इस महीने की शुरुआत में, मैंने कुछ ऐसी युक्ति प्रकाशित की जो हम शायद चाहते हैं कि हमें न करना पड़े:सीमांकित स्ट्रिंग्स से डुप्लीकेट को छाँटना या हटाना, आमतौर पर उपयोगकर्ता-परिभाषित फ़ंक्शंस (UDFs) को शामिल करना। कभी-कभी आपको वर्णानुक्रम में सूची (डुप्लिकेट के बिना) को फिर से इकट्ठा करने की आवश्यकता होती है, और कभी-कभी आपको मूल क्रम बनाए रखने की आवश्यकता हो सकती है (उदाहरण के लिए, यह खराब अनुक्रमणिका में कुंजी कॉलम की सूची हो सकती है)।
मेरे समाधान के लिए, जो दोनों परिदृश्यों को संबोधित करता है, मैंने उपयोगकर्ता-परिभाषित कार्यों (यूडीएफ) की एक जोड़ी के साथ एक संख्या तालिका का उपयोग किया - एक स्ट्रिंग को विभाजित करने के लिए, दूसरा इसे फिर से इकट्ठा करने के लिए। आप उस टिप को यहां देख सकते हैं:
- एसक्यूएल सर्वर में स्ट्रिंग्स से डुप्लीकेट हटाना
बेशक, इस समस्या को हल करने के कई तरीके हैं; यदि आप उस संरचना डेटा के साथ फंस गए हैं तो मैं केवल एक विधि प्रदान कर रहा था। रेड-गेट के @Phil_Factor ने अपना दृष्टिकोण दिखाते हुए एक त्वरित पोस्ट के साथ पीछा किया, जो इनलाइन एक्सएमएल हेरफेर के बजाय कार्यों और संख्या तालिका से बचा जाता है। उनका कहना है कि वह सिंगल-स्टेटमेंट क्वेश्चन रखना पसंद करते हैं और फंक्शन और रो-बाय-रो प्रोसेसिंग दोनों से बचते हैं:
- एसक्यूएल सर्वर में डी-डुप्लिकेटिंग सीमांकित सूचियां
फिर एक पाठक, स्टीव मंगियामेली ने टिप पर एक टिप्पणी के रूप में एक लूपिंग समाधान पोस्ट किया। उनका तर्क यह था कि संख्या तालिका का उपयोग उन्हें अति-अभिनीत लग रहा था।
हम तीनों इसके एक पहलू को संबोधित करने में विफल रहे जो आमतौर पर काफी महत्वपूर्ण होने वाला है यदि आप कार्य को अक्सर पर्याप्त या किसी भी स्तर पर कर रहे हैं:प्रदर्शन ।
परीक्षण
यह देखने के लिए उत्सुक है कि मेरे नंबर टेबल-आधारित समाधान की तुलना में इनलाइन एक्सएमएल और लूपिंग दृष्टिकोण कितना अच्छा प्रदर्शन करेंगे, मैंने कुछ परीक्षण करने के लिए एक कल्पित तालिका का निर्माण किया; मेरा लक्ष्य 5,000 पंक्तियों का था, जिसमें 250 वर्णों से अधिक की औसत स्ट्रिंग लंबाई और प्रत्येक स्ट्रिंग में कम से कम 10 तत्व थे। प्रयोगों के एक बहुत ही छोटे चक्र के साथ, मैं निम्नलिखित कोड के साथ इसके बहुत करीब कुछ हासिल करने में सक्षम था:
टेबल डीबीओ बनाएं। सोर्सटेबल ([रोआईडी] इंट पहचान (1,1) प्राथमिक कुंजी क्लस्टर, डिलिमिटेडस्ट्रिंग वर्कर (8000)); जाओ; एस (एस) एएस के साथ (शीर्ष चुनें (250) ओ.नाम + जगह चुनें ( REPLACE(REPLACE(REPLACE(REPLACE((Select N'/column_' + c.name from sys.all_columns as c जहां c.[object_id] =o.[object_id] ऑर्डर बाय NEWID() फॉर एक्सएमएल पाथ(एन'')) , TYPE).value(N'.[1]', N'nvarchar(max)' ), -- 5 सबसे आम कॉलम नामों का उपयोग करके नकली डुप्लिकेट बनाएं:N'/column_name/', N'/name/name/foo /name/name/id/name/'), N'/column_status/', N'/id/status/blat/status/foo/status/name/'), N'/column_type/', N'/type /id/name/type/id/name/status/id/type/'), N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'), N'/column_pdw_node_id/ ', N'/pdw_node_id/name/pdw_node_id/name/type/name/') sys.all_objects से जहां मौजूद है (जहां sys.all_columns से 1 चुनें जहां c.[object_id] =o.[object_id]) ऑर्डर NEWID () द्वारा) INSERT dbo.SourceTable (DelimitedString) SE LECT s FROM s;GO 20
इसने इस तरह दिखने वाली नमूना पंक्तियों वाली एक तालिका तैयार की (मानों को छोटा कर दिया गया):
RowID DelimitedString-------------------------- मास्टर_फाइल्स/column_redo_target_fork_guid/.../column_differential_base_lsn/...2 आबंटन_यूनिट्स/कॉलम_यूज्ड_पेज/.../column_data_space_id/ टाइप/आईडी/नाम/प्रकार/...3 विदेशी_की_कॉलम/कॉलम_पैरेंट_ऑब्जेक्ट_आईडी/column_constraint_object_id/...
समग्र रूप से डेटा में निम्न प्रोफ़ाइल थी, जो किसी भी संभावित प्रदर्शन समस्याओं को उजागर करने के लिए पर्याप्त होनी चाहिए:
; सीटीई के साथ ([लंबाई], एलिमेंटकाउंट) एएस (चुनें 1.0*LEN(DelimitedString), 1.0*LEN(REPLACE(DelimitedString,'/','')) from dbo.SourceTable) सेलेक्ट row_count =COUNT(* ), avg_size =AVG([Length]), max_size =MAX([Length]), avg_elements =AVG(1 + [Length]-[ElementCount]), sum_elements =SUM(1 + [Length]-[ElementCount])FROM सीटीई; EXEC sys.sp_spaceused N'dbo.SourceTable'; /* परिणाम (संख्याएं थोड़ी भिन्न हो सकती हैं, SQL सर्वर संस्करण के आधार पर उपयोगकर्ता आपके डेटाबेस में ऑब्जेक्ट करता है):row_count avg_size max_size avg_elements sum_elements------------------------ ----------------------------5000 299.559000 2905.0 17.6650000 88250.0 आरक्षित डेटा अनुक्रमणिका_आकार अप्रयुक्त--------------- ------------ ------1672 केबी 1648 केबी 16 केबी 8 केबी*/
ध्यान दें कि मैंने varchar . पर स्विच किया है यहां nvarchar . से मूल लेख में, क्योंकि फिल और स्टीव द्वारा आपूर्ति किए गए नमूने varchar . मान लिए गए थे , केवल 255 या 8000 वर्णों पर कैपिंग, एकल-वर्ण सीमांकक, आदि। मैंने अपना पाठ कठिन तरीके से सीखा है, कि यदि आप किसी के कार्य को लेने जा रहे हैं और इसे प्रदर्शन तुलनाओं में शामिल करते हैं, तो आप जितना कम बदल सकते हैं संभव - आदर्श रूप से कुछ भी नहीं। हकीकत में मैं हमेशा nvarchar . का उपयोग करता हूं और संभव सबसे लंबी स्ट्रिंग के बारे में कुछ भी न मानें। इस मामले में मुझे पता था कि मैं कोई डेटा नहीं खो रहा था क्योंकि सबसे लंबी स्ट्रिंग केवल 2,905 वर्ण है, और इस डेटाबेस में मेरे पास यूनिकोड वर्णों का उपयोग करने वाली कोई तालिका या कॉलम नहीं है।
