मैंने पहले NOEXPAND . का उपयोग करने के लाभों के बारे में लिखा है संकेत, एंटरप्राइज़ संस्करण में भी। विवरण सभी लिंक किए गए लेख में हैं, लेकिन संक्षेप में संक्षेप में:
- SQL सर्वर केवल स्वचालित रूप से बनाएगा एक अनुक्रमित दृश्य पर आँकड़े जब एक
NOEXPANDतालिका संकेत का उपयोग किया जाता है। इस संकेत को छोड़ने से लापता आंकड़ों के बारे में निष्पादन योजना चेतावनियां हो सकती हैं जिन्हें मैन्युअल रूप से आंकड़े बनाकर हल नहीं किया जा सकता है। - SQL सर्वर केवल उपयोग करेगा जब क्वेरी सीधे दृश्य और
NOEXPANDको संदर्भित करती है, तो कार्डिनैलिटी अनुमान गणना में स्वचालित रूप से या मैन्युअल रूप से बनाए गए दृश्य आँकड़े संकेत का प्रयोग किया जाता है। सबसे तुच्छ दृश्य परिभाषाओं को छोड़कर सभी के लिए, इसका मतलब है कि जब इस संकेत का उपयोग नहीं किया जाता है, तो कार्डिनैलिटी अनुमानों की गुणवत्ता कम होने की संभावना है, जिसके परिणामस्वरूप अक्सर कम इष्टतम निष्पादन योजनाएं होती हैं। - आंकड़ों को देखने की कमी या उपयोग करने में असमर्थता के कारण अनुकूलक कार्डिनैलिटी अनुमानों का अनुमान लगा सकता है, यहां तक कि जहां आधार तालिका आंकड़े उपलब्ध हैं। ऐसा तब हो सकता है जब क्वेरी योजना के हिस्से को स्वचालित दृश्य मिलान सुविधा द्वारा अनुक्रमित दृश्य संदर्भ से बदल दिया जाता है, लेकिन देखने के आंकड़े उपलब्ध नहीं होते हैं, जैसा कि ऊपर वर्णित है।
NOEXPAND . का उपयोग न करने का एक और परिणाम है संकेत, जिसका उल्लेख मैंने कुछ साल पहले अपने लेख में किया था, फ़िल्टर्ड इंडेक्स के साथ ऑप्टिमाइज़र लिमिटेशन:
NOEXPAND एंटरप्राइज़ संस्करण में भी संकेतों की आवश्यकता होती है ताकि यह सुनिश्चित हो सके कि व्यू इंडेक्स द्वारा प्रदान की गई विशिष्टता गारंटी ऑप्टिमाइज़र द्वारा उपयोग की जाती है।
यह लेख उस कथन और उसके निहितार्थों की अधिक विस्तार से जाँच करता है।
डेमो सेटअप
निम्न स्क्रिप्ट एक साधारण तालिका और अनुक्रमित दृश्य बनाती है:
क्रिएट टेबल dbo.T(col1 इंटीजर नॉट न्यूल);GOINSERT dbo.T विद (TABLOCKX) (col1) सेलेक्ट SV.numberFROM Master.dbo.spt_values as SVWHERE SV.type =N'P';GOCREATE VEEW dbo. VTWITH SCHEMABINDINGASचयन T.col1 से dbo.T AS T;GOCREATE UNIQUE CLUSTERED INDEX cuqON dbo.VT (col1);
यह एक एकल कॉलम हीप टेबल बनाता है, और एक अद्वितीय क्लस्टर इंडेक्स के साथ एक ही टेबल का एक अप्रतिबंधित दृश्य बनाता है। यह एक अनुक्रमित दृश्य के लिए एक यथार्थवादी उपयोग मामला होने का इरादा नहीं है; लेकिन यह कम से कम विकर्षणों के साथ प्रमुख बिंदुओं को स्पष्ट करने में मदद करेगा। महत्वपूर्ण बिंदु यह है कि यहां आधार तालिका में कोई अनुक्रमणिका नहीं है (यहां तक कि एक संकुल अनुक्रमणिका भी नहीं) लेकिन दृश्य करता है, और वह अनुक्रमणिका अद्वितीय है।
उदाहरण क्वेरी
आधार तालिका के विरुद्ध निम्नलिखित सरल प्रश्न पर विचार करें:
dbo.T AS T से DISTINCT T.col1 चुनें;
इस क्वेरी के लिए आप जो निष्पादन योजना देखेंगे वह उपयोग में SQL सर्वर के संस्करण पर निर्भर करता है। यदि एंटरप्राइज़ संस्करण (या समकक्ष) नहीं है तो आपको इस तरह की योजना दिखाई देगी:

