क्या आपको कभी ऐसी स्थिति का सामना करना पड़ा है जहां आपको समय के साथ बदलने वाली इकाई की स्थिति को प्रबंधित करने की आवश्यकता होती है? वहाँ कई उदाहरण हैं। आइए एक आसान से शुरू करें:ग्राहक रिकॉर्ड मर्ज करना।
मान लीजिए कि हम दो अलग-अलग स्रोतों से ग्राहकों की सूची मर्ज कर रहे हैं। हम निम्नलिखित में से कोई भी राज्य उत्पन्न कर सकते हैं:डुप्लिकेट की पहचान की गई - सिस्टम को दो संभावित डुप्लिकेट निकाय मिले हैं; पुष्टि किए गए डुप्लीकेट - एक उपयोगकर्ता पुष्टि करता है कि दो इकाइयां वास्तव में डुप्लीकेट हैं; या अद्वितीय पुष्टि की गई - उपयोगकर्ता तय करता है कि दो इकाइयाँ अद्वितीय हैं। इनमें से किसी भी स्थिति में, उपयोगकर्ता के पास केवल हां-ना का निर्णय लेने का होता है।
लेकिन अधिक जटिल स्थितियों के बारे में क्या? क्या राज्यों के बीच वास्तविक कार्यप्रवाह को परिभाषित करने का कोई तरीका है? आगे पढ़ें…
कैसे चीजें आसानी से गलत हो सकती हैं
कई संगठनों को नौकरी के आवेदनों का प्रबंधन करने की आवश्यकता है। एक साधारण मॉडल में, आपके पास JOB_APPLICATION , और आप इस तरह के मानों वाली संदर्भ डेटा तालिका का उपयोग करके एप्लिकेशन की स्थिति को ट्रैक कर सकते हैं:
| आवेदन की स्थिति |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
इन मानों को किसी भी समय किसी भी क्रम में चुना जा सकता है। यह सुनिश्चित करने के लिए अंतिम उपयोगकर्ताओं पर निर्भर करता है कि प्रत्येक चरण में एक तार्किक और सही चयन किया जाता है। कुछ भी राज्यों के एक अतार्किक अनुक्रम को प्रतिबंधित नहीं करता है।
उदाहरण के लिए, मान लीजिए कि एक आवेदन खारिज कर दिया गया है। स्पष्ट रूप से वर्तमान स्थिति APPLICATION_REJECTED . होगी . एक अनुभवहीन उपयोगकर्ता को बाद में INVITED_TO_INTERVIEW चुनने से रोकने के लिए एप्लिकेशन स्तर पर कुछ भी नहीं किया जा सकता है। या कोई अन्य अतार्किक स्थिति।
उपयोगकर्ता को अगली तार्किक स्थिति चुनने में मार्गदर्शन करने के लिए कुछ की आवश्यकता है, कुछ ऐसा जो एक तार्किक कार्यप्रवाह को परिभाषित करता है ।
और क्या होगा यदि आपके पास विभिन्न प्रकार के नौकरी अनुप्रयोगों के लिए अलग-अलग आवश्यकताएं हैं? उदाहरण के लिए, कुछ नौकरियों के लिए आवेदक को एप्टीट्यूड टेस्ट देना पड़ सकता है। निश्चित रूप से, आप इन्हें कवर करने के लिए सूची में अधिक मान जोड़ सकते हैं, लेकिन वर्तमान डिज़ाइन में ऐसा कुछ भी नहीं है जो अंतिम उपयोगकर्ता को प्रश्न में एप्लिकेशन के प्रकार के लिए गलत चयन करने से रोकता है। वास्तविकता यह है कि विभिन्न कार्यप्रवाह . हैं विभिन्न संदर्भों . के लिए ।
विचार करने के लिए एक और बिंदु:क्या सूचीबद्ध विकल्प वास्तव में सभी राज्यों हैं? ? या वास्तव में कुछ हैं परिणाम ? उदाहरण के लिए, आवेदक द्वारा नौकरी के प्रस्ताव को स्वीकार या अस्वीकार किया जा सकता है। इसलिए, JOB_OFFER_MADE वास्तव में इसके दो परिणाम हैं:JOB_OFFER_ACCEPTED और JOB_OFFER_DECLINED ।
