डेटाबेस को विभिन्न तरीकों से डिज़ाइन किया गया है। अधिकांश समय हम "स्कूल उदाहरण" का उपयोग कर सकते हैं:डेटाबेस को सामान्य करें और सब कुछ ठीक काम करेगा। लेकिन ऐसी स्थितियां हैं जिनके लिए दूसरे दृष्टिकोण की आवश्यकता होगी। अधिक लचीलापन प्राप्त करने के लिए हम संदर्भों को हटा सकते हैं। लेकिन क्या होगा अगर हमें प्रदर्शन में सुधार करना है जब सब कुछ किताब द्वारा किया गया था? उस मामले में, डीनॉर्मलाइजेशन एक ऐसी तकनीक है जिस पर हमें विचार करना चाहिए। इस लेख में, हम डीनॉर्मलाइजेशन के फायदे और नुकसान पर चर्चा करेंगे और किन परिस्थितियों में इसकी आवश्यकता हो सकती है।
असामान्यीकरण क्या है?
Denormalization एक रणनीति है जो प्रदर्शन को बढ़ाने के लिए पहले से सामान्यीकृत डेटाबेस पर उपयोग की जाती है। इसके पीछे का विचार अनावश्यक डेटा जोड़ना है जहां हमें लगता है कि इससे हमें सबसे अधिक मदद मिलेगी। हम मौजूदा तालिका में अतिरिक्त विशेषताओं का उपयोग कर सकते हैं, नई तालिकाएँ जोड़ सकते हैं, या मौजूदा तालिकाओं के उदाहरण भी बना सकते हैं। सामान्य लक्ष्य डेटा को प्रश्नों के लिए अधिक सुलभ बनाकर या अलग-अलग तालिकाओं में सारांशित रिपोर्ट तैयार करके चुनिंदा प्रश्नों के चलने के समय को कम करना है। यह प्रक्रिया कुछ नई समस्याएं ला सकती है, और हम उन पर बाद में चर्चा करेंगे।
एक सामान्यीकृत डेटाबेस denormalization प्रक्रिया के लिए प्रारंभिक बिंदु है। उस डेटाबेस से अंतर करना महत्वपूर्ण है जिसे सामान्यीकृत नहीं किया गया है और डेटाबेस जिसे पहले सामान्यीकृत किया गया था और फिर बाद में असामान्य किया गया था। दूसरा ठीक है; पहला अक्सर खराब डेटाबेस डिज़ाइन या ज्ञान की कमी का परिणाम होता है।
उदाहरण:एक बहुत ही सरल सीआरएम के लिए एक सामान्यीकृत मॉडल
नीचे दिया गया मॉडल हमारे उदाहरण के रूप में काम करेगा:
आइए तालिकाओं पर एक नज़र डालें:
user_accountतालिका उन उपयोगकर्ताओं के बारे में डेटा संग्रहीत करती है जो हमारे एप्लिकेशन में लॉग इन करते हैं (मॉडल को सरल बनाना, भूमिकाएं और उपयोगकर्ता अधिकार इसमें शामिल नहीं हैं)।- द
clientतालिका में हमारे ग्राहकों के बारे में कुछ बुनियादी डेटा है। productतालिका हमारे ग्राहकों को पेश किए गए उत्पादों को सूचीबद्ध करती है।taskतालिका में हमारे द्वारा बनाए गए सभी कार्य शामिल हैं। आप प्रत्येक कार्य को क्लाइंट के प्रति संबंधित कार्यों के एक सेट के रूप में सोच सकते हैं। प्रत्येक कार्य की अपनी संबंधित कॉल, बैठकें और प्रस्तावित और बेचे गए उत्पादों की सूची होती है।- द
callऔरmeetingटेबल सभी कॉल और मीटिंग के बारे में डेटा स्टोर करते हैं और उन्हें कार्यों और उपयोगकर्ताओं के साथ जोड़ते हैं। - शब्दकोश
task_outcome,meeting_outcomeऔरcall_outcomeकिसी कार्य, मीटिंग या कॉल की अंतिम स्थिति के लिए सभी संभावित विकल्प शामिल हैं। - द
product_offeredproduct_soldइसमें उन सभी उत्पादों की सूची होती है जिन्हें क्लाइंट ने वास्तव में खरीदा था। supply_orderतालिका हमारे द्वारा दिए गए सभी आदेशों औरproducts_on_orderतालिका विशिष्ट आदेशों के लिए उत्पादों और उनकी मात्रा को सूचीबद्ध करती है।- द
writeoffतालिका उन उत्पादों की सूची है जो दुर्घटनाओं या समान (जैसे टूटे हुए दर्पण) के कारण बट्टे खाते में डाले गए थे।
