रखरखाव एक ऐसी चीज है जिससे एक ऑपरेशन टीम बच नहीं सकती है। संपूर्ण प्रदर्शन को बेहतर बनाने के लिए नई सुविधाओं का उपयोग करते हुए सर्वरों को नवीनतम सॉफ़्टवेयर, हार्डवेयर और प्रौद्योगिकी के साथ रहना होगा ताकि यह सुनिश्चित हो सके कि सिस्टम स्थिर हैं और न्यूनतम जोखिम के साथ चल रहे हैं।
निस्संदेह, रखरखाव कार्यों की एक लंबी सूची है जिसे सिस्टम प्रशासकों द्वारा निष्पादित किया जाना है, खासकर जब यह महत्वपूर्ण प्रणालियों की बात आती है। कुछ कार्यों को नियमित अंतराल पर करना पड़ता है, जैसे दैनिक, साप्ताहिक, मासिक और वार्षिक। कुछ को तुरंत करना होगा, तत्काल। फिर भी, किसी भी रखरखाव के संचालन से एक और बड़ी समस्या नहीं होनी चाहिए, और व्यवसाय में किसी भी रुकावट से बचने के लिए किसी भी रखरखाव को अतिरिक्त देखभाल के साथ संभाला जाना चाहिए।
रखरखाव जारी रहने के दौरान संदिग्ध स्थिति और झूठे अलार्म मिलना आम बात है। यह अपेक्षित है क्योंकि रखरखाव अवधि के दौरान, जब तक रखरखाव कार्य पूरा नहीं हो जाता तब तक सर्वर काम नहीं करेगा। ClusterControl, आपके ओपन-सोर्स डेटाबेस के लिए सर्व-समावेशी प्रबंधन और निगरानी प्लेटफ़ॉर्म, इन परिस्थितियों को समझने के लिए कॉन्फ़िगर किया जा सकता है ताकि आपके रखरखाव की दिनचर्या को सरल बनाया जा सके, इसके द्वारा प्रदान की जाने वाली निगरानी और स्वचालन सुविधाओं का त्याग किए बिना।
रखरखाव मोड
ClusterControl ने संस्करण 1.4.0 में रखरखाव मोड पेश किया, जहाँ आप एक व्यक्तिगत नोड को रखरखाव में लगा सकते हैं जो ClusterControl को अलार्म बढ़ाने और निर्दिष्ट अवधि के लिए सूचनाएं भेजने से रोकता है। रखरखाव मोड को ClusterControl UI से और "s9s" नामक ClusterControl CLI टूल का उपयोग करके भी कॉन्फ़िगर किया जा सकता है। UI से, बस नोड्स -> नोड चुनें -> नोड क्रियाएँ -> शेड्यूल रखरखाव मोड पर जाएं :
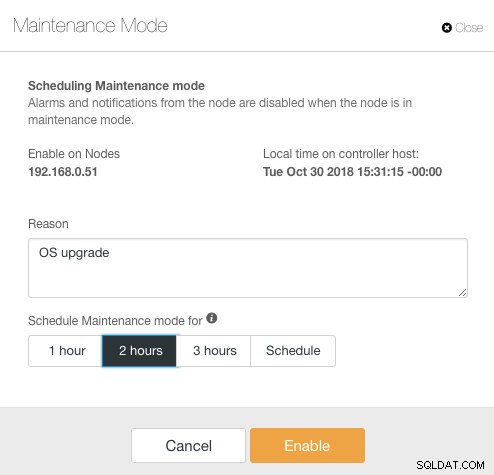
यहां, कोई पूर्व-निर्धारित समय के लिए रखरखाव अवधि निर्धारित कर सकता है या उसके अनुसार शेड्यूल कर सकता है। आप ऑडिटिंग उद्देश्यों के लिए उपयोगी, अपग्रेड शेड्यूल करने का कारण भी लिख सकते हैं। रखरखाव मोड सक्रिय होने पर आपको निम्न सूचना देखनी चाहिए:
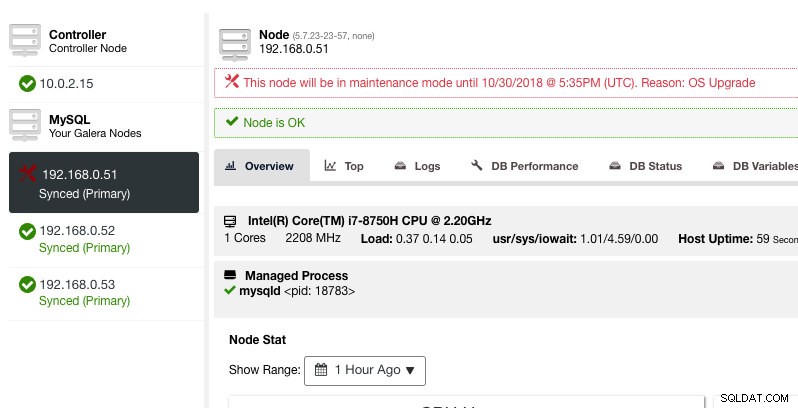
ClusterControl नोड को नीचा नहीं करेगा, इसलिए नोड की स्थिति तब तक बनी रहती है जब तक कि आप राज्य को बदलने वाली कोई क्रिया नहीं करते हैं। इस नोड के लिए अलार्म और सूचनाएं रखरखाव अवधि समाप्त होने के बाद फिर से सक्रिय हो जाएंगी, या ऑपरेटर नोड क्रियाएँ -> रखरखाव मोड अक्षम करें पर जाकर इसे स्पष्ट रूप से अक्षम कर देगा। ।
ध्यान दें कि यदि स्वचालित नोड पुनर्प्राप्ति सक्षम है, तो ClusterControl रखरखाव मोड की स्थिति की परवाह किए बिना हमेशा एक नोड पुनर्प्राप्त करेगा। ClusterControl आपके रखरखाव कार्यों में हस्तक्षेप करने से बचने के लिए नोड पुनर्प्राप्ति को अक्षम करना न भूलें, यह शीर्ष सारांश बार से किया जा सकता है।
रखरखाव मोड को ClusterControl CLI या "s9s" के माध्यम से भी कॉन्फ़िगर किया जा सकता है। आप रखरखाव अवधियों को सूचीबद्ध करने और उनमें हेरफेर करने के लिए "s9s रखरखाव" कमांड का उपयोग कर सकते हैं। निम्न कमांड लाइन कल नोड 192.168.1.121 के लिए एक घंटे की रखरखाव विंडो शेड्यूल करती है:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."अधिक विवरण और उदाहरणों के लिए, s9s रखरखाव दस्तावेज देखें।
क्लस्टर-वाइड रखरखाव मोड