SQL सर्वर क्वेरी ऑप्टिमाइज़र ने बेस टेबल को स्कैन करने और एक विशिष्ट सॉर्ट ऑपरेटर का उपयोग करके निर्दिष्ट विशिष्टता को लागू करने के लिए चुना है। यह योजना आकार पूरी तरह से अपेक्षित है, क्योंकि एंटरप्राइज़ संस्करण के बाहर स्वचालित अनुक्रमित दृश्य मिलान उपलब्ध नहीं है। मैं इस बिंदु से "एंटरप्राइज़ संस्करण या समकक्ष" कहना बंद करने जा रहा हूं, लेकिन कृपया यह अनुमान लगाना जारी रखें कि मेरा मतलब किसी भी संस्करण से है जो अब से "एंटरप्राइज संस्करण" कहने पर स्वचालित दृश्य मिलान का समर्थन करता है।
विस्तार दृश्य संकेत
यह थोड़ा अलग है, लेकिन एंटरप्राइज़ संस्करण पर समान योजना प्राप्त करने के लिए, हमें EXPAND VIEWS का उपयोग करने की आवश्यकता है क्वेरी संकेत:
DBO.T से T.col1 को TOPTION के रूप में चुनें (विस्तार देखें);
कोई दृश्य संदर्भ नहीं . होने पर इस संकेत का उपयोग करना थोड़ा अजीब लग सकता है क्वेरी में, लेकिन इस तरह यह काम करता है। EXPAND VIEWS संकेत प्रभावी रूप से निर्दिष्ट करता है कि क्वेरी को संकलित और अनुकूलित करते समय अनुक्रमित दृश्य मिलान अक्षम किया जाना चाहिए। स्पष्ट होने के लिए:इस संकेत के बिना, एंटरप्राइज़ संस्करण अन्यथा एक या अधिक अनुक्रमित दृश्यों के साथ क्वेरी का मिलान (भागों) कर सकता है।
स्वचालित दृश्य मिलान सक्षम होने के साथ
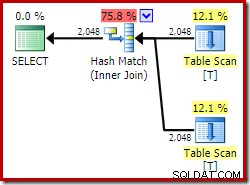
बिना EXPAND VIEWS संकेत, डेवलपर संस्करण (उदाहरण के लिए) पर एक ही क्वेरी को संकलित करने से एक अलग योजना तैयार होती है:
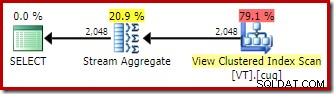
अनुक्रमित दृश्य मिलान के अनुप्रयोग का अर्थ है कि निष्पादन योजना में आधार तालिका स्कैन के बजाय दृश्य संकुल अनुक्रमणिका का स्कैन होता है।
इस मामले में वही योजना तैयार की जाती है यदि क्वेरी सीधे दृश्य को संदर्भित करती है (आधार तालिका के बजाय):
dbo.VT AS V से DISTINCT V.col1 चुनें;
सभी संस्करणों में, क्वेरी ऑप्टिमाइज़ेशन शुरू होने से पहले दृश्य संदर्भ का विस्तार किया जाता है। एंटरप्राइज़-समतुल्य संस्करणों में, विस्तारित रूप को बाद में दृश्य में वापस मिलान किया जा सकता है। SQL सर्वर में क्वेरी कंपाइलर और ऑप्टिमाइज़र अनुक्रमित दृश्यों का उपयोग कैसे करते हैं, इस बारे में सोचते समय यह समझने की एक महत्वपूर्ण अवधारणा है।
द स्ट्रीम एग्रीगेट
अब तक हमने जो दो प्लान देखे हैं, उनमें सबसे दिलचस्प अंतर व्यू-मैचेड प्लान में स्ट्रीम एग्रीगेट है। यदि आप टेबल स्कैन और व्यू स्कैन ऑपरेटरों की अनुमानित लागतों को देखें, तो आप देखेंगे कि वे बिल्कुल समान हैं। ऑप्टिमाइज़र ने अनुक्रमित दृश्य का उपयोग करने का निर्णय नहीं लिया क्योंकि इसने डेटा तक पहुँच को और भी सस्ता बना दिया। बल्कि, दृश्य अनुक्रमणिका को स्कैन करने से DISTINCT . की अनुमति मिलती है हैश एग्रीगेट या डिस्टिंक्ट सॉर्ट (पहली योजना के अनुसार) के बजाय स्ट्रीम एग्रीगेट के रूप में लागू करने की आवश्यकता है।
