एकीकृत परिवहन एक ऐसी चीज है जिसके बारे में हम अक्सर इंटरनेट या समाचारों में सुनते हैं। हालांकि यह कुछ नया नहीं है, यह निश्चित रूप से एक सतत प्रक्रिया है, जिसमें निरंतर परिवर्तन लागू किए जा रहे हैं। आज, हम एक डेटा मॉडल पर एक नज़र डालेंगे जो ज़ोन, यात्री और टिकट की जानकारी को संभाल सकता है।
आइए हम अपने एकीकृत परिवहन डेटा मॉडल की खोज करें, इसके पीछे के विचार से शुरू करें।
विचार
इसकी दक्षता को अधिकतम करने के लिए और ग्राहकों के लिए, इसके आसान उपयोग के लिए परिवहन को एकीकृत करना आवश्यक है। एकीकरण लागत से संबंधित है लेकिन समय, पहुंच, आराम और सुरक्षा से भी संबंधित है। यह बड़े शहरों के साथ-साथ छोटे शहरों पर भी लागू होता है। विचार मौजूदा परिवहन बुनियादी ढांचे का उपयोग करना और बेहतर परिणामों के लिए इसे अनुकूलित करना है; इसका मतलब नए शेड्यूल, नोटिफिकेशन, लाइन या स्टेशन के साथ आना हो सकता है। हो सकता है कि बस के लिए प्रतीक्षा करने, साइकिल किराए पर लेने, या बस अपने गंतव्य तक पैदल चलने का निर्णय लेने के लिए बस कुछ जानकारी होना ही पर्याप्त हो।
आइए इसे दो उदाहरणों से समझाएं।
एक बड़े शहर के मामले में, आमतौर पर परिवहन के कई अलग-अलग साधन उपलब्ध होते हैं:बसें, टैक्सी, ट्राम, रेलवे, भूमिगत, आदि। इससे कई अलग-अलग निजी कंपनियां विभिन्न परिवहन सेवाएं प्रदान कर सकती हैं। इनमें से कुछ सेवाओं के संयोजन से निश्चित रूप से यात्रियों और कंपनियों को लागत कम करने, दक्षता बढ़ाने और प्रति टिकट अधिक सेवा प्रदान करने से लाभ होगा।