इसके बाद, मैंने अपने कार्यों को बनाया (जिसके लिए संख्या तालिका की आवश्यकता होती है)। एक पाठक ने मेरी टिप में फ़ंक्शन में एक समस्या देखी, जहां मैंने मान लिया था कि सीमांकक हमेशा एक ही वर्ण होगा, और इसे यहां ठीक किया। मैंने लगभग हर चीज को varchar(8000) . में बदल दिया है स्ट्रिंग प्रकार और लंबाई के संदर्भ में खेल के मैदान को समतल करने के लिए।
घोषणा @UpperLimit INT =1000000;;एन(आरएन) एएस के साथ (सेलेक्ट ROW_NUMBER() ओवर (एस1 द्वारा ऑर्डर करें। @ऊपरी सीमा; डीबीओ पर अद्वितीय क्लस्टर इंडेक्स बनाएं। संख्याएं ([संख्या]); फ़ंक्शन बनाएं [डीबीओ] जाएं। [स्प्लिटस्ट्रिंग] - इनलाइन टीवीएफ ( @ लिस्ट वर्कर (8000), @ डेलीम वर्कर (32)) स्कीमबिंडिंग रिटर्न के साथ रिटर्न टेबल (चयन करें) rn, vn =ROW_NUMBER() ओवर (पार्टिशन बाय [वैल्यू] ऑर्डर बाय आरएन), [वैल्यू] से (सेलेक्ट आरएन =ROW_NUMBER () ओवर (ऑर्डर बाय CHARINDEX(@Delim, @List + @Delim)), [वैल्यू] =एलटीआरआईएम (आरटीआरआईएम (सबस्ट्रिंग (@ सूची, [संख्या], चारिंडेक्स (@ डेलीम, @ सूची + @ डेलीम, [संख्या]) - [संख्या]))) डीबीओ से। नंबर जहां संख्या <=लेन(@सूची) और सबस्ट्रिंग (@Delim + @List, [Number], LEN(@Delim)) =@Delim) AS x); GO CREATE FUNCTION [dbo]। varchar(32), @Sort varchar(32)) SCHEMABINDINGASBEGIN RETURN के साथ varchar (8000) लौटाता है (नव चुनें =STUFF ((चुनें @Delim + x। [मान] dbo.SplitString (@List, @Delim) से x जहां के रूप में) (x.vn =1) -- डुप्लिकेट को फ़िल्टर करें केस द्वारा ऑर्डर करें @Sort जब 'मूल ऑर्डर' तब कन्वर्ट (int, x.rn) जब 'वर्णमाला' तब कन्वर्ट (varchar (8000), x. [Value]) ELSE CONVERT (SQL_VARIANT, NULL) एक्सएमएल पथ के लिए समाप्त ('' ), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'') );ENDGO