यह इस ब्लॉग श्रृंखला का दूसरा भाग है। आप भाग 1 यहाँ पढ़ सकते हैं: डिजिटल परिवर्तन एक डेटा यात्रा है जो किनारे से अंतर्दृष्टि तक है
यह ब्लॉग श्रृंखला एक कनेक्टेड वाहन निर्माता के लिए विनिर्माण, संचालन और बिक्री डेटा का अनुसरण करती है क्योंकि डेटा चरणों और परिवर्तनों से गुजरता है जो आमतौर पर वर्तमान तकनीक के अग्रणी किनारे पर एक बड़ी निर्माण कंपनी में अनुभव किया जाता है। डेटा जीवनचक्र के माध्यम से निर्माण डेटा पथ को चित्रित करने के लिए पहले ब्लॉग ने एक नकली कनेक्टेड वाहन निर्माण कंपनी, द इलेक्ट्रिक कार कंपनी (ईसीसी) की शुरुआत की। इसे पूरा करने के लिए, ईसीसी दुनिया भर में स्थित अपने कारखानों के भीतर घटनाओं की भविष्यवाणी करने और कार की निर्माण प्रक्रिया के ऊपर से नीचे देखने के लिए क्लौडेरा डेटा प्लेटफॉर्म (सीडीपी) का लाभ उठा रही है।
पिछले ब्लॉग में डेटा संग्रहण चरण को पूरा करने के बाद, डेटा जीवनचक्र में ECC का अगला चरण डेटा संवर्धन है। ECC एकत्र किए गए डेटा को समृद्ध करेगा और इसे बाद में डेटा जीवनचक्र में विश्लेषण और मॉडल निर्माण में उपयोग करने के लिए उपलब्ध कराएगा। नीचे डेटा जीवनचक्र में चरणों का पूरा सेट दिया गया है, और जीवनचक्र के प्रत्येक चरण को एक समर्पित ब्लॉग पोस्ट द्वारा समर्थित किया जाएगा (चित्र 1 देखें):
- डेटा संग्रह - किनारे पर डेटा अंतर्ग्रहण और निगरानी (चाहे किनारे औद्योगिक सेंसर हों या वाहन शोरूम में लोग हों)
- डेटा संवर्धन - डेटा पाइपलाइन प्रसंस्करण, एकत्रीकरण और प्रबंधन आगे के विश्लेषण के लिए डेटा तैयार करने के लिए
- रिपोर्टिंग - व्यावसायिक अंतर्दृष्टि प्रदान करना (बिक्री विश्लेषण और पूर्वानुमान, उदाहरण के रूप में बजट बनाना)
- सेवारत - आवश्यक व्यावसायिक कार्यों को नियंत्रित करना और चलाना (डीलर संचालन, उत्पादन निगरानी)
- भविष्य कहनेवाला विश्लेषण - एआई और मशीन लर्निंग पर आधारित प्रेडिक्टिव एनालिटिक्स (भविष्य कहनेवाला रखरखाव, उदाहरण के तौर पर मांग-आधारित इन्वेंट्री ऑप्टिमाइज़ेशन)
- सुरक्षा और शासन - संपूर्ण डेटा जीवनचक्र में सुरक्षा, प्रबंधन और शासन तकनीकों का एक एकीकृत सेट

चित्र 1 एंटरप्राइज़ डेटा जीवनचक्र
डेटा संवर्धन चुनौती
ईसीसी को अपने वाहनों के निर्माण, डीलर संचालन और शिपमेंट से संबंधित सभी डेटा के व्यापक दृष्टिकोण और मजबूत समझ की आवश्यकता है। उन्हें डेटा के साथ समस्याओं की शीघ्रता से पहचान करने की भी आवश्यकता होगी जैसे डेटा को स्पिन करने वाले परिचालन सेंसर जिसमें अनियोजित मशीन स्टॉपपेज या अचानक स्टार्ट-अप के कारण गलत तापमान स्पाइक्स शामिल हो सकते हैं। डेटा जिसका प्रक्रिया से कोई संबंध नहीं है जब रखरखाव कार्यकर्ता नियमित निरीक्षण करते समय एक एसिड डिप टैंक से एक सेंसर निकालते हैं, उदाहरण के लिए, विश्लेषण में ध्यान में नहीं रखा जाना चाहिए।
इसके अतिरिक्त, ईसीसी को निम्नलिखित डेटा चुनौतियों का सामना करना पड़ता है जिन्हें मोटर निर्माण को अपनी आपूर्ति श्रृंखला के माध्यम से सफलतापूर्वक स्थानांतरित करने के लिए संबोधित करने की आवश्यकता है। इन डेटा चुनौतियों में निम्नलिखित शामिल हैं:
- विभिन्न स्रोतों से विभिन्न स्वरूपों में डेटा पुनर्प्राप्त करना: डेटा इंजीनियरिंग पाइपलाइनों को विभिन्न स्रोतों से और कई अलग-अलग स्वरूपों में डेटा लाने की आवश्यकता होती है। चाहे डेटा उत्पादन लाइन पर बैठे सेंसर से, निर्माण कार्यों का समर्थन करने वाले, या आपूर्ति श्रृंखला को नियंत्रित करने वाले ईआरपी डेटा से प्राप्त किया गया हो, इन सभी को आगे के विश्लेषण के लिए एक साथ लाया जाना चाहिए।
- अनावश्यक या अप्रासंगिक डेटा को फ़िल्टर करना: डुप्लिकेट या अमान्य डेटा को हटाना, और शेष डेटा की सटीकता सुनिश्चित करना, डेटा को उन्नत भविष्य कहनेवाला विश्लेषण में आगे उपयोग के लिए तैयार करने में एक महत्वपूर्ण कदम है।
- अक्षम प्रक्रियाओं की पहचान करने की क्षमता: ECC को यह देखने की क्षमता की आवश्यकता होती है कि कौन सी डेटा प्रक्रियाएं सबसे अधिक समय और संसाधन ले रही हैं, जिससे समग्र प्रक्रिया को गति देने के लिए पाइपलाइन के खराब प्रदर्शन वाले हिस्सों को लक्षित करना आसान हो जाता है।
- एक ही फलक से सभी प्रक्रियाओं की निगरानी करने की क्षमता: ईसीसी को एक केंद्रीकृत प्रणाली की आवश्यकता है जो उन्हें सभी चल रही डेटा प्रक्रियाओं की निगरानी करने के साथ-साथ पारदर्शिता बनाए रखते हुए अपने मौजूदा बुनियादी ढांचे का विस्तार करने की अनुमति देता है।
क्यूरेटेड, गुणवत्ता वाले डेटासेट किसी भी उन्नत विश्लेषिकी पहल की रीढ़ हैं। इसे प्राप्त करने के लिए, डेटा जीवनचक्र में विभिन्न वाहन भागों के डेटा को स्थानांतरित करने, हेरफेर करने और प्रबंधित करने के लिए आवश्यक सभी पाइपिंग और प्लंबिंग के निर्माण की अनुमति देने के लिए एक डेटा इंजीनियरिंग ढांचे का उपयोग किया जाना चाहिए।
क्लौडेरा डेटा इंजीनियरिंग का उपयोग करके पाइपलाइन बनाना
पहले ब्लॉग में डेटा को समृद्ध और चर्चा करने से पहले, कारखाने से एकत्र किए गए आईटी और ओटी डेटा स्ट्रीम को साफ, हेरफेर और संशोधित किया जाएगा। फैक्ट्री आईडी, मशीन आईडी, टाइमस्टैम्प, पार्ट नंबर और सीरियल नंबर इलेक्ट्रिक मोटर पर अंकित क्यूआर-कोड से कैप्चर किया जा सकता है। जैसे ही मोटर को कनेक्टेड वाहन में इकट्ठा किया जाता है, डेटा कैप्चर किया जाता है जैसे मॉडल प्रकार, वीआईएन, और आधार वाहन लागत।