डेटाबेस सरल है लेकिन यह पूरी तरह से सामान्यीकृत है। आपको कोई अतिरेक नहीं मिलेगा और इसे काम करना चाहिए। जब तक हम अपेक्षाकृत कम मात्रा में डेटा के साथ काम करते हैं, तब तक हमें किसी भी मामले में किसी भी प्रदर्शन समस्या का अनुभव नहीं करना चाहिए।
विसामान्यीकरण का उपयोग कब और क्यों करें
जैसा कि लगभग किसी भी चीज़ के साथ होता है, आपको यह सुनिश्चित होना चाहिए कि आप डीनॉर्मलाइज़ेशन क्यों लागू करना चाहते हैं। आपको यह भी सुनिश्चित करने की आवश्यकता है कि इसका उपयोग करने से होने वाला लाभ किसी भी नुकसान से अधिक है। ऐसी कुछ स्थितियां हैं जब आपको निश्चित रूप से असामान्यता के बारे में सोचना चाहिए:
- इतिहास बनाए रखना: डेटा समय के दौरान बदल सकता है, और हमें उन मानों को संग्रहीत करने की आवश्यकता होती है जो रिकॉर्ड बनाते समय मान्य थे। हमारा मतलब किस तरह के बदलाव से है? खैर, एक व्यक्ति का पहला और अंतिम नाम बदल सकता है; एक ग्राहक अपने व्यवसाय का नाम या कोई अन्य डेटा भी बदल सकता है। कार्य विवरण में वे मान होने चाहिए जो उस समय वास्तविक थे जब कोई कार्य उत्पन्न हुआ था। अगर ऐसा नहीं हुआ तो हम पिछले डेटा को सही तरीके से दोबारा नहीं बना पाएंगे। हम इन परिवर्तनों के इतिहास वाली एक तालिका जोड़कर इस समस्या को हल कर सकते हैं। उस स्थिति में, कार्य को वापस करने वाली एक चुनिंदा क्वेरी और एक वैध क्लाइंट नाम अधिक जटिल हो जाएगा। शायद एक अतिरिक्त तालिका सबसे अच्छा समाधान नहीं है।
- क्वेरी प्रदर्शन में सुधार: कुछ क्वेरीज़ डेटा तक पहुँचने के लिए कई तालिकाओं का उपयोग कर सकती हैं जिनकी हमें अक्सर आवश्यकता होती है। ऐसी स्थिति के बारे में सोचें जहां हमें ग्राहक के नाम और उन्हें बेचे गए उत्पादों को वापस करने के लिए 10 तालिकाओं में शामिल होने की आवश्यकता होगी। पथ के साथ कुछ तालिकाओं में बड़ी मात्रा में डेटा भी हो सकता है। उस स्थिति में, शायद
client_id. जोड़ना समझदारी होगी सीधेproducts_soldटेबल. - रिपोर्टिंग में तेजी लाना: हमें कुछ आंकड़ों की बहुत बार आवश्यकता होती है। उन्हें लाइव डेटा से बनाना काफी समय लेने वाला है और समग्र सिस्टम प्रदर्शन को प्रभावित कर सकता है। मान लें कि हम कुछ या सभी ग्राहकों के लिए कुछ वर्षों में ग्राहकों की बिक्री को ट्रैक करना चाहते हैं। लाइव डेटा से ऐसी रिपोर्ट तैयार करना लगभग पूरे डेटाबेस में "खोद" देगा और इसे बहुत धीमा कर देगा। और अगर हम उस आंकड़े का अक्सर इस्तेमाल करते हैं तो क्या होगा?
- आम तौर पर आवश्यक मूल्यों की गणना करना: हम चाहते हैं कि कुछ मान तैयार हों, ताकि हमें उन्हें वास्तविक समय में उत्पन्न न करना पड़े।
यह बताना ज़रूरी है कि अगर परफ़ॉर्मेंस में कोई समस्या नहीं है, तो आपको डीनॉर्मलाइज़ेशन का इस्तेमाल करने की ज़रूरत नहीं है आवेदन में। लेकिन अगर आप देखते हैं कि सिस्टम धीमा हो रहा है - या यदि आप जानते हैं कि ऐसा हो सकता है - तो आपको इस तकनीक को लागू करने के बारे में सोचना चाहिए। हालांकि, इसके साथ जाने से पहले, अन्य विकल्पों पर विचार करें, जैसे क्वेरी ऑप्टिमाइज़ेशन और उचित अनुक्रमण। यदि आप पहले से ही उत्पादन में हैं तो आप डीनॉर्मलाइज़ेशन का भी उपयोग कर सकते हैं लेकिन विकास के चरण में मुद्दों को हल करना बेहतर है।
विरूपण के नुकसान क्या हैं?