एक छोटे शहर के लिए भी इसी तरह के लाभ हैं। गठबंधन करने के लिए समान संख्या में विकल्प नहीं हो सकते हैं, लेकिन अधिकतम दक्षता प्राप्त करने के लिए उन्हें व्यवस्थित किया जा सकता है।
यह लेख मुख्य रूप से एकीकृत परिवहन टिकट प्रणाली पर केंद्रित होगा। हम एकीकरण के सभी पहलुओं और विभिन्न प्रकार के परिवहन पर ध्यान केंद्रित नहीं करेंगे; यह बहुत जटिल होगा।
इसे ध्यान में रखते हुए, आइए अपने मॉडल पर चलते हैं।
डेटा मॉडल
मॉडल में दो विषय क्षेत्र शामिल हैं:
Cities & companiesTickets
हम उनका वर्णन उसी क्रम में करेंगे जिस क्रम में वे सूचीबद्ध हैं।
शहर और कंपनियां
पहले विषय क्षेत्र में, हम शहरों में परिवहन क्षेत्र स्थापित करने के लिए आवश्यक सभी तालिकाओं को संग्रहीत करेंगे।
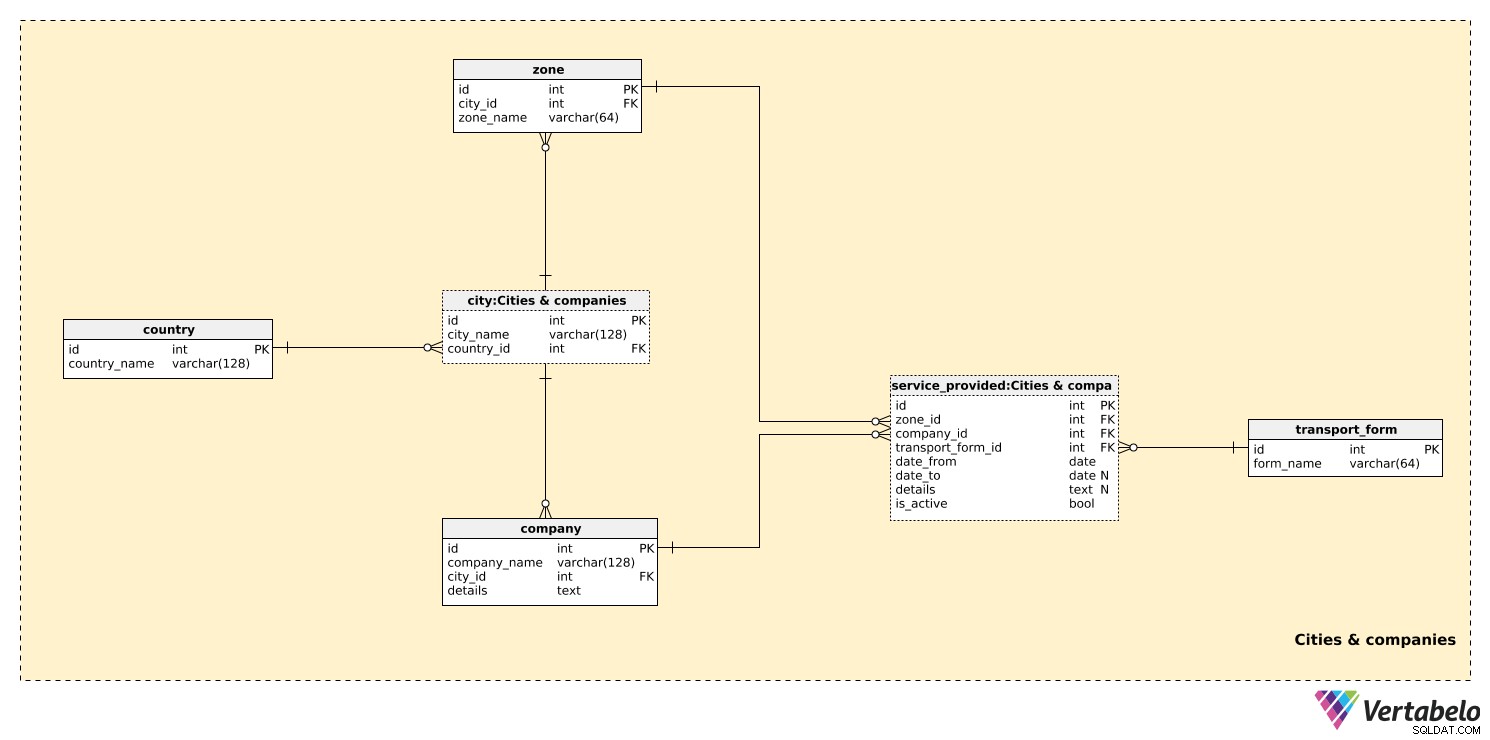
country तालिका में UNIQUE की एक सूची है country_name मूल्य। इस तालिका का उपयोग केवल city टेबल। जबकि हम उम्मीद कर सकते हैं कि हमारा मॉडल केवल एक देश में परिवहन को कवर करेगा, हम कई देशों को शामिल करने का विकल्प चाहते हैं। प्रत्येक शहर के लिए, हम UNIQUE संयोजन city_name . संग्रहित करेंगे - country_id .
