HBase कई सर्वरों को डेटा लिखता है, जिसे क्षेत्र सर्वर . कहा जाता है ।
प्रत्येक क्षेत्र सर्वर में एक या कई क्षेत्र होते हैं , और डेटा इन क्षेत्रों पर आवंटित किया गया है; Hbase नियंत्रित करेगा कि कौन सा क्षेत्र सर्वर किस क्षेत्र (क्षेत्रों) को नियंत्रित करता है।
क्षेत्र संख्या को तालिका निर्माण स्तर पर परिभाषित किया जा सकता है:
[hbase@gw vagrant]$ kinit -kt /etc/security/keytabs/hbase.headless.keytab hbase[hbase@gw vagrant]$ hbase shellhbase(main):001:0> 'table2' बनाएं , 'columnfamily1', {NUMREGIONS => 5, SPLITALGO => 'HexStringSplit'} हमने पहले परिभाषित किया है कि क्षेत्र सर्वर संख्या और वांछित क्षेत्रों के आकार के संबंध में 5 क्षेत्र सटीक होंगे, और 2 बुनियादी एल्गोरिदम की आपूर्ति की जाती है, HexStringSplit और UniformSplit (लेकिन आप अपना जोड़ सकते हैं)।
आप अपने स्वयं के विभाजन प्रदान कर सकते हैं:
hbase(main):001:0> 'table2', 'columnfamily1', {NUMREGIONS => 5, SPLITS=> ['a', 'b', 'c']} बनाएं
तो यह तालिका2 हमारे 5 क्षेत्रों के साथ बनाया गया है, आइए HBase webUI पर जाकर देखें कि यह कैसा दिखता है:
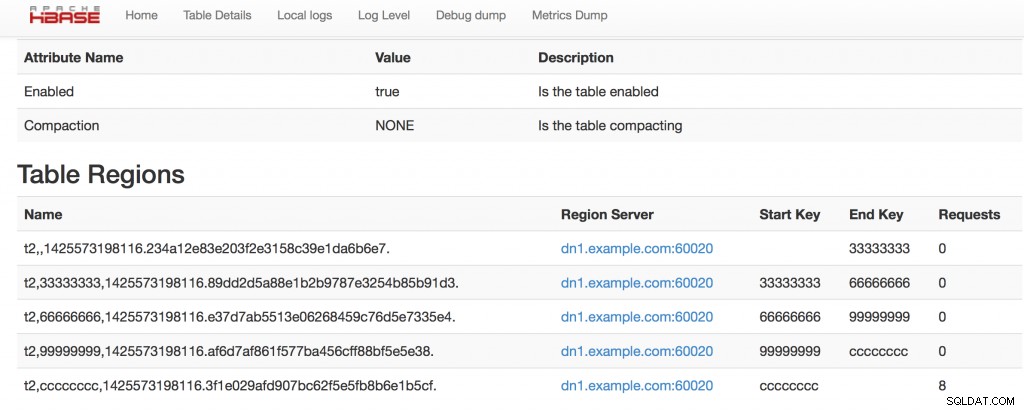 हमारे पास हमारे 5 क्षेत्र हैं, कुंजी पुनर्विभाजन देखें, और हम क्षेत्रों के नामों में देख सकते हैं:table_name, start_key,end_key,timestamp.ENCODED_REGIONNAME.
हमारे पास हमारे 5 क्षेत्र हैं, कुंजी पुनर्विभाजन देखें, और हम क्षेत्रों के नामों में देख सकते हैं:table_name, start_key,end_key,timestamp.ENCODED_REGIONNAME.
तो अब, यदि हम क्षेत्रों को मर्ज करना चाहते हैं, तो हम hbase शेल में merge_region का उपयोग कर सकते हैं।
क्षेत्रों को आसन्न होना चाहिए।
hbase(main):010:0> merge_region '234a12e83e203f2e3158c39e1da6b6e7', '89dd2d5a88e1b2b9787e3254b85b91d3'0 पंक्ति (पंक्तियाँ) 0.0140 सेकंड में हाँ।
ध्यान दें कि परिणाम क्षेत्र का ENCODED_REGIONNAME नया है।
hbase(main):012:0> merge_region 'bfad503057fca37bd60b5a83109f7dc6','e37d7ab5513e06268459c76d5e7335e4'0 पंक्ति (पंक्तियों) 0.0040 सेकंड में अंत में सभी क्षेत्रों को मिला दें!
hbase (मुख्य):013:0> merge_region '0f5fc22bf0beacbf83c1ad562324c778','af6d7af861f577ba456cff88bf5e5e38','3f1e029afd907bc62f5e5fb901'5fb8b6e'3f1e029afd907bc62f5e5fb8b57b1'
तब हम देख सकते हैं कि केवल एक क्षेत्र बचा है:

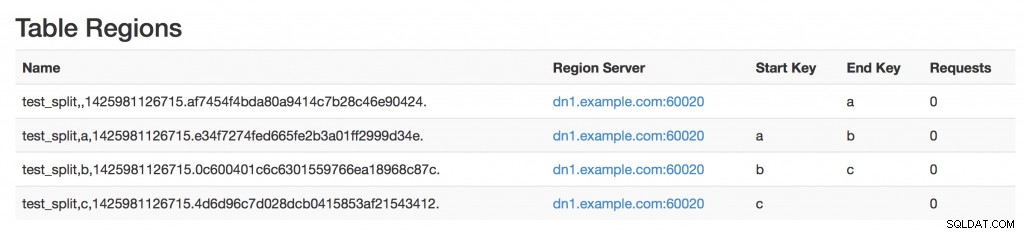
रिकॉर्ड के लिए, यदि आप अपनी चाबियों के पुनर्विभाजन को जानते हैं, तो आप पूर्व-विभाजित HBase तालिका बना सकते हैं:या तो SPLITS पास करके, या SPLITS_FILE प्रदान करके जिसमें विभाजन के बिंदु होते हैं (इसलिए पंक्ति संख्या =क्षेत्र -1)
आदेश से अवगत रहें, {...} से पहले SPLITS_FILE काम नहीं करेगा।
[hbase@gw vagrant]$ echo "a\nb\nc"> /tmp/splits.txt;[hbase@gw vagrant]$ kinit -kt /etc/security/keytabs/hbase.headless. keytab hbase[hbase@gw vagrant]$ hbase shellhbase(main):011:0> 'test_split' बनाएं, { NAME=> 'cf', VERSIONS => 1, TTL => 69200 }, SPLITS_FILE => '/tmp/ splits.txt'
और परिणाम: