम उतना ही कुशल है जितना पहले संभावित उल्लंघन की जांच करना। उदाहरण के लिए, यह स्थिर बाधा उल्लंघन की तुलना में एक महत्वपूर्ण उल्लंघन के लिए अलग हो सकता है, लेकिन इस पोस्ट में मैं पूर्व पर ध्यान केंद्रित करने जा रहा हूं।
अपवादों से निपटने के लिए लोग जिन प्राथमिक तरीकों का उपयोग करते हैं वे हैं:
- बस इंजन को इसे संभालने दें, और किसी भी अपवाद को कॉल करने वाले को वापस बुला लें।
BEGIN TRANSACTIONका उपयोग करें औरROLLBACKअगर@@ERROR <> 0।TRY/CATCHका प्रयोग करेंROLLBACKके साथCATCH. में ब्लॉक (एसक्यूएल सर्वर 2005+)।
और कई लोग यह तरीका अपनाते हैं कि उन्हें यह जांचना चाहिए कि क्या वे पहले उल्लंघन करने जा रहे हैं, क्योंकि ऐसा लगता है कि इंजन को ऐसा करने के लिए मजबूर करने के बजाय डुप्लिकेट को स्वयं संभालना साफ है। मेरा सिद्धांत यह है कि आपको भरोसा करना चाहिए लेकिन सत्यापित करना चाहिए; उदाहरण के लिए, इस दृष्टिकोण पर विचार करें (ज्यादातर छद्म कोड):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
हम जानते हैं कि IF NOT EXISTS चेक इस बात की गारंटी नहीं देता है कि जब तक हम INSERT पर पहुंचेंगे, तब तक किसी और ने पंक्ति नहीं डाली होगी (जब तक हम टेबल पर आक्रामक ताले नहीं लगाते और/या SERIALIZABLE का उपयोग नहीं करते ), लेकिन बाहरी जांच हमें विफलता करने की कोशिश करने और फिर वापस रोल करने से रोकती है। हम संपूर्ण TRY/CATCH . से दूर रहते हैं संरचना यदि हम पहले से ही जानते हैं कि INSERT विफल हो जाएगा, और यह मानना तर्कसंगत होगा कि - कम से कम कुछ मामलों में - यह TRY/CATCH दर्ज करने से अधिक कुशल होगा बिना शर्त संरचना। एक INSERT . में इसका कोई मतलब नहीं है परिदृश्य, लेकिन एक ऐसे मामले की कल्पना करें जहां उस TRY . में और कुछ चल रहा हो ब्लॉक करें (और अधिक संभावित उल्लंघन जिन्हें आप पहले से जांच सकते हैं, जिसका अर्थ है कि और भी अधिक काम जो आपको अन्यथा करना पड़ सकता है और बाद में उल्लंघन होने पर वापस रोल बैक करना होगा)।
