पेरोल डेटा मॉडल आपको अपने कर्मचारियों के वेतन की आसानी से गणना करने की अनुमति देता है। यह मॉडल कैसे काम करता है?
कोई फर्क नहीं पड़ता कि आप एक छोटी या बड़ी कंपनी चला रहे हैं, आपको किसी प्रकार के पेरोल समाधान की आवश्यकता है। यहीं पेरोल एप्लिकेशन काम आता है। साथ ही, कंपनी जितनी बड़ी होगी, कर्मचारियों के वेतन की गणना को संभालना उतना ही कठिन होगा; यहाँ, एक पेरोल आवेदन एक आवश्यकता बन जाता है। ऐसे एप्लिकेशन के लिए आवश्यक सभी डेटा को समझने में आपकी मदद करने के लिए, हम आपको संबंधित डेटा मॉडल के बारे में बताएंगे।
आइए देखें कि हमारा पेरोल डेटा मॉडल कैसे काम करता है!
डेटा मॉडल
इस डेटा मॉडल को बनाने के साथ, मैंने एक ऐसा मॉडल बनाने की कोशिश की जो आम तौर पर हर व्यवसाय के लिए लागू हो। बेशक, नियमों, कंपनी की नीतियों, आदि में हमेशा अंतर रहेगा, जिसके लिए मॉडल को एक विशिष्ट पेरोल की जरूरतों को पूरा करने के लिए अनुकूलित करने की आवश्यकता होगी। हालांकि, इस मॉडल में निर्धारित सिद्धांत अधिकांश संगठनों के लिए प्रासंगिक होने चाहिए।
यह ध्यान दिया जाना चाहिए कि यह मॉडल कई मान्यताओं के साथ बनाया गया था:
- रोजगार अनुबंध द्वारा सहमति के अनुसार वेतन प्रति वर्ष है।
- निवल वेतन (अर्थात करों आदि के लिए कुछ निश्चित राशियों के साथ) का भुगतान कर्मचारियों को किया जाता है।
- वेतन मासिक भुगतान किया जाता है।
डेटा मॉडल में चौदह टेबल होते हैं और इसे दो विषय क्षेत्रों में विभाजित किया जाता है:
EmployeesSalaries
मॉडल को बेहतर ढंग से समझने के लिए, प्रत्येक विषय क्षेत्र को अच्छी तरह से पढ़ना आवश्यक है।
कर्मचारी
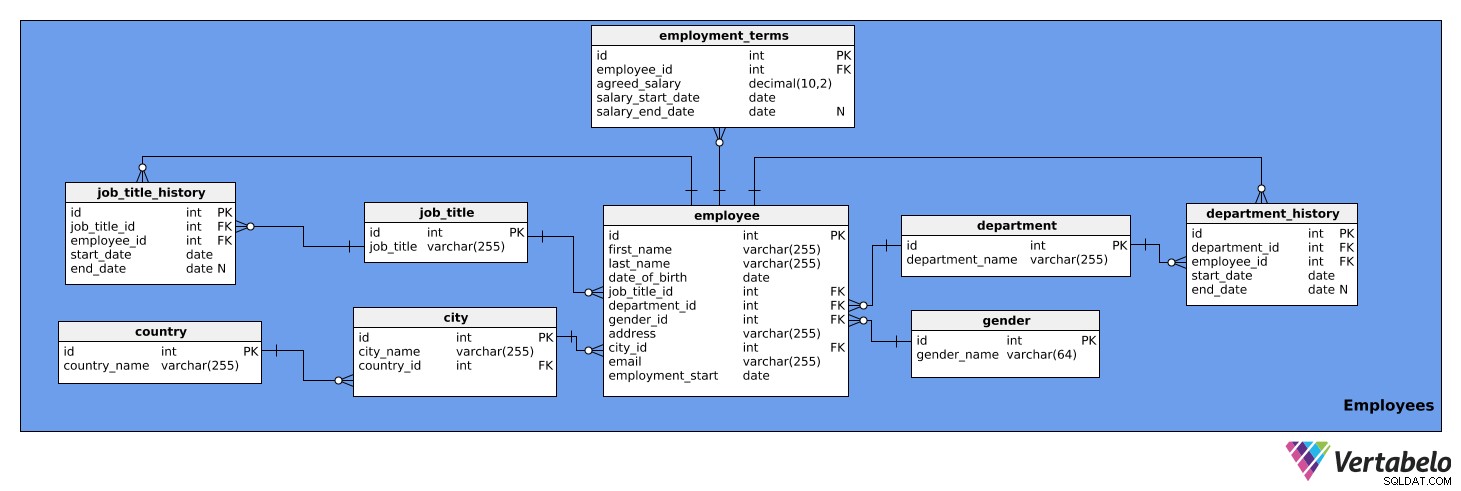
इस विषय क्षेत्र में कर्मचारियों के बारे में विस्तृत जानकारी है। इसमें नौ टेबल होते हैं:
Employeesemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
पहली तालिका जो हम देखेंगे वह है Employees टेबल। इसमें सभी कर्मचारियों और उनके प्रासंगिक विवरणों की एक सूची है। तालिका की विशेषताएं हैं:
id- प्रत्येक कर्मचारी के लिए एक विशिष्ट आईडी।first_name- कर्मचारी का पहला नाम।last_name- कर्मचारी का उपनाम।job_title_id- संदर्भjob_titleटेबल.department_id- संदर्भdepartmentटेबल.gender_id- संदर्भgenderटेबल.address- कर्मचारी का पता।city_id-cityटेबल.email- कर्मचारी का ई-मेल।employment_start- वह तारीख जब इस व्यक्ति का रोजगार शुरू हुआ।
