यह Hadoop ट्यूटोरियल MapReduce फेरबदल और छँटाई के बारे में सब कुछ है। यहां हम आपको Hadoop शफलिंग और सॉर्टिंग चरण का विस्तृत विवरण प्रदान करेंगे।
सबसे पहले हम चर्चा करेंगे कि MapReduce शफलिंग क्या है, इसके बाद MapReduce सॉर्टिंग के साथ, फिर हम MapReduce सेकेंडरी सॉर्टिंग चरण को विस्तार से कवर करेंगे।
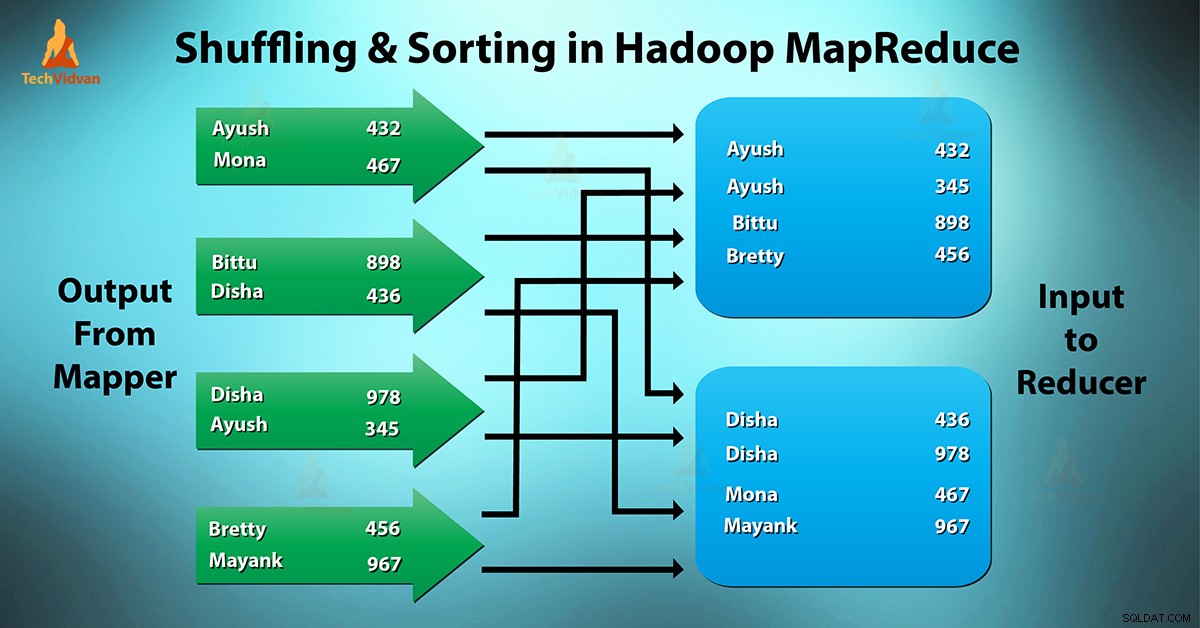
MapReduce शफलिंग और सॉर्टिंग क्या है?
