नोट:यह पोस्ट मूल रूप से केवल हमारी ईबुक, SQL सर्वर के लिए उच्च प्रदर्शन तकनीक, खंड 4 में प्रकाशित हुई थी। आप हमारी ई-पुस्तकों के बारे में यहां जान सकते हैं।
मुझसे नियमित रूप से सवाल पूछा जाता है, "जब SQL सर्वर इंस्टेंस को ट्यून करने का प्रयास करने की बात आती है तो मैं कहां से शुरू करूं?" मेरी पहली प्रतिक्रिया उनसे उनके उदाहरण के विन्यास के बारे में पूछना है। अगर कुछ चीजें ठीक से कॉन्फ़िगर नहीं की जाती हैं तो लंबे समय से चल रहे या उच्च लागत वाले प्रश्नों को तुरंत देखना शुरू करना व्यर्थ प्रयास हो सकता है।
मैंने उन सामान्य चीजों के बारे में ब्लॉग किया है जो प्रशासकों को याद आती हैं जहां मैं कई सेटिंग्स साझा करता हूं जिन्हें व्यवस्थापकों को SQL सर्वर की डिफ़ॉल्ट स्थापना से बदलना चाहिए। प्रदर्शन से संबंधित वस्तुओं के लिए, मैं उन्हें बताता हूं कि उन्हें निम्नलिखित की जांच करनी चाहिए:
- स्मृति सेटिंग
- आंकड़े अपडेट करना
- इंडेक्स रखरखाव
- MAXDOP और समानता के लिए लागत सीमा
- tempdb सर्वोत्तम अभ्यास
- तदर्थ कार्यभार के लिए अनुकूलित करें
एक बार जब मैं कॉन्फ़िगरेशन आइटम से आगे निकल जाता हूं, तो मैं पूछता हूं कि क्या उन्होंने फ़ाइल और प्रतीक्षा आंकड़ों के साथ-साथ उच्च लागत वाले प्रश्नों को देखा है। अधिकांश समय प्रतिक्रिया "नहीं" होती है - एक स्पष्टीकरण के साथ कि वे सुनिश्चित नहीं हैं कि वह जानकारी कैसे प्राप्त करें।
आम तौर पर जब कोई कहता है कि उसे SQL सर्वर को ट्यून करने की आवश्यकता है तो आम शिकायत यह है कि यह धीमा चल रहा है। धीमी का क्या मतलब है? क्या यह एक निश्चित रिपोर्ट, एक विशिष्ट अनुप्रयोग, या सब कुछ है? क्या यह अभी होना शुरू हुआ है, या यह समय के साथ खराब हो रहा है? मैं सामान्य ट्राइएज प्रश्न पूछकर शुरू करता हूं कि मेमोरी, सीपीयू और डिस्क उपयोग की तुलना तब की जाती है जब चीजें सामान्य होती हैं, क्या समस्या अभी शुरू हुई है, और हाल ही में क्या बदल गया है। जब तक क्लाइंट बेसलाइन कैप्चर नहीं कर रहा है, तब तक उनके पास तुलना करने के लिए मेट्रिक्स नहीं हैं, यह जानने के लिए कि क्या वर्तमान आँकड़े असामान्य हैं।
