प्रदर्शन ट्यूनिंग आपके Hadoop . को अनुकूलित करने में सहायता करेगी प्रदर्शन। इस ब्लॉग में, हम MapReduce जॉब ऑप्टिमाइजेशन के लिए उन सभी तकनीकों पर चर्चा करने जा रहे हैं।
इस MapReduce ट्यूटोरियल में, हम आपको MapReduce जॉब ऑप्टिमाइज़ेशन के लिए 6 महत्वपूर्ण टिप्स प्रदान करेंगे जैसे कि आपके क्लस्टर का उचित कॉन्फ़िगरेशन, LZO कम्प्रेशन उपयोग, MapReduce कार्यों की संख्या की उचित ट्यूनिंग आदि।
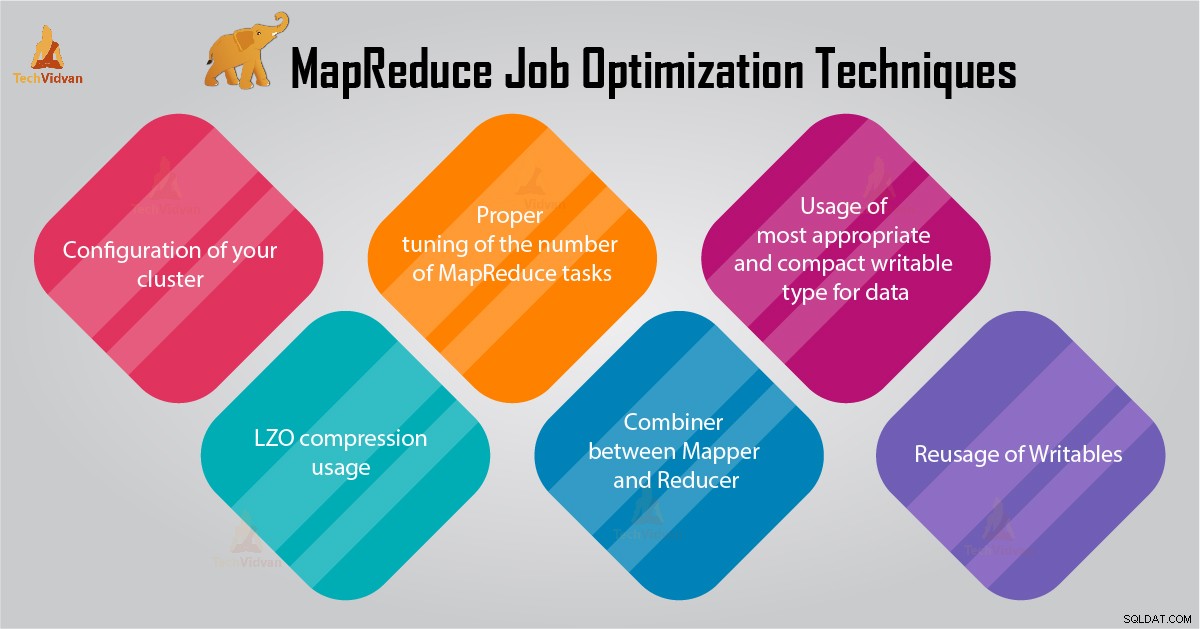
MapReduce जॉब ऑप्टिमाइज़ेशन के लिए टिप्स
नीचे कुछ MapReduce जॉब ऑप्टिमाइज़ेशन तकनीकें दी गई हैं जो आपको MapReduce जॉब परफॉर्मेंस को ऑप्टिमाइज़ करने में मदद करेंगी।
<एच4>1. आपके क्लस्टर का उचित विन्यास- -noatime . के साथ विकल्प Dfs और MapReduce संग्रहण माउंट किए गए हैं। यह एक्सेस समय को अक्षम कर देगा। इस प्रकार I/O प्रदर्शन में सुधार होता है।
- टास्कट्रैकर और डेटानोड मशीनों पर RAID से बचने की कोशिश करें। यह आम तौर पर प्रदर्शन को कम करता है।
- सुनिश्चित करें कि आपने mapred.local.dir configured को कॉन्फ़िगर किया है और dfs.data.dir अपने प्रत्येक डिस्क पर एक निर्देशिका को इंगित करने के लिए। यह सुनिश्चित करने के लिए है कि आपकी सभी I/O क्षमता का उपयोग किया जाता है।
- आपको सॉफ्टवेयर के साथ स्वैप उपयोग और नेटवर्क उपयोग के ग्राफ की निगरानी करनी चाहिए। यदि आप देखते हैं कि स्वैप का उपयोग किया जा रहा है, तो आपको mapred.child.java.opts में प्रत्येक कार्य के लिए आवंटित RAM की मात्रा को कम करना चाहिए ।
- सुनिश्चित करें कि आपके पास अपने डिस्क ड्राइव की स्वास्थ्य स्थिति के लिए स्मार्ट मॉनिटरिंग होनी चाहिए। यह MapReduce प्रदर्शन ट्यूनिंग के लिए महत्वपूर्ण अभ्यासों में से एक है।
इंटरमीडिएट डेटा के लिए, यह हमेशा एक अच्छा विचार है। हर Hadoop जॉब जो मैप आउटपुट की नगण्य मात्रा उत्पन्न करता है, उसे LZO के साथ इंटरमीडिएट डेटा कंप्रेशन से लाभ मिलेगा।
हालांकि LZO CPU में थोड़ा सा ओवरहेड जोड़ता है, यह फेरबदल के दौरान डिस्क IO की मात्रा को कम करके समय बचाता है।
mapred.compress.map.output सेट करें LZO संपीड़न को सक्षम करने के लिए सही पर
<एच4>3. MapReduce कार्यों की संख्या की उचित ट्यूनिंग- MapReduce जॉब में, यदि प्रत्येक कार्य में 30-40 सेकंड या अधिक समय लगता है, तो यह कार्यों की संख्या को कम कर देगा। मैपर या reducer प्रक्रिया में निम्नलिखित चीजें शामिल हैं:सबसे पहले, आपको JVM (स्मृति में लोड किया गया JVM) प्रारंभ करने की आवश्यकता है। फिर आपको JVM को इनिशियलाइज़ करना होगा। और प्रसंस्करण (मैपर/रेड्यूसर) के बाद आपको JVM को डी-इनिशियलाइज़ करना होगा। और ये JVM कार्य बहुत महंगे हैं। मान लीजिए कि कोई ऐसा मामला है जिसमें मैपर किसी कार्य को केवल 20-30 सेकंड के लिए चलाता है। इसके लिए हमें JVM को प्रारंभ/प्रारंभ/बंद करना होगा। इसमें काफी समय लग सकता है। इसलिए, कार्य को कम से कम 1 मिनट तक चलाने की सख्ती से अनुशंसा की जाती है।