इसके बाद, मैंने एक एकल, इनलाइन तालिका-मूल्यवान फ़ंक्शन बनाया जो उपरोक्त दो कार्यों को जोड़ता है, जो अब मैं चाहता हूं कि मैंने मूल लेख में किया था, ताकि स्केलर फ़ंक्शन से पूरी तरह से बचा जा सके। (जबकि सच है कि सभी . नहीं स्केलर फ़ंक्शंस बड़े पैमाने पर भयानक हैं, बहुत कम अपवाद हैं।)
क्रिएट फंक्शन [डीबीओ]। [रीबिल्डस्ट्रिंग] (@ लिस्ट वर्कर (8000), @ डेलीम वर्कर (32), @ सॉर्ट वर्कर (32)) स्कीमिंग रिटर्न के साथ रिटर्न टेबल (चुनें [आउटपुट] =स्टफ ((चुनें @Delim) + x। [मान] से (चयन आरएन, [मान], वीएन =ROW_NUMBER () ओवर (आरएन द्वारा आदेश [मूल्य] आदेश द्वारा) से ( चयन आरएन =ROW_NUMBER () ओवर (CHARINDEX द्वारा आदेश(@Delim, @List) + @Delim)), [मान] =LTRIM(RTRIM(SUBSTRING(@List, [Number], CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number]))) से dbo.Numbers WHERE नंबर <=LEN(@List) और सबस्ट्रिंग(@Delim+@List, [Number], LEN(@Delim)) =@Delim) AS y) AS x WHERE (x.vn =1) केस द्वारा ऑर्डर करें @Sort WHEN 'OriginalOrder' तब CONVERT(int, x.rn) जब 'Alphabetical' तब CONVERT(varchar(8000), x.[Value]) ELSE CONVERT(sql_variant, NULL) END for XML PATH(''), TYPE).value (N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'') );GO
मैंने इनलाइन TVF के अलग-अलग संस्करण भी बनाए हैं जो कि CASE की अस्थिरता से बचने के लिए दो सॉर्टिंग विकल्पों में से प्रत्येक के लिए समर्पित थे। अभिव्यक्ति, लेकिन यह बिल्कुल भी नाटकीय प्रभाव नहीं पड़ा।
फिर मैंने स्टीव के दो फंक्शन बनाए:
