हमारे पिछले Hadoop ट्यूटोरियल . में , हमने Hadoop पार्टिशनर . का अध्ययन किया है विस्तार से। अब हम Hadoop MapReduce में InputSplit पर चर्चा करने जा रहे हैं।
यहां, हम Hadoop InputSplit, MapReduce में InputSplit की आवश्यकता को कवर करेंगे। हम इस बात पर भी चर्चा करेंगे कि कैसे Hadoop MapReduce में ये InputSplits बड़े विस्तार से बनाए जाते हैं।
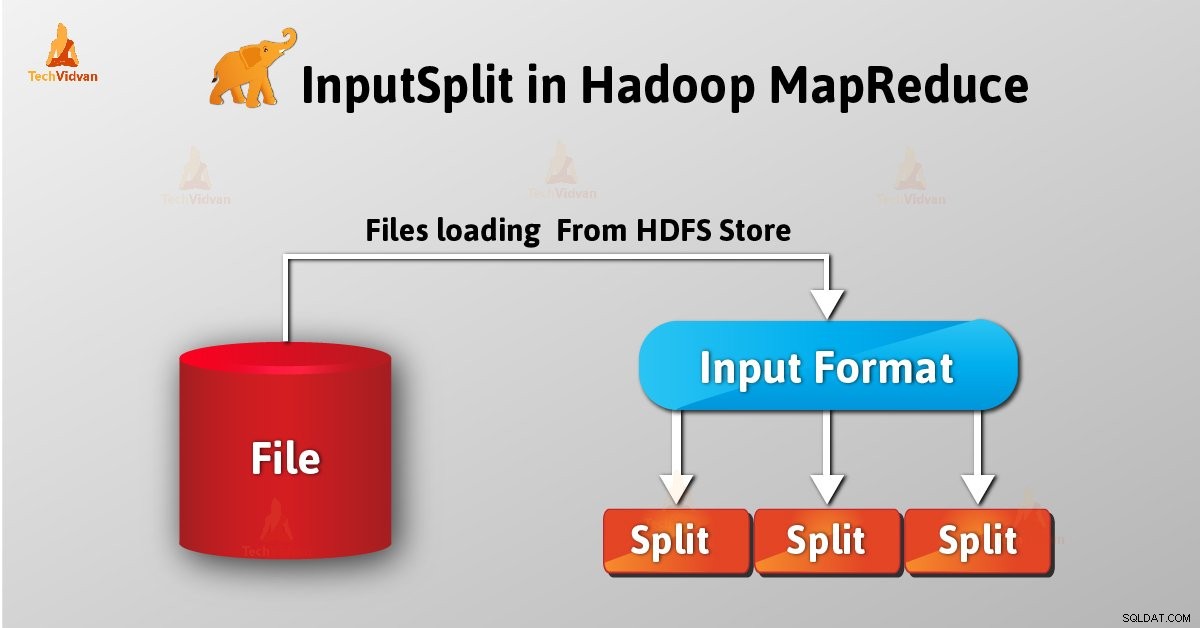
Hadoop में InputSplit का परिचय
InputSplit Hadoop MapReduce में डेटा का तार्किक प्रतिनिधित्व है। यह उस डेटा का प्रतिनिधित्व करता है जिसे व्यक्तिगत मैपर प्रक्रियाएं। इस प्रकार मानचित्र कार्यों की संख्या इनपुटस्प्लिट्स की संख्या के बराबर होती है। फ्रेमवर्क विभाजन को रिकॉर्ड में विभाजित करता है, जिसे मैपर प्रोसेस करता है।
MapReduce InputSplit लंबाई बाइट्स में मापी गई है। प्रत्येक इनपुटस्प्लिट में भंडारण स्थान (होस्टनाम तार) होते हैं। MapReduce सिस्टम स्टोरेज लोकेशन का इस्तेमाल करके मैप टास्क को स्प्लिट के डेटा के जितना करीब हो सके रखता है।
फ्रेमवर्क मानचित्र कार्यों को विभाजन के आकार के क्रम में संसाधित करता है ताकि सबसे बड़ा पहले संसाधित हो जाए (लालची सन्निकटन एल्गोरिदम)। यह कार्य चलाने के समय को कम करता है।
ध्यान देने वाली मुख्य बात यह है कि इनपुटस्प्लिट में इनपुट डेटा नहीं होता है; यह केवल डेटा का संदर्भ है।
Hadoop MapReduce में InputSplits कैसे बनाए जाते हैं?
एक उपयोगकर्ता के रूप में, हम सीधे Hadoop में InputSplit के साथ InputFormat के रूप में डील नहीं करते हैं (जैसा कि InputFormat Inputsplit बनाने और रिकॉर्ड में विभाजित करने के लिए जिम्मेदार है) इसे बनाता है। FileInputFormat फ़ाइल को 128MB भागों में विभाजित करता है।
साथ ही, मैप किए गए . को सेट करके .मिनट .विभाजित .आकार मेप्रेड-साइट . में पैरामीटर .एक्सएमएल उपयोगकर्ता आवश्यकता के अनुसार मूल्य बदल सकता है। इसके अलावा, हम किसी विशेष MapReduce जॉब को सबमिट करने के लिए उपयोग की जाने वाली जॉब ऑब्जेक्ट में पैरामीटर को ओवरराइड कर सकते हैं।
एक कस्टम इनपुटफ़ॉर्मैट लिखकर हम यह भी नियंत्रित कर सकते हैं कि फ़ाइल को कैसे विभाजित किया जाए।
इनपुटस्प्लिट उपयोगकर्ता परिभाषित है। उपयोगकर्ता MapReduce प्रोग्राम में डेटा के आकार के आधार पर विभाजित आकार को भी नियंत्रित कर सकता है। इसलिए, MapReduce कार्य निष्पादन में मानचित्र कार्यों की संख्या InputSplits की संख्या के बराबर होती है।
‘getSplit ()’ . पर कॉल करके , क्लाइंट नौकरी के लिए विभाजन की गणना करता है। फिर इसे एप्लिकेशन मास्टर को भेजा गया, जो उनके भंडारण स्थानों का उपयोग मानचित्र कार्यों को शेड्यूल करने के लिए करता है जो उन्हें क्लस्टर पर संसाधित करेगा।
उसके बाद नक्शा कार्य विभाजन को createRecordReader() . को पास कर देता है तरीका। इससे उसे RecordReader . प्राप्त होता है विभाजन के लिए। फिर RecordReader (की-वैल्यू पेयर) रिकॉर्ड जेनरेट करता है , जिसे वह मैप फंक्शन में भेजता है।
निष्कर्ष
निष्कर्ष में हम कह सकते हैं कि, इनपुटस्प्लिट उस डेटा का प्रतिनिधित्व करता है जिसे व्यक्तिगत मैपर संसाधित करता है। प्रत्येक विभाजन के लिए एक नक्शा कार्य बनाया जाता है। इसलिए, InputFormat InputSplit बनाता है।
यदि आपके पास MapReduce में इनपुटस्प्लिट के बारे में कोई प्रश्न है, तो कृपया नीचे दिए गए अनुभाग में एक टिप्पणी छोड़ दें।