छोटे शहरों में शायद एक ही जोन होगा, जबकि बड़े शहरों में कई जोन होंगे। सभी संभावित क्षेत्रों की सूची zone टेबल। प्रत्येक ज़ोन के लिए, हम उसका zone_name स्टोर करेंगे और संबंधित शहर के लिए एक संदर्भ। यह जोड़ी इस तालिका की वैकल्पिक कुंजी बनाती है।
हम उम्मीद कर सकते हैं कि हमारा सिस्टम कई परिवहन कंपनियों के बारे में जानकारी संग्रहीत करेगा। कंपनियां अपने खुद के टिकट जारी करेंगी, लेकिन वे अन्य कंपनियों के साथ संयुक्त रूप से टिकट भी जारी कर सकेंगी। प्रत्येक company , हम company_name . के UNIQUE संयोजन को संग्रहित करेंगे और city_id जहाँ यह स्थित है। किसी भी आवश्यक अतिरिक्त जानकारी को शाब्दिक details . में संग्रहीत किया जा सकता है फ़ील्ड.
आखिरी चीज जिसे हमें परिभाषित करने की आवश्यकता है वह है परिवहन का रूप जो प्रत्येक कंपनी प्रदान करती है। कुछ अपेक्षित मान "बस", "ट्राम", "भूमिगत" और "रेलवे" हैं। transport_form तालिका, हम UNIQUE form_name संग्रहीत करेंगे।
zone_id-zoneतालिका और उस क्षेत्र को दर्शाता है जहां इस कंपनी द्वारा परिवहन का यह रूप प्रदान किया जाता है।company_id- संदर्भcompanyइस क्षेत्र में यह सेवा प्रदान करना।transport_form_id-transport_formतालिका और प्रदान की गई सेवा के प्रकार को दर्शाता है।date_fromऔरdate_to- जिस अवधि के दौरान इस कंपनी द्वारा यह सेवा प्रदान की गई थी। ध्यान दें किdate_toयदि यह सेवा अभी भी उपलब्ध है और/या इसकी कोई अपेक्षित समाप्ति तिथि नहीं है, तो इसमें NULL मान हो सकता है।details- अन्य सभी विवरण, एक असंरचित पाठ्य प्रारूप में।is_active- यदि यह सेवा सक्रिय है (चल रही है) या नहीं। यह एक आसान ऑन/ऑफ स्विच है जिसका उपयोग हम कुछ मामलों मेंdate_from. के बजाय कर सकते हैं -date_toसेवा गतिविधि अंतराल। इस विशेषता का सबसे अच्छा उपयोग प्रश्नों को सरल बनाना होगा, यानी दिनांक अंतराल का परीक्षण करने और NULL मानों के साथ "खेलने" के बजाय इस मान का परीक्षण करके।
टिकट
पिछला विषय क्षेत्र सिर्फ मुख्य चीज की तैयारी था:टिकट। और इस विषय क्षेत्र में यही शामिल होगा।
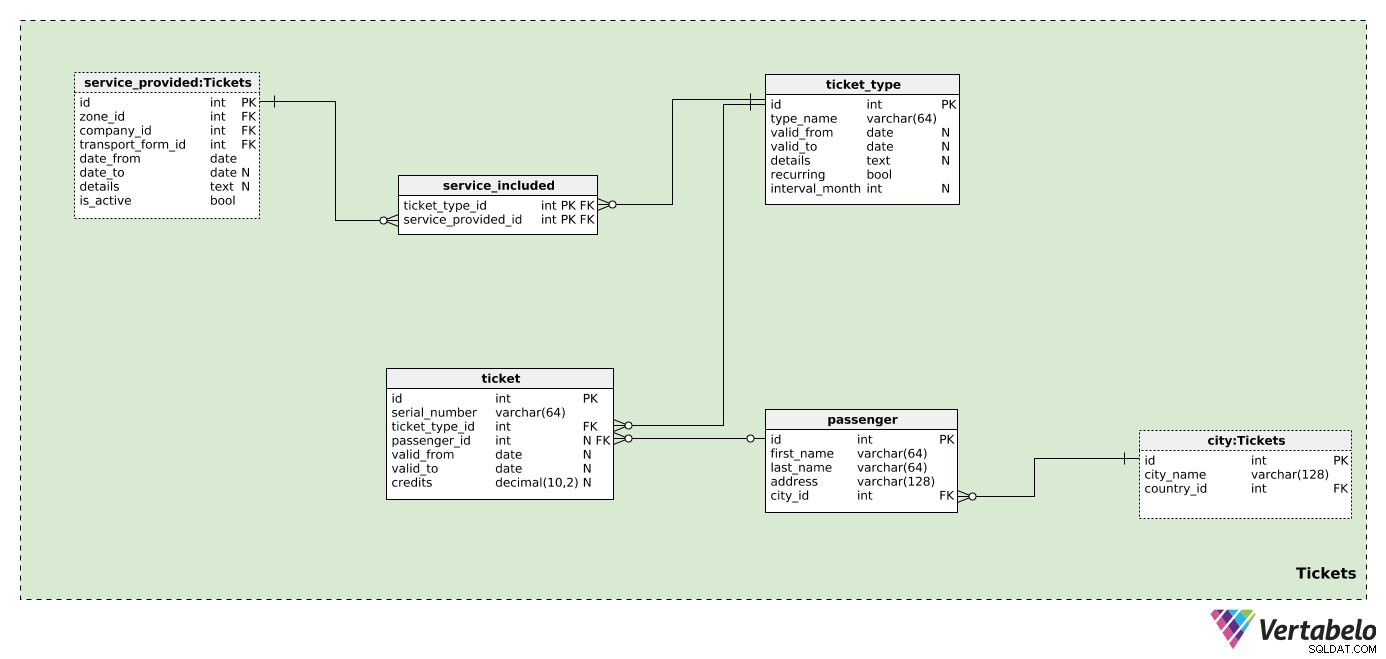