क्रिएट फंक्शन [डीबीओ]। startPos INT =0, @strLen INT =0 जबकि LEN(@strToPars)>=@startPos BEGIN IF (चुनें CHARINDEX(@parseChar,@strToPars,(@startPos+1)))> @startPos SELECT @strLen =CHARINDEX(@ parseChar,@strToPars,(@startPos+1)) - @startPos ELSE BEGIN SET @strLen =LEN(@strToPars) - (@startPos -1) INSERT @parsedIDs SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @) strLen))) ब्रेक एंड सेलेक्ट @strLen =CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos INSERT @parsedIDs SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen))) SET @startPos =@startPos+@strLen+1 ENDRETURNEND GO CREATE FUNCTION [dbo]। वापसी nvarchar, लेकिन मैं इसे नहीं छू रहा हूँ रिटर्न NVARCHAR (MAX) ASBEGIN DECLARE @ tblStr2Tbl तालिका (ParsedValue VARCHAR (255), स्थिति आईडी INT); DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), positionID INT); INSERT @ tblStr2Tbl DISTINCT ParsedValue चुनें, dbo.gfn_ParseList से स्थिति आईडी (@dupeStr,@strDelimiter); cteUniqueValues के साथ (@tblStr2Tbl से DISTINCT पार्स किए गए मान का चयन करें) INSERT @tblDeDupeMe चुनें d.ParsedValue , CASE @maintainOrder जब 1 तब MIN (d.PositionID) ELSE ROW_NUMBER () से अधिक (ParusedValue ASID) ROM मान। @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue GROUP द्वारा d.ParsedValue ऑर्डर द्वारा d.ParsedValue DECLARE @valCount INT, @curValue VARCHAR(255) ='', @posValue INT=0 , @dedupedStr VARCHAR(4000)=' '; @tblDeDupeMe से @valCount =COUNT(1) चुनें; जबकि @valCount> 0 प्रारंभ करें @posValue=a.minPos, @curValue=d.ParsedValue FROM (चुनें MIN(PositionID) minPos @tblDeDupeMe से जहां स्थिति आईडी> @posValue) एक जॉइन @tblDeDupeMe d ON d.PositionID=a.minPos; सेट @dedupedStr+=@curValue; सेट @ वैलकाउंट- =1; IF @valCount> 0 SET @dedupedStr+='/'; END RETURN @dedupedStr;ENDGO
