लगभग एक साल पहले, मैंने SQL सर्वर में पेजिनेशन के लिए अपना समाधान पोस्ट किया था, जिसमें प्रश्न में पंक्तियों के सेट के लिए केवल महत्वपूर्ण मानों का पता लगाने के लिए सीटीई का उपयोग करना शामिल था, और फिर सीटीई से स्रोत तालिका में वापस शामिल होना शामिल था। पंक्तियों के उस "पृष्ठ" के लिए अन्य कॉलम। यह सबसे फायदेमंद साबित हुआ जब एक संकीर्ण इंडेक्स था जो उपयोगकर्ता द्वारा अनुरोधित ऑर्डरिंग का समर्थन करता था, या जब ऑर्डरिंग क्लस्टरिंग कुंजी पर आधारित थी, लेकिन आवश्यक सॉर्ट का समर्थन करने के लिए इंडेक्स के बिना थोड़ा बेहतर प्रदर्शन किया।
तब से, मैंने सोचा है कि कॉलमस्टोर इंडेक्स (क्लस्टर और गैर-क्लस्टर दोनों) इनमें से किसी भी परिदृश्य में मदद कर सकते हैं। टीएल; डॉ :अलगाव में इस प्रयोग के आधार पर, इस पोस्ट के शीर्षक का उत्तर एक शानदार नहीं है . यदि आप परीक्षण सेटअप, कोड, निष्पादन योजना या ग्राफ़ नहीं देखना चाहते हैं, तो बेझिझक मेरे सारांश पर जाएं, यह ध्यान में रखते हुए कि मेरा विश्लेषण बहुत विशिष्ट उपयोग के मामले पर आधारित है।
सेटअप
SQL सर्वर 2016 CTP 3.2 (13.0.900.73) के साथ एक नए VM पर, मैं पहले की तरह ही लगभग उसी सेटअप के माध्यम से चला, केवल इस बार तीन तालिकाओं के साथ। सबसे पहले, एक संकीर्ण क्लस्टरिंग कुंजी और एकाधिक सहायक अनुक्रमणिका वाली एक पारंपरिक तालिका:
टेबल बनाएं [डीबीओ]। [ग्राहक] ( [ग्राहक आईडी] [int] न्यूल नहीं, [फर्स्टनाम] [नवरचर] (64) न्यूल नहीं, [अंतिम नाम] [नवरचर] (64) न्यूल नहीं, [ईमेल] [ nvarchar](320) नॉट न्यूल यूनिक, [एक्टिव] [बिट] नॉट डिफॉल्ट 1, [बनाया गया] [डेटाटाइम] नॉट डिफॉल्ट सिस्डेटटाइम (), [अपडेटेड] [डेटटाइम] न्यूल, कॉन्स्ट्रेंट [पीके_कस्टमर] प्राथमिक कुंजी क्लस्टर ([ ग्राहक आईडी])); [dbo] पर गैर-अनुक्रमित सूचकांक [Active_Customers] बनाएं। [ग्राहक] ([प्रथम नाम], [अंतिम नाम], [ईमेल]) जहां ([सक्रिय] =1); -- "फ़ोनबुक" सॉर्टिंग का समर्थन करने के लिए (अंतिम, प्रथम द्वारा आदेश) गैर-अनुक्रमित अनुक्रमणिका बनाएं [फ़ोनबुक_ग्राहक] [डीबीओ] पर। [ग्राहक] ([अंतिम नाम], [प्रथम नाम]) शामिल करें ([ईमेल]);
इसके बाद, क्लस्टर्ड ColumnStore अनुक्रमणिका वाली एक तालिका:
टेबल बनाएं [डीबीओ]। nvarchar](320) नॉट न्यूल यूनीक, [एक्टिव] [बिट] नॉट डिफॉल्ट 1, [बनाया गया] [डेटाटाइम] नॉट डिफॉल्ट सिस्डेटटाइम (), [अपडेट किया गया] [डेटटाइम] न्यूल, कॉन्स्ट्रेंट [पीके_कस्टमरसीसीआई] प्राथमिक कुंजी नॉनक्लस्टर्ड ([ ग्राहक आईडी])); [dbo] पर क्लस्टर किए गए COLUMNSTORE INDEX [Customers_CCI] बनाएं।[Customers_CCI];
और अंत में, एक तालिका जिसमें एक गैर-संकुल ColumnStore अनुक्रमणिका है जिसमें सभी कॉलम शामिल हैं:
टेबल बनाएं [डीबीओ]। nvarchar](320) नॉट न्यूल यूनिक, [एक्टिव] [बिट] नॉट डिफॉल्ट 1, [बनाया गया] [डेटाटाइम] नॉट डिफॉल्ट सिस्डेटटाइम (), [अपडेट किया गया] [डेटटाइम] न्यूल, कॉन्स्ट्रेंट [पीके_कस्टमरएनसीसीआई] प्राथमिक कुंजी क्लस्टर ([ ग्राहक आईडी])); [dbo] पर गैर-क्लस्टर किए गए COLUMNSTORE INDEX [Customers_NCCI] बनाएं।ध्यान दें कि ColumnStore अनुक्रमणिका वाली दोनों तालिकाओं के लिए, मैंने उस अनुक्रमणिका को छोड़ दिया है जो "फ़ोनबुक" सॉर्ट (अंतिम नाम, प्रथम नाम) पर त्वरित खोज का समर्थन करेगी।
टेस्ट डेटा
मैंने तब पहली तालिका को 1,000,000 यादृच्छिक पंक्तियों के साथ पॉप्युलेट किया, एक स्क्रिप्ट के आधार पर जिसे मैंने पिछली पोस्ट से फिर से उपयोग किया है:
INSERT dbo.Customers with (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) rn चुनें =ROW_NUMBER() ओवर (ऑर्डर बाय n), fn, ln, em, aFROM ( सेलेक्ट टॉप (1000000) fn, ln, em, a =MAX(a), n =MAX(NEWID ()) से (चुनें fn, ln, em, a, r =ROW_NUMBER() ओवर (उन्हें ऑर्डर के अनुसार विभाजन) से (शीर्ष का चयन करें) (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT (c.name, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID) ())),3) + '.com', a =मामला जब c.name '%y%' की तरह हो तो 0 अन्य 1 sys.all_objects से समाप्त होता है जैसे कि sys.all_columns के रूप में sys.all_columns के रूप में NEWID द्वारा आदेश ()) एएस एक्स) एएस वाई जहां आर =1 ग्रुप बाय एफएन, एलएन, एम ऑर्डर बाय एन) एएस जेड ऑर्डर बाय आरएन;फिर मैंने उस तालिका का उपयोग अन्य दो को ठीक उसी डेटा के साथ पॉप्युलेट करने के लिए किया, और सभी इंडेक्स को फिर से बनाया:
INSERT dbo.Customers_CCI के साथ (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) Select CustomerID, FirstName, LastName, EMail, [Active]FROM dbo.Customers; INSERT dbo.Customers_NCCI के साथ (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) Select CustomerID, FirstName, LastName, EMail, [Active]FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD;ALTER INDEX ALL ON dbo.Customers_CCI REBUILD;ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;प्रत्येक तालिका का कुल आकार:
| टेबल | आरक्षित | डेटा | सूचकांक |
|---|---|---|---|
| ग्राहक | 463,200 केबी | 154,344 KB | 308,576 केबी |
| Customers_CCI | 117,280 केबी | 30,288 KB | 86,536 KB |
| Customers_NCCI | 349,480 केबी | 154,344 KB | 194,976 KB |
और प्रासंगिक अनुक्रमितों की पंक्ति गणना / पृष्ठ संख्या (ई-मेल पर अद्वितीय अनुक्रमणिका मेरे लिए किसी अन्य चीज़ की तुलना में अपनी स्वयं की डेटा पीढ़ी स्क्रिप्ट को बेबीसिट करने के लिए अधिक थी):
| टेबल | सूचकांक | पंक्तियाँ | पेज |
|---|---|---|---|
| ग्राहक | PK_ग्राहक | 1,000,000 | 19,377 |
| ग्राहक | फ़ोनबुक_ग्राहक | 1,000,000 | 17,209 |
| ग्राहक | Active_Customers | 808,012 | 13,977 |
| Customers_CCI | PK_CustomersCCI | 1,000,000 | 2,737 |
| Customers_CCI | Customers_CCI | 1,000,000 | 3,826 |
| Customers_NCCI | PK_CustomersNCCI | 1,000,000 | 19,377 |
| Customers_NCCI | ग्राहक_एनसीसीआई | 1,000,000 | 16,971 |
प्रक्रियाएं
फिर, यह देखने के लिए कि क्या कॉलमस्टोर इंडेक्स झपट्टा मारेंगे और किसी भी परिदृश्य को बेहतर बनाएंगे, मैंने पहले की तरह ही प्रश्नों का सेट चलाया, लेकिन अब तीनों तालिकाओं के खिलाफ। मैं कम से कम थोड़ा सा होशियार हो गया और टेबल स्रोत और सॉर्ट ऑर्डर को स्वीकार करने के लिए डायनामिक एसक्यूएल के साथ दो संग्रहीत प्रक्रियाएं बनाईं। (मैं एसक्यूएल इंजेक्शन के बारे में अच्छी तरह से जानता हूं; यह वह नहीं है जो मैं उत्पादन में करूँगा यदि ये तार एक अंतिम उपयोगकर्ता से आ रहे थे, तो कृपया इसे ऐसा करने की सिफारिश के रूप में न लें। मुझे अपने आप में पर्याप्त भरोसा है संलग्न वातावरण है कि यह इन परीक्षणों के लिए चिंता का विषय नहीं है।)
CREATE PROCEDURE dbo.P_Old @PageNumber INT =1, @PageSize INT =100, @Table SYSNAME, @Sort VARCHAR(32)ASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N' चयन ग्राहक आईडी, प्रथम नाम, अंतिम नाम, ईमेल, सक्रिय, बनाया गया, डीबीओ से अपडेट किया गया।' + QUOTENAME(@Table) + N' द्वारा 'ऑर्डर' + केस @ सॉर्ट करें जब 'कुंजी' तब N'CustomerID' जब 'फ़ोनबुक' फिर N'LastName, FirstName' जब 'असमर्थित' तब N'FirstName DESC, ईमेल' END + N' OFFSET @PageSize * (@PageNumber - 1) पंक्तियाँ फ़ेच अगला @PageSize ROWS केवल विकल्प (RECOMPILE);'; EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;ENDGO CREATE PROCEDURE dbo.P_CTE @PageNumber INT =1, @PageSize INT =100, @Table SYSNAME( @Sort VARCHAR) 32) ASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'; pg AS के साथ (dbo से कस्टमर आईडी चुनें।' + QUOTENAME(@Table) + N' ऑर्डर बाय '+ केस @ सॉर्ट करें जब 'की' तब N'CustomerID' जब 'फोनबुक' फिर N'LastName, FirstName' जब 'असमर्थित' तब N'FirstName DESC, EMail' END + N' OFFSET @PageSize * (@PageNumber-1) ROWS FETCH NEXT @PageSize ROWS केवल ) चुनें c.CustomerID, c.FirstName, c.LastName, c.EMail, c.Active, c.Created, c.dbo से अपडेट किया गया।' + QUOTENAME(@Table) + N' जहां पर मौजूद है (pg से 1 चुनें जहां pg.CustomerID =c.CustomerID) '+ केस @ सॉर्ट करें जब 'कुंजी' तब N'CustomerID' जब 'फ़ोनबुक' तब N' LastName, FirstName' जब 'असमर्थित' तब N'FirstName DESC, ईमेल' END + N' विकल्प (RECOMPILE);'; EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;ENDGO
फिर मैंने कॉल के सभी संयोजनों को उत्पन्न करने के लिए कुछ और गतिशील एसक्यूएल को चाबुक किया, जो मुझे पुरानी और नई संग्रहीत प्रक्रियाओं को कॉल करने के लिए, वांछित सॉर्ट ऑर्डर के तीनों में, और अलग-अलग पेज नंबरों पर (आवश्यकता का अनुकरण करने के लिए) करने की आवश्यकता होगी। क्रम के आरंभ, मध्य और अंत के निकट एक पृष्ठ)। ताकि मैं PRINT कॉपी कर सकूं आउटपुट और इसे रनटाइम मेट्रिक्स प्राप्त करने के लिए SQL सेंट्री प्लान एक्सप्लोरर में पेस्ट करें, मैंने इस बैच को दो बार चलाया, एक बार procedures के साथ P_Old . का उपयोग करते हुए CTE , और फिर P_CTE . का उपयोग करके फिर से ।
घोषणा @sql NVARCHAR(MAX) =N'';; [टेबल] (नाम) एएस के साथ (चयन एन 'ग्राहक' यूनियन सभी चयन एन 'ग्राहक_सीसीआई' यूनियन सभी चयन एन 'ग्राहक_एनसीसीआई'), प्रकार (सॉर्ट) एएस ('कुंजी' यूनियन सभी चुनें 'फोनबुक' यूनियन सभी चयन करें 'असमर्थित'), पेज (पेजनंबर) एएस (चुनें 1 यूनियन सभी चुनें 500 यूनियन सभी चुनें 5000 यूनियन सभी चुनें 9999), प्रक्रियाएं (नाम) एएस (चुनें एन'पी_सीटीई' - एन'पी_ओल्ड') @ एसक्यूएल + =चुनें एन 'EXEC डीबीओ।' + p.name + N' @Table =N' + CHAR(39) + t.name + CHAR(39) + N', @Sort =N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber =' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' टेबल से जैसे t CROSS JOIN सॉर्ट्स के रूप में s CROSS JOIN पेजों के रूप में pg CROSS JOIN प्रोसेस जैसे p ORDER BY t.name, s .सॉर्ट, पीजी.पेजनंबर; प्रिंट @sql;
इसने इस तरह उत्पादन किया (पुरानी विधि के लिए कुल 36 कॉल (P_Old .) ), और नई विधि के लिए 36 कॉल (P_CTE )):
EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Key', @PageNumber =1; EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Key', @PageNumber =500; EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Key', @PageNumber =5000; EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Key', @PageNumber =9999; EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'PhoneBook', @PageNumber =1; ... EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'PhoneBook', @PageNumber =9999; EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Unsupported', @PageNumber =1; ... EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Unsupported', @PageNumber =9999; EXEC dbo.P_CTE @Table =N'Customers_CCI', @Sort =N'Key', @PageNumber =1; ... EXEC dbo.P_CTE @Table =N'Customers_CCI', @Sort =N'असमर्थित', @PageNumber =9999; EXEC dbo.P_CTE @Table =N'Customers_NCCI', @Sort =N'Key', @PageNumber =1; ... EXEC dbo.P_CTE @Table =N'Customers_NCCI', @Sort =N'Unsupported', @PageNumber =9999;
मुझे पता है, यह सब बहुत बोझिल है; हम जल्द ही पंचलाइन पर पहुंच रहे हैं, मैं वादा करता हूं।
परिणाम
मैंने 36 कथनों के उन दो सेटों को लिया और प्लान एक्सप्लोरर में दो नए सत्र शुरू किए, प्रत्येक सेट को कई बार चलाने के लिए यह सुनिश्चित करने के लिए कि हम एक गर्म कैश से डेटा प्राप्त कर रहे थे और औसत ले रहे थे (मैं ठंडे और गर्म कैश की तुलना भी कर सकता था, लेकिन मुझे लगता है कि वहां हैं यहां पर्याप्त चर)।
मैं आपको समर्थन रेखांकन या योजना दिखाए बिना कुछ सरल तथ्य बता सकता हूं:
- किसी भी स्थिति में "पुरानी" पद्धति ने नई सीटीई पद्धति को मात नहीं दी मैंने अपनी पिछली पोस्ट में प्रचार किया था, चाहे किसी भी प्रकार के इंडेक्स मौजूद हों। ताकि कम से कम अवधि के संदर्भ में (जो एक मीट्रिक अंत उपयोगकर्ता सबसे अधिक परवाह करता है) परिणामों के आधे परिणामों को लगभग अनदेखा करना आसान बनाता है।
- परिणाम के अंत में पेजिंग करते समय किसी भी कॉलमस्टोर इंडेक्स ने अच्छा प्रदर्शन नहीं किया - उन्होंने केवल शुरुआत में ही लाभ प्रदान किया, और केवल कुछ मामलों में।
- प्राथमिक कुंजी के अनुसार क्रमित करते समय (क्लस्टर या नहीं), कॉलमस्टोर इंडेक्स की उपस्थिति ने मदद नहीं की - फिर से, अवधि के संदर्भ में।
उन सारांशों के साथ, आइए अवधि डेटा के कुछ क्रॉस-सेक्शन पर एक नज़र डालें। सबसे पहले, पहले नाम के क्रम में क्वेरी के परिणाम अवरोही, फिर ई-मेल, सॉर्टिंग के लिए मौजूदा इंडेक्स का उपयोग करने की कोई उम्मीद नहीं है। जैसा कि आप चार्ट में देख सकते हैं, प्रदर्शन असंगत था - निचले पृष्ठ संख्याओं पर, गैर-संकुलित ColumnStore ने सबसे अच्छा प्रदर्शन किया; उच्च पृष्ठ संख्या पर, पारंपरिक सूचकांक हमेशा जीता:
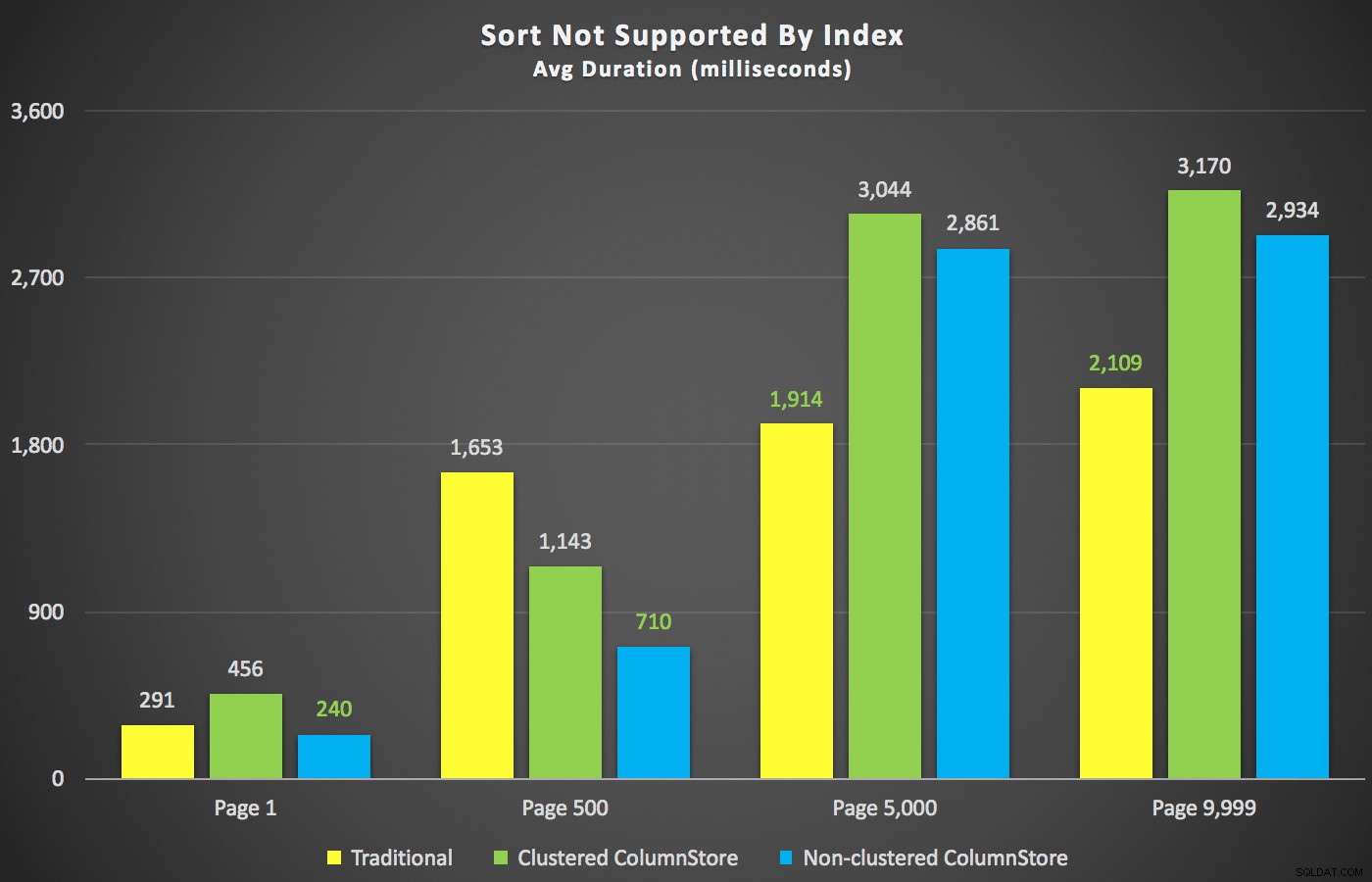 विभिन्न पेज नंबरों और विभिन्न इंडेक्स प्रकारों के लिए अवधि (मिलीसेकंड)
विभिन्न पेज नंबरों और विभिन्न इंडेक्स प्रकारों के लिए अवधि (मिलीसेकंड)
और फिर तीन अलग-अलग प्रकार के इंडेक्स का प्रतिनिधित्व करने वाली तीन योजनाएं (योजनाओं के बीच प्रमुख अंतर को उजागर करने के लिए फ़ोटोशॉप द्वारा जोड़े गए ग्रेस्केल के साथ):
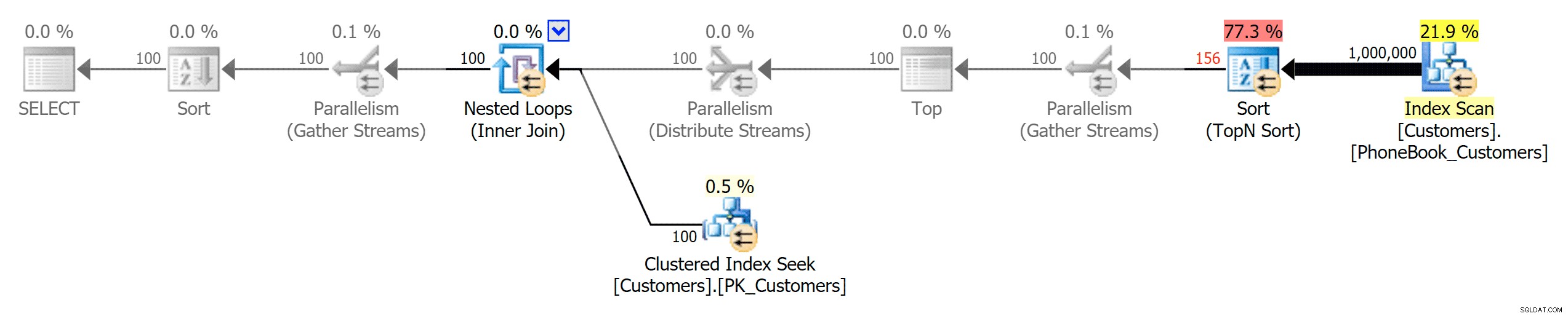 पारंपरिक अनुक्रमणिका की योजना
पारंपरिक अनुक्रमणिका की योजना
 क्लस्टर कॉलमस्टोर इंडेक्स के लिए योजना
क्लस्टर कॉलमस्टोर इंडेक्स के लिए योजना
 गैर-संकुल ColumnStore अनुक्रमणिका के लिए योजना
गैर-संकुल ColumnStore अनुक्रमणिका के लिए योजना
परीक्षण शुरू करने से पहले भी, एक परिदृश्य जिसमें मुझे अधिक दिलचस्पी थी, वह था फोन बुक सॉर्टिंग दृष्टिकोण (अंतिम नाम, पहला नाम)। इस मामले में कॉलमस्टोर इंडेक्स वास्तव में परिणाम के प्रदर्शन के लिए काफी हानिकारक थे:
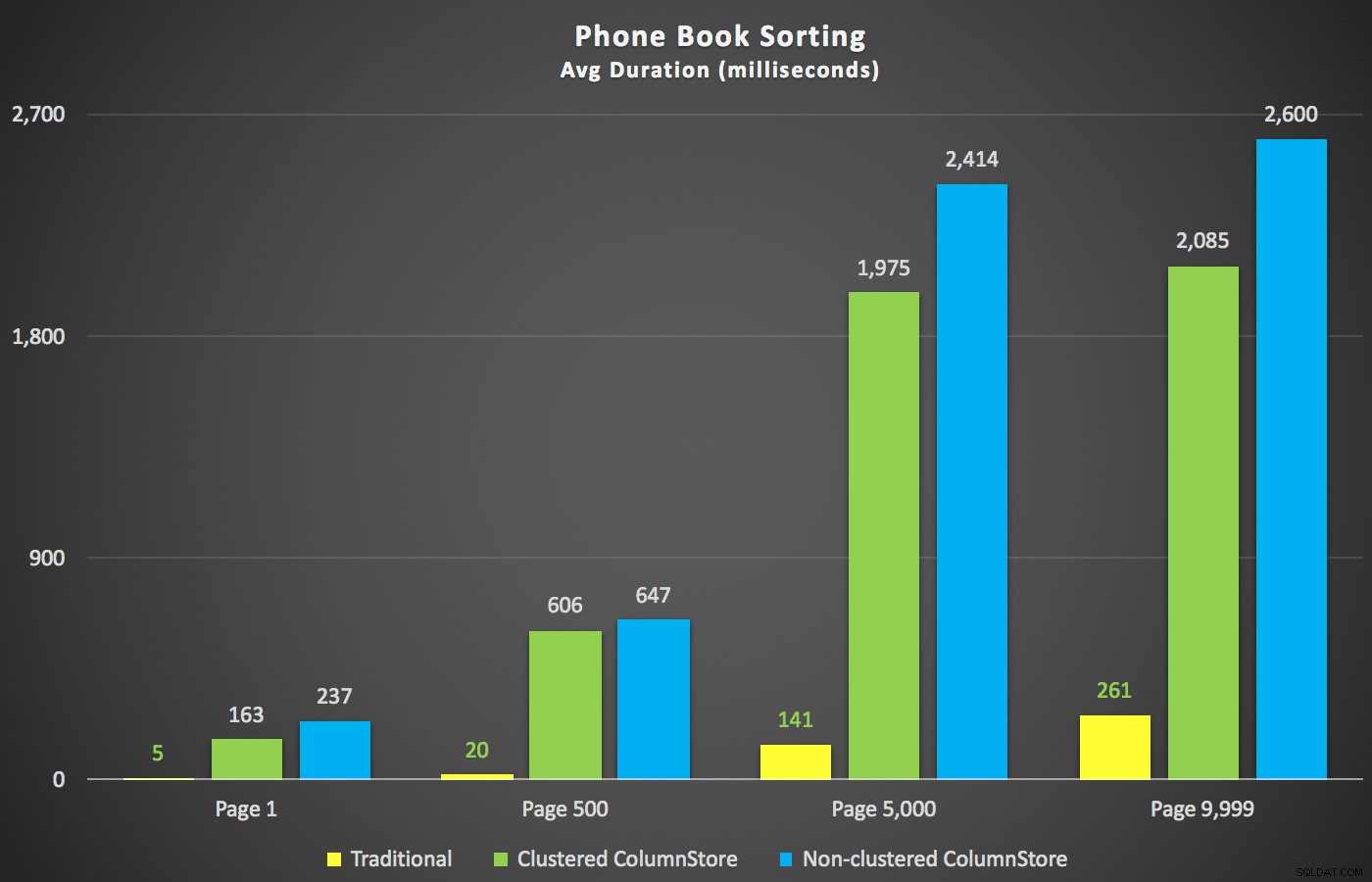
यहाँ ColumnStore योजनाएँ असमर्थित सॉर्ट के लिए ऊपर दिखाए गए दो ColumnStore प्लान के मिरर इमेज के पास हैं। दोनों ही मामलों में कारण एक ही है:सॉर्ट-सपोर्टिंग इंडेक्स की कमी के कारण महंगे स्कैन या सॉर्ट।
तो आगे, मैंने कॉलमस्टोर इंडेक्स के साथ टेबल पर "फोनबुक" इंडेक्स का समर्थन किया, यह देखने के लिए कि क्या मैं उन परिदृश्यों में से किसी एक में एक अलग योजना और/या तेज़ निष्पादन समय को जोड़ सकता हूं। मैंने ये दो इंडेक्स बनाए, फिर दोबारा बनाए:
[dbo] परअसंबद्ध अनुक्रमणिका [PhoneBook_CustomersCCI] बनाएं।[Customers_CCI]([LastName],[FirstName])INCLUDE ([ईमेल]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; [dbo] पर गैर-अनुक्रमित सूचकांक [PhoneBook_CustomersNCCI] बनाएं। [Customers_NCCI]([LastName],[FirstName])INCLUDE ([ईमेल]); ऑल्टर इंडेक्स ऑल ऑन dbo.Customers_NCCI REBUILD;
ये रही नई अवधियां:
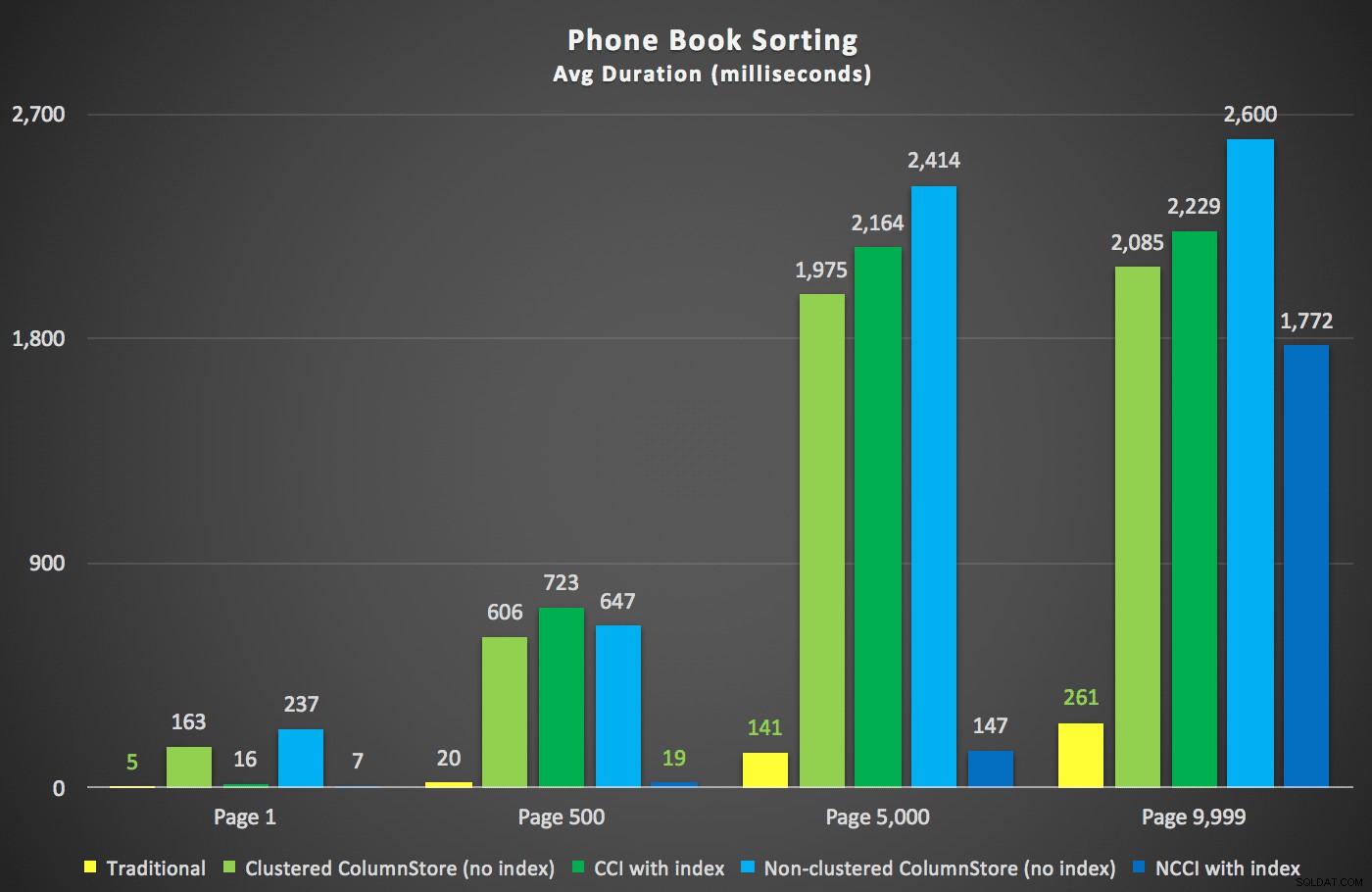
यहां सबसे दिलचस्प बात यह है कि अब गैर-क्लस्टर वाले कॉलमस्टोर इंडेक्स वाली टेबल के खिलाफ पेजिंग क्वेरी पारंपरिक इंडेक्स के साथ तालमेल बिठा रही है, जब तक कि हम टेबल के बीच से आगे नहीं निकल जाते। योजनाओं को देखते हुए, हम देख सकते हैं कि 5,000 पृष्ठ पर, एक पारंपरिक इंडेक्स स्कैन का उपयोग किया जाता है, और कॉलमस्टोर इंडेक्स को पूरी तरह से नजरअंदाज कर दिया जाता है:
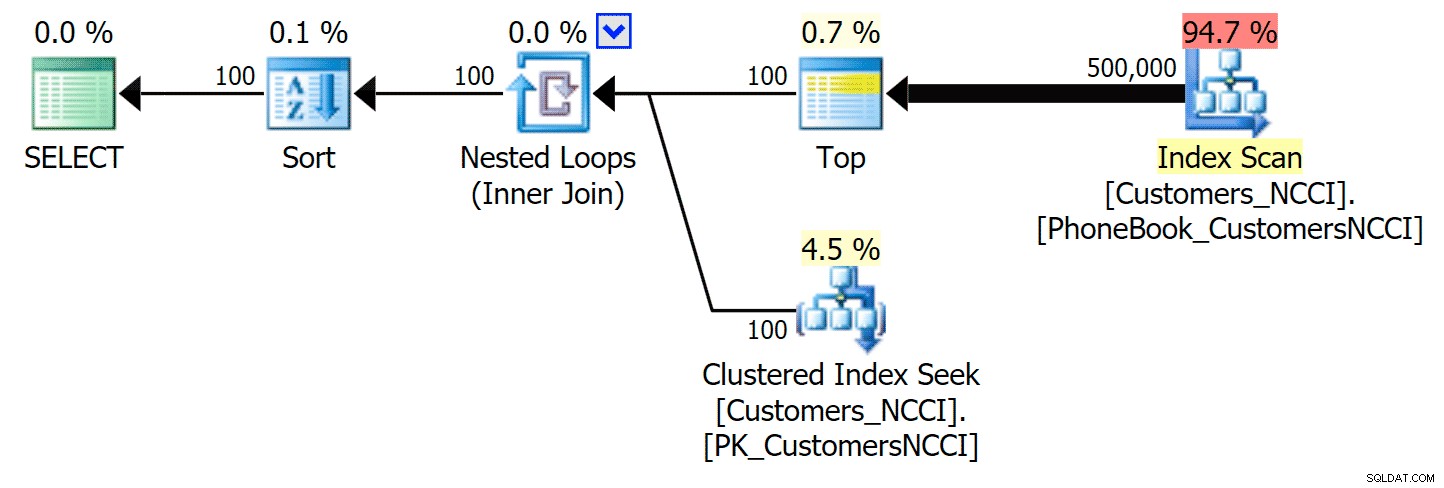 गैर-संकुल ColumnStore अनुक्रमणिका को अनदेखा करते हुए फ़ोन बुक योजना
गैर-संकुल ColumnStore अनुक्रमणिका को अनदेखा करते हुए फ़ोन बुक योजना
लेकिन 5,000 पृष्ठों के मध्य-बिंदु और 9,999 पृष्ठों पर तालिका के "अंत" के बीच, ऑप्टिमाइज़र ने एक प्रकार का टिपिंग पॉइंट मारा है और - ठीक उसी क्वेरी के लिए - अब गैर-क्लस्टर किए गए कॉलमस्टोर इंडेक्स को स्कैन करना चुन रहा है। :
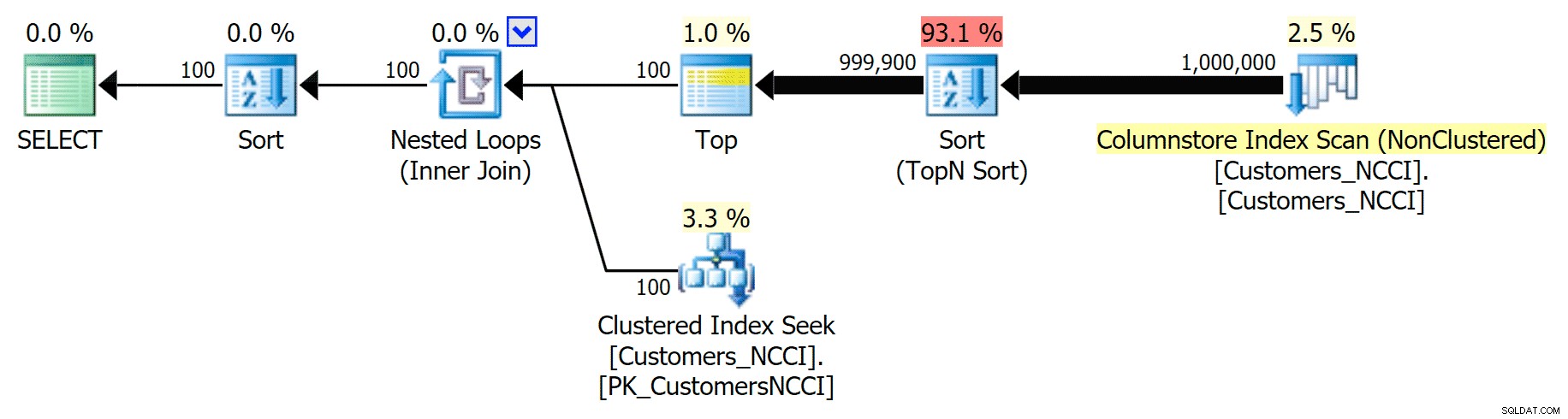 फोन बुक प्लान 'टिप्स' और कॉलमस्टोर इंडेक्स का उपयोग करता है
फोन बुक प्लान 'टिप्स' और कॉलमस्टोर इंडेक्स का उपयोग करता है
यह ऑप्टिमाइज़र द्वारा एक बहुत अच्छा निर्णय नहीं है, मुख्य रूप से सॉर्ट ऑपरेशन की लागत के कारण। यदि आप नियमित सूचकांक का संकेत देते हैं तो आप देख सकते हैं कि अवधि कितनी बेहतर हो जाती है:
--...;पीजी एएस के साथ (डीबीओ से ग्राहक आईडी चुनें। @PageSize ROWS केवल )--...