अब, यह देखना दिलचस्प होगा कि क्या होगा यदि आप एक गैर-डिफ़ॉल्ट अलगाव स्तर (कुछ ऐसा जो मैं भविष्य की पोस्ट में व्यवहार करूंगा) का उपयोग करता हूं, विशेष रूप से संगामिति के साथ। इस पोस्ट के लिए, हालांकि, मैं धीरे-धीरे शुरू करना चाहता था, और एक ही उपयोगकर्ता के साथ इन पहलुओं का परीक्षण करना चाहता था। मैंने dbo.[Objects] . नामक एक तालिका बनाई है , एक बहुत ही सरल तालिका:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
मैं इस तालिका को नमूना डेटा की 100,000 पंक्तियों के साथ पॉप्युलेट करना चाहता था। नाम कॉलम में मानों को अद्वितीय बनाने के लिए (चूंकि पीके वह बाधा है जिसका मैं उल्लंघन करना चाहता था), मैंने एक सहायक फ़ंक्शन बनाया जो कई पंक्तियों और न्यूनतम स्ट्रिंग लेता है। न्यूनतम स्ट्रिंग का उपयोग यह सुनिश्चित करने के लिए किया जाएगा कि या तो (ए) सेट ऑब्जेक्ट तालिका में अधिकतम मान से आगे शुरू हुआ, या (बी) ऑब्जेक्ट तालिका में न्यूनतम मान पर सेट शुरू हुआ। (मैं परीक्षणों के दौरान इन्हें मैन्युअल रूप से निर्दिष्ट करूंगा, केवल डेटा का निरीक्षण करके सत्यापित किया जाएगा, हालांकि मैं शायद उस चेक को फ़ंक्शन में बना सकता था।)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
यह एक CROSS JOIN लागू होता है का sys.all_objects अपने आप में, प्रत्येक नाम के लिए एक अद्वितीय row_number जोड़ रहा है, इसलिए पहले 10 परिणाम इस तरह दिखाई देंगे:
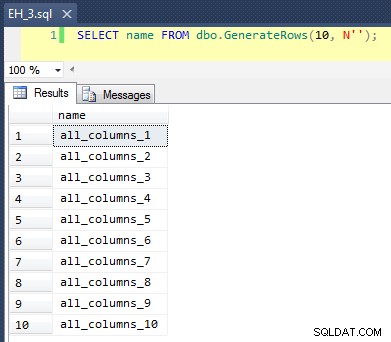
तालिका को 100,000 पंक्तियों से भरना आसान था:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
अब, चूंकि हम तालिका में नए अद्वितीय मान डालने जा रहे हैं, इसलिए मैंने प्रत्येक परीक्षण की शुरुआत और अंत में कुछ सफाई करने के लिए एक प्रक्रिया बनाई - हमारे द्वारा जोड़ी गई किसी भी नई पंक्तियों को हटाने के अलावा, यह भी साफ हो जाएगी कैश और बफ़र्स। कुछ ऐसा नहीं है जिसे आप अपने उत्पादन प्रणाली पर एक प्रक्रिया में कोड करना चाहते हैं, लेकिन स्थानीय प्रदर्शन परीक्षण के लिए बिल्कुल ठीक है।