इस लेखन के समय, रखरखाव मोड कॉन्फ़िगरेशन प्रति प्रबंधित नोड कॉन्फ़िगर किया जाना चाहिए। क्लस्टर-व्यापी रखरखाव के लिए, क्लस्टर के प्रत्येक प्रबंधित नोड के लिए शेड्यूलिंग प्रक्रिया को दोहराना होगा। यह अव्यावहारिक हो सकता है यदि आपके क्लस्टर में बड़ी संख्या में नोड हैं, या यदि दो कार्यों के बीच रखरखाव अंतराल बहुत कम है।
सौभाग्य से, इस सीमा को पार करने के लिए ClusterControl CLI (a.k.a s9s) का उपयोग वर्कअराउंड के रूप में किया जा सकता है। आप क्लस्टर में प्रबंधित नोड्स को सूचीबद्ध करने और उनमें हेरफेर करने के लिए "s9s नोड्स" का उपयोग कर सकते हैं। इस सूची को "s9s रखरखाव" कमांड का उपयोग करके एक समय में क्लस्टर-व्यापी रखरखाव मोड शेड्यूल करने के लिए पुनरावृत्त किया जा सकता है।
आइए इसे बेहतर ढंग से समझने के लिए एक उदाहरण देखें। निम्नलिखित तीन-नोड Percona XtraDB क्लस्टर पर विचार करें जो हमारे पास है:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4क्लस्टर में कुल 4 नोड होते हैं - 3 डेटाबेस नोड्स जिसमें एक ClusterControl नोड होता है। पहला कॉलम, STAT, नोड की भूमिका और स्थिति दिखाता है। पहला वर्ण नोड की भूमिका है - "c" का अर्थ है नियंत्रक और "g" का अर्थ है गैलेरा डेटाबेस नोड। मान लीजिए कि हम रखरखाव के लिए केवल डेटाबेस नोड्स को शेड्यूल करना चाहते हैं, हम होस्टनाम या आईपी पता प्राप्त करने के लिए आउटपुट को फ़िल्टर कर सकते हैं जहां रिपोर्ट किए गए STAT में शुरुआत में "g" है:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53एक साधारण पुनरावृत्ति के साथ, हम क्लस्टर में प्रत्येक नोड के लिए क्लस्टर-व्यापी रखरखाव विंडो शेड्यूल कर सकते हैं। निम्न आदेश लूप के लिए क्लस्टर में पाए गए सभी आईपी पते के आधार पर रखरखाव निर्माण को पुनरावृत्त करता है, जहां हम कल उसी समय रखरखाव संचालन शुरू करने और एक घंटे बाद समाप्त करने की योजना बनाते हैं:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bआपको 3 यूयूआईडी का एक प्रिंटआउट देखना चाहिए, जो अद्वितीय स्ट्रिंग है जो प्रत्येक रखरखाव अवधि की पहचान करता है। फिर हम निम्नलिखित कमांड से सत्यापित कर सकते हैं:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3उपरोक्त आउटपुट से, हमें प्रत्येक डेटाबेस नोड के लिए निर्धारित रखरखाव समय की एक सूची मिली है। निर्धारित समय के दौरान, क्लस्टर कंट्रोल न तो अलार्म बजाएगा और न ही सूचना भेजेगा यदि उसे क्लस्टर में अनियमितताएं मिलती हैं।
रखरखाव मोड पुनरावृत्ति
कुछ रखरखाव दिनचर्या को नियमित अंतराल पर करना पड़ता है, जैसे, बैकअप, हाउसकीपिंग और सफाई कार्य। रखरखाव के समय के दौरान, हम सर्वर से अलग तरह से व्यवहार करने की अपेक्षा करेंगे। हालांकि, किसी भी सेवा की विफलता, अस्थायी दुर्गमता या उच्च भार निश्चित रूप से हमारी निगरानी प्रणाली को नुकसान पहुंचाएगा। बार-बार और कम अंतराल के रखरखाव स्लॉट के लिए, यह बहुत कष्टप्रद हो सकता है और उठाए गए झूठे अलार्म को छोड़ना आपको रात के दौरान बेहतर नींद दे सकता है।
हालाँकि, रखरखाव मोड को सक्षम करना सर्वर को एक बड़े जोखिम के लिए भी उजागर कर सकता है क्योंकि समय की अवधि के लिए सख्त निगरानी की अनदेखी की जाती है। इसलिए, रखरखाव मोड को सक्षम करने से पहले रखरखाव संचालन की प्रकृति को समझना शायद एक अच्छा विचार है। निम्नलिखित चेकलिस्ट को हमारी रखरखाव मोड नीति निर्धारित करने में हमारी सहायता करनी चाहिए:
- प्रभावित नोड्स - रखरखाव में कौन से नोड शामिल हैं?
