इससे पहले इस श्रृंखला में (भाग 1 | भाग 2) हमने विभिन्न तकनीकों का उपयोग करके संख्याओं की एक श्रृंखला बनाने के बारे में बात की थी। कुछ परिदृश्यों में दिलचस्प और उपयोगी होते हुए, एक अधिक व्यावहारिक अनुप्रयोग सन्निहित तिथियों की एक श्रृंखला उत्पन्न करना है; उदाहरण के लिए, एक रिपोर्ट जिसमें महीने के सभी दिन दिखाने की आवश्यकता होती है, भले ही कुछ दिनों में कोई लेन-देन न हुआ हो।
पिछली पोस्ट में मैंने उल्लेख किया था कि संख्याओं की एक श्रृंखला से दिनों की एक श्रृंखला प्राप्त करना आसान है। चूंकि हमने संख्याओं की एक श्रृंखला प्राप्त करने के कई तरीके पहले ही स्थापित कर लिए हैं, आइए देखें कि अगला चरण कैसा दिखता है। आइए बहुत सरल शुरुआत करें, और दिखाएँ कि हम 1 जनवरी से 3 जनवरी तक तीन दिनों के लिए एक रिपोर्ट चलाना चाहते हैं, और प्रत्येक दिन के लिए एक पंक्ति शामिल करना चाहते हैं। पुराने जमाने का तरीका एक #temp टेबल बनाना होगा, एक लूप बनाना होगा, एक वेरिएबल होगा जो वर्तमान दिन रखता है, लूप के भीतर #temp टेबल में रेंज के अंत तक एक पंक्ति डालें, और फिर # का उपयोग करें हमारे स्रोत डेटा में बाहरी जुड़ने के लिए अस्थायी तालिका। यहां तक कि मैं यहां प्रस्तुत करना चाहता हूं, उससे कहीं अधिक कोड है, उत्पादन में कोई फर्क नहीं पड़ता, रखरखाव करता है, और सहकर्मियों से सीखता है।
सरल शुरुआत
संख्याओं के एक स्थापित अनुक्रम के साथ (चाहे आप जो भी विधि चुनें), यह कार्य बहुत आसान हो जाता है। इस उदाहरण के लिए मैं जटिल अनुक्रम जनरेटर को एक बहुत ही सरल संघ के साथ बदल सकता हूं, क्योंकि मुझे केवल तीन दिनों की आवश्यकता है। मैं इस सेट में चार पंक्तियाँ बनाने जा रहा हूँ, ताकि यह प्रदर्शित करना भी आसान हो जाए कि आपको जिस शृंखला की ज़रूरत है, उसे कैसे काटें।
सबसे पहले, हमारे पास उस श्रेणी की शुरुआत और अंत को पकड़ने के लिए कुछ चर हैं जिनमें हम रुचि रखते हैं:
DECLARE @s DATE = '2012-01-01', @e DATE = '2012-01-03';
अब, अगर हम केवल साधारण श्रृंखला जनरेटर से शुरू करते हैं, तो यह इस तरह दिख सकता है। मैं एक ORDER BY जोड़ने जा रहा हूं यहां भी, केवल सुरक्षित रहने के लिए, क्योंकि हम कभी भी उन धारणाओं पर भरोसा नहीं कर सकते जो हम आदेश के बारे में करते हैं।
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT n FROM n ORDER BY n; -- result: n ---- 1 2 3 4
इसे तिथियों की एक श्रृंखला में बदलने के लिए, हम बस DATEADD() . लागू कर सकते हैं प्रारंभ तिथि से:
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n, @s) FROM n ORDER BY n; -- result: ---- 2012-01-02 2012-01-03 2012-01-04 2012-01-05
यह अभी भी बिल्कुल सही नहीं है, क्योंकि हमारी सीमा 1 के बजाय 2 से शुरू होती है। तो आधार के रूप में हमारी प्रारंभ तिथि का उपयोग करने के लिए, हमें अपने सेट को 1-आधारित से 0-आधारित में परिवर्तित करने की आवश्यकता है। हम 1 को घटाकर ऐसा कर सकते हैं:
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03 2012-01-04
वहाँ लगभग! हमें केवल अपने बड़े श्रृंखला स्रोत से परिणाम को सीमित करने की आवश्यकता है, जो हम DATEDIFF को खिलाकर कर सकते हैं , दिनों में, सीमा के प्रारंभ और अंत के बीच, एक TOP . तक ऑपरेटर - और फिर 1 जोड़ना (चूंकि DATEDIFF अनिवार्य रूप से एक ओपन-एंडेड रेंज की रिपोर्ट करता है)।
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03
वास्तविक डेटा जोड़ना
अब यह देखने के लिए कि हम एक रिपोर्ट प्राप्त करने के लिए किसी अन्य तालिका से कैसे जुड़ेंगे, हम बस उस नई क्वेरी का उपयोग कर सकते हैं और स्रोत डेटा के विरुद्ध बाहरी जुड़ाव का उपयोग कर सकते हैं।