- यदि किसी कार्य में 1TB से अधिक इनपुट है। फिर आपको इनपुट डेटासेट के ब्लॉक आकार को 256M या 512M तक बढ़ाने पर विचार करना चाहिए। तो कार्यों की संख्या कम होगी। आप Hadoop distcp –Hdfs.block.size=$[256*1024*1024] /path/to/inputdata /path/to/inputdata-with-largeblocks कमांड का उपयोग करके ब्लॉक का आकार बदल सकते हैं।
- जैसा कि हम जानते हैं कि प्रत्येक कार्य कम से कम 30-40 सेकंड तक चलता है। आपको मैपर कार्यों की संख्या को क्लस्टर में मैपर स्लॉट की संख्या के कुछ गुणकों तक बढ़ाना चाहिए।
- अधिकांश कार्यों के लिए - बहुत अधिक कम कार्य न करें। क्लस्टर में रिड्यूस स्लॉट्स की संख्या के बराबर या उससे थोड़ा कम रिड्यूस टास्क की संख्या।
यदि एल्गोरिथम में किसी भी प्रकार के समुच्चय की गणना करना शामिल है, तो हमें एक Combiner का उपयोग करना चाहिए। डेटा रेड्यूसर को हिट करने से पहले कॉम्बिनर कुछ एकत्रीकरण करता है।
डिस्क पर लिखे जाने वाले डेटा की मात्रा को कम करने के लिए Hadoop MapReduce फ्रेमवर्क समझदारी से चलता है। और उस डेटा को मानचित्र और गणना के चरणों को कम करने के बीच स्थानांतरित किया जाना है।
5. डेटा के लिए सबसे उपयुक्त और कॉम्पैक्ट लिखने योग्य प्रकार का उपयोग
बड़े डेटा उपयोगकर्ता Hadoop स्ट्रीमिंग से Java MapReduce पर स्विच करने के लिए टेक्स्ट लिखने योग्य प्रकार का अनावश्यक रूप से उपयोग करते हैं। पाठ सुविधाजनक हो सकता है। संख्यात्मक डेटा को UTF8 स्ट्रिंग्स में और उससे कनवर्ट करना अक्षम है। और वास्तव में CPU समय का एक महत्वपूर्ण हिस्सा बना सकता है।
<एच4>6. लिखने योग्य का पुन:उपयोगकई MapReduce उपयोगकर्ता एक बहुत ही सामान्य गलती करते हैं जो एक मैपर/रेड्यूसर से प्रत्येक आउटपुट के लिए एक नई लिखने योग्य वस्तु आवंटित करना है। मान लीजिए, उदाहरण के लिए, शब्द-गणना मैपर कार्यान्वयन इस प्रकार है:
public void map(...) {
...
for (String word: words) {
output.collect(new Text(word), new IntWritable(1));
} यह कार्यान्वयन हजारों अल्पकालिक वस्तुओं के आवंटन का कारण बनता है। जबकि जावा कचरा संग्रहकर्ता इससे निपटने में उचित काम करता है, यह लिखने में अधिक कुशल है:
class MyMapper ... {
Text wordText = new Text();
IntWritable one = new IntWritable(1);
public void map(...) {
... for (String word: words)
{
wordText.set(word);
output.collect(word, one); }
}
} निष्कर्ष
इसलिए, कई MapReduce जॉब ऑप्टिमाइजेशन तकनीकें हैं जो आपको MapReduce जॉब को ऑप्टिमाइज़ करने में मदद करती हैं। जैसे मैपर और रेड्यूसर के बीच कंबाइनर का उपयोग करना, LZO कम्प्रेशन उपयोग द्वारा, MapReduce कार्यों की संख्या की उचित ट्यूनिंग, लिखने योग्य का पुन:उपयोग।
यदि आपको MapReduce जॉब ऑप्टिमाइजेशन के लिए कोई अन्य तकनीक मिलती है, तो हमें नीचे दिए गए कमेंट सेक्शन में बताएं।