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
मैंने प्रत्येक परीक्षण के लिए प्रारंभ और समाप्ति समय का ट्रैक रखने के लिए एक लॉग तालिका भी बनाई है:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
अंत में, परीक्षण संग्रहीत प्रक्रिया विभिन्न चीजों को संभालती है। हमारे पास तीन अलग-अलग त्रुटि प्रबंधन विधियां हैं, जैसा कि ऊपर की गोलियों में वर्णित है:"जस्टइन्सर्ट", "रोलबैक", और "ट्राईकैच"; हमारे पास तीन अलग-अलग सम्मिलित प्रकार भी हैं:(1) सभी प्रविष्टियां सफल होती हैं (सभी पंक्तियां अद्वितीय होती हैं), (2) सभी प्रविष्टियां विफल होती हैं (सभी पंक्तियां डुप्लीकेट होती हैं), और (3) आधा प्रविष्टियां सफल होती हैं (आधी पंक्तियां अद्वितीय होती हैं, और आधी पंक्तियाँ डुप्लिकेट हैं)। इसके साथ दो अलग-अलग दृष्टिकोण हैं:डालने का प्रयास करने से पहले उल्लंघन की जांच करें, या बस आगे बढ़ें और इंजन को यह निर्धारित करने दें कि यह मान्य है या नहीं। मैंने सोचा था कि यह टकराव की विभिन्न संभावनाओं के साथ संयुक्त विभिन्न त्रुटि प्रबंधन तकनीकों की एक अच्छी तुलना देगा, यह देखने के लिए कि उच्च या निम्न टक्कर प्रतिशत परिणामों को महत्वपूर्ण रूप से प्रभावित करेगा या नहीं।
इन परीक्षणों के लिए मैंने अपने सम्मिलित प्रयासों की कुल संख्या के रूप में 40,000 पंक्तियों को चुना, और इस प्रक्रिया में मैं 20,000 अन्य अद्वितीय या गैर-अद्वितीय पंक्तियों के साथ 20,000 अद्वितीय या गैर-अद्वितीय पंक्तियों का एक संघ करता हूं। आप देख सकते हैं कि मैंने प्रक्रिया में कटऑफ स्ट्रिंग्स को हार्ड-कोड किया है; कृपया ध्यान दें कि आपके सिस्टम पर ये कटऑफ लगभग निश्चित रूप से एक अलग जगह पर होंगे।
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GOछोड़ें
