मैंने संक्षेप में उल्लेख किया है कि बैच मोड डेटा सामान्यीकृत है मेरे पिछले लेख में SQL सर्वर में बैच मोड बिटमैप्स। बैच में सभी डेटा को इस विशेष सामान्यीकृत प्रारूप में आठ-बाइट मान द्वारा दर्शाया जाता है, चाहे अंतर्निहित डेटा प्रकार कुछ भी हो।
यह कथन निस्संदेह कुछ प्रश्न उठाता है, कम से कम इस बारे में नहीं कि आठ बाइट्स से अधिक लंबाई वाले डेटा को संभवतः इस तरह कैसे संग्रहीत किया जा सकता है। यह आलेख बैच डेटा सामान्यीकृत प्रतिनिधित्व की पड़ताल करता है, बताता है कि सभी आठ-बाइट डेटा प्रकार 64 बिट्स के भीतर फ़िट क्यों नहीं हो सकते हैं, और यह एक उदाहरण दिखाता है कि यह सब बैच-मोड प्रदर्शन को कैसे प्रभावित करता है।
डेमो
मैं एक उदाहरण के साथ शुरू करने जा रहा हूं जो बैच डेटा प्रारूप को निष्पादन योजना में महत्वपूर्ण अंतर दिखाता है। यहां दिखाए गए परिणामों को पुन:पेश करने के लिए आपको SQL सर्वर 2016 (या बाद में) और डेवलपर संस्करण (या समकक्ष) की आवश्यकता होगी।
पहली चीज़ जो हमें चाहिए वह है bigint . की एक तालिका संख्या 1 से 102,400 तक समावेशी। इन नंबरों का उपयोग शीघ्र ही एक कॉलमस्टोर तालिका को पॉप्युलेट करने के लिए किया जाएगा (एक संपीड़ित खंड प्राप्त करने के लिए पंक्तियों की संख्या न्यूनतम आवश्यक है)।
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); सफल कुल पुशडाउन
निम्न स्क्रिप्ट एक अन्य तालिका बनाने के लिए संख्या तालिका का उपयोग करती है जिसमें समान संख्याएं एक विशिष्ट मान से ऑफसेट होती हैं। बाद में बैच मोड निष्पादन उत्पन्न करने के लिए यह तालिका अपने प्राथमिक भंडारण के लिए कॉलमस्टोर का उपयोग करती है।
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); नई कॉलमस्टोर तालिका में निम्नलिखित परीक्षण क्वेरी चलाएँ:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
<उप>SUM के अंदर जोड़ अतिप्रवाह से बचने के लिए है। आप WHERE . को छोड़ सकते हैं यदि आप SQL Server 2017 चला रहे हैं तो खंड (एक तुच्छ योजना से बचने के लिए)।
उन सभी प्रश्नों को कुल पुशडाउन से लाभ होता है। समुच्चय की गणना Columnstore अनुक्रमणिका स्कैन . पर की जाती है बैच-मोड के बजाय हैश एग्रीगेट ऑपरेटर। निष्पादन के बाद की योजनाएँ स्कैन द्वारा उत्सर्जित शून्य पंक्तियाँ दिखाती हैं। सभी 102,400 पंक्तियों को 'स्थानीय रूप से एकत्रित' किया गया था।
SUM योजना नीचे एक उदाहरण के रूप में दिखाई गई है:

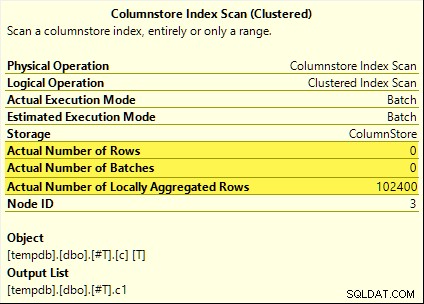
असफल एग्रीगेट पुशडाउन
अब ड्रॉप करें और फिर कॉलमस्टोर टेस्ट टेबल को ऑफसेट के साथ एक से कम करके फिर से बनाएं:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); पहले की तरह ही समग्र पुशडाउन परीक्षण क्वेरी चलाएँ:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
इस बार, केवल COUNT_BIG एग्रीगेट एग्रीगेट पुशडाउन प्राप्त करता है (केवल SQL सर्वर 2017)। MAX और SUM समुच्चय नहीं करते हैं। ये रहा नया SUM पहले परीक्षण से तुलना करने की योजना:

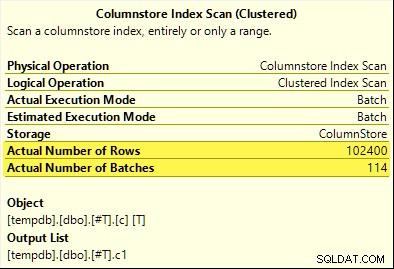
सभी 102,400 पंक्तियां (114 बैचों में) कॉलमस्टोर इंडेक्स स्कैन द्वारा उत्सर्जित होती हैं , कंप्यूट स्केलर . द्वारा संसाधित किया जाता है , और हैश एग्रीगेट . को भेजा गया ।
अंतर क्यों? हमने केवल कॉलमस्टोर तालिका में संग्रहीत संख्याओं की श्रेणी को एक-एक करके ऑफसेट करना था!
