डेटा प्रबंधन का रिलेशनल मॉडल पहली बार 1969 में डॉ. एडगर एफ. कोड द्वारा विकसित किया गया था। आधुनिक रिलेशनल डेटाबेस मैनेजमेंट सिस्टम (RDBMSes) प्रतिमान के साथ संरेखित हैं। RDBMS के साथ पहचाने जाने वाली प्रमुख संरचना तार्किक संरचना है जिसे "टेबल" कहा जाता है। तालिकाएँ मुख्य रूप से पंक्तियों और स्तंभों से बनी होती हैं (जिन्हें रिकॉर्ड और विशेषताएँ या टुपल्स और फ़ील्ड भी कहा जाता है)। एक सख्त गणितीय अर्थ में, शब्द तालिका वास्तव में "रिलेशनल मॉडल" शब्द के लिए एक संबंध और खातों के रूप में जाना जाता है। गणित में, संबंध एक समुच्चय का प्रतिनिधित्व है।
अभिव्यक्ति विशेषता एक कॉलम के उद्देश्य का एक अच्छा विवरण देती है - यह इससे जुड़ी पंक्तियों के सेट की विशेषता है। प्रत्येक कॉलम एक विशेष डेटा प्रकार का होना चाहिए और प्रत्येक पंक्ति में कुछ विशिष्ट पहचान विशेषताएँ होनी चाहिए जिन्हें "कुंजी" कहा जाता है। रिलेशनल मॉडल का उपयोग करते समय डेटा परिवर्तन आम तौर पर अधिक कुशल होता है जबकि डेटा पुनर्प्राप्ति पुराने पदानुक्रमित मॉडल के साथ तेज़ हो सकती है जिसे मॉडल नोएसक्यूएल सिस्टम में फिर से परिभाषित किया गया है।
डेटा सामान्यीकरण एक गणितीय प्रक्रिया है जिसमें व्यवसाय डेटा को एक ऐसे रूप में मॉडलिंग की जाती है जो सुनिश्चित करता है कि प्रत्येक इकाई एक ही संबंध (तालिका) द्वारा दर्शायी जाती है। संबंधपरक मॉडल के शुरुआती समर्थकों ने सामान्य रूपों की अवधारणा का प्रस्ताव रखा। एडगर कोडड ने पहले, दूसरे और तीसरे सामान्य रूपों को परिभाषित किया। उसके बाद वह रेमंड एफ. बॉयस से जुड़ गया। दोनों ने मिलकर बॉयस-कॉड नॉर्मल फॉर्म को परिभाषित किया। अब तक, छह सामान्य रूपों को सैद्धांतिक रूप से परिभाषित किया गया है, लेकिन अधिकांश व्यावहारिक अनुप्रयोगों में, हम आम तौर पर सामान्यीकरण को तीसरे सामान्य रूप तक बढ़ाते हैं। प्रत्येक सामान्य प्रपत्र डेटा संशोधन के दौरान विसंगतियों से बचने का प्रयास करता है, एक तालिका के भीतर डेटा की अतिरेक और निर्भरता को कम करता है। सामान्यीकरण का प्रत्येक स्तर अधिक तालिकाओं का परिचय देता है, अतिरेक को कम करता है, प्रत्येक तालिका की सादगी को बढ़ाता है, लेकिन संपूर्ण संबंधपरक डेटाबेस प्रबंधन प्रणाली की जटिलता को भी बढ़ाता है। इसलिए संरचनात्मक रूप से RDBM सिस्टम पदानुक्रमित प्रणालियों की तुलना में अधिक जटिल होते हैं।
डेटाबेस सामान्यीकरण क्यों:चार विसंगतियां
सामान्यीकरण के बिना डेटा संग्रहण डेटा खपत के साथ कई समस्याओं का कारण बनता है। सामान्यीकरण के समर्थकों ने ऐसी समस्याओं को विसंगति कहा। इन विसंगतियों का वर्णन करने के लिए, आइए अंजीर में प्रस्तुत आंकड़ों को देखें। 1.