फिर मैंने फिल के सीधे प्रश्नों को अपने परीक्षण रिग में डाल दिया (ध्यान दें कि उनके प्रश्न < . को एन्कोड करते हैं < . के रूप में उन्हें XML पार्सिंग त्रुटियों से बचाने के लिए, लेकिन वे > . को एन्कोड नहीं करते हैं या & - मैंने प्लेसहोल्डर जोड़े हैं यदि आपको उन स्ट्रिंग्स से बचाव करने की आवश्यकता है जिनमें संभावित रूप से वे समस्याग्रस्त वर्ण हो सकते हैं):
-- मूल आदेश को बनाए रखने के लिए फिल की क्वेरी चुनें /*फिर से इकट्ठा की गई सूची*/ सामान ((चुनें '/'+ TheValue FROM (सेलेक्ट x.y.value('.','varchar(20)') AS Thevalue, row_number() ओवर (ऑर्डर बाय (सिलेक्ट 1)) XMLList.nodes से ऑर्डर के रूप में ('/list/i/text()') AS x (y)) नोड्स (Thevalue, TheOrder) ग्रुप बाय द वैल्यू ऑर्डर बाय मिनट (TheOrder) ) XML PATH('') ),1,1,'') के लिए DeduplicatedFROM के रूप में (/*मूल सूची का XML संस्करण*/ Select Convert(XML,'' --+replace(replace) +replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&'),'/','')+'
') FROM (dbo.SourceTable से DelimitedString का चयन करें)XMLlist(AsciiList))सूचियां(XMLlist); - अल्फा सेलेक्ट स्टफ के लिए फिल की क्वेरी ((चुनें DISTINCT '/'+x.y.value('.','varchar(20)') XMLList.nodes('/list/i/text()') AS x ( y से) ) एक्सएमएल पाथ ('')), 1,1,'') से डीडुप्लिकेट के रूप में (सेलेक्ट कन्वर्ट (एक्सएमएल,'<सूची> ' --+replace(replace(+replace(replace(ASCIIList,'<)) ','<') --,'>','>'),'&','&') ,'/','')+' से चुनें
परीक्षण रिग मूल रूप से वे दो प्रश्न थे, और निम्नलिखित फ़ंक्शन कॉल भी थे। एक बार जब मैंने पुष्टि कर दी कि वे सभी एक ही डेटा लौटाते हैं, तो मैंने स्क्रिप्ट को DATEDIFF के साथ जोड़ दिया आउटपुट और इसे एक टेबल पर लॉग किया:
-- मूल क्रम बनाए रखें -- मूल लेख से मेरी UDF/TVF जोड़ी चुनें UDF_Original =dbo.ReaassemblyString(DelimitedString, '/', 'OriginalOrder') from dbo.SourceTable ORDER by RowID; - मेरी इनलाइन टीवीएफ मूल लेख पर आधारित टीवीएफ_ओरिजिनल =एफ चुनें। -- स्टीव की UDF/TVF जोड़ी:चुनें स्टीव_ऑरिजिनल =dbo.ufn_DedupeString(DelimitedString, '/', 1) dbo.SourceTable से; - ऊपर से फिल की पहली क्वेरी - वर्णानुक्रम में फिर से इकट्ठा करें - मूल लेख से मेरी UDF/TVF जोड़ी चुनें UDF_Alpha =dbo.ReaassemblyString(DelimitedString, '/', 'Alphabetical') from dbo.SourceTable ORDER BY RowID; - मूल लेख पर आधारित मेरा इनलाइन टीवीएफ चुनें टीवीएफ_अल्फा =एफ। [आउटपुट] डीबीओ से। सोर्सटेबल एएस टी क्रॉस एप्लाई डीबीओ। रीबिल्डस्ट्रिंग (टी। डिलीमिटेडस्ट्रिंग, '/', 'अल्फाबेटिकल') एएस एफ ऑर्डर बाय टी। रोआईडी; -- स्टीव की UDF/TVF जोड़ी:चुनें स्टीव_अल्फा =dbo.ufn_DedupeString(DelimitedString, '/', 0) dbo.SourceTable से; -- ऊपर से फिल की दूसरी क्वेरी
और फिर मैंने दो अलग-अलग प्रणालियों (8GB के साथ एक क्वाड कोर, और 32GB के साथ एक 8-कोर VM) पर प्रदर्शन परीक्षण चलाया, और प्रत्येक मामले में, SQL Server 2012 और SQL Server 2016 CTP 3.2 (13.0.900.73) दोनों पर।
परिणाम
मेरे द्वारा देखे गए परिणामों को निम्नलिखित चार्ट में संक्षेपित किया गया है, जो प्रत्येक प्रकार की क्वेरी के मिलीसेकंड में अवधि, वर्णानुक्रम और मूल क्रम पर औसत, चार सर्वर/संस्करण संयोजन, और प्रत्येक क्रमपरिवर्तन के लिए 15 निष्पादन की एक श्रृंखला दिखाता है। बड़ा करने के लिए क्लिक करें:
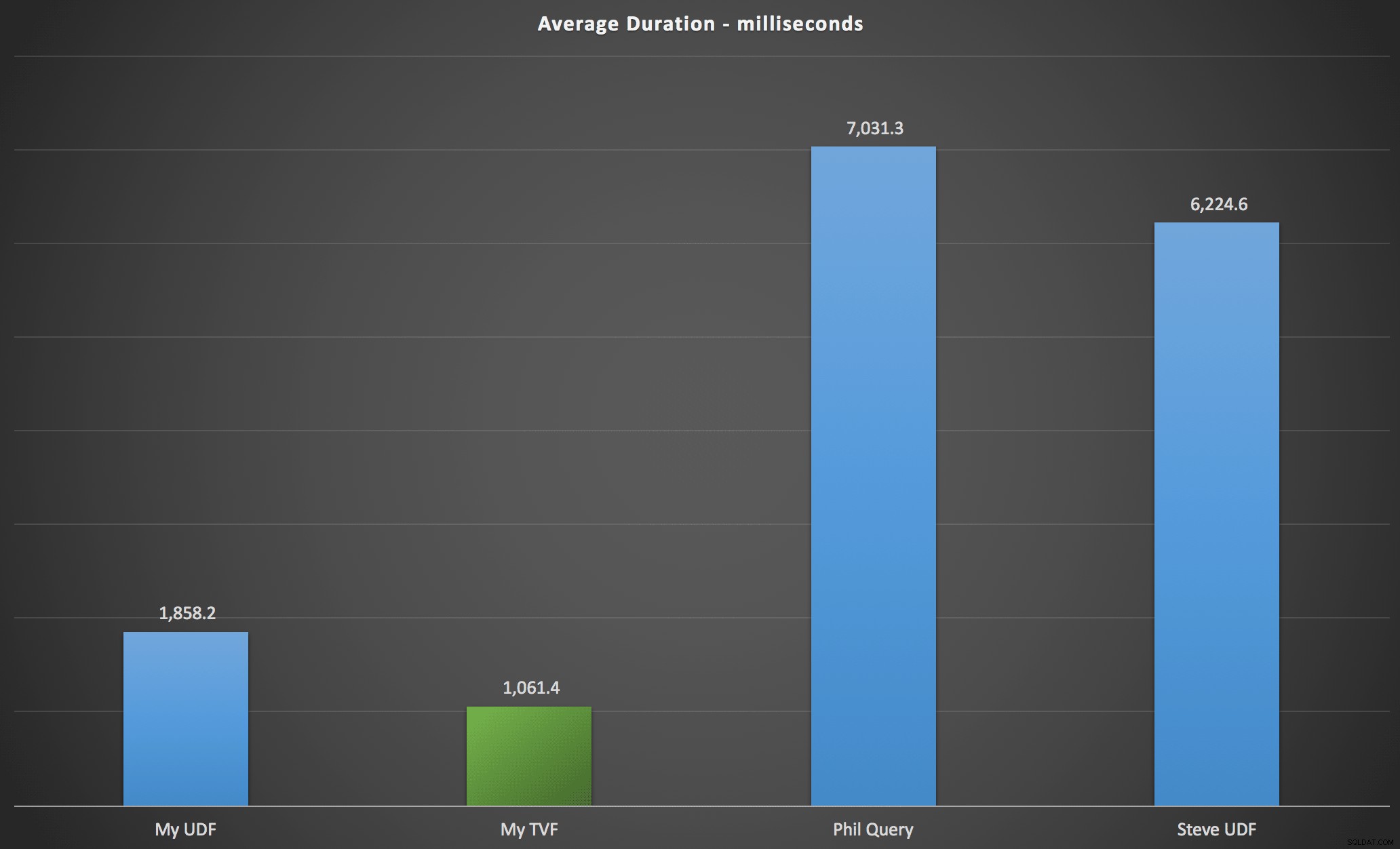