स्पष्टीकरण
मैंने परिचय में उल्लेख किया है कि सभी आठ-बाइट डेटा प्रकार 64 बिट्स में फिट नहीं हो सकते हैं। यह तथ्य महत्वपूर्ण है क्योंकि कई कॉलमस्टोर और बैच मोड प्रदर्शन अनुकूलन केवल 64 बिट आकार के डेटा के साथ काम करते हैं। कुल पुशडाउन उन चीजों में से एक है। कई और प्रदर्शन विशेषताएं हैं (सभी दस्तावेज नहीं हैं) जो सबसे अच्छा काम करती हैं (या बिल्कुल भी) जब डेटा 64 बिट्स में फिट बैठता है।
हमारे विशिष्ट उदाहरण में, कुल पुशडाउन अक्षम है कॉलमस्टोर सेगमेंट के लिए जब इसमें यहां तक कि एक हो डेटा मान जो 64 बिट में फ़िट नहीं होता है। SQL सर्वर सभी डेटा की जाँच किए बिना प्रत्येक सेगमेंट से जुड़े न्यूनतम और अधिकतम मूल्य मेटाडेटा से इसे निर्धारित कर सकता है। प्रत्येक खंड का अलग से मूल्यांकन किया जाता है।
कुल पुशडाउन अभी भी COUNT_BIG . के लिए काम करता है केवल दूसरे टेस्ट में कुल। यह SQL सर्वर 2017 में किसी बिंदु पर जोड़ा गया एक अनुकूलन है (मेरे परीक्षण CU16 पर चलाए गए थे)। जब हम केवल पंक्तियों की गिनती कर रहे हैं, और विशिष्ट डेटा मानों के साथ कुछ नहीं कर रहे हैं, तो कुल पुशडाउन को अक्षम नहीं करना तर्कसंगत है। मुझे इस सुधार के लिए कोई दस्तावेज नहीं मिला, लेकिन आजकल यह इतना असामान्य नहीं है।
एक साइड नोट के रूप में, मैंने देखा कि SQL Server 2017 CU16 पहले से असमर्थित डेटा प्रकारों real के लिए कुल पुशडाउन सक्षम करता है , float , datetimeoffset , और numeric 18 से अधिक सटीकता के साथ - जब डेटा 64 बिट्स में फिट बैठता है। यह भी लेखन के समय अनिर्दिष्ट है।
ठीक है, लेकिन क्यों?
आप बहुत ही उचित प्रश्न पूछ रहे होंगे:bigint . का एक सेट क्यों करता है? परीक्षण मान 64 बिट्स में स्पष्ट रूप से फिट होते हैं लेकिन अन्य नहीं करते हैं?