;WITH n(n) AS ( SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 ), d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(o.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeader AS o ON o.OrderDate >= d.OrderDate AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate) GROUP BY d.OrderDate ORDER BY d.OrderDate;
(ध्यान दें कि अब हम COUNT(*) . नहीं कह सकते हैं , चूंकि यह बाईं ओर गिना जाएगा, जो हमेशा 1 होगा।)
इसे लिखने का दूसरा तरीका यह होगा:
;WITH d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s)
FROM
(
SELECT 1 UNION ALL SELECT 2 UNION ALL
SELECT 3 UNION ALL SELECT 4
) AS n(n) ORDER BY n
)
SELECT
d.OrderDate,
OrderCount = COUNT(o.SalesOrderID)
FROM d
LEFT OUTER JOIN Sales.SalesOrderHeader AS o
ON o.OrderDate >= d.OrderDate
AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate)
GROUP BY d.OrderDate
ORDER BY d.OrderDate;
इससे यह कल्पना करना आसान हो जाना चाहिए कि आप अपने द्वारा चुने गए किसी भी स्रोत से दिनांक अनुक्रम की पीढ़ी के साथ अग्रणी सीटीई को कैसे बदलेंगे। हम AdventureWorks2012 का उपयोग करके उन (पुनरावर्ती CTE दृष्टिकोण के अपवाद के साथ, जो केवल ग्राफ़ को तिरछा करने के लिए कार्य करता है) के माध्यम से जाएंगे, लेकिन हम SalesOrderHeaderEnlarged का उपयोग करेंगे तालिका मैंने जोनाथन केहैयस द्वारा इस लिपि से बनाई है। मैंने इस विशिष्ट क्वेरी में मदद के लिए एक इंडेक्स जोड़ा:
CREATE INDEX d_so ON Sales.SalesOrderHeaderEnlarged(OrderDate);
यह भी ध्यान दें कि मैं एक मनमाना दिनांक सीमा चुन रहा हूँ जो मुझे पता है कि तालिका में मौजूद है।
नंबर तालिका
;WITH d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM dbo.Numbers ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
योजना (विस्तार करने के लिए क्लिक करें):
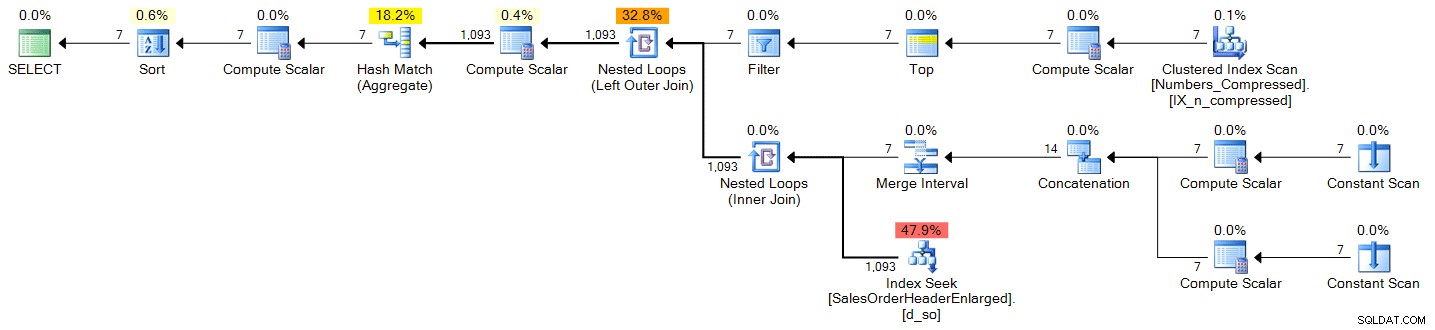
spt_values
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY Number) FROM master..spt_values) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
योजना (विस्तार करने के लिए क्लिक करें):
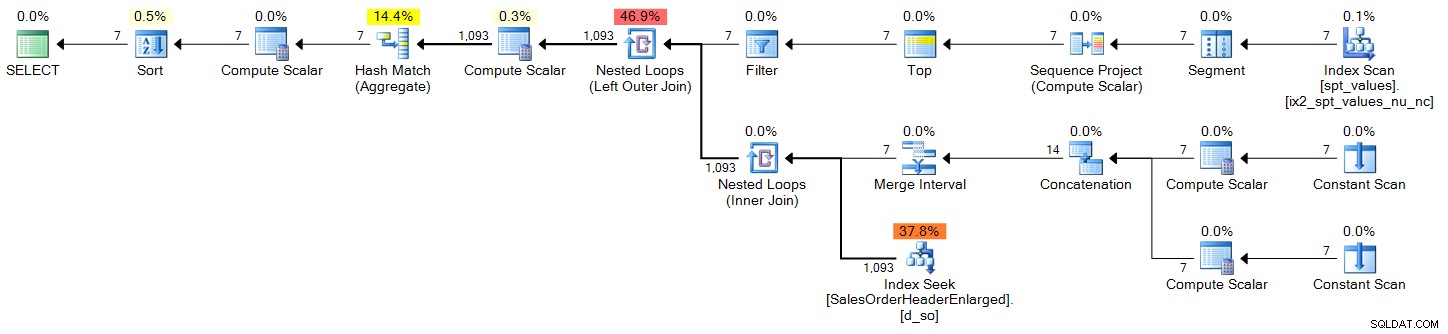
sys.all_objects
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
योजना (विस्तार करने के लिए क्लिक करें):
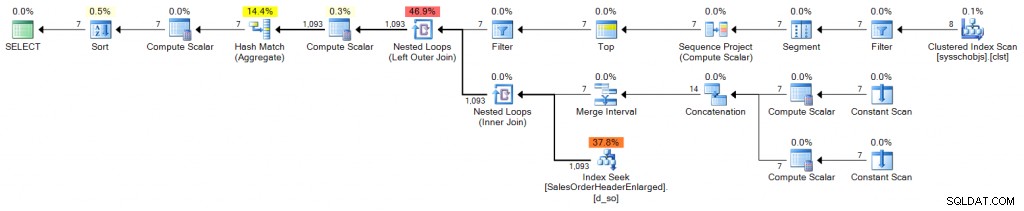
स्टैक्ड सीटीई
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY n)-1, @s)
FROM e2
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; योजना (विस्तार करने के लिए क्लिक करें):
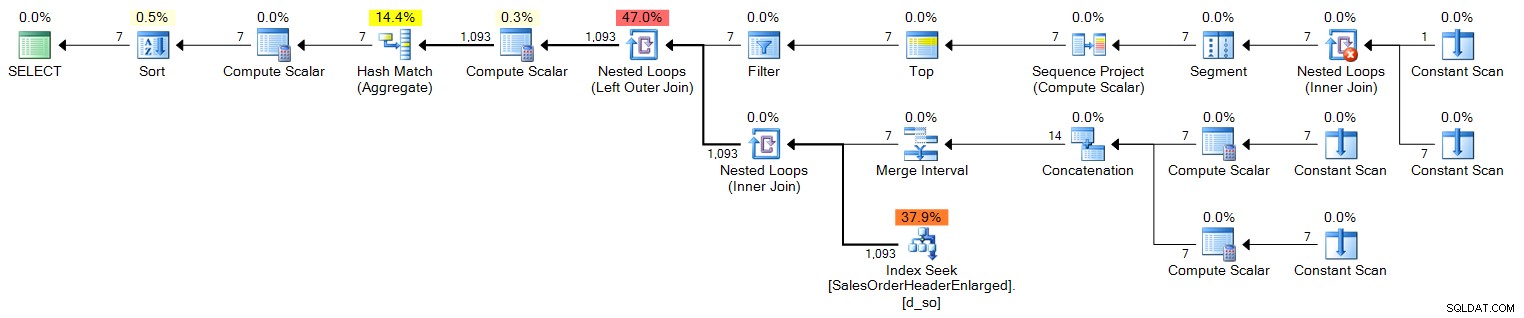
अब, एक साल की लंबी अवधि के लिए, यह इसे नहीं काटेगा, क्योंकि यह केवल 100 पंक्तियों का उत्पादन करता है। एक साल के लिए हमें 366 पंक्तियों को कवर करना होगा (संभावित लीप वर्षों के लिए खाते में), तो यह इस तरह दिखेगा:
DECLARE @s DATE = '2006-10-23', @e DATE = '2007-10-22';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
e3(n) AS (SELECT 1 FROM e2 CROSS JOIN (SELECT TOP (37) n FROM e2) AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY N)-1, @s)
FROM e3
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; योजना (विस्तार करने के लिए क्लिक करें):
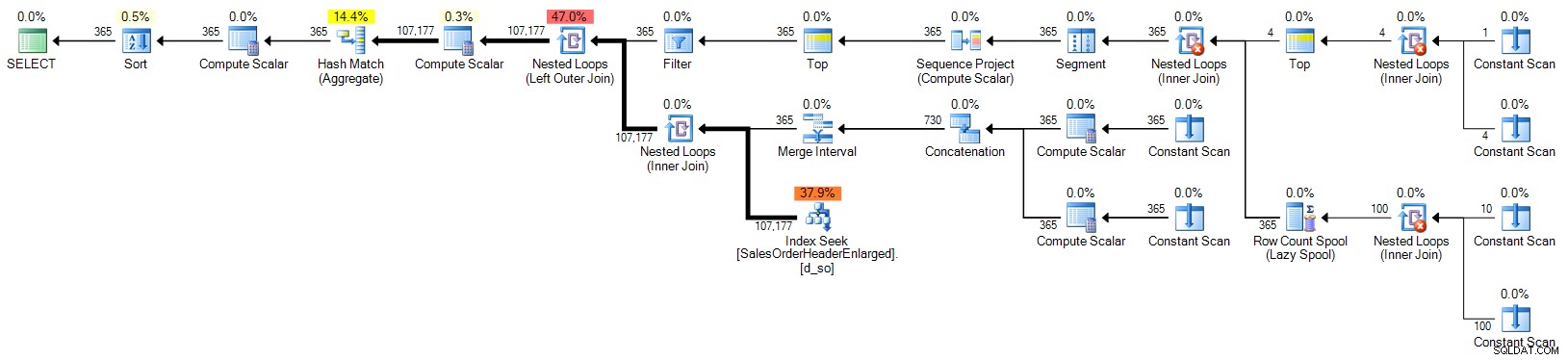
कैलेंडर तालिका
यह एक नया है जिसके बारे में हमने पिछली दो पोस्टों में ज्यादा बात नहीं की थी। यदि आप बहुत से प्रश्नों के लिए दिनांक श्रृंखला का उपयोग कर रहे हैं तो आपको संख्या तालिका और कैलेंडर तालिका दोनों पर विचार करना चाहिए। वही तर्क इस बारे में रखता है कि वास्तव में कितनी जगह की आवश्यकता है और तालिका को बार-बार पूछे जाने पर कितनी तेज़ पहुंच होगी। उदाहरण के लिए, 30 साल की तारीखों को संग्रहीत करने के लिए, इसे 11,000 से कम पंक्तियों की आवश्यकता होती है (सटीक संख्या इस बात पर निर्भर करती है कि आप कितने लीप वर्ष फैलाते हैं), और केवल 200 केबी लेता है। हां, आपने सही पढ़ा:200 किलोबाइट . (और संकुचित, यह केवल 136 KB है।)
