हमारे पिछले Hadoop tut . में ओ रियाल , हमने आपको InputFormat. . का विस्तृत विवरण प्रदान किया है अब इस ब्लॉग में, हम Hadoop OutputFormat को कवर करने जा रहे हैं।
हम चर्चा करेंगे कि Hadoop में OutputFormat क्या है, MapReduce OutputFormat में RecordWritter क्या है। हम MapReduce में OutputFormat के प्रकारों को भी कवर करेंगे।
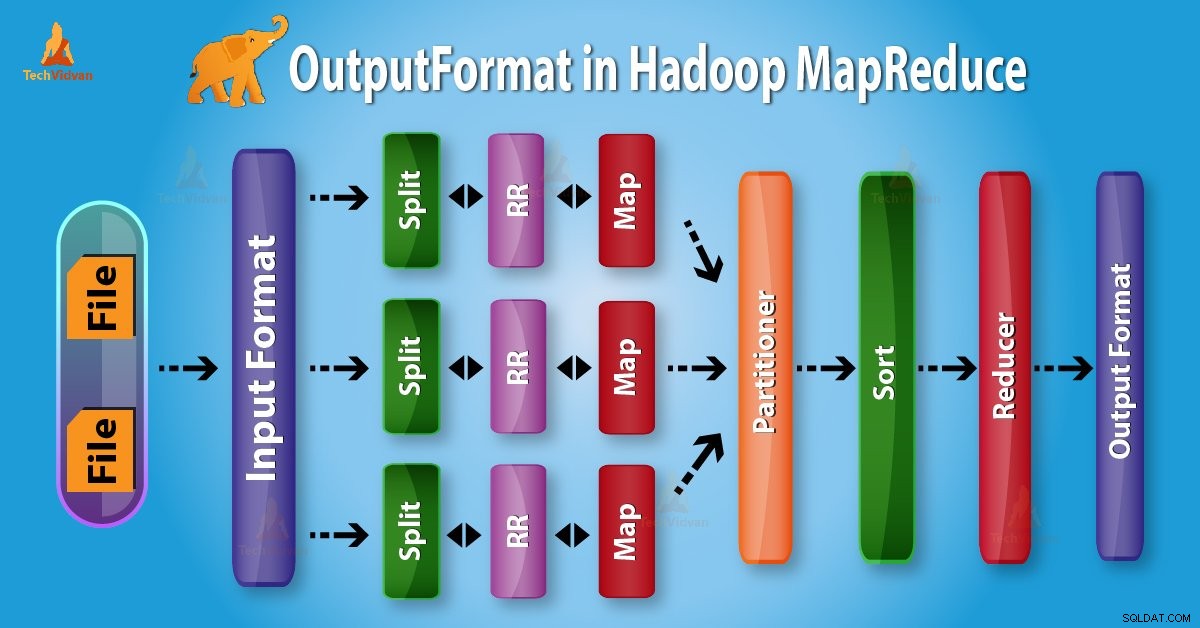
Hadoop OutputFormat का परिचय
आउटपुटफ़ॉर्मैट मैप-रिड्यूस जॉब के निष्पादन के लिए आउटपुट स्पेसिफिकेशन की जाँच करें। यह वर्णन करता है कि आउटपुट फाइलों में आउटपुट लिखने के लिए रिकॉर्डवाइटर कार्यान्वयन का उपयोग कैसे किया जाता है।
OutputFormat के साथ शुरू करने से पहले, आइए पहले जानें कि RecordWriter क्या है और MapReduce में RecordWriter का क्या काम है?
<एच4>1. Hadoop MapReduce में RecordWriterजैसा कि हम जानते हैं, Reducer मैपर takes लेता है इनपुट के रूप में मध्यवर्ती आउटपुट। फिर यह उन पर एक रिड्यूसर फ़ंक्शन चलाता है जो आउटपुट उत्पन्न करता है जो फिर से शून्य या अधिक की-वैल्यू पेयर होता है।
इसलिए, MapReduce जॉब एक्जीक्यूशन में RecordWriter इन आउटपुट की-वैल्यू पेयर को रेड्यूसर फेज से आउटपुट फाइल में लिखता है।
<एच4>2. Hadoop OutputFormatऊपर से यह स्पष्ट है कि RecordWriter रेड्यूसर से आउटपुट डेटा लेता है। फिर यह इस डेटा को आउटपुट फाइलों में लिखता है। OutputFormat यह निर्धारित करता है कि RecordWriter द्वारा आउटपुट फाइलों में इन आउटपुट की-वैल्यू पेयर को किस तरह से लिखा जाता है।
OutputFormat और InputFormat फ़ंक्शन समान हैं। OutputFormat उदाहरणों का उपयोग स्थानीय डिस्क पर या HDFS. . में फ़ाइलों को लिखने के लिए किया जाता है MapReduce में आउटपुट विनिर्देश के आधार पर कार्य निष्पादन;
- Hadoop MapReduce जॉब जाँचता है कि आउटपुट निर्देशिका पहले से मौजूद नहीं है।
- MapReduce जॉब में OutputFormat रिकॉर्डवाइटर कार्यान्वयन प्रदान करता है जिसका उपयोग जॉब की आउटपुट फाइल लिखने के लिए किया जाता है। फिर आउटपुट फाइल फाइल सिस्टम में स्टोर हो जाती है।
फ्रेमवर्क FileOutputFormat.setOutputPath() . का उपयोग करता है आउटपुट निर्देशिका सेट करने की विधि।
MapReduce में OutputFormat के प्रकार
OutputFormat कई प्रकार के होते हैं जो इस प्रकार हैं:
<एच4>1. TextOutputFormatडिफ़ॉल्ट आउटपुटफ़ॉर्मैट टेक्स्टऑटपुटफ़ॉर्मैट है। यह टेक्स्ट फाइलों की अलग-अलग पंक्तियों पर (कुंजी, मान) जोड़े लिखता है। इसकी चाबियां और मूल्य किसी भी प्रकार के हो सकते हैं। इसके पीछे कारण यह है कि TextOutputFormat उन्हें toString() . पर कॉल करके स्ट्रिंग में बदल देता है उन पर।
यह की-वैल्यू पेयर को टैब कैरेक्टर से अलग करता है। MapReduce.output.textoutputformat.separator . का उपयोग करके संपत्ति हम इसे बदल भी सकते हैं।
KeyValueTextOutputFormat का उपयोग इन आउटपुट टेक्स्ट फ़ाइलों को पढ़ने के लिए भी किया जाता है।
<एच4>2. SequenceFileOutputFormatयह OutputFormat इसके आउटपुट के लिए सीक्वेंस फाइल लिखता है। SequenceFileInputFormat भी MapReduce नौकरियों के बीच मध्यवर्ती प्रारूप का उपयोग है। यह फ़ाइल में मनमाने डेटा प्रकारों को क्रमबद्ध करता है।
और संबंधित SequenceFileInputFormat फ़ाइल को उसी प्रकार में deserialize करेगा। यह डेटा को अगले मैपर . को प्रस्तुत करता है उसी तरह जैसे पिछले रेड्यूसर द्वारा उत्सर्जित किया गया था। स्थैतिक विधियाँ संपीड़न को भी नियंत्रित करती हैं।
<एच4>3. SequenceFileAsBinaryOutputFormatयह SequenceFileInputFormat का दूसरा रूप है। यह बाइनरी प्रारूप में फ़ाइल को अनुक्रमित करने के लिए कुंजी और मान भी लिखता है।
<एच4>4. MapFileOutputFormatयह FileOutputFormat का दूसरा रूप है। यह आउटपुट को मैप फाइल के रूप में भी लिखता है। फ्रेमवर्क क्रम में MapFile में एक कुंजी जोड़ता है। इसलिए हमें यह सुनिश्चित करने की आवश्यकता है कि रेड्यूसर क्रमबद्ध क्रम में चाबियों का उत्सर्जन करता है।
5. एकाधिक आउटपुट
यह प्रारूप उन फ़ाइलों को डेटा लिखने की अनुमति देता है जिनके नाम आउटपुट कुंजियों और मानों से प्राप्त होते हैं।
<एच4>6. LazyOutputFormatMapReduce कार्य निष्पादन में, FileOutputFormat कभी-कभी आउटपुट फ़ाइलें बनाता है, भले ही वे खाली हों। LazyOutputFormat भी एक रैपर OutputFormat है।
<एच4>7. DBOutputFormatयह रिलेशनल डेटाबेस और HBase को लिखने के लिए OutputFormat है। यह प्रारूप कम आउटपुट को SQL तालिका में भी भेजता है। यह कुंजी-मूल्य जोड़े को भी स्वीकार करता है। इसमें key का एक type होता है जो DBwritable को बढ़ाता है।
निष्कर्ष
इसलिए जरूरत के हिसाब से अलग-अलग OutputFormats का इस्तेमाल किया जाता है। आशा है कि आपको यह ब्लॉग मददगार लगा होगा। यदि आपके पास Hadoop OutputFormat के बारे में कोई प्रश्न है, तो कृपया एक टिप्पणी बॉक्स में एक टिप्पणी छोड़ दें। हमें उन्हें हल करने में खुशी होगी।