अगर आपको लगता है कि इसका कारण NULL . से संबंधित था , अपने आप को एक टिक दें। भले ही टेस्ट टेबल कॉलम को NOT NULL के रूप में परिभाषित किया गया हो , SQL सर्वर bigint . के लिए समान सामान्यीकृत डेटा लेआउट का उपयोग करता है डेटा नल की अनुमति देता है या नहीं। इसके कुछ कारण हैं, जिन्हें मैं थोड़ा-थोड़ा करके खोलूंगा।
मैं कुछ टिप्पणियों के साथ शुरू करता हूं:
- एक बैच में प्रत्येक स्तंभ मान अंतर्निहित डेटा प्रकार की परवाह किए बिना ठीक आठ बाइट्स (64 बिट) में संग्रहीत किया जाता है। यह निश्चित आकार का लेआउट सब कुछ आसान और तेज बनाता है। बैच मोड निष्पादन गति के बारे में है।
- एक बैच 64KB आकार का होता है और इसमें 64 और 900 पंक्तियों के बीच होता है, जो अनुमानित किए जा रहे स्तंभों की संख्या पर निर्भर करता है। यह समझ में आता है कि कॉलम डेटा आकार 64 बिट्स पर तय किए गए हैं। अधिक कॉलम का अर्थ है कि प्रत्येक 64KB बैच में कम पंक्तियाँ फ़िट हो सकती हैं।
- सभी SQL सर्वर डेटा प्रकार सिद्धांत रूप में भी 64 बिट्स में फ़िट नहीं हो सकते हैं। एक लंबी स्ट्रिंग (एक उदाहरण लेने के लिए) पूरे 64KB बैच में भी फिट नहीं हो सकती है (यदि इसकी अनुमति थी), तो केवल एक 64-बिट प्रविष्टि को छोड़ दें।
SQL सर्वर 8-बाइट संदर्भ को संग्रहीत करके इस अंतिम समस्या को हल करता है 64 बिट से बड़े डेटा के लिए। 'बड़ा' डेटा मान स्मृति में कहीं और संग्रहीत किया जाता है। आप इस व्यवस्था को "ऑफ-रो" या "आउट-ऑफ-बैच" स्टोरेज कह सकते हैं। आंतरिक रूप से इसे गहरा डेटा . कहा जाता है ।
अब, आठ-बाइट डेटा प्रकार अशक्त होने पर 64 बिट्स में फिट नहीं हो सकते। bigint NULL लें उदाहरण के लिए । गैर-शून्य डेटा श्रेणी को पूर्ण 64 बिट्स की आवश्यकता हो सकती है, और हमें अभी भी शून्य या नहीं इंगित करने के लिए एक और बिट की आवश्यकता है।
समस्याओं का समाधान
इन चुनौतियों का रचनात्मक और कुशल समाधान सबसे कम महत्वपूर्ण बिट आरक्षित करना . है (LSB) 64-बिट मान का ध्वज के रूप में। ध्वज इन-बैच . इंगित करता है LSB साफ़ होने पर डेटा संग्रहण (शून्य पर सेट)। जब एलएसबी सेट . हो (एक से), इसका मतलब दो चीजों में से एक हो सकता है:
- मान शून्य है; या
- मान ऑफ-बैच स्टोर किया जाता है (यह डीप डेटा है)।
इन दो मामलों को शेष 63 बिट्स की स्थिति से अलग किया जाता है। जब वे बिल्कुल शून्य . हों , मान NULL है . अन्यथा, 'मान' कहीं और संग्रहीत गहरे डेटा का सूचक है।
जब एक पूर्णांक के रूप में देखा जाता है, तो LSB को सेट करने का अर्थ है कि गहरे डेटा के सूचक हमेशा विषम होंगे संख्याएं। नल (विषम) संख्या 1 (अन्य सभी बिट शून्य हैं) द्वारा दर्शाए जाते हैं। इन-बैच डेटा सम . द्वारा दर्शाया जाता है संख्याएं क्योंकि एलएसबी शून्य है।
यह नहीं करता है इसका मतलब है कि SQL सर्वर केवल एक बैच के भीतर सम संख्याएँ संग्रहीत कर सकता है! इसका सीधा सा मतलब है कि सामान्यीकृत प्रतिनिधित्व "इन-बैच" संग्रहीत होने पर अंतर्निहित कॉलम मानों में हमेशा शून्य एलएसबी होगा। यह एक पल में और अधिक समझ में आएगा।
बैच डेटा सामान्यीकरण
अंतर्निहित डेटा प्रकार के आधार पर, सामान्यीकरण विभिन्न तरीकों से किया जाता है। bigint . के लिए प्रक्रिया है:
- यदि डेटा शून्य है , मान 1 स्टोर करें (केवल एलएसबी सेट)।
- यदि मान को 63 बिट्स में दर्शाया जा सकता है , सभी बिट्स को एक जगह बाईं ओर शिफ्ट करें और एलएसबी को शून्य करें। मान को पूर्णांक के रूप में देखते समय, इसका अर्थ है दोगुना मूल्य। उदाहरण के लिए
bigintमान 1 को मान 2 के लिए सामान्यीकृत किया जाता है। बाइनरी में, यानी सात पूर्ण-शून्य बाइट्स और उसके बाद00000010. एलएसबी शून्य होना इंगित करता है कि यह डेटा इनलाइन संग्रहीत है। जब SQL सर्वर को मूल मान की आवश्यकता होती है, तो यह 64-बिट मान को एक स्थिति (LSB ध्वज को फेंक कर) से राइट-शिफ्ट करता है। - यदि मान नहीं 63 बिट्स में प्रदर्शित किया जा सकता है, मान को ऑफ-बैच के रूप में डीप डेटा . के रूप में संग्रहीत किया जाता है . इन-बैच पॉइंटर में एलएसबी सेट होता है (इसे विषम संख्या बनाता है)।
परीक्षण की प्रक्रिया यदि कोई bigint . है मान 63 बिट में फ़िट हो सकता है:
- कच्चा स्टोर करें*
bigint64-बिट प्रोसेसर रजिस्टर में मानr8। r8के मान को दोगुना स्टोर करें रजिस्टर मेंrax।raxके बिट्स को शिफ्ट करें एक जगह दाईं ओर।- जांचें कि क्या
raxमें मान हैं औरr8बराबर हैं।
<उप>* नोट करें कि कच्चे मान को सभी डेटा प्रकारों के लिए एक बाइनरी प्रकार में टी-एसक्यूएल रूपांतरण द्वारा विश्वसनीय रूप से निर्धारित नहीं किया जा सकता है। टी-एसक्यूएल परिणाम में एक अलग बाइट ऑर्डर हो सकता है और इसमें मेटाडेटा भी हो सकता है उदा। time भिन्नात्मक दूसरी परिशुद्धता।
यदि चरण 4 में परीक्षण पास हो जाता है, तो हम जानते हैं कि मान को दोगुना किया जा सकता है और फिर 64 बिट्स के भीतर आधा किया जा सकता है - मूल मान को संरक्षित करते हुए।
एक कम की गई रेंज
इन सबका नतीजा यह है कि bigint . की रेंज बैच में संग्रहीत किए जा सकने वाले मान कम हैं एक बिट से (क्योंकि एलएसबी उपलब्ध नहीं है)। bigint . की निम्नलिखित समावेशी श्रेणियां मानों को ऑफ-बैच डीप डेटा . के रूप में संग्रहीत किया जाएगा :
- -4,611,686,018,427,387,905 से -9,223,372,036,854,775,808
- +4,611,686,018,427,387,904 से +9,223,372,036,854,775,807
यह स्वीकार करने के बदले में ये bigint सीमा सीमा, सामान्यीकरण SQL सर्वर को (अधिकांश) bigint store स्टोर करने की अनुमति देता है मान, शून्य और गहन डेटा संदर्भ इन-बैच . यह अशक्तता और गहरे डेटा संदर्भों के लिए अलग-अलग संरचना होने की तुलना में बहुत सरल और अधिक स्थान-कुशल है। यह SIMD प्रोसेसर निर्देशों के साथ बैच डेटा को संसाधित करना भी बहुत आसान बनाता है।
अन्य डेटा प्रकारों का सामान्यीकरण
SQL सर्वर में सामान्यीकरण शामिल है बैच मोड निष्पादन द्वारा समर्थित प्रत्येक डेटा प्रकार के लिए कोड। प्रत्येक रूटीन को आने वाले बाइनरी लेआउट को कुशलतापूर्वक संभालने के लिए अनुकूलित किया गया है, और केवल आवश्यक होने पर ही गहरा डेटा बनाने के लिए अनुकूलित किया गया है। सामान्यीकरण के परिणामस्वरूप हमेशा एलएसबी को शून्य या गहरे डेटा को इंगित करने के लिए आरक्षित किया जाता है, लेकिन शेष 63 बिट्स का लेआउट प्रति डेटा प्रकार में भिन्न होता है।
हमेशा इन-बैच