अंजीर। 1 कर्मचारी तालिका
सूचीकरण 1. डेटाबेस सामान्यीकरण प्रदर्शित करने के लिए मूल तालिका।
1.1. तालिका बनाएं
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. पंक्तियाँ सम्मिलित करें
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. तालिका को क्वेरी करें
select * from staffers;
यह तालिका संक्षेप में डेटा के दो सेटों का प्रतिनिधित्व करती है जिन्हें अनजाने में संयोजित किया गया है:कर्मचारियों के नाम और विभाग। ध्यान दें कि सभी कर्मचारी एक ही विभाग से हैं:इंजीनियरिंग। यह सादगी के लिए और सामान्यीकरण प्रदर्शित करने के लिए किया गया था। इस संरचना में हेरफेर करने से जुड़ी तीन मुख्य समस्याएं हैं:
सम्मिलन विसंगति
नया रिकॉर्ड डालने के लिए, हमें विभाग और प्रबंधक के नामों को दोहराते रहना होगा।
विलोपन विसंगति
एक कर्मचारी के रिकॉर्ड को हटाने के लिए, हमें संबंधित प्रबंधक और विभाग को भी हटाना होगा। यदि सभी कर्मचारियों के रिकॉर्ड को हटाने की आवश्यकता है, तो हमें सभी विभागों और सभी प्रबंधकों को भी हटाना होगा।
अपडेट विसंगति
यदि किसी विभाग के प्रबंधक को बदलने की आवश्यकता है, तो हमें इस तालिका की प्रत्येक पंक्ति में परिवर्तन करना होगा क्योंकि प्रत्येक कर्मचारी के लिए मूल्यों की नकल की जाती है।
डेटाबेस सामान्य प्रपत्र
लेख के निम्नलिखित अनुभागों में, हम पहले, दूसरे और तीसरे सामान्य रूपों का वर्णन करने का प्रयास करेंगे जो वास्तविक आरडीबीएम सिस्टम में देखे जाने की अधिक संभावना है। सिद्धांत के अन्य विस्तार हैं जैसे कि चौथा, पांचवां और बॉयस-कॉड सामान्य रूप लेकिन इस लेख में, हम खुद को तीन सामान्य रूपों तक सीमित रखेंगे।
पहला सामान्य फ़ॉर्म
पहला सामान्य फॉर्म चार नियमों द्वारा परिभाषित किया गया है:
प्रत्येक कॉलम में समान डेटा प्रकार के मान होने चाहिए।
कर्मचारी तालिका पहले से ही इस नियम को पूरा करती है।
तालिका में प्रत्येक स्तंभ परमाणु होना चाहिए।
इसका अनिवार्य रूप से मतलब है कि आपको कॉलम की सामग्री को तब तक विभाजित करना चाहिए जब तक कि उन्हें विभाजित नहीं किया जा सके। ध्यान दें कि भूमिका कर्मचारियों . में कॉलम StaffID=3 वाली पंक्ति के लिए तालिका नियम 2 को तोड़ती है।
तालिका में प्रत्येक पंक्ति अद्वितीय होनी चाहिए।
सामान्यीकृत तालिकाओं में विशिष्टता आमतौर पर प्राथमिक कुंजी का उपयोग करके प्राप्त की जाती है। प्राथमिक कुंजी तालिका में प्रत्येक पंक्ति को विशिष्ट रूप से परिभाषित करती है। अधिकांश समय प्राथमिक कुंजी को केवल एक कॉलम द्वारा परिभाषित किया जाता है। एक से अधिक स्तंभों से बनी प्राथमिक कुंजी को समग्र कुंजी कहा जाता है।
रिकॉर्ड्स को स्टोर करने का क्रम मायने नहीं रखता।
डेटा को कर्मचारियों में संरेखित करने के लिए तालिका पहले सामान्य रूप के सिद्धांतों के साथ हमें तालिका को विभाजित करने की आवश्यकता है जैसा कि चित्र 2, 3 और 4 में दिखाया गया है।
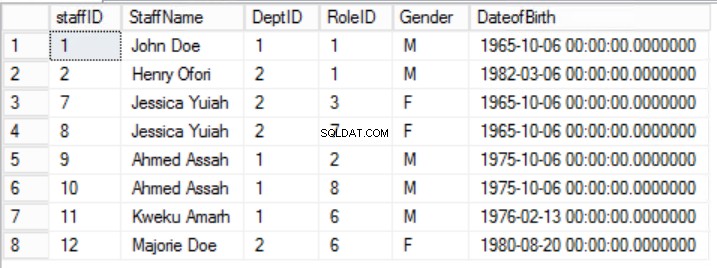
अंजीर। 2 कर्मचारी तालिका
हमने कर्मचारियों . में डेटा को सीमित कर दिया है तालिका बनाई और विशिष्टता की गारंटी के लिए एक समग्र प्राथमिक कुंजी लागू की। हमने दो अतिरिक्त तालिकाएं भी बनाई हैं भूमिकाएं और विभाग जिनका मूल कर्मचारियों . के साथ संबंध है तालिका विदेशी कुंजी का उपयोग करके लागू की गई। लिस्टिंग 2 में डीडीएल की समीक्षा करें।
लिस्टिंग 2. नए कर्मचारियों . का डीडीएल पहले सामान्य रूप के लिए तालिका।
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
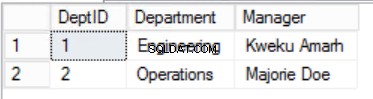
अंजीर। 3 विभाग तालिका
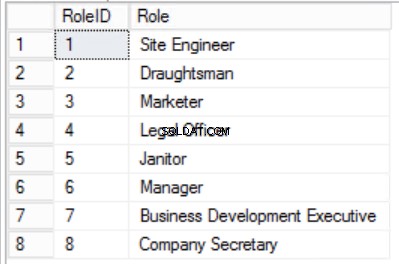
अंजीर। 4 भूमिका तालिका
दूसरा सामान्य फॉर्म
पहला सामान्य फ़ॉर्म पहले से मौजूद होना चाहिए।
प्रत्येक गैर-कुंजी कॉलम में प्राथमिक कुंजी पर आंशिक निर्भरता नहीं होनी चाहिए।
दूसरे नियम का जोर यह है कि तालिका के सभी स्तंभों को उन सभी स्तंभों पर निर्भर होना चाहिए जिनमें प्राथमिक कुंजी एक साथ होती है। चित्र 2, 3 और 4 में दी गई तालिकाओं को देखते हुए, हम पाते हैं कि हमने पहले सामान्य रूप की सभी आवश्यकताओं को प्राप्त कर लिया है। हमने दो तालिकाओं भूमिकाओं . के लिए दूसरे सामान्य प्रपत्र की आवश्यकताओं को भी प्राप्त कर लिया है और विभाग . हालांकि, कर्मचारियों . के मामले में तालिका, हमें अभी भी एक समस्या है। हमारी प्राथमिक कुंजी कॉलम स्टाफ़आईडी और रोलआईडी से बनी है।
दूसरे सामान्य फॉर्म के नियम 2 को यहां इस तथ्य से तोड़ा गया है कि स्टाफ का लिंग और जन्म तिथि रोलआईडी पर निर्भर नहीं है। आंशिक निर्भरता है।
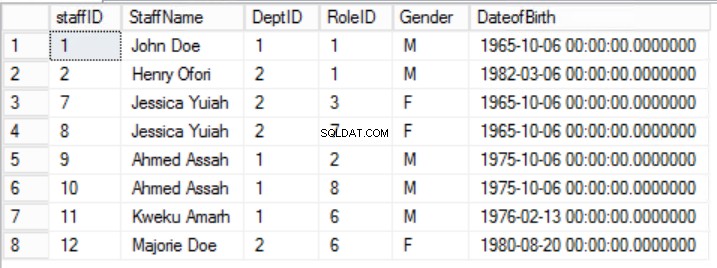
अंजीर। पहले सामान्य फॉर्म के लिए 5 कर्मचारी
दिए गए उदाहरण में, हम प्राथमिक कुंजी से रोलआईडी को हटाकर इसे ठीक करने का प्रयास कर सकते हैं, लेकिन अगर हम ऐसा करते हैं तो हम एक और नियम तोड़ देंगे:पहले सामान्य फॉर्म में बताई गई विशिष्टता की भूमिका। हमें दूसरा तरीका अपनाना चाहिए। हम कर्मचारियों को संशोधित करेंगे तालिका इस समझ के साथ कि एक कर्मचारी एक से अधिक भूमिका निभा सकता है। अंजीर देखें। 6.