ध्यान दें कि कॉलम job_title_id और department_id निरर्थक हैं, क्योंकि वर्तमान नौकरी के शीर्षक और विभागों के बारे में जानकारी job_title_history और department_history टेबल। हालाँकि, हम इन दो कॉलमों को जानकारी तक त्वरित पहुँच के लिए इस तालिका में रखेंगे।
employment_terms टेबल। यह प्रत्येक कर्मचारी के वेतन के बारे में डेटा संग्रहीत करता है, जैसा कि रोजगार अनुबंध में सहमति है, और यह समय के साथ कैसे बदल गया है। तालिका की विशेषताएं हैं:
id- रोज़गार शर्तों के प्रत्येक सेट के लिए एक अद्वितीय आईडी।employee_id- संदर्भEmployeesटेबल.agreed_salary- रोजगार अनुबंध में बताया गया वेतन।salary_start_date- सहमत वेतन की आरंभ तिथि।salary_end_date- सहमत वेतन की अंतिम तिथि। यह NULL हो सकता है क्योंकि वेतन में कोई नियोजित परिवर्तन नहीं हो सकता है।
job_title तालिका नौकरी के शीर्षक की एक सूची है जिसे विभिन्न कंपनी कर्मचारियों को सौंपा जा सकता है, उदा। विश्लेषक, ड्राइवर, सचिव, निदेशक, आदि। तालिका में निम्नलिखित विशेषताएं हैं:
id- प्रत्येक कार्य शीर्षक के लिए एक अद्वितीय आईडी।job_title- नौकरी का नाम शीर्षक। यह वैकल्पिक कुंजी है।
हमें प्रत्येक कर्मचारी की नौकरी के शीर्षक इतिहास को संग्रहीत करने के लिए एक तालिका की भी आवश्यकता होती है। हमें इसकी आवश्यकता है क्योंकि कर्मचारियों को कंपनी के भीतर पदोन्नत, पदावनत या पुन:असाइन किया जा सकता है। job_title_history तालिका इस जानकारी का प्रबंधन करेगी और इसमें निम्नलिखित विशेषताएं शामिल होंगी:
id- नौकरी शीर्षक ऐतिहासिक प्रविष्टि के लिए एक अद्वितीय आईडी।job_title_id- संदर्भjob_titleटेबल.employee_id- संदर्भEmployeesटेबल.start_date- जिस तारीख को कर्मचारी ने पहली बार उस नौकरी का शीर्षक धारण किया था।end_date- जब कर्मचारी के पास वह जॉब टाइटल होना बंद हो गया। यह NULL हो सकता है क्योंकि कर्मचारी वर्तमान में उस नौकरी का शीर्षक धारण कर सकता है।
job_title_id . का संयोजन , employee_id , और start_date उपरोक्त तालिका के लिए वैकल्पिक कुंजी है। एक कर्मचारी के पास किसी भी तिथि पर केवल एक ही कार्य शीर्षक सौंपा जा सकता है।
अगली तालिका है department टेबल। यह केवल कंपनी के सभी विभागों, जैसे आईटी, लेखा, कानूनी, आदि को सूचीबद्ध करेगा। इसमें दो विशेषताएं शामिल हैं:
id- प्रत्येक विभाग के लिए एक विशिष्ट आईडी।department_name- प्रत्येक विभाग का नाम। यह वैकल्पिक कुंजी है।
कर्मचारी कंपनी के भीतर विभाग भी बदल सकते हैं। इसलिए, हमारे पास एक department_history टेबल। यह तालिका निम्नलिखित को संग्रहित करेगी:
id- उस विभाग की ऐतिहासिक प्रविष्टि के लिए एक अद्वितीय आईडी।department_id- संदर्भdepartmentटेबल.employee_id- संदर्भEmployeesटेबल.start_date- जिस तारीख को किसी कर्मचारी ने विभाग में काम करना शुरू किया था।end_date- जिस तारीख को किसी कर्मचारी ने उस विभाग में काम करना बंद कर दिया था। यह NULL हो सकता है क्योंकि कर्मचारी अभी भी वहां काम कर सकता है।
department_id . का संयोजन , employee_id , और start_date वैकल्पिक कुंजी है। एक कर्मचारी एक समय में केवल एक ही विभाग में काम कर सकता है।
अगली तालिका जिसके बारे में हम बात करेंगे वह है city टेबल। यह सभी प्रासंगिक शहरों की एक सूची है। इसकी निम्नलिखित विशेषताएं हैं:
id- प्रत्येक शहर के लिए एक विशिष्ट आईडी।city_name- शहर का नाम।country_id- संदर्भcountryटेबल.
country तालिका हमारे मॉडल में आगे है। यह केवल देशों की एक सूची है और इसमें निम्नलिखित जानकारी है:
id- हर देश के लिए एक विशिष्ट आईडी।country_name- देश का नाम। यह वैकल्पिक कुंजी है।
इस विषय क्षेत्र में अंतिम तालिका gender टेबल। यह तालिका सभी लिंगों की सूची देती है। इसमें निम्नलिखित विशेषताएं शामिल हैं:
id- हर लिंग के लिए एक अद्वितीय आईडी।gender_name- लिंग का नाम।
आइए अब दूसरे विषय क्षेत्र का विश्लेषण करें।
वेतन
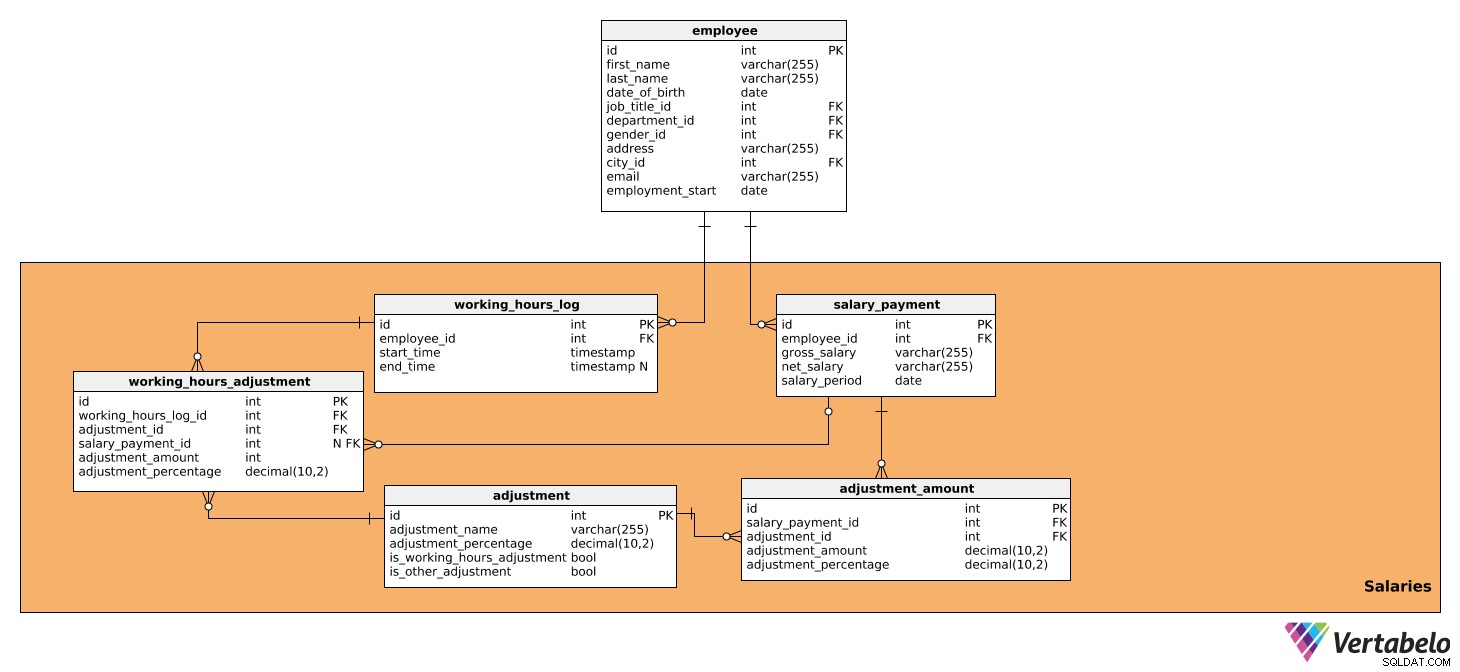
इस विषय क्षेत्र में टेबल होते हैं जिनमें सभी डेटा होते हैं जो सीधे हर अवधि के लिए वेतन गणना के साथ-साथ भुगतान की जाने वाली राशि को प्रभावित करते हैं। इसमें पाँच टेबल शामिल हैं:
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
आइए अब प्रत्येक तालिका को देखें।
पहली तालिका है salary_payment . इसमें प्रत्येक कर्मचारी को भुगतान किए गए वेतन के बारे में सभी प्रासंगिक विवरण शामिल हैं और इसमें निम्नलिखित विशेषताएं हैं:
id- प्रत्येक वेतन के लिए एक विशिष्ट आईडी।employee_id- संदर्भEmployeesटेबल.gross_salary- सकल वेतन, जो आगे के समायोजन का आधार होगा।net_salary- शुद्ध वेतन (यानी विभिन्न कटौती के बाद कर्मचारी द्वारा प्राप्त राशि)।salary_period- वह अवधि जिसके लिए वेतन की गणना और भुगतान किया जा रहा है।
दूसरा है working_hours_log टेबल। इसमें प्रत्येक कर्मचारी द्वारा काम किए गए घंटों की संख्या का डेटा होता है, जो कुछ वेतन समायोजन को प्रभावित कर सकता है। इस तालिका में निम्नलिखित विशेषताएं हैं:
id- प्रत्येक लॉग प्रविष्टि के लिए एक अद्वितीय आईडी।employee_id- संदर्भEmployeesटेबल.start_time- वह समय जब कर्मचारी ने लॉग इन किया, यानी उस दिन के लिए काम शुरू किया।end_time- जब कर्मचारी लॉग आउट हो गया। यह NULL हो सकता है क्योंकि जब तक कर्मचारी लॉग आउट नहीं करता तब तक हमें सही समय का पता नहीं चलेगा।
अगली तालिका जिसका हम विश्लेषण करेंगे वह है working_hours_adjustment . इस तालिका का उपयोग केवल काम किए गए घंटों के आधार पर समायोजन की गणना में किया जाएगा, यानी वे जिनका is_working_hours_adjustment में TRUE मान है adjustment टेबल। विशेषताएं इस प्रकार हैं:
id- प्रत्येक समायोजन के लिए एक अद्वितीय आईडी।working_hours_log_id- संदर्भworking_hours_logटेबल.adjustment_id- संदर्भadjustmentटेबल.salary_payment_id- संदर्भsalary_paymentटेबल। यह मान NULL हो सकता है क्योंकिsalary_payment_idमहीने में केवल एक बार उपयोग किया जाएगा, जब हम वेतन गणना शुरू करते हैं।adjustment_amount- समायोजन की राशि।adjustment_percentage- समायोजन की प्रतिशत राशि। इसका उपयोग ऐतिहासिक उद्देश्यों के लिए किया जाएगा, क्योंकि समय के साथ प्रतिशत बदल सकता है।
अगली तालिका जिसके बारे में हम बात करेंगे वह है adjustment टेबल। इसमें वेतन गणना के लिए उपयोग किए जाने वाले सभी समायोजनों के बारे में जानकारी शामिल है, जिसका अर्थ है कि सभी कर और योगदान जो वेतन राशि पर प्रभाव डालते हैं। साथ ही, इसमें सभी समायोजन शामिल होंगे जो काम किए गए घंटों पर निर्भर करते हैं और काम नहीं करते हैं, जैसे बोनस, ओवरटाइम, बीमार छुट्टी, और मातृत्व/पितृत्व अवकाश। उसके लिए, हमें निम्नलिखित डेटा की आवश्यकता है:
id- प्रत्येक समायोजन के लिए एक अद्वितीय आईडी।adjustment_name- उस समायोजन का वर्णन करने वाला नाम।adjustment_percentage- विशेष समायोजन की प्रतिशत राशि।is_working_hours_adjustment- यह एक फ्लैग मार्किंग है यदि समायोजन सीधे काम के घंटों पर निर्भर करता है, उदा। ओवरटाइम, बीमार छुट्टी, आदिis_other_adjustment- यह एक फ़्लैग मार्किंग समायोजन है जो नहीं . है सीधे काम के घंटों पर निर्भर करता है, जैसे कर कटौती, सामाजिक सुरक्षा योगदान, नियोक्ता योगदान, आदि।
उसके बाद, हमें adjustment_amount टेबल। इसका उपयोग पहले से ही working_hours_adjustment , यानी वे जिनका is_other_adjustment में TRUE मान है adjustment टेबल। तालिका में निम्नलिखित विशेषताएं हैं:
id- प्रत्येक समायोजन राशि प्रविष्टि के लिए एक अद्वितीय आईडी।salary_payment_id- संदर्भsalary_paymentटेबल.adjustment_id- संदर्भadjustmentटेबल.adjustment_amount- प्रत्येक परिकलित समायोजन की राशि।adjustment_percentage- समायोजन की प्रतिशत राशि। इसका उपयोग ऐतिहासिक उद्देश्यों के लिए किया जाएगा, क्योंकि समय के साथ प्रतिशत बदल सकता है।
मैं आपको एक उदाहरण देता हूं कि कैसे टेबल working_hours_log , working_hours_adjustment , adjustment , और adjustment_amount वेतन की गणना के लिए एक साथ काम करें। हर दिन, कर्मचारी लॉग इन करता है जब वह काम पर आता है और जब वह निकलता है। यह डेटा working_hours_log टेबल। मान लीजिए कि हमारे कर्मचारी ने एक महीने के लिए 10 घंटे ओवरटाइम काम किया है और, कंपनी की नीति के अनुसार, उसे हर घंटे के ओवरटाइम के लिए प्रति घंटे 20% अधिक भुगतान किया जाएगा। adjustment तालिका में, हम आवश्यक समायोजन, यानी ओवरटाइम का पता लगाने में सक्षम होंगे, जिसमें एक निश्चित प्रतिशत राशि (20%) होगी। हमारे पास is_working_hours_adjustment भी होगा TRUE पर सेट करें। उन दो तालिकाओं के डेटा का उपयोग करके, हम समायोजन की गणना करने और इसे working_hours_adjustment टेबल।
अब हम अन्य सभी समायोजनों की गणना कर सकते हैं जो नहीं काम के घंटों पर निर्भर करता है। यह adjustment_amount टेबल। जैसा कि हमने ऊपर किया था, हम adjustment तालिका और उन समायोजनों को खोजें जिनकी हमें आवश्यकता है - उदा। कर कटौती, सामाजिक सुरक्षा योगदान, या नियोक्ता योगदान - और उनके प्रासंगिक प्रतिशत। is_other_adjustment adjustment इन समायोजनों के लिए तालिका को TRUE पर सेट कर दिया जाएगा।
उन गणनाओं के आधार पर, हम सकल वेतन और शुद्ध वेतन डेटा को salary_payment टेबल।
इस उदाहरण पर जाकर, हमने अपने डेटा मॉडल में सब कुछ शामिल कर लिया है!
क्या आपको पेरोल डेटा मॉडल पसंद आया?
मैंने एक ऐसा मॉडल बनाने की कोशिश की जिसका इस्तेमाल लगभग सभी स्थितियों में किया जा सकता है। हालांकि, इस लंबाई के लेख में वेतन गणना को प्रभावित करने वाले सभी विशिष्ट मापदंडों को शामिल करना असंभव है। सामान्य सिद्धांतों को शामिल करके, मैंने इस मॉडल को आपके पेरोल डेटा मॉडल के लिए एक ठोस आधार के रूप में उपयोगी बनाने की कोशिश की है।
पेरोल डेटा मॉडल के बारे में आप क्या सोचते हैं? क्या यह आपकी पेरोल आवश्यकताओं के समाधान के रूप में लागू है? क्या आप कुछ अलग लेकर आए हैं? क्या ऐसी विशिष्ट समस्याएं हैं जो आपको मिली हैं जो डेटा मॉडल को महत्वपूर्ण रूप से बदल देंगी? कमेंट सेक्शन में अपनी बात रखें।