लगभग हर SQL सर्वर जिस पर मैं काम करता हूँ एक से अधिक उपयोगकर्ता डेटाबेस को होस्ट करता है। जब कोई क्लाइंट रिपोर्ट करता है कि SQL सर्वर धीमा चल रहा है, तो अधिकांश समय वे किसी विशिष्ट एप्लिकेशन के बारे में चिंतित रहते हैं जो उनके ग्राहकों के लिए समस्याएँ पैदा कर रहा है। एक नुकीली प्रतिक्रिया उस विशेष डेटाबेस पर तुरंत ध्यान केंद्रित करना है, हालांकि कई बार एक और प्रक्रिया मूल्यवान संसाधनों का उपभोग कर सकती है और एप्लिकेशन का डेटाबेस प्रभावित हो रहा है। उदाहरण के लिए, यदि आपके पास एक बड़ा रिपोर्टिंग डेटाबेस है और किसी ने एक विशाल रिपोर्ट शुरू की है जो डिस्क को संतृप्त करती है, सीपीयू को बढ़ाती है, और योजना कैश को फ्लश करती है, तो आप शर्त लगा सकते हैं कि अन्य उपयोगकर्ता डेटाबेस धीमा हो जाएगा जबकि वह रिपोर्ट तैयार की जा रही है।
मैं हमेशा फ़ाइल आँकड़ों को देखकर शुरुआत करना पसंद करता हूँ। SQL सर्वर 2005 और उसके बाद के संस्करण के लिए, आप प्रत्येक डेटा और लॉग फ़ाइल के लिए I/O आँकड़े प्राप्त करने के लिए sys.dm_io_virtual_file_stats DMV को क्वेरी कर सकते हैं। इस DMV ने fn_virtualfilestats फ़ंक्शन को बदल दिया है। फ़ाइल आँकड़ों को कैप्चर करने के लिए, मैं एक स्क्रिप्ट का उपयोग करना पसंद करता हूं जिसे पॉल रैंडल ने एक साथ रखा है:समय की अवधि के लिए IO विलंबता को कैप्चर करना। यह स्क्रिप्ट एक बेसलाइन कैप्चर करेगी और, 30 मिनट बाद (जब तक कि आप WAITFOR DELAY सेक्शन में अवधि नहीं बदलते), आँकड़ों को कैप्चर करें और उनके बीच डेल्टा की गणना करें। पॉल की लिपि पढ़ने और लिखने की विलंबता को निर्धारित करने के लिए थोड़ा सा गणित भी करती है, जिससे हमारे लिए पढ़ना और समझना बहुत आसान हो जाता है।
अपने लैपटॉप पर मैंने एक यूएसबी ड्राइव पर एडवेंचरवर्क्स2014 डेटाबेस की एक प्रति को पुनर्स्थापित किया ताकि मेरे पास धीमी डिस्क गति हो; इसके बाद मैंने इसके खिलाफ लोड उत्पन्न करने के लिए एक प्रक्रिया शुरू की। आप नीचे परिणाम देख सकते हैं जहां मेरी डेटा फ़ाइल के लिए मेरी लेखन विलंबता 240ms है और मेरी लॉग फ़ाइल के लिए लेखन विलंबता 46ms है। यह उच्च विलंबता परेशानी का सबब है।
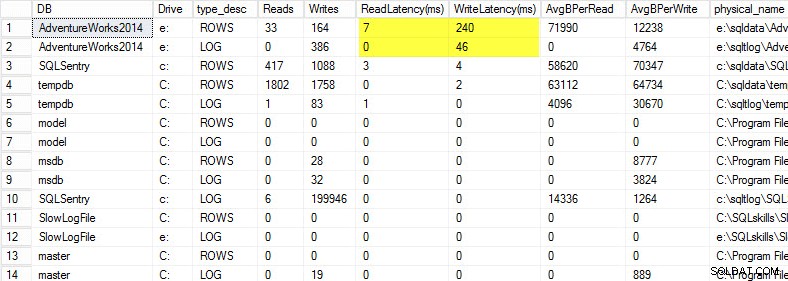
