क्वेरी प्रदर्शन को देखते समय SQL सर्वर के भीतर जानकारी के बहुत सारे महान स्रोत होते हैं, और मेरे पसंदीदा में से एक क्वेरी योजना ही है। पिछले कई रिलीज में, विशेष रूप से SQL सर्वर 2012 से शुरू होकर, प्रत्येक नए संस्करण में निष्पादन योजनाओं में अधिक विवरण शामिल किया गया है। जबकि एन्हांसमेंट की सूची बढ़ती जा रही है, यहां कुछ विशेषताएं हैं जो मुझे मूल्यवान मिली हैं:
- NonParallelPlanReason (एसक्यूएल सर्वर 2012)
- अवशिष्ट विधेय पुशडाउन निदान (एसक्यूएल सर्वर 2012 एसपी3, एसक्यूएल सर्वर 2014 एसपी2, एसक्यूएल सर्वर 2016 एसपी1)
- tempdb स्पिल डायग्नोस्टिक्स (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- ट्रेस फ्लैग सक्षम किया गया (एसक्यूएल सर्वर 2012 एसपी4, एसक्यूएल सर्वर 2014 एसपी2, एसक्यूएल सर्वर 2016 एसपी1)
- ऑपरेटर क्वेरी निष्पादन सांख्यिकी (एसक्यूएल सर्वर 2014 एसपी2, एसक्यूएल सर्वर 2016)
- एकल क्वेरी के लिए अधिकतम मेमोरी सक्षम (SQL Server 2014 SP2, SQL Server 2016 SP1)
यह देखने के लिए कि SQL सर्वर के प्रत्येक संस्करण के लिए क्या मौजूद है, शोप्लान स्कीमा पृष्ठ पर जाएँ, जहाँ आप SQL सर्वर 2005 के बाद से प्रत्येक संस्करण के लिए स्कीमा पा सकते हैं।
जितना मुझे यह सब अतिरिक्त डेटा पसंद है, यह ध्यान रखना महत्वपूर्ण है कि कुछ जानकारी वास्तविक निष्पादन योजना के लिए अधिक प्रासंगिक है, अनुमानित एक (उदाहरण के लिए tempdb स्पिल जानकारी)। कुछ दिन हम समस्या निवारण के लिए वास्तविक योजना पर कब्जा कर सकते हैं और उसका उपयोग कर सकते हैं, दूसरी बार हमें अनुमानित योजना का उपयोग करना होगा। बहुत बार हमें वह अनुमानित योजना मिलती है - वह योजना जिसका उपयोग संभावित रूप से समस्याग्रस्त निष्पादन के लिए किया गया है - SQL सर्वर के प्लान कैश से। और किसी विशिष्ट क्वेरी या सेट या प्रश्नों को ट्यून करते समय व्यक्तिगत योजनाओं को खींचना उचित होता है। लेकिन जब आप पैटर्न के संदर्भ में अपने ट्यूनिंग प्रयासों पर ध्यान केंद्रित करने के बारे में विचार चाहते हैं तो क्या होगा?
जब प्रदर्शन ट्यूनिंग की बात आती है तो SQL सर्वर प्लान कैश सूचना का एक विलक्षण स्रोत है, और मेरा मतलब केवल समस्या निवारण और यह समझने की कोशिश नहीं है कि सिस्टम में क्या चल रहा है। इस मामले में, मैं स्वयं योजनाओं से खनन जानकारी के बारे में बात कर रहा हूं, जो sys.dm_exec_query_plan में पाई जाती हैं, जो query_plan कॉलम में XML के रूप में संग्रहीत होती हैं।