वाहन के बेचे जाने के बाद, बिक्री की जानकारी जैसे ग्राहक का नाम, संपर्क जानकारी, अंतिम बिक्री मूल्य और ग्राहक का स्थान अलग से दर्ज किया जाता है। यह डेटा किसी भी संभावित रिकॉल या लक्षित निवारक रखरखाव के लिए ग्राहक से संपर्क करने के लिए महत्वपूर्ण होगा। जियोलोकेशन डेटा भी संग्रहीत किया जाता है, जो ग्राहक स्थानों को अक्षांश और देशांतर में मैप करने में मदद करेगा ताकि यह बेहतर ढंग से समझ सके कि वाहन में बेचे जाने के बाद ये मोटर कहां स्थित हैं।
ECC उपरोक्त डेटा चुनौतियों का समाधान करने के लिए Cloudera डेटा इंजीनियरिंग (CDE) का उपयोग करेगा (चित्र 2 देखें)। सीडीई तब डेटा को क्लाउडेरा डेटा वेयरहाउस (सीडीडब्ल्यू) को उपलब्ध कराएगा, जहां इसे उन्नत विश्लेषिकी और व्यावसायिक खुफिया रिपोर्ट के लिए उपलब्ध कराया जाएगा। सीडीई के चरण नीचे दिए गए हैं।
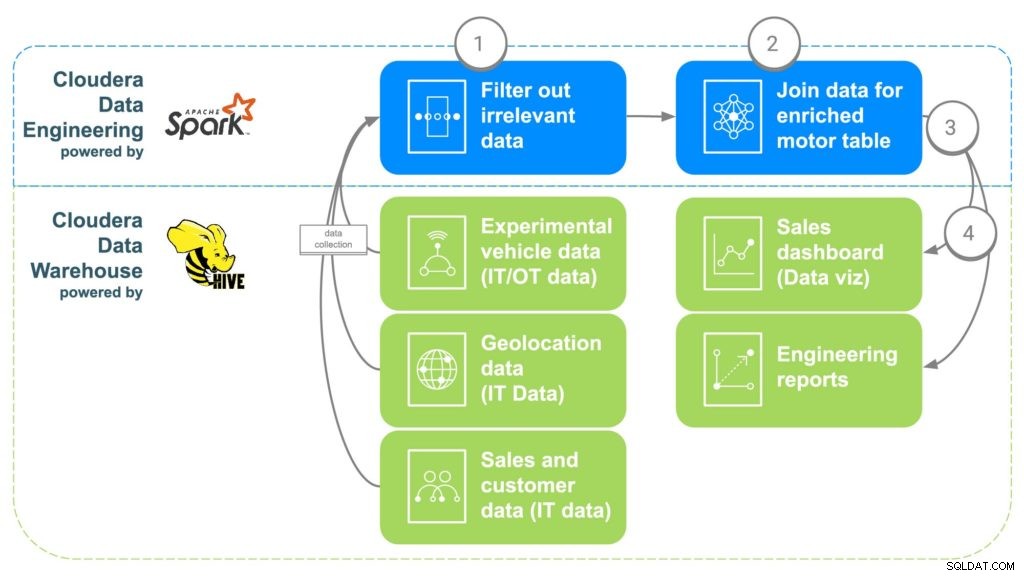
चित्र 2 ECC डेटा संवर्धन पाइपलाइन
चरण 1:डेटा फ़िल्टर करें और अलग करें
सीडीई का उपयोग करने में पहला कदम एक पायस्पार्क नौकरी बनाना है जो चरण 1 से इन विभिन्न "कच्चे" स्रोतों से डेटा लाता है। यह 16 साल से कम उम्र के ग्राहकों जैसे किसी भी अप्रासंगिक डेटा को फ़िल्टर करने का अवसर है, उदाहरण के लिए, उसके बाद से आमतौर पर ड्राइविंग की न्यूनतम उम्र होती है। डुप्लिकेट डेटा और अन्य अप्रासंगिक डेटा को भी फ़िल्टर या अलग किया जा सकता है।
चरण 2:डेटा संयोजित करें
सभी डेटा को संयोजित करने के लिए, सीडीई सामान्य लिंक को एक साथ सहसंबंधित करेगा। सबसे पहले, कार बिक्री डेटा उस ग्राहक से जुड़ा होगा जिसने ग्राहक मेटाडेटा प्राप्त करने के लिए कार खरीदी थी, जैसे संपर्क जानकारी, आयु, वेतन इत्यादि। जियोलोकेशन डेटा का उपयोग ग्राहक के लिए अधिक सटीक स्थान जानकारी प्राप्त करने के लिए किया जाएगा। , जो बाद में मोटर्स की मैपिंग में मदद करेगा। ग्राहक की कार में स्थापित प्रत्येक मोटर के सीरियल नंबर की पहचान करने के लिए पार्ट इंस्टॉलेशन डेटा का उपयोग किया जाएगा। अंत में, फ़ैक्टरी डेटा को मोटर के सीरियल नंबर से मिलान करने के लिए संरेखित किया जाएगा जो यह पहचान करेगा कि कौन सी फ़ैक्टरी, मशीन और प्रत्येक विशिष्ट मोटर कब बनाई गई थी।
चरण 3:क्लाउडेरा डेटा वेयरहाउस को डेटा भेजें
एक बार जब सभी डेटा को एक समृद्ध तालिका में एक साथ लाया जाता है, तो एक साधारण अपाचे स्पार्क कमांड क्लाउडरा डेटा वेयरहाउस के भीतर डेटा को एक नई तालिका में लिख देगा। यह डेटा को किसी भी डेटा वैज्ञानिकों के लिए सुलभ बना देगा जो कुछ अतिरिक्त विश्लेषण करने के लिए इसे एक्सेस करना चाहते हैं।
चरण 4:डेटा विज़ुअलाइज़ेशन डैशबोर्ड और रिपोर्ट जेनरेट करें
एक ही स्थान पर डेटा के साथ, अब ऐसी रिपोर्टें बनाई जा सकती हैं जो कर्मचारियों को बेहतर सूचित निर्णय लेने और उन क्षमताओं को खोलने में मदद करेंगी जो मौजूद नहीं थीं। मोटर स्थान को ट्रैक करने और संभावित भौगोलिक स्थानों के साथ किसी भी मुद्दे को सहसंबंधित करने के लिए हीटमैप्स बनाए जा सकते हैं, जैसे अत्यधिक ठंड या गर्मी के कारण विफलता। इस डेटा का उपयोग यह ट्रैक करने के लिए भी किया जा सकता है कि किसी निश्चित कारखाने में एक समय सीमा में कोई समस्या होने पर ग्राहक क्या प्रभावित हो सकते हैं, जिससे उन ग्राहकों को ट्रैक करना आसान हो जाता है जिन्हें रिकॉल या कुछ निवारक रखरखाव की आवश्यकता हो सकती है।