एक और परिणाम यह हो सकता है कि नौकरी की पेशकश वापस ले ली जाए। क्वालीफायर का उपयोग करके इसे वापस लेने का कारण आप रिकॉर्ड करना चाह सकते हैं। यदि आप इन कारणों को उपरोक्त सूची में जोड़ते हैं, तो कुछ भी अंतिम उपयोगकर्ता को तार्किक चयन करने में मार्गदर्शन नहीं करता है।
तो वास्तव में, जितने अधिक जटिल राज्य, परिणाम और क्वालीफायर बनते हैं, उतना ही आपको कार्यप्रवाह को परिभाषित करने की आवश्यकता होती है एक प्रक्रिया . का ।
प्रक्रियाओं, राज्यों और परिणामों को व्यवस्थित करना
इससे पहले कि आप इसे मॉडल करने का प्रयास करें, यह समझना महत्वपूर्ण है कि आपके डेटा के साथ क्या हो रहा है। आप पहले यह सोचने के इच्छुक हो सकते हैं कि यहाँ प्रकारों का एक सख्त पदानुक्रम है:
जब हम उपरोक्त उदाहरण को करीब से देखते हैं, तो हम देखते हैं कि INVITED_TO_INTERVIEW और JOB_OFFER_MADE राज्य समान संभावित परिणाम साझा करते हैं, अर्थात् ACCEPTED और DECLINED . यह हमें बताता है कि अनेक-से-अनेक संबंध . है राज्यों और परिणामों के बीच। यह अक्सर अन्य राज्यों, परिणामों और क्वालीफायर के लिए सच होता है।
वैचारिक स्तर पर, वास्तव में हमारे मेटाडेटा के साथ यही हो रहा है:
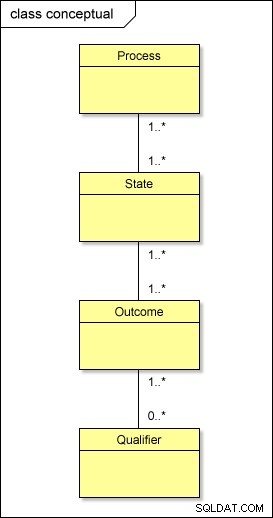
यदि आप मानक दृष्टिकोण का उपयोग करके इस मॉडल को भौतिक दुनिया में बदलना चाहते हैं, तो आपके पास PROCESS , STATE , OUTCOME , और QUALIFIER; आपको मध्यवर्ती तालिकाओं की भी आवश्यकता होगी उनके बीच - PROCESS_STATE , STATE_OUTCOME , और OUTCOME_QUALIFIER - अनेक-से-अनेक संबंधों को हल करने के लिए . यह डिज़ाइन को जटिल बनाता है।
जबकि स्तरों के तार्किक पदानुक्रम (प्रक्रिया → स्थिति → परिणाम → क्वालीफायर) को बनाए रखा जाना चाहिए, हमारे मेटाडेटा को भौतिक रूप से व्यवस्थित करने का एक सरल तरीका है।
कार्यप्रवाह पैटर्न
नीचे दिया गया आरेख वर्कफ़्लो डेटाबेस मॉडल के मुख्य घटकों को परिभाषित करता है:
बाईं ओर की पीली तालिकाओं में कार्यप्रवाह मेटाडेटा होता है, और दाईं ओर की नीली तालिकाओं में व्यावसायिक डेटा होता है।
ध्यान देने वाली पहली बात यह है कि किसी भी इकाई को प्रबंधित किया जा सकता है इस मॉडल में बड़े बदलाव की आवश्यकता के बिना। YOUR_ENTITIY_TO_MANAGE तालिका कार्यप्रवाह प्रबंधन के अंतर्गत एक है। हमारे उदाहरण के संदर्भ में, यह JOB_APPLICATION टेबल।
इसके बाद, हमें बस wf_state_type_process_id . जोड़ना होगा हम जिस भी टेबल को मैनेज करना चाहते हैं, उस पर कॉलम। यह कॉलम वास्तविक कार्यप्रवाह प्रक्रिया की ओर इशारा करता है इकाई का प्रबंधन करने के लिए इस्तेमाल किया जा रहा है। यह कड़ाई से एक विदेशी कुंजी कॉलम नहीं है, लेकिन यह हमें WORKFLOW_STATE_TYPE को तुरंत क्वेरी करने की अनुमति देता है सही प्रक्रिया के लिए। वह तालिका जिसमें राज्य का इतिहास . होगा है MANAGED_ENTITY_STATE . दोबारा, आप यहां अपना विशिष्ट तालिका नाम चुनेंगे और अपनी आवश्यकताओं के लिए इसे संशोधित करेंगे।