30 साल के डेटा के साथ एक कैलेंडर तालिका बनाने के लिए, यह मानते हुए कि आप पहले से ही आश्वस्त हैं कि नंबर तालिका होना एक अच्छी बात है, हम यह कर सकते हैं:
DECLARE @s DATE = '2005-07-01'; -- earliest year in SalesOrderHeader DECLARE @e DATE = DATEADD(DAY, -1, DATEADD(YEAR, 30, @s)); SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) d = CONVERT(DATE, DATEADD(DAY, n-1, @s)) INTO dbo.Calendar FROM dbo.Numbers ORDER BY n; CREATE UNIQUE CLUSTERED INDEX d ON dbo.Calendar(d);पर अद्वितीय क्लस्टर इंडेक्स बनाएं
अब हमारी बिक्री रिपोर्ट क्वेरी में उस कैलेंडर तालिका का उपयोग करने के लिए, हम एक बहुत ही सरल क्वेरी लिख सकते हैं:
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; SELECT OrderDate = c.d, OrderCount = COUNT(s.SalesOrderID) FROM dbo.Calendar AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND c.d = CONVERT(DATE, s.OrderDate) WHERE c.d >= @s AND c.d <= @e GROUP BY c.d ORDER BY c.d;
योजना (विस्तार करने के लिए क्लिक करें):

प्रदर्शन
मैंने संख्याओं और कैलेंडर तालिकाओं की संपीड़ित और असम्पीडित दोनों प्रतियां बनाईं, और एक सप्ताह की सीमा, एक महीने की सीमा और एक वर्ष की सीमा का परीक्षण किया। मैंने कोल्ड कैशे और वार्म कैशे के साथ क्वेरीज़ भी चलाईं, लेकिन यह काफी हद तक अप्रासंगिक साबित हुई।
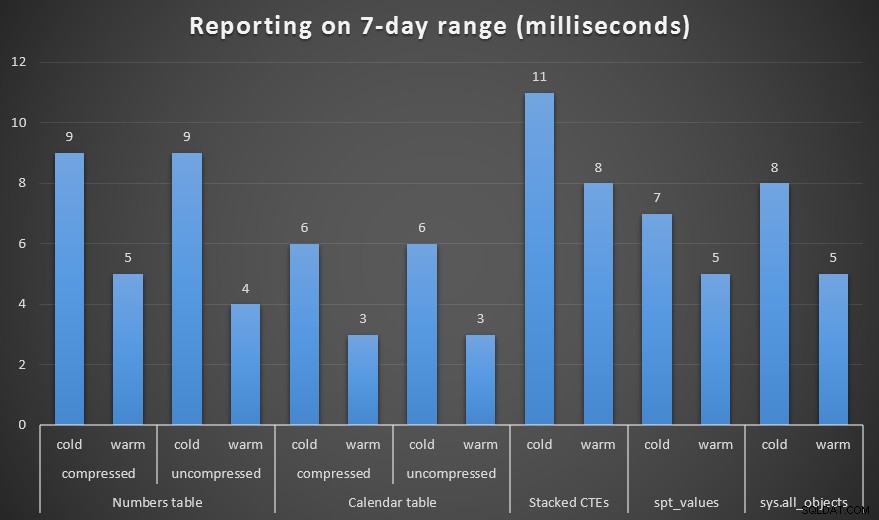
अवधि, मिलीसेकंड में, सप्ताह भर की अवधि उत्पन्न करने के लिए
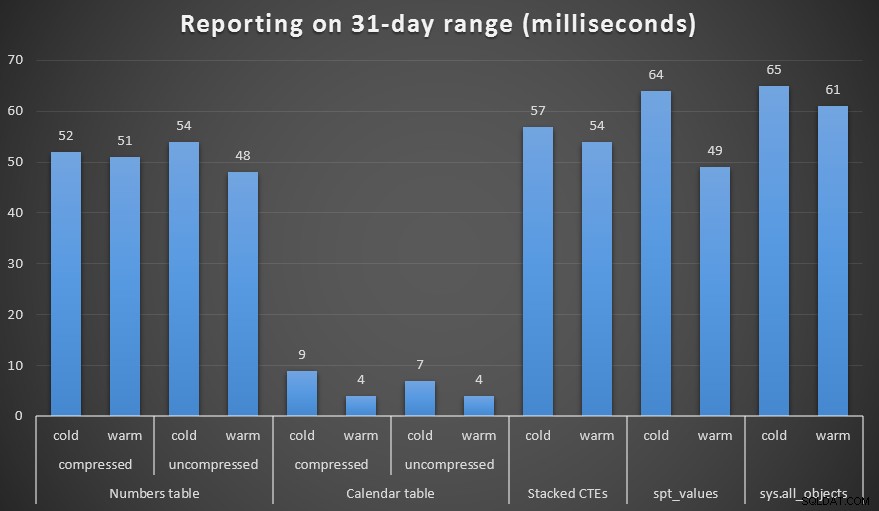
अवधि, मिलीसेकंड में, महीने भर की अवधि उत्पन्न करने के लिए
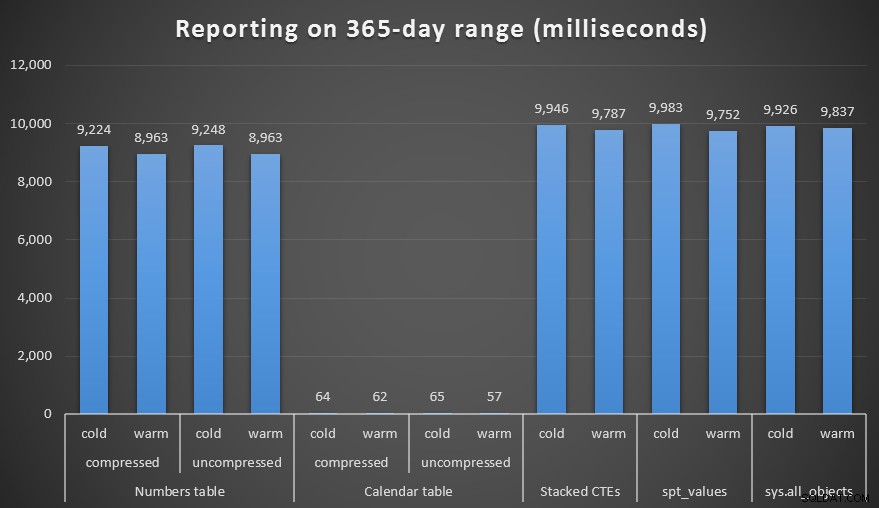