जब आप इस डेटा को sys.dm_exec_sql_text (ताकि आप आसानी से क्वेरी का टेक्स्ट देख सकें) और sys.dm_exec_query_stats (निष्पादन आँकड़े) की जानकारी के साथ जोड़ते हैं, तो आप अचानक न केवल उन प्रश्नों की तलाश शुरू कर सकते हैं जो भारी हिटर हैं या निष्पादित हैं सबसे अधिक बार, लेकिन वे योजनाएँ जिनमें एक विशेष प्रकार का जुड़ाव होता है, या सूचकांक स्कैन होता है, या जिनकी लागत सबसे अधिक होती है। इसे आमतौर पर प्लान कैश माइनिंग के रूप में जाना जाता है, और कई ब्लॉग पोस्ट हैं जो इस बारे में बात करते हैं कि यह कैसे करना है। मेरे सहयोगी, जोनाथन केहैयस कहते हैं कि उन्हें एक्सएमएल लिखने से नफरत है, फिर भी उनके पास योजना कैश खनन के लिए कई पोस्ट हैं:
- प्लान कैश से 'समानता के लिए लागत सीमा' को ट्यून करना
- प्लान कैश में निहित कॉलम रूपांतरण ढूँढना
- यह पता लगाना कि प्लान कैश में कौन सी क्वेरी एक विशिष्ट इंडेक्स का उपयोग करती हैं
- एसक्यूएल प्लान कैश में खोदना:लापता इंडेक्स ढूंढना
- प्लान कैश के अंदर मुख्य लुकअप ढूँढना
यदि आपने कभी यह पता नहीं लगाया है कि आपके प्लान कैश में क्या है, तो इन पोस्ट में क्वेरीज़ एक अच्छी शुरुआत है। हालाँकि, प्लान कैश की अपनी सीमाएँ हैं। उदाहरण के लिए, किसी क्वेरी को निष्पादित करना संभव है और योजना को कैश में नहीं जाना है। यदि आपने उदाहरण के लिए एडहॉक वर्कलोड विकल्प के लिए ऑप्टिमाइज़ किया है, तो पहले निष्पादन पर, संकलित योजना स्टब को योजना कैश में संग्रहीत किया जाता है, न कि पूर्ण संकलित योजना में। लेकिन सबसे बड़ी चुनौती यह है कि प्लान कैश अस्थायी होता है। SQL सर्वर में ऐसी कई घटनाएँ हैं जो योजना कैश को पूरी तरह से साफ़ कर सकती हैं या इसे डेटाबेस के लिए साफ़ कर सकती हैं, और योजनाओं का उपयोग न करने पर कैश से बाहर हो सकता है, या पुन:संकलन के बाद हटा दिया जा सकता है। इसका मुकाबला करने के लिए, आमतौर पर आपको या तो प्लान कैश को नियमित रूप से क्वेरी करना होगा, या सामग्री को एक निर्धारित आधार पर तालिका में स्नैपशॉट करना होगा।
यह SQL सर्वर 2016 में क्वेरी स्टोर के साथ बदलता है।
जब किसी उपयोगकर्ता डेटाबेस में क्वेरी स्टोर सक्षम होता है, तो उस डेटाबेस के विरुद्ध निष्पादित क्वेरी के लिए टेक्स्ट और प्लान आंतरिक तालिकाओं में कैप्चर और बनाए रखा जाता है। वर्तमान में जो क्रियान्वित हो रहा है, उसके अस्थायी दृष्टिकोण के बजाय, हमारे पास पहले जो क्रियान्वित किया गया है उसकी एक लंबी अवधि की तस्वीर है। बनाए रखा डेटा की मात्रा CEANUP_POLICY सेटिंग द्वारा निर्धारित की जाती है, जो डिफ़ॉल्ट रूप से 30 दिनों तक होती है। एक योजना कैश की तुलना में जो क्वेरी निष्पादन के कुछ ही घंटों का प्रतिनिधित्व कर सकता है, क्वेरी स्टोर डेटा एक गेम चेंजर है।