निम्न डेटा प्रकारों के लिए सामान्यीकृत डेटा हमेशा बैच में संग्रहीत होता है चूँकि उन्हें कभी भी 63 बिट से अधिक की आवश्यकता नहीं होती है:
datetime(n)- आंतरिक रूप सेtime(7). पर पुन:स्केल किया गयाdatetime2(n)- आंतरिक रूप सेdatetime2(7). पर पुन:स्केल किया गयाintegersmallinttinyintbit-tinyintका उपयोग करता है कार्यान्वयन।-
smalldatetime datetimerealfloatsmallmoney
यह निर्भर करता है
निम्न डेटा प्रकार इन-बैच या डीप डेटा संग्रहीत किए जा सकते हैं डेटा मान के आधार पर:
bigint- जैसा कि पहले बताया गया है।money- बैच मेंbigint. के समान श्रेणी लेकिन 10,000 से विभाजित।numeric/decimal- 18 दशमलव अंक या उससे कम इन-बैच चाहे घोषित सटीकता की। उदाहरण के लिएdecimal(38,9)मान -999999999.999999999 को 8 बाइट पूर्णांक के रूप में दर्शाया जा सकता है -999999999999999999 (f21f494c589c0001hex), जिसे दोगुना करके -1999999999999999998 किया जा सकता है (e43e9298b1380002hex) प्रतिवर्ती रूप से 64 बिट के भीतर। SQL सर्वर जानता है कि दशमलव बिंदु डेटा प्रकार के पैमाने से कहाँ जाता है।datetimeoffset(n)- बैच में यदि रनटाइम मानdatetimeoffset(2)में फ़िट हो जाएगा भले ही घोषित भिन्नात्मक सेकंड की सटीकता।timestamp- इंटरनल फॉर्मेट डिस्प्ले से अलग है। उदाहरण के लिए एकtimestampT-SQL से0x000000000099449A. के रूप में प्रदर्शित होता है आंतरिक रूप से9a449900 00000000. के रूप में दर्शाया गया है (हेक्स में)। यह मान डीप डेटा के रूप में संग्रहीत किया जाता है क्योंकि यह दोगुना होने पर 64-बिट में फ़िट नहीं होता है (बाएं-शिफ्ट एक बिट)।
हमेशा गहरा डेटा
निम्नलिखित हमेशा डीप डेटा के रूप में संग्रहीत होते हैं (नल को छोड़कर) :
uniqueidentifiervarbinary(n)-(max)सहितbinarychar/varchar(n)/nchar/nvarchar(n)/sysname(max). सहित - ये प्रकार एक शब्दकोश (जब उपलब्ध हो) का भी उपयोग कर सकते हैं।text/ntext/image/xml-varbinary(n). का उपयोग करता है कार्यान्वयन।
स्पष्ट होने के लिए, सभी . के लिए शून्य बैच-मोड संगत डेटा प्रकारों को विशेष मान 'एक' के रूप में इन-बैच में संग्रहीत किया जाता है।
अंतिम विचार
64 बिट्स में फिट होने वाले डेटा प्रकारों और मानों का उपयोग करते समय आप उपलब्ध कॉलमस्टोर और बैच मोड ऑप्टिमाइज़ेशन का सर्वोत्तम उपयोग करने की उम्मीद कर सकते हैं। आपके पास समय के साथ वृद्धिशील उत्पाद सुधारों से लाभान्वित होने का सबसे अच्छा मौका होगा, उदाहरण के लिए मुख्य पाठ में नोट किए गए कुल पुशडाउन में नवीनतम सुधार। निष्पादन योजनाओं में सभी प्रदर्शन लाभ इतने दृश्यमान नहीं होंगे, या यहां तक कि प्रलेखित भी नहीं होंगे। फिर भी, मतभेद अत्यंत महत्वपूर्ण हो सकते हैं।
मुझे यह भी उल्लेख करना चाहिए कि डेटा सामान्यीकृत होता है जब एक पंक्ति-मोड निष्पादन योजना ऑपरेटर बैच-मोड माता-पिता को डेटा प्रदान करता है, या जब एक गैर-कॉलमस्टोर स्कैन बैच उत्पन्न करता है (रोस्टोर पर बैच मोड)। एक अदृश्य पंक्ति-से-बैच एडेप्टर है जो बैच में जोड़ने से पहले प्रत्येक कॉलम मान पर उपयुक्त सामान्यीकरण रूटीन को कॉल करता है। जटिल सामान्यीकरण और गहन डेटा संग्रहण वाले डेटा प्रकारों से बचने से यहां भी प्रदर्शन लाभ मिल सकते हैं।