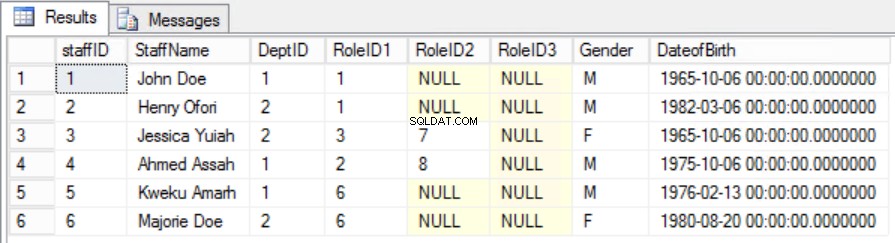
अंजीर। दूसरे सामान्य फॉर्म के लिए 6 कर्मचारी तालिका
हम विशिष्टता बनाए रखने के साथ-साथ आंशिक निर्भरता को दूर करने में सफल रहे हैं।
लिस्टिंग 3. दूसरे सामान्य फॉर्म के लिए नए कर्मचारी तालिका का डीडीएल।
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
तीसरा सामान्य फ़ॉर्म
दूसरा सामान्य फ़ॉर्म पहले से ही मौजूद होना चाहिए।
प्रत्येक गैर-कुंजी कॉलम में प्राथमिक कुंजी पर ट्रांजिटिव निर्भरता नहीं होनी चाहिए।
तीसरे सामान्य रूप का जोर यह है कि कोई भी स्तंभ ऐसा नहीं होना चाहिए जो गैर-कुंजी स्तंभों पर निर्भर हो, भले ही वह गैर-कुंजी स्तंभ पहले से ही प्राथमिक कुंजी पर निर्भर हो।
एक उदाहरण के रूप में, मान लें कि हमने कर्मचारियों में एक अतिरिक्त कॉलम जोड़ने का निर्णय लिया है कर्मचारी के प्रबंधक को स्पष्ट रूप से देखने के लिए चित्र 7 में दर्शाई गई तालिका। ऐसा करने से हम दूसरे तीसरे नॉर्मल फॉर्म नियम को तोड़ देते, क्योंकि मैनेजर का नाम DeptID पर निर्भर करता है और DeptID, बदले में, StaffID पर निर्भर करता है। यह एक सकर्मक निर्भरता है।
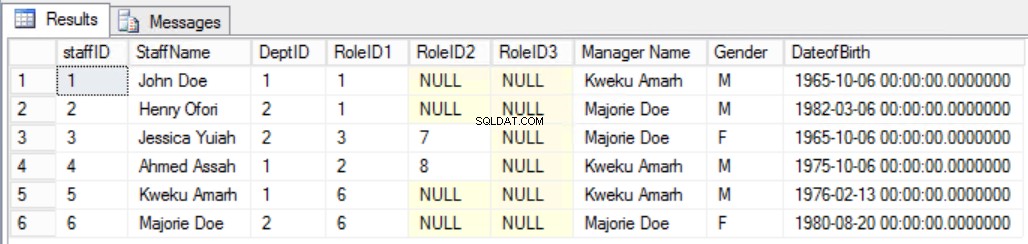
अंजीर। तीसरे सामान्य फॉर्म के लिए 7 कर्मचारी तालिका (टूटा नियम)
पुराने फॉर्म को बनाए रखना और स्टाफ टेबल और डिपार्टमेंट टेबल के बीच जॉइन का उपयोग करके आवश्यक जानकारी प्रदर्शित करना बेहतर होगा।
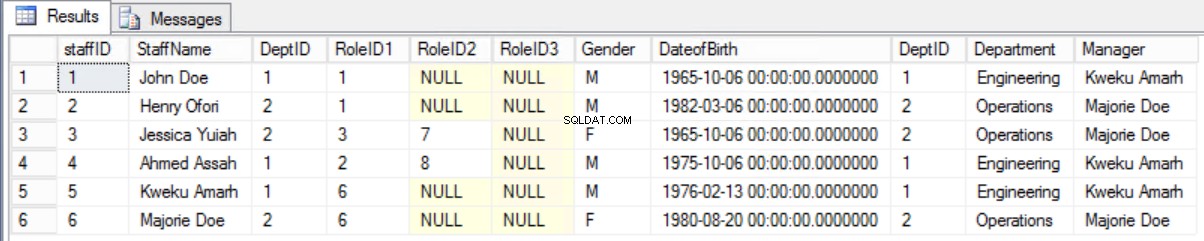
अंजीर। 8 कर्मचारी और विभाग के बीच जुड़ें
लिस्टिंग 4. कर्मचारियों और प्रबंधकों को प्रदर्शित करने के लिए प्रश्न।
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
व्यावहारिक अनुप्रयोग