20ms से अधिक की किसी भी चीज़ को बुरा माना जाना चाहिए, जैसा कि मैंने पिछली पोस्ट में साझा किया था:मॉनिटरिंग रीड/राइट लेटेंसी। मेरी रीड लेटेंसी अच्छी है, लेकिन एडवेंचरवर्क्स2014 डेटाबेस धीमी गति से लिखने से पीड़ित है। इस मामले में मैं जांच करूंगा कि मेरे I/O सबसिस्टम प्रदर्शन की जांच करने के साथ-साथ लेखन क्या उत्पन्न कर रहा है। यदि यह अत्यधिक उच्च पठन विलंबता थी, तो मैं क्वेरी प्रदर्शन की जांच करना शुरू कर दूंगा (उदाहरण के लिए, लापता इंडेक्स से यह इतने सारे रीड क्यों कर रहा है), साथ ही साथ समग्र I/O सबसिस्टम प्रदर्शन।
अपने I/O सबसिस्टम के समग्र प्रदर्शन को जानना महत्वपूर्ण है, और यह जानने का सबसे अच्छा तरीका है कि यह क्या करने में सक्षम है, इसे बेंचमार्क करके। ग्लेन बेरी इस बारे में अपने आलेख में SQL सर्वर के लिए I/O प्रदर्शन का विश्लेषण करते हुए बात करते हैं। ग्लेन विलंबता, आईओपीएस और थ्रूपुट की व्याख्या करता है और क्रिस्टलडिस्कमार्क दिखाता है जो एक निःशुल्क टूल है जिसका उपयोग आप अपने स्टोरेज को बेसलाइन करने के लिए कर सकते हैं।
यह पता लगाने के बाद कि फ़ाइल आँकड़े कैसा प्रदर्शन कर रहे हैं, मैं DMV sys.dm_os_wait_stats का उपयोग करके प्रतीक्षा आँकड़ों को देखना पसंद करता हूँ, जो कि हुई सभी प्रतीक्षाओं के बारे में जानकारी देता है। इसके लिए मैं एक और स्क्रिप्ट की ओर मुड़ता हूं जो पॉल रान्डल अपने कैप्चरिंग वेट स्टैटिस्टिक्स में समय की अवधि के ब्लॉग पोस्ट के लिए प्रदान करता है। पॉल की स्क्रिप्ट फिर से हमारे लिए थोड़ा गणित करती है, लेकिन इससे भी महत्वपूर्ण बात यह है कि इसमें बहुत सारे सौम्य इंतजार शामिल नहीं हैं जिनकी हम आमतौर पर परवाह नहीं करते हैं। इस स्क्रिप्ट में WAITFOR DELAY भी है और इसे 30 मिनट के लिए सेट किया गया है। प्रतीक्षा आँकड़े पढ़ना थोड़ा अधिक कठिन हो सकता है:आपके पास वे प्रतीक्षाएँ हो सकती हैं जो प्रतिशत के आधार पर उच्च प्रतीत होती हैं, लेकिन औसत प्रतीक्षा इतनी कम है कि चिंता की कोई बात नहीं है।
मैंने उसी लोड प्रक्रिया को शुरू किया और अपने प्रतीक्षा आँकड़े कैप्चर किए, जो मैंने नीचे दिखाए हैं। इनमें से कई प्रतीक्षा प्रकारों के स्पष्टीकरण के लिए आप पॉल के ब्लॉग पोस्ट में से एक को पढ़ सकते हैं, आंकड़े प्रतीक्षा कर सकते हैं, या कृपया मुझे बताएं कि यह कहां दर्द होता है, साथ ही इस ब्लॉग पर उनकी कुछ पोस्ट भी।
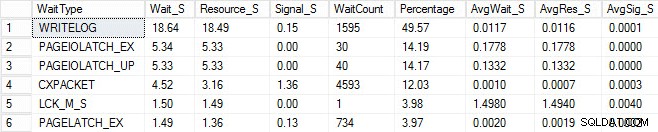
इस आकस्मिक आउटपुट में, PAGEIOLATCH प्रतीक्षा मेरे I/O सबसिस्टम के साथ एक अड़चन का संकेत दे सकती है, लेकिन यह एक स्मृति समस्या भी हो सकती है, इसके बजाय टेबल स्कैन, या अन्य मुद्दों की मेजबानी हो सकती है। मेरे मामले में, हम जानते हैं कि यह एक डिस्क समस्या है, क्योंकि मैं डेटाबेस को USB स्टिक पर संग्रहीत कर रहा हूं। LCK_M_S प्रतीक्षा समय बहुत अधिक है, हालांकि प्रतीक्षा का केवल एक उदाहरण है। मेरा WRITELOG भी मेरे द्वारा देखे जाने की तुलना में अधिक है, लेकिन USB स्टिक के साथ विलंबता मुद्दों को जानना समझ में आता है। यह भी दिखाता है कि CXPACKET इंतजार कर रहा है, और घुटने के बल प्रतिक्रिया करना आसान होगा और आपको लगता है कि आपके पास समांतरता/MAXDOP मुद्दा है, हालांकि AvgWait_S काउंटर बहुत कम है। समस्या निवारण के लिए प्रतीक्षा का उपयोग करते समय सावधान रहें। यह आपको उन चीजों के बारे में बताने के लिए एक मार्गदर्शक होने दें जो समस्या नहीं हैं और साथ ही आपको यह भी बताती हैं कि मुद्दों की तलाश में कहां जाना है। उचित समस्या निवारण समस्या को कम करने के लिए कई क्षेत्रों के व्यवहारों को सहसंबद्ध कर रहा है।
फ़ाइल को देखने और आँकड़ों की प्रतीक्षा करने के बाद, मुझे मिली समस्याओं के आधार पर उच्च लागत वाले प्रश्नों की खोज शुरू होती है। इसके लिए मैं ग्लेन बेरी की नैदानिक सूचना प्रश्नों की ओर मुड़ता हूं। प्रश्नों के ये सेट गो-टू स्क्रिप्ट हैं जिनका उपयोग कई सलाहकार करते हैं। ग्लेन और समुदाय उन्हें यथासंभव सूचनात्मक और मजबूत बनाने के लिए लगातार अपडेट प्रदान कर रहे हैं। मेरे पसंदीदा प्रश्नों में से एक निष्पादन गणना द्वारा शीर्ष कैश किए गए प्रश्न हैं। मुझे ऐसे प्रश्न या संग्रहीत कार्यविधियाँ खोजना अच्छा लगता है जिनमें उच्च निष्पादन_गणना उच्च कुल_लॉजिकल_रीड्स के साथ होती है। यदि उन प्रश्नों में ट्यूनिंग के अवसर हैं तो आप जल्दी से सर्वर पर एक बड़ा बदलाव ला सकते हैं। लिपियों में कुल लॉजिकल रीड्स द्वारा टॉप कैश्ड एसपी और कुल फिजिकल रीड्स द्वारा टॉप कैश्ड एसपी शामिल हैं। ये दोनों उच्च निष्पादन संख्या के साथ उच्च पठन की तलाश के लिए अच्छे हैं ताकि आप I/Os की संख्या को कम कर सकें।
ग्लेन की लिपियों के अलावा, मैं एडम मचानिक के sp_whoisactive का उपयोग यह देखने के लिए करना चाहता हूं कि वर्तमान में क्या चल रहा है।