मेटाडेटा
कार्यप्रवाह के विभिन्न स्तरों को WORKFLOW_LEVEL_TYPE . इस तालिका में निम्नलिखित शामिल हैं:
| कुंजी टाइप करें | <थ>विवरण|
|---|---|
| प्रक्रिया | उच्च स्तरीय कार्यप्रवाह प्रक्रिया। |
| राज्य | एक राज्य प्रक्रिया में है। |
| परिणाम | किसी राज्य का अंत कैसे होता है, उसका परिणाम। |
| क्वालिफायर | परिणाम के लिए एक वैकल्पिक, अधिक विस्तृत क्वालीफायर। |
WORKFLOW_STATE_TYPE और WORKFLOW_STATE_HIERARCHY एक उत्कृष्ट सामग्री बिल (बीओएम) संरचना बनाएं . यह संरचना, जो सामग्री के वास्तविक निर्माण बिल का बहुत वर्णनात्मक है, डेटा मॉडलिंग में काफी सामान्य है। यह पदानुक्रम को परिभाषित कर सकता है या कई पुनरावर्ती स्थितियों पर लागू किया जा सकता है। हम यहां इसका उपयोग प्रक्रियाओं, राज्यों, परिणामों और वैकल्पिक क्वालिफायर के हमारे तार्किक पदानुक्रम को परिभाषित करने के लिए करने जा रहे हैं।
इससे पहले कि हम एक पदानुक्रम को परिभाषित कर सकें, हमें अलग-अलग घटकों को परिभाषित करने की आवश्यकता है। ये हमारे बुनियादी निर्माण खंड हैं। मैं इन्हें TYPE_KEY . द्वारा संदर्भित करने जा रहा हूं (जो अद्वितीय है) संक्षिप्तता के लिए। हमारे उदाहरण के लिए, हमारे पास है:
| कार्यप्रवाह स्तर प्रकार | कार्यप्रवाह स्थिति प्रकार.कुंजी प्रकार |
|---|---|
| परिणाम | पास |
| परिणाम | विफल |
| परिणाम | स्वीकृत |
| परिणाम | अस्वीकार किया गया |
| परिणाम | CANDIDATE_CANCELLED |
| परिणाम | EMPLOYER_CANCELLED |
| परिणाम | अस्वीकृत |
| परिणाम | EMPLOYER_WITHDRAWN |
| परिणाम | NO_SHOW |
| परिणाम | किराए पर लिया |
| परिणाम | NOT_HIRED |
| राज्य | APPLICATION_RECEIVED |
| राज्य | APPLICATION_REVIEW |
| राज्य | INVITED_TO_INTERVIEW |
| राज्य | साक्षात्कार |
| राज्य | TEST_APTITUDE |
| राज्य | SEEK_REFERENCES |
| राज्य | MAKE_OFFER |
| राज्य | APPLICATION_CLOSED |
| प्रक्रिया | STANDARD_JOB_APPLICATION |
| प्रक्रिया | TECHNICAL_JOB_APPLICATION |
अब हम अपने पदानुक्रम को परिभाषित करना शुरू कर सकते हैं। यह वह जगह है जहां हम अपने बिल्डिंग ब्लॉक लेते हैं और अपनी संरचना को परिभाषित करते हैं। प्रत्येक राज्य के लिए, हम संभावित परिणामों को परिभाषित करते हैं। वास्तव में, यह इस वर्कफ़्लो सिस्टम का एक नियम है कि प्रत्येक राज्य को समाप्त होना चाहिए परिणाम के साथ:
| माता-पिता का प्रकार - राज्य | बच्चे का प्रकार - परिणाम |
|---|---|
| APPLICATION_RECEIVED | स्वीकृत |
| APPLICATION_RECEIVED | अस्वीकृत |
| APPLICATION_REVIEW | पास |
| APPLICATION_REVIEW | विफल |
| INVITED_TO_INTERVIEW | स्वीकृत |
| INVITED_TO_INTERVIEW | अस्वीकार किया गया |