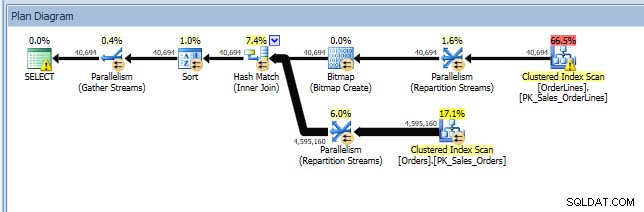
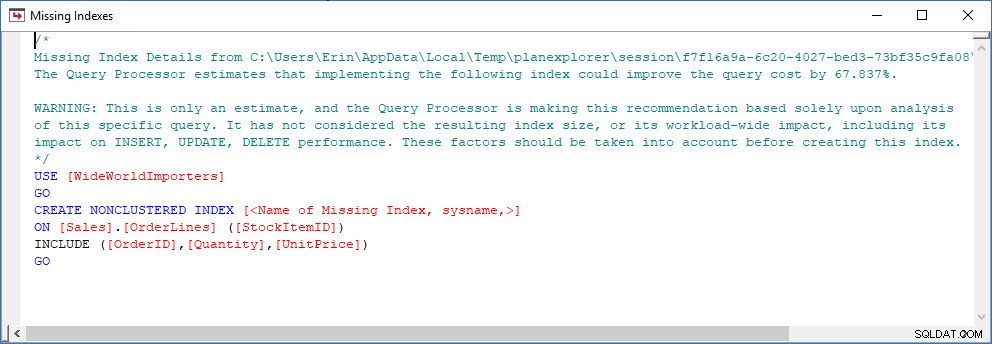
एक ऐसे परिदृश्य पर विचार करें जहां आप कुछ इंडेक्स विश्लेषण कर रहे हैं - आपके पास कुछ इंडेक्स का उपयोग नहीं किया जा रहा है, और आपके पास अनुपलब्ध इंडेक्स डीएमवी से कुछ सिफारिशें हैं। अनुपलब्ध अनुक्रमणिका DMV इस बारे में कोई विवरण प्रदान नहीं करते हैं कि किस क्वेरी ने अनुपलब्ध अनुक्रमणिका अनुशंसा उत्पन्न की। आप जोनाथन की फाइंडिंग मिसिंग इंडेक्स पोस्ट से क्वेरी का उपयोग करके प्लान कैश को क्वेरी कर सकते हैं। अगर मैं इसे अपने स्थानीय SQL सर्वर इंस्टेंस के विरुद्ध निष्पादित करता हूं, तो मुझे कुछ प्रश्नों से संबंधित आउटपुट की कुछ पंक्तियां मिलती हैं जिन्हें मैंने पहले चलाया था।

मैं प्लान एक्सप्लोरर में योजना खोल सकता हूं, और मुझे लगता है कि चयन ऑपरेटर पर एक चेतावनी है, जो लापता इंडेक्स के लिए है:
यह एक अच्छी शुरुआत है, लेकिन फिर से, मेरा आउटपुट कैश में जो कुछ भी है उस पर निर्भर करता है। मैं जोनाथन की क्वेरी ले सकता हूं और क्वेरी स्टोर के लिए संशोधित कर सकता हूं, फिर इसे अपने डेमो वाइडवर्ल्ड इम्पोर्टर्स डेटाबेस के खिलाफ चला सकता हूं:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
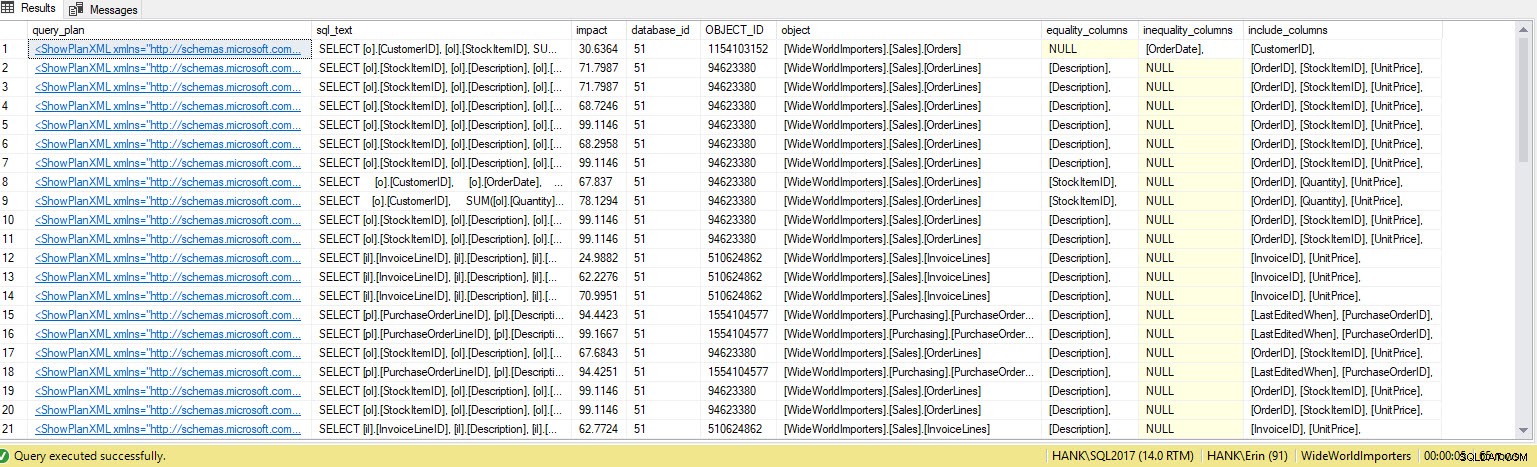
मुझे आउटपुट में कई और पंक्तियाँ मिलती हैं। फिर से, क्वेरी स्टोर डेटा सिस्टम के विरुद्ध निष्पादित प्रश्नों के एक बड़े दृश्य का प्रतिनिधित्व करता है, और इस डेटा का उपयोग करने से हमें न केवल यह निर्धारित करने के लिए एक व्यापक तरीका मिलता है कि कौन से इंडेक्स गायब हैं, लेकिन वे इंडेक्स किन प्रश्नों का समर्थन करेंगे। यहां से, हम क्वेरी स्टोर में गहराई से खुदाई कर सकते हैं और इंडेक्स बनाने के प्रभाव को समझने के लिए प्रदर्शन मेट्रिक्स और निष्पादन आवृत्ति को देख सकते हैं और यह तय कर सकते हैं कि क्या क्वेरी इंडेक्स को वारंट करने के लिए पर्याप्त रूप से निष्पादित होती है।
यदि आप क्वेरी स्टोर का उपयोग नहीं कर रहे हैं, लेकिन आप SentryOne का उपयोग कर रहे हैं, तो आप SentryOne डेटाबेस से यही जानकारी प्राप्त कर सकते हैं। क्वेरी योजना dbo.PerformanceAnalysisPlan तालिका में एक संपीड़ित प्रारूप में संग्रहीत है, इसलिए हम जिस क्वेरी का उपयोग करते हैं वह ऊपर वाले के समान भिन्नता है, लेकिन आप देखेंगे कि DECOMPRESS फ़ंक्शन का भी उपयोग किया जाता है:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; एक SentryOne सिस्टम पर मेरे पास निम्न आउटपुट था (और निश्चित रूप से किसी भी query_plan मान पर क्लिक करने से ग्राफिकल प्लान खुल जाएगा):