फ़ाइल और प्रतीक्षा आँकड़े और उच्च-लागत वाले प्रश्नों को देखने की तुलना में प्रदर्शन ट्यूनिंग के लिए बहुत कुछ है, हालांकि मैं वहीं से शुरू करना चाहता हूं। यह समस्या का कारण क्या है, यह निर्धारित करने के लिए किसी परिवेश को शीघ्रता से ट्राइएज करने का एक तरीका है। ट्यून करने का कोई पूरी तरह से मूर्खतापूर्ण तरीका नहीं है:प्रत्येक उत्पादन डीबीए को समाप्त करने के लिए चीजों की एक चेकलिस्ट की आवश्यकता होती है और सिस्टम के स्वास्थ्य का विश्लेषण करने के लिए स्क्रिप्ट का एक अच्छा संग्रह चलाने के लिए वास्तव में अच्छा संग्रह होता है। सामान्य बनाम असामान्य व्यवहार को जल्दी से दूर करने के लिए आधार रेखा होना महत्वपूर्ण है। मेरे अच्छे दोस्त एरिन स्टेलाटो के पास प्लूरलसाइट पर एक संपूर्ण पाठ्यक्रम है जिसे SQL सर्वर कहा जाता है:बेंचमार्किंग और बेसलाइनिंग यदि आपको अपनी आधार रेखा को स्थापित करने और कैप्चर करने में सहायता की आवश्यकता है।
बेहतर अभी तक, SQL संतरी प्रदर्शन सलाहकार जैसा एक अत्याधुनिक उपकरण प्राप्त करें जो न केवल प्रोफाइलिंग और ट्रेंडिंग के लिए ऐतिहासिक जानकारी एकत्र और संग्रहीत करेगा, और ऊपर वर्णित सभी विवरणों तक आसान पहुंच प्रदान करेगा, बल्कि यह भी देता है गतिविधि की तुलना बिल्ट-इन या उपयोगकर्ता-परिभाषित बेसलाइन से करने की क्षमता, बिना उंगली उठाए कुशलतापूर्वक इंडेक्स बनाए रखना, और एक बहुत ही मजबूत कस्टम परिस्थितियों के आधार पर प्रतिक्रियाओं को स्वचालित या स्वचालित करना। निम्न स्क्रीन शॉट प्रदर्शन सलाहकार डैशबोर्ड के ऐतिहासिक दृश्य को दर्शाता है, जिसमें डिस्क नारंगी रंग में प्रतीक्षा करती है, डेटाबेस I/O नीचे दाईं ओर, और बेसलाइन प्रत्येक ग्राफ़ पर वर्तमान और पिछली अवधि की तुलना करती है (विस्तार करने के लिए क्लिक करें):
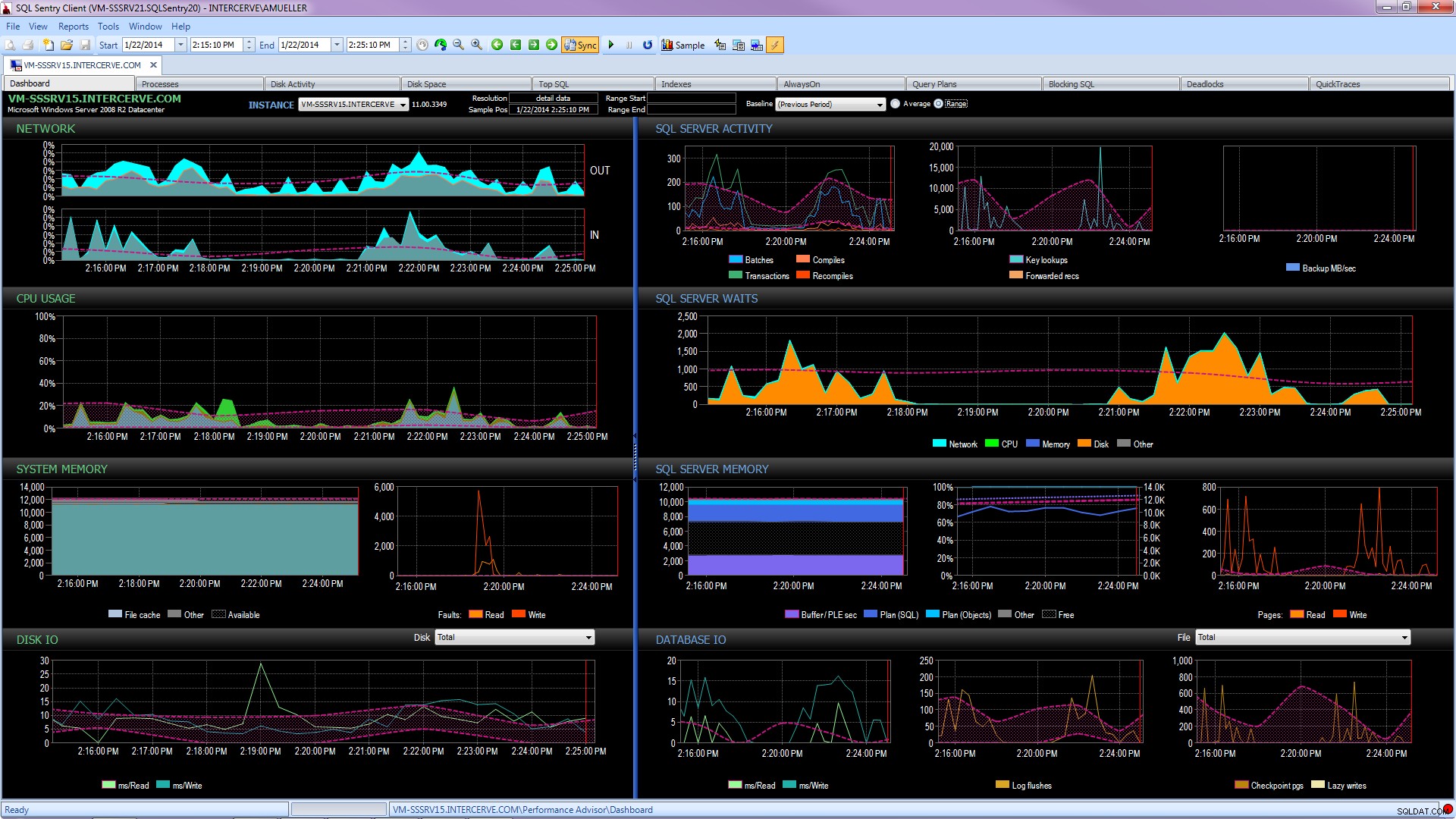
गुणवत्ता निगरानी उपकरण मुफ़्त नहीं हैं, लेकिन वे ढेर सारी कार्यक्षमता और समर्थन प्रदान करते हैं जो आपको प्रश्नों, नौकरियों और चेतावनियों पर ध्यान केंद्रित करने के बजाय अपने सर्वर पर प्रदर्शन के मुद्दों पर ध्यान केंद्रित करने की अनुमति देते हैं जो हो सकता है आपको अपने प्रदर्शन के मुद्दों पर ध्यान केंद्रित करने की अनुमति देता है - लेकिन केवल एक बार जब आप उन्हें ठीक कर लेते हैं। पहिए का पुन:आविष्कार न करने में अक्सर बहुत अच्छा मूल्य होता है।