यह निम्नलिखित योजना देता है, लगभग ऊपर की पहली योजना के समान (स्कैन के लिए थोड़ी अधिक लागत, हालांकि, केवल इसलिए कि अधिक आउटपुट है):
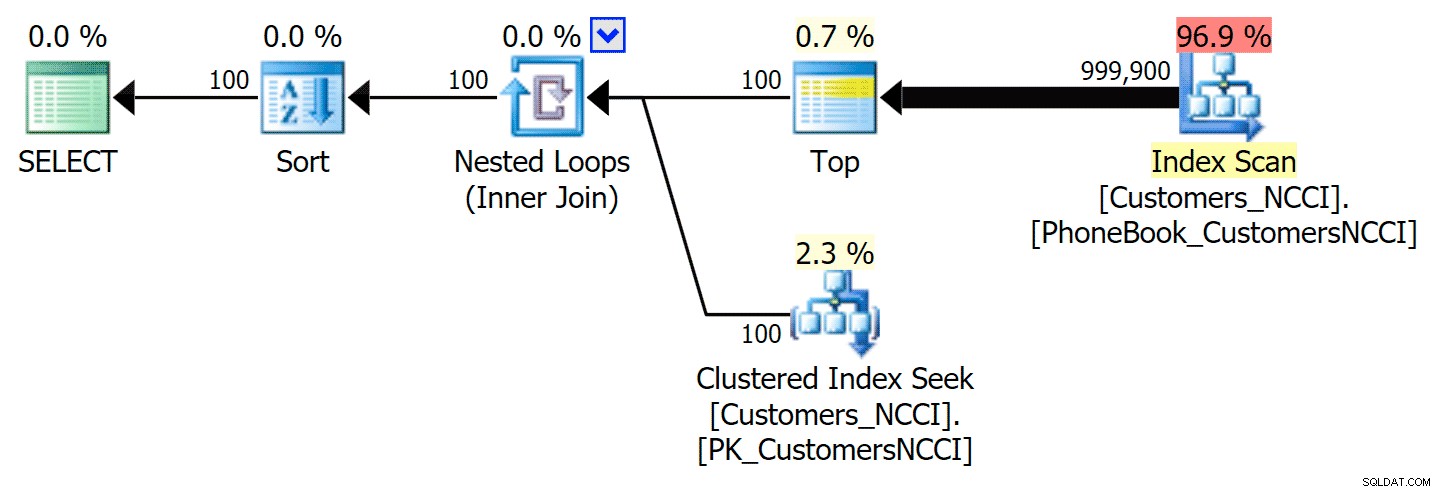 संकेतित अनुक्रमणिका के साथ फोन बुक योजना
संकेतित अनुक्रमणिका के साथ फोन बुक योजना
आप इसे OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) का उपयोग करके प्राप्त कर सकते हैं स्पष्ट सूचकांक संकेत के बजाय। बस इस बात का ध्यान रखें कि यह वही है जो वहां कॉलमस्टोर इंडेक्स को पहले स्थान पर नहीं रखता है।
निष्कर्ष
जबकि ऊपर कुछ किनारे के मामले हैं जहां एक कॉलमस्टोर इंडेक्स (मुश्किल से) भुगतान कर सकता है, मुझे ऐसा नहीं लगता है कि वे इस विशिष्ट पेजिनेशन परिदृश्य के लिए उपयुक्त हैं। मुझे लगता है, सबसे महत्वपूर्ण बात, जबकि कॉलमस्टोर संपीड़न के कारण महत्वपूर्ण स्थान बचत प्रदर्शित करता है, क्रम की आवश्यकताओं के कारण रनटाइम प्रदर्शन शानदार नहीं है (भले ही इन प्रकारों को बैच मोड में चलाने का अनुमान है, SQL सर्वर 2016 के लिए एक नया अनुकूलन)।
सामान्य तौर पर, यह अनुसंधान और परीक्षण पर खर्च किए गए बहुत अधिक समय के साथ कर सकता है; पिछले लेखों के गुल्लक में, मैं जितना संभव हो उतना कम बदलना चाहता था। उदाहरण के लिए, मुझे उस टिपिंग पॉइंट को ढूंढना अच्छा लगेगा, और मैं यह भी स्वीकार करना चाहता हूं कि ये बिल्कुल बड़े पैमाने पर परीक्षण नहीं हैं (वीएम आकार और मेमोरी सीमाओं के कारण), और मैंने आपको बहुत कुछ अनुमान लगाया है रनटाइम मेट्रिक्स (ज्यादातर संक्षिप्तता के लिए, लेकिन मुझे नहीं पता कि पढ़ने का एक चार्ट जो हमेशा अवधि के लिए आनुपातिक नहीं होता है, वास्तव में आपको बताएगा)। ये परीक्षण एसएसडी की विलासिता, पर्याप्त मेमोरी, हमेशा गर्म कैश और एकल-उपयोगकर्ता वातावरण को भी मानते हैं। मैं वास्तव में अधिक डेटा के खिलाफ परीक्षणों की एक बड़ी बैटरी करना चाहता हूं, धीमी डिस्क वाले बड़े सर्वर पर और कम मेमोरी वाले इंस्टेंस पर, हर समय सिम्युलेटेड कंसीडर के साथ।
उस ने कहा, यह केवल एक परिदृश्य भी हो सकता है कि कॉलमस्टोर को पहली जगह में हल करने में मदद के लिए डिज़ाइन नहीं किया गया है, क्योंकि पारंपरिक इंडेक्स के साथ अंतर्निहित समाधान पंक्तियों के एक संकीर्ण सेट को खींचने में पहले से ही काफी कुशल है - कॉलमस्टोर का व्हीलहाउस बिल्कुल नहीं। शायद मैट्रिक्स में जोड़ने के लिए एक और चर पृष्ठ आकार है - ऊपर के सभी परीक्षण एक बार में 100 पंक्तियों को खींचते हैं, लेकिन क्या होगा यदि हम एक बार में 10,000 या 100,000 पंक्तियों के बाद हों, भले ही अंतर्निहित तालिका कितनी बड़ी हो?
क्या आपके पास ऐसी स्थिति है जहां आपके OLTP कार्यभार में केवल ColumnStore अनुक्रमणिका को जोड़कर सुधार किया गया था? मुझे पता है कि वे डेटा वेयरहाउस-शैली के वर्कलोड के लिए डिज़ाइन किए गए हैं, लेकिन अगर आपने कहीं और लाभ देखा है, तो मुझे आपके परिदृश्य के बारे में सुनना और यह देखना अच्छा लगेगा कि क्या मैं अपने परीक्षण रिग में कोई विभेदक शामिल कर सकता हूं।