एक स्ट्रीम एग्रीगेट को ग्रुपिंग कॉलम द्वारा ऑर्डर किए गए इनपुट की आवश्यकता होती है। इस मामले में, विशिष्ट एकल कॉलम द्वारा समूहीकरण के बराबर है, और दृश्य का अद्वितीय क्लस्टर इंडेक्स आवश्यक ऑर्डरिंग गारंटी प्रदान करता है। ऑप्टिमाइज़र का लागत मॉडल इस क्वेरी के लिए डिस्टिंक्ट सॉर्ट या हैश एग्रीगेट की तुलना में एक सस्ते विकल्प के रूप में स्ट्रीम एग्रीगेट की पहचान करता है। स्वचालित दृश्य मिलान उपलब्ध होने पर ऑप्टिमाइज़र द्वारा अनुक्रमित दृश्य तक पहुँचने का चयन करने का यही आधार है।
जो कुछ भी कहा और समझा गया है, उसके साथ स्ट्रीम एग्रीगेट अभी भी अप्रत्याशित है:व्यू इंडेक्स द्वारा प्रदान की गई विशिष्टता की गारंटी को देखते हुए, इस ग्रुपिंग ऑपरेशन को करने की बिल्कुल भी आवश्यकता नहीं है। अद्वितीय क्लस्टर इंडेक्स पहले से ही सुनिश्चित करता है कि कॉलम में कोई डुप्लीकेट नहीं है।
यह, संक्षेप में, समस्या है। जब स्वचालित दृश्य मिलान का उपयोग किया जाता है, तो ऑप्टिमाइज़र दृश्य अनुक्रमणिका द्वारा प्रदान की गई ऑर्डरिंग गारंटी को पहचानता है, लेकिन विशिष्टता की गारंटी को नहीं।
NOEXPAND संकेत का उपयोग करना
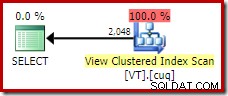
इस क्वेरी के लिए आदर्श निष्पादन योजना प्राप्त करने के लिए, हमें सीधे दृश्य को संदर्भित करने और NOEXPAND का उपयोग करने की आवश्यकता है तालिका संकेत:
dbo.VT AS V से (NOEXPAND) से DISTINCT V.col1 चुनें;
यह हमें वह योजना देता है जिसकी एक अनुभवी डेटाबेस व्यक्ति अपेक्षा करता है; एक जो सही ढंग से पहचानता है कि विशिष्ट ऑपरेशन बेमानी है और इसे हटाया जा सकता है:
दूसरा उदाहरण
एक दृश्य सूचकांक द्वारा प्रदान की गई विशिष्टता गारंटी का लाभ लेने में विफल होने से अंतिम निष्पादन योजना पर अन्य प्रभाव पड़ सकते हैं। अब अनुक्रमित दृश्य के एक सेल्फ जॉइन पर विचार करें (फिर से, केवल एक अवधारणा को स्पष्ट करने के लिए - यह एक यथार्थवादी प्रश्न होने का इरादा नहीं है):
V1.col1, V2.col1FROM से चुनें।डेवलपर संस्करण का उपयोग करके चुनी गई निष्पादन योजना अनुक्रमित दृश्य तक बिल्कुल भी नहीं पहुंचती है, और हैश जॉइन की सुविधा देती है (कभी-कभी एक संकेत है कि एक उपयोगी अनुक्रमणिका गुम है):
आइए अब ठीक उसी क्वेरी का प्रयास करें, लेकिन एक
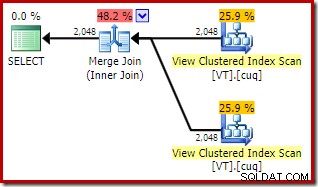
NOEXPAND. के साथ प्रत्येक दृश्य संदर्भ पर संकेत:V1.col1, V2.col1FROM से चुनें।निष्पादन योजना में अब दो अनुक्रमित दृश्य एक्सेस और एक मर्ज जॉइन की सुविधा है:
इस नई योजना की अनुमानित लागत हैश जॉइन योजना की तुलना में बहुत कम है, तो अनुकूलक ने पहले इस विकल्प को क्यों नहीं चुना? मूल क्वेरी में मर्ज जॉइन हिंट जोड़कर हम देख सकते हैं कि क्यों:
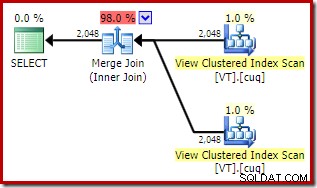
V1.col1, V2.col1FROM से चुनें।यह एक समान दिखने वाला . देता है योजना जो दृश्य तक पहुँचने का विकल्प चुनती है, भले ही
NOEXPANDनिर्दिष्ट नहीं किया गया था:
इस योजना की कुल अनुमानित लागत पिछले दोनों उदाहरणों की तुलना में अधिक है। इस योजना में शामिल होने से पहले की तुलना में कुल अनुमानित लागत का उच्च अनुपात (98% बनाम 48.2%) भी होता है।