जाहिर है, डीनॉर्मलाइजेशन प्रक्रिया का सबसे बड़ा फायदा प्रदर्शन में वृद्धि है। लेकिन हमें इसके लिए एक कीमत चुकानी होगी, और उस कीमत में निम्न शामिल हो सकते हैं:
- डिस्क स्थान: यह अपेक्षित है, क्योंकि हमारे पास डुप्लिकेट डेटा होगा।
- डेटा विसंगतियां: हमें इस तथ्य से बहुत अवगत होना होगा कि डेटा को अब एक से अधिक स्थानों पर बदला जा सकता है। हमें डुप्लिकेट डेटा के हर टुकड़े को तदनुसार समायोजित करना चाहिए। यह गणना किए गए मानों और रिपोर्ट पर भी लागू होता है। हम सभी कार्यों के लिए ट्रिगर, लेन-देन और/या प्रक्रियाओं का उपयोग करके इसे प्राप्त कर सकते हैं जिन्हें एक साथ पूरा किया जाना चाहिए।
- दस्तावेज़ीकरण: हमारे द्वारा लागू किए गए प्रत्येक विसामान्यीकरण नियम को हमें ठीक से प्रलेखित करना चाहिए। यदि हम बाद में डेटाबेस डिज़ाइन को संशोधित करते हैं, तो हमें अपने सभी अपवादों को देखना होगा और उन्हें एक बार फिर से ध्यान में रखना होगा। हो सकता है कि हमें अब उनकी आवश्यकता न हो क्योंकि हमने समस्या का समाधान कर लिया है। या हो सकता है कि हमें मौजूदा डीनॉर्मलाइजेशन नियमों को जोड़ने की जरूरत हो। (उदाहरण के लिए:हमने क्लाइंट टेबल में एक नई विशेषता जोड़ी है और हम इसके इतिहास मूल्य को एक साथ स्टोर करना चाहते हैं जो हम पहले से ही स्टोर कर रहे हैं। हमें इसे हासिल करने के लिए मौजूदा डीनॉर्मलाइजेशन नियमों को बदलना होगा)।
- अन्य कार्यों को धीमा करना: हम उम्मीद कर सकते हैं कि हम डेटा डालने, संशोधन और हटाने के संचालन को धीमा कर देंगे। यदि ये ऑपरेशन अपेक्षाकृत कम ही होते हैं, तो यह एक लाभ हो सकता है। मूल रूप से, हम एक धीमे चयन को बड़ी संख्या में धीमी इन्सर्ट/अपडेट/डिलीट प्रश्नों में विभाजित करेंगे। जबकि एक बहुत ही जटिल चयन क्वेरी तकनीकी रूप से पूरे सिस्टम को धीमा कर सकती है, कई "छोटे" संचालन को धीमा करने से हमारे एप्लिकेशन की उपयोगिता को नुकसान नहीं पहुंचना चाहिए।
- अधिक कोडिंग: नियम 2 और 3 के लिए अतिरिक्त कोडिंग की आवश्यकता होगी, लेकिन साथ ही वे कुछ चुनिंदा प्रश्नों को बहुत सरल कर देंगे। यदि हम किसी मौजूदा डेटाबेस को असामान्य बना रहे हैं तो हमें अपने काम का लाभ प्राप्त करने के लिए इन चुनिंदा प्रश्नों को संशोधित करना होगा। हमें मौजूदा रिकॉर्ड के लिए नई जोड़ी गई विशेषताओं में मानों को भी अपडेट करना होगा। इसके लिए भी थोड़ी अधिक कोडिंग की आवश्यकता होगी।
उदाहरण मॉडल, विरूपित
नीचे दिए गए मॉडल में, मैंने ऊपर बताए गए कुछ डीनॉर्मलाइज़ेशन नियम लागू किए हैं। गुलाबी तालिकाओं को संशोधित किया गया है, जबकि हल्की-नीली तालिका पूरी तरह से नई है।
कौन से परिवर्तन लागू होते हैं और क्यों?

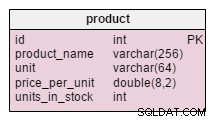
product तालिका units_in_stock का जोड़ है गुण। एक सामान्यीकृत मॉडल में हम इस डेटा की गणना आदेशित इकाइयों - बेची गई इकाइयों - (प्रस्तावित इकाइयों) - बट्टे खाते में डाली गई इकाइयों के रूप में कर सकते हैं। . जब भी कोई ग्राहक उस उत्पाद के लिए पूछता है तो हम हर बार गणना दोहराते हैं, जिसमें अत्यधिक समय लगता है। इसके बजाय, हम आगे मूल्य की गणना करेंगे; जब कोई ग्राहक हमसे पूछेगा, तो हम उसे तैयार कर देंगे। बेशक, यह चुनिंदा क्वेरी को बहुत सरल करता है। दूसरी ओर, units_in_stock विशेषता को products_on_order , writeoff , product_offered और product_sold टेबल.