फेरबदल वह प्रक्रिया है जिसके द्वारा वह मैपर . को स्थानांतरित करता है reducer. . के लिए मध्यवर्ती आउटपुट रेड्यूसर के आधार पर रेड्यूसर को 1 या अधिक कुंजी और संबद्ध मान मिलते हैं।
इंटरमीडिएट की - मैपर द्वारा उत्पन्न मूल्य स्वचालित रूप से कुंजी द्वारा क्रमबद्ध किया जाता है। सॉर्ट फेज़ में मैप आउटपुट का मर्जिंग और सॉर्टिंग होता है।
Hadoop में फेरबदल और छँटाई एक साथ होती है।
MapReduce में फेरबदल
मैपर्स से रिड्यूसर में डेटा ट्रांसफर करने की प्रक्रिया में फेरबदल हो रहा है। यह वह प्रक्रिया भी है जिसके द्वारा सिस्टम सॉर्ट करता है। फिर यह मैप आउटपुट को इनपुट के रूप में रिड्यूसर में ट्रांसफर करता है। यही कारण है कि फेरबदल चरण रिड्यूसर के लिए आवश्यक है।
अन्यथा, उनके पास कोई इनपुट नहीं होगा (या प्रत्येक मैपर से इनपुट)। चूंकि मानचित्र चरण समाप्त होने से पहले ही फेरबदल शुरू हो सकता है। तो यह कुछ समय बचाता है और कम समय में कार्यों को पूरा करता है।
MapReduce में क्रमित करना
MapReduce Framework स्वचालित रूप से मैपर द्वारा उत्पन्न कीज़ को सॉर्ट करता है। इस प्रकार, रेड्यूसर शुरू करने से पहले, सभी मध्यवर्ती कुंजी-मूल्य जोड़े कुंजी द्वारा क्रमबद्ध होते हैं, न कि मूल्य से। यह प्रत्येक रेड्यूसर को दिए गए मानों को क्रमबद्ध नहीं करता है। वे किसी भी क्रम में हो सकते हैं।
MapReduce जॉब में सॉर्ट करने से रेड्यूसर को आसानी से अंतर करने में मदद मिलती है जब एक नया कम कार्य शुरू होना चाहिए।
यह reducer के लिए समय बचाता है। MapReduce में रेड्यूसर एक नया कम कार्य शुरू करता है जब सॉर्ट किए गए इनपुट डेटा में अगली कुंजी पिछले से अलग होती है। प्रत्येक कम करने वाला कार्य कुंजी मान जोड़े को इनपुट के रूप में लेता है और आउटपुट के रूप में कुंजी-मूल्य जोड़ी उत्पन्न करता है।
ध्यान देने वाली महत्वपूर्ण बात यह है कि यदि आप शून्य रेड्यूसर (setNumReduceTasks (0)) निर्दिष्ट करते हैं, तो Hadoop MapReduce में फेरबदल और छँटाई बिल्कुल नहीं होगी।
यदि रेड्यूसर शून्य है, तो MapReduce कार्य मानचित्र चरण पर रुक जाता है। और मानचित्र चरण में किसी भी प्रकार की छँटाई शामिल नहीं है (यहां तक कि मानचित्र चरण भी तेज़ है)।
MapReduce में सेकेंडरी सॉर्टिंग
यदि हम रेड्यूसर वैल्यू को सॉर्ट करना चाहते हैं, तो हम सेकेंडरी सॉर्टिंग तकनीक का उपयोग करते हैं। यह तकनीक हमें प्रत्येक रेड्यूसर को दिए गए मानों (आरोही या अवरोही क्रम में) को क्रमबद्ध करने में सक्षम बनाती है।
निष्कर्ष
अंत में, MapReduce शफलिंग और सॉर्टिंग मैपर इंटरमीडिएट आउटपुट को सारांशित करने के लिए एक साथ होता है। यदि आप शून्य रिड्यूसर (setNumReduceTasks (0)) निर्दिष्ट करते हैं, तो Hadoop शफलिंग-सॉर्टिंग नहीं होगी।
फ्रेमवर्क सभी इंटरमीडिएट की-वैल्यू पेयर को कुंजी के आधार पर सॉर्ट करता है, वैल्यू के आधार पर नहीं। यह मूल्य के आधार पर छँटाई के लिए द्वितीयक छँटाई का उपयोग करता है। यदि आपके पास MapReduce फेरबदल और छँटाई चरण से संबंधित कोई सुझाव या प्रश्न है, तो कृपया एक टिप्पणी बॉक्स में एक टिप्पणी छोड़ दें।
हमें उनका समाधान करने में खुशी होगी.