अधिकांश परिपक्व एप्लिकेशन सामान्यीकरण के नियमों को उचित सीमा तक लागू करते हैं। हम देखते हैं कि डेटा सामान्यीकरण कार्यान्वयन प्राथमिक कुंजी बाधाओं और विदेशी कुंजी बाधाओं के उपयोग को जन्म देता है। इसके अलावा, जैसे ही हम विषय में गहराई से उतरते हैं, विदेशी कुंजी अनुक्रमण जैसे मुद्दे भी दिखाई देते हैं। पहले हमने उल्लेख किया था कि कैसे सामान्यीकरण की कमी डेटा के सुचारू हेरफेर को प्रभावित कर सकती है जैसा कि सम्मिलन, विलोपन और अद्यतन विसंगतियों में वर्णित है। उचित सामान्यीकरण की कमी भी अप्रत्यक्ष रूप से क्वेरी प्रदर्शन को प्रभावित कर सकती है।
मैंने हाल ही में एक टेबल देखी है जो टेबल 1 में दिखाए गए फॉर्म की थी जिसे हम Customer_Accounts कहेंगे।
S/No | Name | Account_No | फ़ोन_नहीं |
1 | केनेथ इगिरी | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | अर्नेस्ट डो | 6677554897 | 2348022887546, 2348039988456 |
तालिका 1 Customer_Accounts
इस तालिका के साथ मुख्य समस्या यह है कि यह पहले सामान्य प्रपत्र के दूसरे नियम को तोड़ती है। हमारे मामले में परिणाम यह हुआ कि ग्राहकों को उनके फोन नंबरों के आधार पर खोजने के लिए WHERE क्लॉज में LIKE और अग्रणी % का उपयोग करना आवश्यक था।
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
उपरोक्त निर्माण का प्रभाव यह था कि अनुकूलक ने कभी भी एक इंडेक्स का उपयोग नहीं किया जो एक बड़ी प्रदर्शन समस्या थी।
निष्कर्ष
डेटा नॉर्मलाइजेशन डेटाबेस डिजाइन के दायरे में आता है और डेवलपर्स और डीबीए दोनों को इस आलेख में उल्लिखित नियमों पर ध्यान देना चाहिए। डेटाबेस के उत्पादन में जाने से पहले सामान्यीकरण करना हमेशा बेहतर होता है। ठीक से डिज़ाइन किए गए रिलेशनल डेटाबेस मैनेजमेंट सिस्टम के लाभ बस प्रयास के लायक हैं।