इससे पता चलता है कि संख्या तालिका, जबकि अति-इंजीनियर समझा जाता है, वास्तव में सबसे कुशल समाधान (कम से कम अवधि के संदर्भ में) प्राप्त करता है। यह निश्चित रूप से, एकल टीवीएफ के साथ बेहतर था जिसे मैंने मूल लेख से नेस्टेड कार्यों की तुलना में हाल ही में लागू किया था, लेकिन दोनों समाधान दो विकल्पों के आसपास मंडल चलाते हैं।
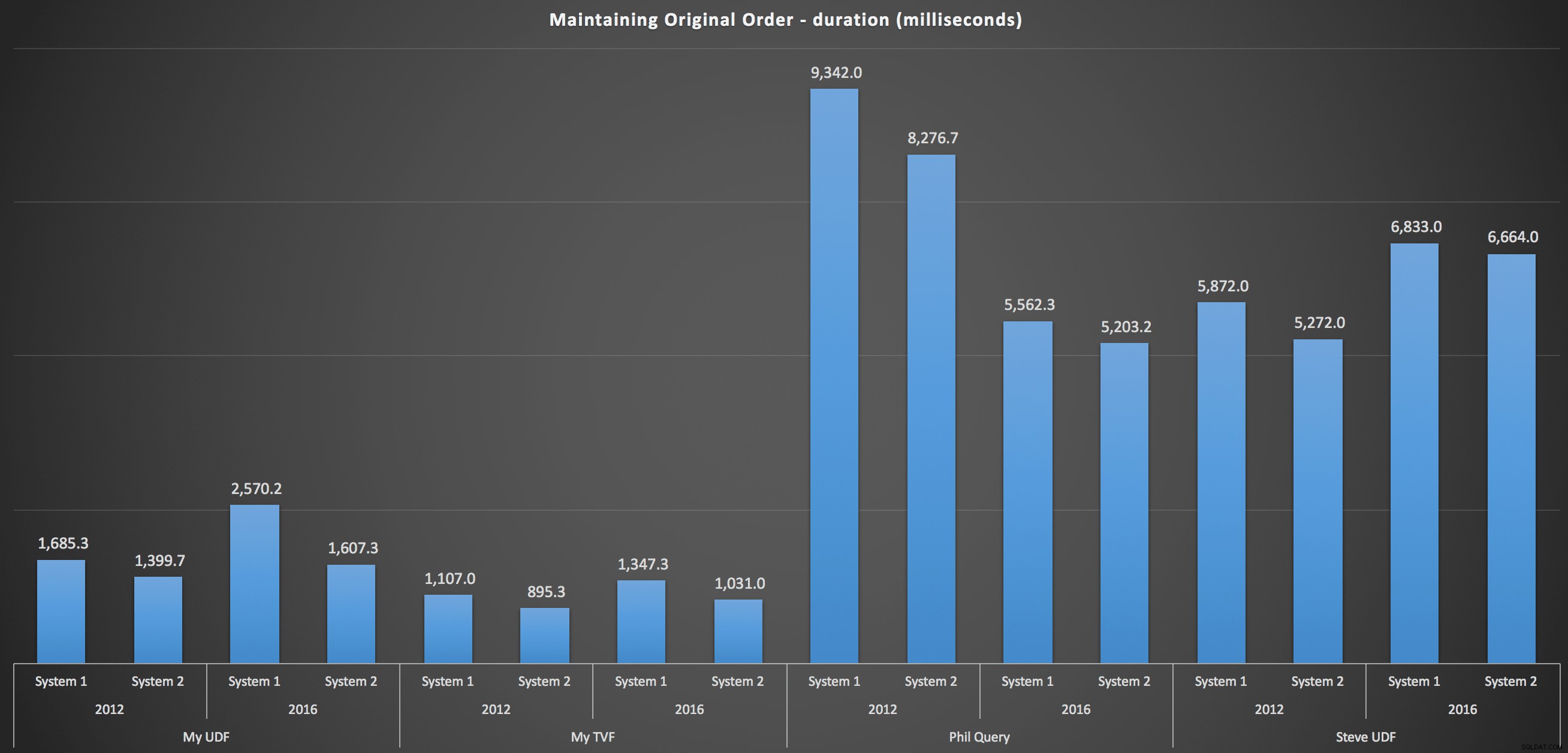
अधिक विवरण में जाने के लिए, मूल क्रम को बनाए रखने के लिए प्रत्येक मशीन, संस्करण और क्वेरी प्रकार के लिए विश्लेषण यहां दिए गए हैं:
...और सूची को वर्णानुक्रम में फिर से जोड़ने के लिए:
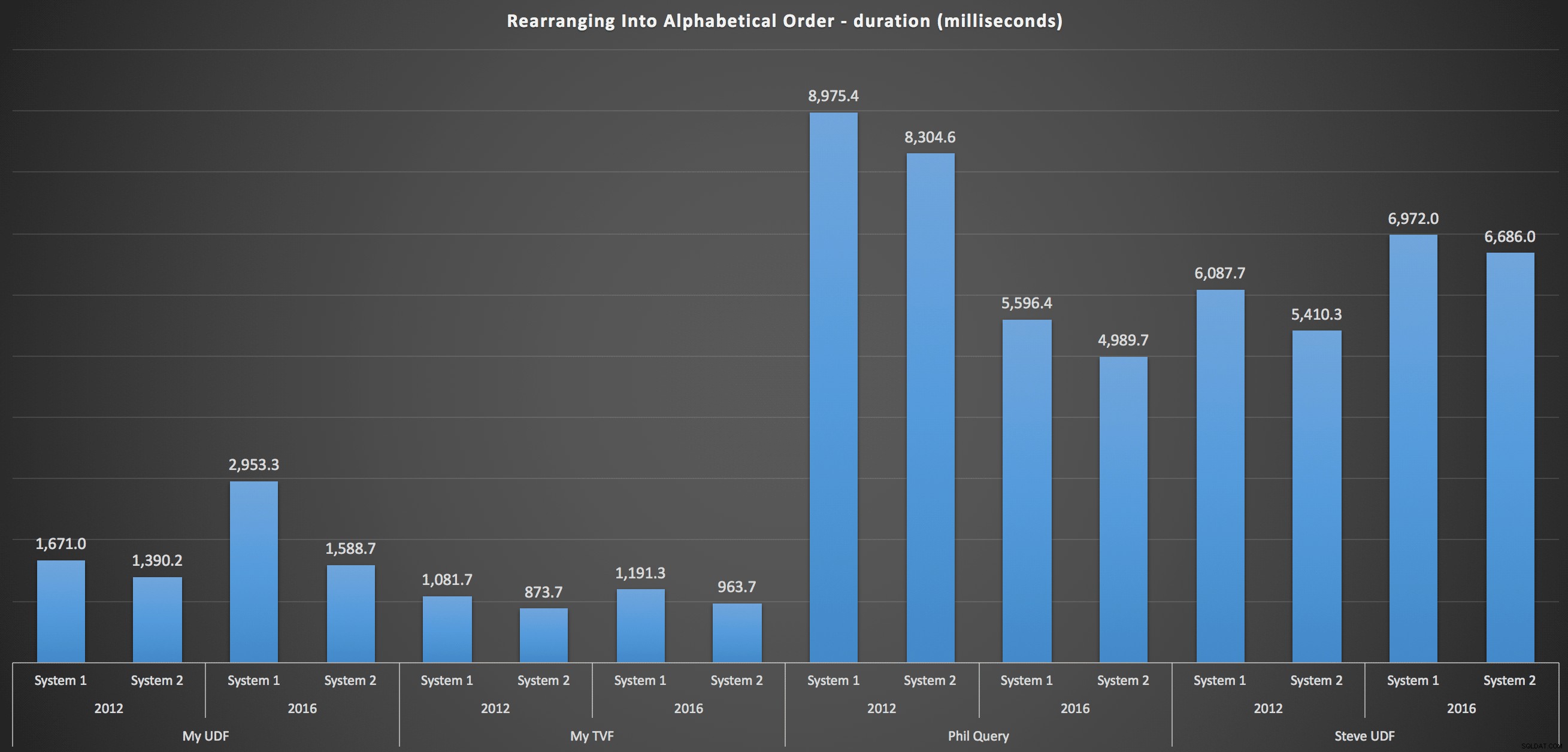
ये दिखाते हैं कि छँटाई के विकल्प का परिणाम पर बहुत कम प्रभाव पड़ा - दोनों चार्ट लगभग समान हैं। और यह समझ में आता है क्योंकि, इनपुट डेटा के रूप को देखते हुए, कोई अनुक्रमणिका नहीं है जिसकी मैं कल्पना कर सकता हूं जो सॉर्टिंग को और अधिक कुशल बना देगा - यह एक पुनरावृत्त दृष्टिकोण है चाहे आप इसे कैसे टुकड़ा करते हैं या आप डेटा कैसे वापस करते हैं। लेकिन यह स्पष्ट है कि कुछ पुनरावृत्त दृष्टिकोण आम तौर पर दूसरों की तुलना में बदतर हो सकते हैं, और यह जरूरी नहीं कि एक यूडीएफ (या संख्याओं की एक तालिका) का उपयोग होता है जो उन्हें इस तरह बनाता है।
निष्कर्ष
जब तक हमारे पास SQL सर्वर में नेटिव स्प्लिट और कॉन्सटेनेशन फंक्शनलिटी नहीं है, तब तक हम काम पूरा करने के लिए सभी प्रकार के अनपेक्षित तरीकों का उपयोग करने जा रहे हैं, जिसमें यूजर-डिफ़ाइंड फ़ंक्शंस भी शामिल हैं। यदि आप एक समय में एक ही स्ट्रिंग को संभाल रहे हैं, तो आपको बहुत अंतर दिखाई नहीं देगा। लेकिन जैसे-जैसे आपका डेटा बढ़ता है, विभिन्न दृष्टिकोणों का परीक्षण करने के लिए यह आपके समय के लायक होगा (और मैं किसी भी तरह से यह सुझाव नहीं दे रहा हूं कि उपरोक्त विधियां सबसे अच्छी हैं जो आपको मिलेंगी - मैंने सीएलआर को भी नहीं देखा, उदाहरण के लिए, या इस श्रृंखला से अन्य टी-एसक्यूएल दृष्टिकोण)।