अब हम इस प्रक्रिया को विभिन्न तर्कों के साथ कॉल कर सकते हैं, जिसके बाद हम अलग-अलग व्यवहार प्राप्त कर सकते हैं, 40,000 मान सम्मिलित करने का प्रयास कर रहे हैं (और निश्चित रूप से, प्रत्येक मामले में कितने सफल या असफल होने चाहिए)। प्रत्येक 'त्रुटि प्रबंधन विधि' के लिए (बस सम्मिलित करने का प्रयास करें, ट्रॅन/रोलबैक शुरू करें, या कोशिश करें/पकड़ें) और प्रत्येक सम्मिलित प्रकार (सभी सफल, आधा सफल, और कोई भी सफल नहीं), उल्लंघन की जांच करने के लिए संयुक्त है या नहीं सबसे पहले, यह हमें 18 संयोजन देता है:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
इसे चलाने के बाद (इसमें मेरे सिस्टम पर लगभग 8 मिनट लगते हैं), हमें अपने लॉग में कुछ परिणाम मिले हैं। मैंने पूरे बैच को पांच बार दौड़ाया ताकि यह सुनिश्चित हो सके कि हमें अच्छा औसत मिले और किसी भी तरह की विसंगतियों को दूर किया जा सके। ये रहे परिणाम:
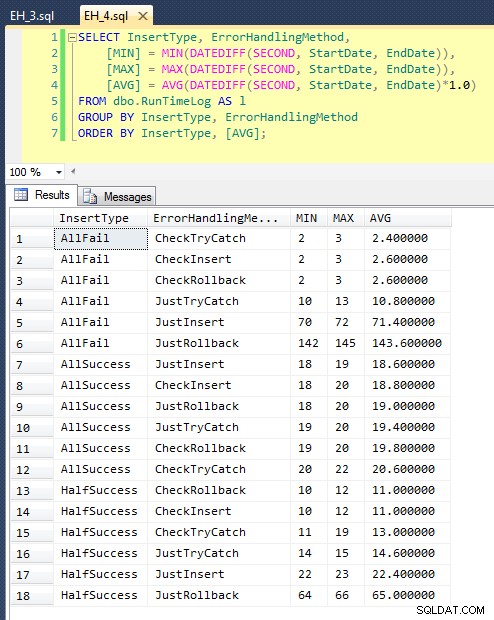
ग्राफ़ जो सभी अवधियों को एक साथ प्लॉट करता है, कुछ गंभीर आउटलेयर दिखाता है:
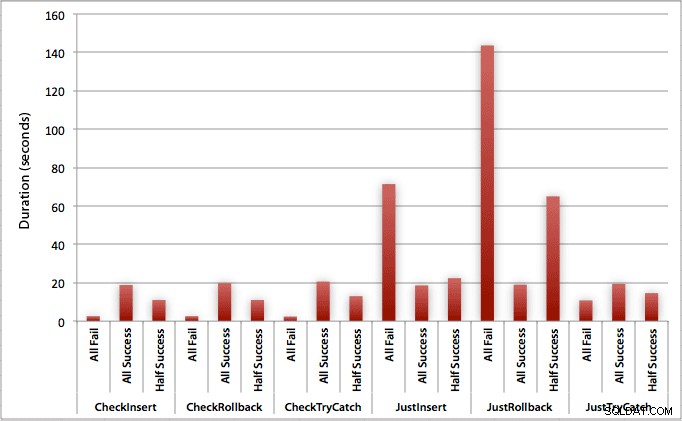
आप देख सकते हैं कि, ऐसे मामलों में जहां हम विफलता की उच्च दर (इस परीक्षण में, 100%) की अपेक्षा करते हैं, लेन-देन शुरू करना और वापस रोल करना अब तक कम से कम आकर्षक दृष्टिकोण (प्रति प्रयास 3.59 मिलीसेकंड) है, जबकि केवल इंजन को बढ़ाने देना एक त्रुटि लगभग आधी खराब है (1.785 मिलीसेकंड प्रति प्रयास)। अगला सबसे खराब प्रदर्शन वह मामला था जहां हम लेन-देन शुरू करते हैं और फिर उसे वापस रोल करते हैं, ऐसे परिदृश्य में जहां हम लगभग आधे प्रयासों के विफल होने की उम्मीद करते हैं (औसतन 1.625 मिलीसेकंड प्रति प्रयास)। ग्राफ़ के बाईं ओर के 9 मामले, जहां हम पहले उल्लंघन की जांच कर रहे हैं, प्रति प्रयास 0.515 मिलीसेकंड से ऊपर नहीं गए।
ऐसा कहने के बाद, प्रत्येक परिदृश्य के लिए अलग-अलग ग्राफ़ (सफलता का उच्च%, विफलता का उच्च%, और 50-50) वास्तव में प्रत्येक विधि के प्रभाव को घर ले जाते हैं।
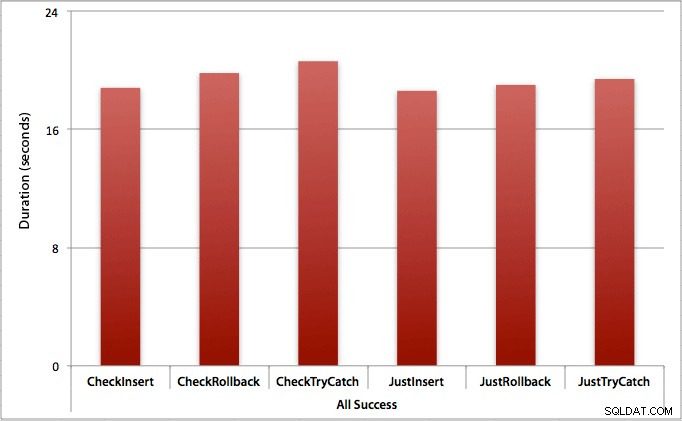
जहां सभी प्रविष्टियां सफल होती हैं
इस मामले में हम देखते हैं कि पहले उल्लंघन के लिए जाँच का ओवरहेड नगण्य है, पूरे बैच में 0.7 सेकंड के औसत अंतर के साथ (या 125 माइक्रोसेकंड प्रति सम्मिलित प्रयास):