निष्कर्ष
क्लौडेरा डेटा इंजीनियरिंग ईसीसी को एक पाइपलाइन बनाने में सक्षम बनाता है जो ग्राहकों की संतुष्टि और वाहन की विश्वसनीयता में सुधार के लिए विनिर्माण और भागों के डेटा, ग्राहक उपयोग प्रकार, पर्यावरण की स्थिति, बिक्री की जानकारी और बहुत कुछ को सहसंबंधित कर सकता है। ECC ने अपने उद्देश्यों को प्राप्त किया और अपनी मोटरों के निर्माण से संबंधित डेटा को ट्रैक करके और निम्नलिखित तरीकों से लाभान्वित करके उनकी चुनौतियों का समाधान किया:
- ईसीसी ने विभिन्न डेटा स्रोतों से सुरक्षित और पारदर्शी रूप से क्यूरेटेड, गुणवत्ता वाले डेटासेट वितरित करने के लिए डेटा पाइपलाइनों को व्यवस्थित और स्वचालित करके मूल्य के लिए समय बिताया।
- ECC प्रासंगिक डेटा की पहचान करने और किसी भी अनावश्यक और डुप्लिकेट डेटा को फ़िल्टर करने में सक्षम था।
- ECC एकल फलक से डेटा पाइपलाइन निगरानी प्राप्त करने में सक्षम था, जबकि व्यवसाय प्रभावित होने से पहले समस्याओं को जल्दी से हल करने के लिए दृश्य समस्या निवारण के माध्यम से मुद्दों को जल्दी पकड़ने के लिए सतर्क रहने की स्थिति में था।
अगले ब्लॉग की तलाश करें जो रिपोर्टिंग में तल्लीन होगा जो दिखाएगा कि कैसे ईसीसी इंजीनियर इस क्यूरेटेड डेटा के खिलाफ सीडीडब्ल्यू में एड-हॉक क्वेरी चलाते हैं और साथ ही डेटा को एंटरप्राइज़ डेटा वेयरहाउस के अंदर अन्य प्रासंगिक स्रोतों से जोड़ते हैं। सीडीडब्ल्यू सभी डेटा को एक साथ लाने की सुविधा प्रदान करता है और क्वेरी किए गए परिणामों से डैशबोर्ड तक जाने के लिए एक अंतर्निहित डेटा विज़ुअलाइज़ेशन टूल प्रदान करता है। अगले के लिए बने रहें!
अधिक डेटा संग्रहण संसाधन
यह सब क्रिया में देखने के लिए, कृपया अधिक डेटा संवर्धन जानने के लिए नीचे दिए गए संबंधित लिंक पर क्लिक करें:
- वीडियो - अगर आप देखना और सुनना चाहते हैं कि इसे कैसे बनाया गया, तो लिंक पर वीडियो देखें।
- ट्यूटोरियल - यदि आप इसे अपनी गति से करना चाहते हैं, तो स्क्रीनशॉट के साथ एक विस्तृत वॉकथ्रू देखें और इसे कैसे सेट करें और कैसे निष्पादित करें, इसके लिए लाइन-दर-लाइन निर्देश देखें।
- Meetup - अगर आप Cloudera के विशेषज्ञों से सीधे बात करना चाहते हैं, तो लाइव स्ट्रीम प्रस्तुति देखने के लिए कृपया वर्चुअल मीटअप में शामिल हों। अंत में सीधे प्रश्नोत्तर के लिए समय होगा।
- उपयोगकर्ता - उपयोगकर्ताओं के लिए विशिष्ट तकनीकी सामग्री देखने के लिए, लिंक पर क्लिक करें।