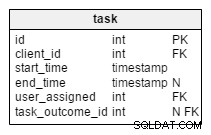
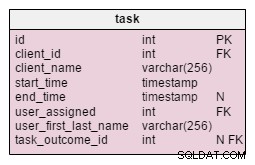
संशोधित task तालिका में, हमें दो नई विशेषताएँ मिलती हैं:client_name और user_first_last_name . जब कार्य बनाया गया था तो वे दोनों मूल्यों को संग्रहीत करते हैं। कारण यह है कि ये दोनों मूल्य समय के साथ बदल सकते हैं। हम एक विदेशी कुंजी भी रखेंगे जो उन्हें मूल क्लाइंट और उपयोगकर्ता आईडी से संबंधित करती है। ऐसे और भी मूल्य हैं जिन्हें हम स्टोर करना चाहते हैं, जैसे क्लाइंट का पता, वैट आईडी, आदि।




असामान्य product_offered तालिका में दो नई विशेषताएं हैं, price_per_unit और price . price_per_unit विशेषता संग्रहीत की जाती है क्योंकि हमें वास्तविक मूल्य उत्पाद की पेशकश के समय . को संग्रहीत करने की आवश्यकता होती है . सामान्यीकृत मॉडल केवल अपनी वर्तमान स्थिति दिखाएगा, इसलिए जब उत्पाद की कीमत बदलती है तो हमारे 'इतिहास' की कीमतें भी बदल जाएंगी। हमारा परिवर्तन न केवल डेटाबेस को तेजी से चलाता है:यह इसे बेहतर काम भी करता है। price विशेषता परिकलित मान है units_sold * price_per_unit . हर बार जब हम प्रस्तावित उत्पादों की सूची पर एक नज़र डालना चाहते हैं, तो उस गणना को करने से बचने के लिए मैंने इसे यहां जोड़ा है। यह एक छोटी सी लागत है, लेकिन यह प्रदर्शन में सुधार करता है।
product_sold तालिका बहुत समान हैं। तालिका संरचना समान है, लेकिन यह बेची गई वस्तुओं की एक सूची संग्रहीत करती है।
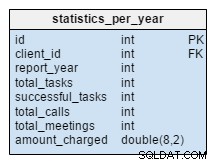
statistics_per_year तालिका हमारे मॉडल के लिए बिल्कुल नई है। हमें इसे एक असामान्य तालिका के रूप में देखना चाहिए क्योंकि इसके सभी डेटा की गणना अन्य तालिकाओं से की जा सकती है। इस तालिका के पीछे का विचार किसी दिए गए क्लाइंट से संबंधित कार्यों, सफल कार्यों, बैठकों और कॉलों की संख्या को संग्रहीत करना है। यह प्रति वर्ष कुल चार्ज की गई राशि को भी संभालता है। task , meeting , call और product_sold तालिकाएँ, हमें उस ग्राहक और संबंधित वर्ष के लिए इस तालिका के डेटा की पुनर्गणना करनी चाहिए। हम उम्मीद कर सकते हैं कि हमारे पास ज्यादातर बदलाव केवल चालू वर्ष के लिए होंगे। पिछले वर्षों की रिपोर्ट को बदलने की आवश्यकता नहीं है।
इस तालिका में मूल्यों की गणना सामने की जाती है, इसलिए हम उस समय कम समय और संसाधन खर्च करेंगे जब हमें गणना परिणाम की आवश्यकता होगी। उन मूल्यों के बारे में सोचें जिनकी आपको अक्सर आवश्यकता होगी। हो सकता है कि आपको नियमित रूप से उन सभी की आवश्यकता न हो और आप उनमें से कुछ की लाइव गणना करने का जोखिम उठा सकते हैं।
Denormalization एक बहुत ही रोचक और शक्तिशाली अवधारणा है। हालांकि यह पहला नहीं है जो आपको प्रदर्शन में सुधार करने के लिए ध्यान में रखना चाहिए, कुछ स्थितियों में यह सबसे अच्छा या एकमात्र समाधान भी हो सकता है।
इससे पहले कि आप डीनॉर्मलाइजेशन का उपयोग करना चुनें, सुनिश्चित करें कि आप इसे चाहते हैं। कुछ विश्लेषण करें और प्रदर्शन को ट्रैक करें। आप शायद पहले से ही लाइव होने के बाद असामान्यता के साथ जाने का फैसला करेंगे। इसका उपयोग करने से डरो मत, लेकिन परिवर्तनों को ट्रैक करें और आपको किसी भी समस्या का अनुभव नहीं होना चाहिए (यानी, भयानक डेटा विसंगतियाँ)।