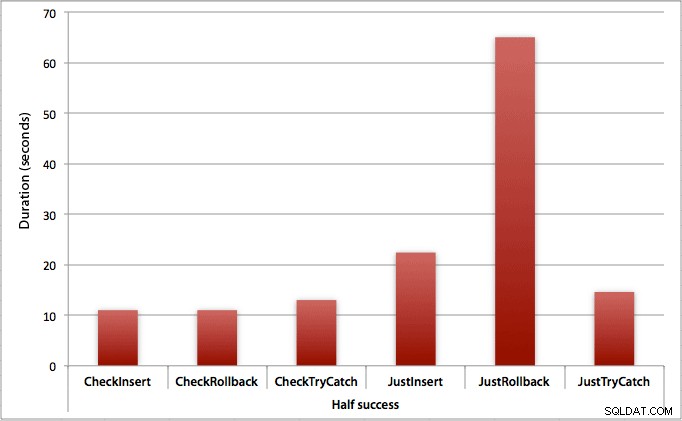
जहां केवल आधे इंसर्ट सफल होते हैं
जब आधे इंसर्ट विफल हो जाते हैं, तो हम इंसर्ट / रोलबैक विधियों की अवधि में एक बड़ी छलांग देखते हैं। जिस परिदृश्य में हम एक लेन-देन शुरू करते हैं और उसे वापस रोल करते हैं, पहले जांच की तुलना में बैच में लगभग 6x धीमा होता है (1.625 मिलीसेकंड प्रति प्रयास बनाम 0.275 मिलीसेकंड प्रति प्रयास)। जब हम पहली बार जांच करते हैं तो TRY/CATCH विधि भी 11% तेज होती है:
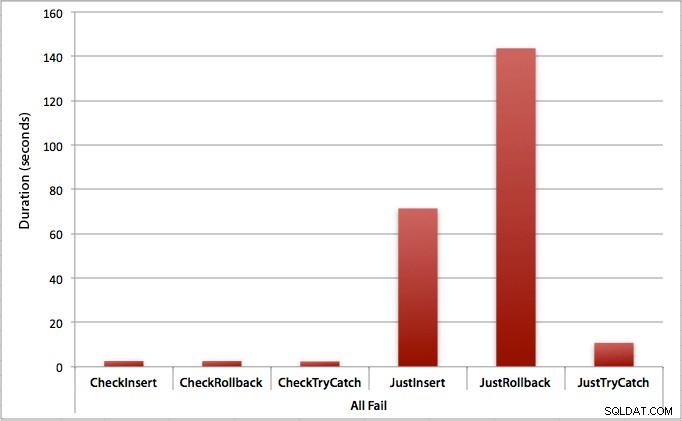
जहां सभी इंसर्ट विफल हो जाते हैं
जैसा कि आप उम्मीद कर सकते हैं, यह त्रुटि प्रबंधन का सबसे स्पष्ट प्रभाव दिखाता है, और पहले जांच करने का सबसे स्पष्ट लाभ दिखाता है। इस मामले में रोलबैक विधि लगभग 70x धीमी है जब हम जांच नहीं करते हैं जब हम करते हैं (3.59 मिलीसेकंड प्रति प्रयास बनाम 0.065 मिलीसेकंड प्रति प्रयास):
यह हमें क्या बताता है? अगर हमें लगता है कि हमारे पास विफलता की उच्च दर होने जा रही है, या हमें पता नहीं है कि हमारी संभावित विफलता दर क्या होगी, तो इंजन में उल्लंघन से बचने के लिए पहले जांच करना हमारे समय के लिए काफी फायदेमंद होगा। यहां तक कि उस मामले में जहां हमारे पास हर बार एक सफल इंसर्ट होता है, पहले जांच की लागत मामूली होती है और बाद में त्रुटियों को संभालने की संभावित लागत से आसानी से उचित होती है (जब तक कि आपकी अनुमानित विफलता दर बिल्कुल 0% न हो)।
तो अभी के लिए मुझे लगता है कि मैं अपने सिद्धांत पर टिकूंगा कि, साधारण मामलों में, SQL सर्वर को आगे बढ़ने और वैसे भी डालने से पहले संभावित उल्लंघन की जांच करना समझ में आता है। भविष्य की पोस्ट में, मैं विभिन्न अलगाव स्तरों, समवर्ती, और शायद कुछ अन्य त्रुटि प्रबंधन तकनीकों के प्रदर्शन प्रभाव को भी देखूंगा।
[एक तरफ, मैंने इस पोस्ट का एक संक्षिप्त संस्करण फरवरी में mssqltips.com के लिए एक टिप के रूप में लिखा था।]