हमने कंपनियों, क्षेत्रों और परिवहन रूपों को परिभाषित किया है, लेकिन हमारे पास यात्रियों और टिकटों के लिए कोई प्रावधान नहीं है - इस मॉडल का मूल। हम मान लेंगे कि एक टिकट का उपयोग एक या अधिक कंपनियों द्वारा कवर किए गए एक या अधिक क्षेत्रों के लिए किया जा सकता है।
इसलिए, हमें पहले प्रत्येक ticket_type . इस तालिका में, हम अपने डेटाबेस में कंपनियों द्वारा बेचे जा रहे सभी संभावित प्रकार के टिकटों को सूचीबद्ध करेंगे। प्रत्येक प्रकार के लिए, हम निम्नलिखित मान संग्रहीत करेंगे:
type_name- इस प्रकार को विशिष्ट रूप से दर्शाने वाला एक नाम।valid_fromऔरvalid_to- वह अवधि जब यह टिकट प्रकार वैध है (या था)। दोनों फ़ील्ड अशक्त हैं; एक NULL मान का अर्थ है कि यह कब मान्य था इसके लिए कोई आरंभ (या समाप्ति) तिथि नहीं है।details- कोई भी आवश्यक विवरण, असंरचित पाठ्य प्रारूप में।recurring- एक ध्वज यह दर्शाता है कि यह टिकट प्रकार आवर्ती है (जैसे वार्षिक, मासिक) या नहीं।interval_month- अगर टिकट का प्रकार आवर्ती है, तो इस विशेषता में महीनों में अंतराल होगा, जब इसकी पुनरावृत्ति होगी (उदाहरण के लिए मासिक टिकट के लिए "1", वार्षिक टिकट के लिए "12")।
अब हम प्रत्येक टिकट प्रकार द्वारा कवर किए गए क्षेत्रों को परिभाषित करने के लिए तैयार हैं। service_included तालिका में, हम केवल UNIQUE युग्म संग्रहीत करेंगे ticket_type_id - service_available_id . उत्तरार्द्ध कंपनी और उस क्षेत्र को भी इंगित करेगा जहां इस टिकट का उपयोग किया जा सकता है। यह तालिका हमें प्रति टिकट कई क्षेत्रों को परिभाषित करने की अनुमति देती है; क्षेत्र विभिन्न कंपनियों के हो सकते हैं। चूंकि ये पूर्वनिर्धारित टिकट प्रकार हैं, इसलिए प्रत्येक टिकट प्रकार में यहां परिभाषित क्षेत्र होंगे (प्रत्येक व्यक्तिगत यात्री के लिए नहीं)।
हम इस मॉडल में बहुत अधिक यात्री विवरण संग्रहीत नहीं करेंगे। प्रत्येक passenger , हम केवल उनका first_name संग्रहित करेंगे , last_name , address , और उस शहर का संदर्भ जहां वे रहते हैं। यह सारा डेटा टिकट पर प्रदर्शित किया जाएगा।