इसका कारण मर्ज जॉइन के गुणों को देखकर देखा जा सकता है।
NOEXPAND. में योजना, यह एक से कई मर्ज में शामिल होना था। सीधे ऊपर की योजना में, यह कई से कई मर्ज में शामिल है। ऑप्टिमाइज़र का लागत मॉडल कई-से-अनेक मर्ज में शामिल होने के लिए एक उच्च लागत प्रदान करता है क्योंकि किसी भी डुप्लिकेट को संभालने के लिए एक tempdb वर्कटेबल की आवश्यकता होती है।निष्कर्ष
एक अद्वितीय सूचकांक द्वारा प्रदान की गई गारंटी एक शक्तिशाली अनुकूलन उपकरण हो सकती है, इसलिए यह शर्म की बात है कि स्वचालित सूचकांक मिलान वर्तमान में इसका लाभ उठाने में असमर्थ है। संभावित लाभ अनावश्यक एकत्रीकरण को समाप्त करने या एक-से-कई मर्ज में शामिल होने को सक्षम करने से परे हैं जैसा कि पिछले सरल उदाहरणों में देखा गया है। सामान्य तौर पर, यह पता लगाना कठिन हो सकता है कि एक निष्पादन योजना उप-इष्टतम है क्योंकि अनुकूलक एक विशिष्टता गारंटी का लाभ लेने से चूक गया।
यह ऑप्टिमाइज़र सीमा न केवल उस अद्वितीय क्लस्टर इंडेक्स पर लागू होती है जो एक दृश्य को अमल में लाने के लिए होना चाहिए। अधिक जटिल परिदृश्यों में, अतिरिक्त गैर-संकुल अनुक्रमणिकाएँ भी दृश्य पर मौजूद हो सकती हैं; शायद क्रॉस-टेबल संबंधों को प्रतिबिंबित करने के लिए जिन्हें लागू करना या अन्यथा प्रतिनिधित्व करना मुश्किल है। यदि इन गैर-संकुल अनुक्रमणिकाओं को अद्वितीय के रूप में परिभाषित किया गया है, तो अनुकूलक इन गारंटियों को भी अनदेखा कर देगा, यदि स्वचालित अनुक्रमणिका मिलान का उपयोग किया जाता है।
इसे सांख्यिकीय जानकारी के निर्माण और उपयोग के आसपास की सीमाओं में जोड़कर, ऐसा लगता है कि स्वचालित दृश्य मिलान पर निर्भर होने से निम्न निष्पादन योजनाएं हो सकती हैं। सबसे सुरक्षित विकल्प शायद अनुक्रमित दृश्यों को स्पष्ट रूप से संदर्भित करना है, और
NOEXPAND. का उपयोग करना है हर बार संकेत दें - कम से कम जब तक इन मुद्दों को उत्पाद में संबोधित नहीं किया जाता है।कम करने वाले कारक
मुझे इस बात पर जोर देना चाहिए कि इस लेख में वर्णित मुद्दा केवल एक अद्वितीय दृश्य सूचकांक द्वारा प्रदान की गई विशिष्टता की गारंटी पर लागू होता है। यदि अनुकूलक आवश्यक विशिष्टता जानकारी प्राप्त कर सकता है दूसरे तरीके से , संभावना अच्छी है कि अनुकूलन समस्याओं से बचा जा सकता है।
उदाहरण के लिए, दृश्य द्वारा संदर्भित आधार तालिका पर एक उपयुक्त अद्वितीय अनुक्रमणिका हो सकती है। या, एक दृश्य के मामले में जिसमें एकत्रीकरण होता है, अनुकूलक पहले से ही दृश्य के
GROUP BYसे एक उपयोगी विशिष्टता गारंटी का अनुमान लगा सकता है। खंड। ग्रुपिंग कीज़ में व्यू क्लस्टर्ड इंडेक्स जोड़ने का सामान्य अभ्यास उस मामले में कोई अतिरिक्त विशिष्टता जानकारी नहीं जोड़ता है।फिर भी, ऐसे समय होते हैं जहां इस "विशिष्टता निरीक्षण" का अर्थ यह हो सकता है कि आपको एक स्पष्ट दृश्य संदर्भ और
NOEXPANDका उपयोग करके बेहतर गुणवत्ता निष्पादन योजनाएं प्राप्त होंगी। संकेत, एंटरप्राइज़ संस्करण में भी।