क्वेरी स्टोर पर सेंट्रीऑन द्वारा प्रदान किए जाने वाले कुछ लाभ यह है कि आपको प्रति डेटाबेस इस प्रकार के संग्रह को सक्षम करने की आवश्यकता नहीं है, और मॉनिटर किए गए डेटाबेस को भंडारण आवश्यकताओं का समर्थन करने की आवश्यकता नहीं है, क्योंकि सभी डेटा रिपॉजिटरी में संग्रहीत है। आप इस जानकारी को SQL सर्वर के सभी समर्थित संस्करणों में भी कैप्चर कर सकते हैं, न कि केवल वे जो क्वेरी स्टोर का समर्थन करते हैं। ध्यान दें कि SentryOne केवल उन प्रश्नों को एकत्र करता है जो थ्रेसहोल्ड से अधिक होते हैं जैसे कि अवधि और पढ़ना। आप इन डिफ़ॉल्ट थ्रेशोल्ड को बदल सकते हैं, लेकिन SentryOne डेटाबेस को माइन करते समय यह एक आइटम है:सभी प्रश्नों को एकत्र नहीं किया जा सकता है। इसके अलावा, DECOMPRESS फ़ंक्शन SQL सर्वर 2016 तक उपलब्ध नहीं है; SQL सर्वर के पुराने संस्करणों के लिए, आप या तो यह करना चाहेंगे:
- SentryOne डेटाबेस का बैकअप लें और क्वेरी चलाने के लिए इसे SQL Server 2016 या उच्चतर पर पुनर्स्थापित करें;
- डेटा को dbo.PerformanceAnalysisPlan तालिका से बाहर निकालें और इसे SQL Server 2016 इंस्टेंस पर एक नई तालिका में आयात करें;
- SentryOne डेटाबेस को SQL सर्वर 2016 इंस्टेंस से लिंक किए गए सर्वर के माध्यम से क्वेरी करें; या,
- एप्लिकेशन कोड से डेटाबेस को क्वेरी करें जो डीकंप्रेसिंग के बाद विशिष्ट चीजों के लिए पार्स कर सकता है।
SentryOne के साथ, आपके पास न केवल प्लान कैश को माइन करने की क्षमता है, बल्कि SentryOne रिपॉजिटरी के भीतर रखे गए डेटा को भी रखने की क्षमता है। यदि आप SQL सर्वर 2016 या उच्चतर चला रहे हैं, और आपके पास क्वेरी स्टोर सक्षम है, तो आप यह जानकारी sys.query_store_plan में भी प्राप्त कर सकते हैं . आप लापता इंडेक्स खोजने के इस उदाहरण तक ही सीमित नहीं हैं; जोनाथन के अन्य प्लान कैश पोस्ट के सभी प्रश्नों को सेंट्रीऑन या क्वेरी स्टोर से डेटा माइन करने के लिए उपयोग करने के लिए संशोधित किया जा सकता है। इसके अलावा, यदि आप XQuery (या सीखने के इच्छुक) से पर्याप्त रूप से परिचित हैं, तो आप शोप्लान स्कीमा का उपयोग करके यह पता लगा सकते हैं कि अपनी इच्छित जानकारी को खोजने के लिए योजना को कैसे पार्स किया जाए। यह आपको आपकी क्वेरी योजनाओं में पैटर्न और विरोधी पैटर्न खोजने की क्षमता देता है, जिसे आपकी टीम समस्या बनने से पहले ठीक कर सकती है।