हमारे मॉडल में अंतिम तालिका है Tickets टेबल। हम यहां एकल-उपयोग वाले टिकटों पर ध्यान केंद्रित नहीं करेंगे; इसके बजाय, हम सब्सक्रिप्शन और प्रीपेड टिकटों का प्रबंधन करेंगे। इन टिकटों में बैलेंस, वैलिडिटी डेट या दोनों होंगे। यह कंपनी और उसके नियमों के आधार पर काफी भिन्न हो सकता है। यदि कुछ कंपनियां टिकट जारी करने का निर्णय लेती हैं, तो हम इस तालिका में इसका समर्थन कर सकते हैं - हम सभी महत्वपूर्ण विवरण जानेंगे। प्रत्येक टिकट के लिए, हम स्टोर करेंगे:
serial_number- प्रत्येक टिकट के लिए एक अद्वितीय पदनाम। यह संख्याओं और अक्षरों का संयोजन हो सकता है।ticket_type_id- उस टिकट के प्रकार का संदर्भ देता है।passenger_id- उस यात्री को संदर्भित करता है, यदि कोई हो, जो उस टिकट का मालिक है। प्रीपेड टिकट के मामले में, कोई मालिक नहीं हो सकता है।valid_fromऔरvalid_to- उस अवधि को दर्शाता है जिसके दौरान यह टिकट वैध है। NULL मान दर्शाता है कि कोई निचली या ऊपरी सीमा नहीं है।credits- उस टिकट पर वर्तमान में उपलब्ध क्रेडिट (संख्यात्मक मान के रूप में)। अगर यह प्रीपेड टिकट है, तो हम मान सकते हैं कि यात्री टिकट पर अतिरिक्त क्रेडिट खरीदेंगे। यदि टिकट पूरे महीने (या किसी अन्य समय अवधि) के दौरान उपयोग की किसी सीमा के बिना वैध है, तो यह मान शून्य हो सकता है।
एकीकृत परिवहन डेटा मॉडल में सुधार
आप देख सकते हैं कि इस मॉडल को बहुत सरल बनाया गया है। ऐसा इसलिए है क्योंकि एकीकृत परिवहन एक लेख में शामिल होने के लिए बहुत बड़ा है। कुछ चीजें हैं जो मुझे लगता है कि इस मॉडल में बदली जा सकती हैं:
- क्षेत्र बहुत सरल हैं; हमें उन्हें अधिक गतिशील रूप से परिभाषित करने में सक्षम होना चाहिए।
- हम लाइनों (जैसे बस लाइन) को कवर नहीं करते हैं। क्या होगा यदि वे एक क्षेत्र से दूसरे क्षेत्र में जाते हैं, आदि?
- हम टिकट उपयोग के इतिहास को संग्रहीत नहीं करते हैं।
- कंपनियों और यात्रियों के लिए कोई पंजीकरण नहीं है।
ये सभी इस तथ्य की ओर ले जाएंगे कि हमारे पास महत्वपूर्ण डेटा की कमी है और हम कोई गहरा विश्लेषण नहीं कर सकते। तो आप क्या सोचते हैं? इस मॉडल को क्या चाहिए? आप क्या जोड़ेंगे या हटाएंगे? टिप्पणियों में अपने विचार साझा करें।