| साक्षात्कार | पास |
| साक्षात्कार | विफल |
| साक्षात्कार | CANDIDATE_CANCELLED |
| साक्षात्कार | NO_SHOW |
| MAKE_OFFER | स्वीकृत |
| MAKE_OFFER | अस्वीकार किया गया |
| SEEK_REFERENCES | पास |
| SEEK_REFERENCES | विफल |
| APPLICATION_CLOSED | किराए पर लिया |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | पास |
| TEST_APTITUDE | विफल |
हमारी प्रक्रियाएं केवल राज्यों का एक समूह है जो प्रत्येक समय के लिए मौजूद हैं। नीचे दी गई तालिका में उन्हें तार्किक क्रम में प्रस्तुत किया गया है, लेकिन यह प्रसंस्करण के वास्तविक क्रम को परिभाषित नहीं करता है।
| अभिभावक प्रकार – प्रक्रियाएं | बच्चे का प्रकार - राज्य |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | साक्षात्कार |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | साक्षात्कार |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_CLOSED |
बीओएम पदानुक्रम के संबंध में एक महत्वपूर्ण बिंदु है। जिस तरह सामग्री का एक भौतिक बिल असेंबली और सब-असेंबली को सबसे छोटे घटकों तक परिभाषित करता है, हमारे पदानुक्रम में भी इसी तरह की व्यवस्था है। इसका मतलब है कि हमें 'असेंबली' और 'सब-असेंबली' का दोबारा इस्तेमाल करना होगा।
उदाहरण के तौर पर:दोनों STANDARD_JOB_APPLICATION और TECHNICAL_JOB_APPLICATION प्रक्रियाएं INTERVIEW प्राप्त करें राज्य . बदले में, INTERVIEW राज्य PASSED है , FAILED , CANDIDATE_CANCELLED , और NO_SHOW परिणाम इसके लिए परिभाषित किया गया है।
जब आप किसी प्रक्रिया में किसी राज्य का उपयोग करते हैं, तो आप स्वचालित रूप से इसके साथ अपने बच्चे के परिणाम प्राप्त करते हैं क्योंकि यह पहले से ही एक असेंबली है। इसका मतलब यह है कि INTERVIEW . पर दोनों प्रकार के नौकरी आवेदन के लिए समान परिणाम मौजूद हैं मंच। यदि आप विभिन्न प्रकार के नौकरी आवेदनों के लिए अलग-अलग साक्षात्कार परिणाम चाहते हैं, तो आपको TECHNICAL_INTERVIEW परिभाषित करना होगा, जैसे कि, और STANDARD_INTERVIEW बताता है कि प्रत्येक के अपने विशिष्ट परिणाम होते हैं।
इस उदाहरण में, दो प्रकार के नौकरी के आवेदनों के बीच एकमात्र अंतर यह है कि तकनीकी नौकरी आवेदन में योग्यता परीक्षा शामिल है।
आपके जाने से पहले
इस दो-भाग वाले आलेख के भाग 1 ने वर्कफ़्लो डेटाबेस प्रतिमान प्रस्तुत किया है। इसने दिखाया है कि आप इसे अपने डेटाबेस में किसी भी इकाई के जीवनचक्र को प्रबंधित करने के लिए कैसे शामिल कर सकते हैं।
भाग 2 आपको दिखाएगा वास्तविक कार्यप्रवाह कैसे परिभाषित करें अतिरिक्त कॉन्फ़िगरेशन तालिकाओं का उपयोग करना। यह वह जगह है जहां उपयोगकर्ता को स्वीकार्य अगले चरणों के साथ प्रस्तुत किया जाएगा। हम बीओएम में 'असेंबली' और 'सब-असेंबली' के सख्त पुन:उपयोग से बचने के लिए एक तकनीक का भी प्रदर्शन करेंगे।