अवधि, मिलीसेकंड में, साल भर की अवधि उत्पन्न करने के लिए
परिशिष्ट
पॉल व्हाइट (ब्लॉग | @SQL_Kiwi) ने बताया कि आप निम्न क्वेरी का उपयोग करके एक अधिक कुशल योजना तैयार करने के लिए Numbers तालिका को बाध्य कर सकते हैं:
SELECT OrderDate = DATEADD(DAY, n, 0), OrderCount = COUNT(s.SalesOrderID) FROM dbo.Numbers AS n LEFT OUTER JOIN Sales.SalesOrderHeader AS s ON s.OrderDate >= CONVERT(DATETIME, @s) AND s.OrderDate < DATEADD(DAY, 1, CONVERT(DATETIME, @e)) AND DATEDIFF(DAY, 0, OrderDate) = n WHERE n.n >= DATEDIFF(DAY, 0, @s) AND n.n <= DATEDIFF(DAY, 0, @e) GROUP BY n ORDER BY n;
इस बिंदु पर मैं सभी प्रदर्शन परीक्षण (पाठक के लिए व्यायाम!) को फिर से नहीं चलाने जा रहा हूं, लेकिन मैं यह मानूंगा कि यह बेहतर या समान समय उत्पन्न करेगा। फिर भी, मुझे लगता है कि कैलेंडर तालिका एक उपयोगी चीज़ है, भले ही यह कड़ाई से आवश्यक न हो।
निष्कर्ष
परिणाम खुद अपनी कहानी कहते हैं। संख्याओं की एक श्रृंखला उत्पन्न करने के लिए, संख्या तालिका दृष्टिकोण जीत जाता है, लेकिन केवल मामूली - 1,000,000 पंक्तियों पर भी। और तिथियों की एक श्रृंखला के लिए, निचले सिरे पर, आपको विभिन्न तकनीकों के बीच अधिक अंतर नहीं दिखाई देगा। हालांकि, यह बिल्कुल स्पष्ट है कि जैसे-जैसे आपकी तिथि सीमा बड़ी होती जाती है, खासकर जब आप एक बड़े स्रोत तालिका के साथ काम कर रहे होते हैं, तो कैलेंडर तालिका वास्तव में इसके मूल्य को प्रदर्शित करती है - विशेष रूप से इसकी कम मेमोरी फुटप्रिंट को देखते हुए। कनाडा के निराला मीट्रिक सिस्टम के साथ भी, 60 मिलीसेकंड लगभग 10 *सेकंड* से बेहतर है, जब यह डिस्क पर केवल 200 KB खर्च करता था।
मुझे आशा है कि आपने इस छोटी सी श्रृंखला का आनंद लिया होगा; यह एक ऐसा विषय है जिसे मैं सदियों से फिर से देखना चाहता हूं।
[ भाग 1 | भाग 2 | भाग 3 ]