- परिणाम - जब रखरखाव कार्य चल रहा हो तो नोड का क्या होता है? क्या यह पहुंच से बाहर, उच्च लोड या फिर से शुरू होगा?
- अवधि - रखरखाव कार्य पूरा होने में कितना समय लगता है?
- आवृत्ति - रखरखाव कार्य कितनी बार चलना चाहिए?
आइए इसे एक उपयोग के मामले में डालते हैं। विचार करें कि हमारे पास क्लस्टरकंट्रोल नोड के साथ तीन-नोड Percona XtraDB क्लस्टर है। माना जाता है कि हमारे सभी सर्वर वर्चुअल मशीनों पर चल रहे हैं और वीएम बैकअप नीति के लिए सभी वीएम का बैकअप हर दिन 1:00 पूर्वाह्न से, एक समय में एक नोड से शुरू करने की आवश्यकता है। इस बैकअप ऑपरेशन के दौरान, नोड को अधिकतम 10 मिनट के लिए फ्रीज कर दिया जाएगा और क्लस्टर कंट्रोल द्वारा प्रबंधित और मॉनिटर किया जा रहा नोड बैकअप खत्म होने तक पहुंच योग्य नहीं रहेगा। गैलेरा क्लस्टर के दृष्टिकोण से, यह ऑपरेशन पूरे क्लस्टर को नीचे नहीं लाता है क्योंकि क्लस्टर कोरम में रहता है और प्राथमिक घटक प्रभावित नहीं होता है।
रखरखाव कार्य की प्रकृति के आधार पर, हम इसे निम्नलिखित के रूप में सारांशित कर सकते हैं:
- प्रभावित नोड्स - क्लस्टर आईडी 1 के लिए सभी नोड्स (3 डेटाबेस नोड्स और 1 क्लस्टर कंट्रोल नोड)।
- परिणाम - जिस वीएम का बैकअप लिया जा रहा है, वह पूरा होने तक पहुंच योग्य नहीं रहेगा।
- अवधि - प्रत्येक VM बैकअप ऑपरेशन को पूरा होने में लगभग 5 से 10 मिनट का समय लगता है।
- फ़्रीक्वेंसी - VM बैकअप प्रतिदिन चलने के लिए निर्धारित है, जो पहले नोड पर 1:00 पूर्वाह्न से शुरू होगा।
फिर हम अपने रखरखाव मोड को शेड्यूल करने के लिए एक निष्पादन योजना के साथ सामने आ सकते हैं:
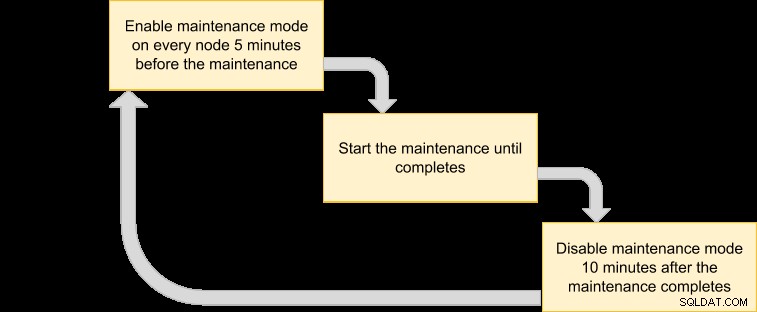
चूँकि हम चाहते हैं कि क्लस्टर में सभी नोड्स VM प्रबंधक द्वारा बैकअप लें, बस संबंधित क्लस्टर आईडी के लिए नोड्स को सूचीबद्ध करें:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53उपरोक्त आउटपुट का उपयोग पूरे क्लस्टर में रखरखाव को शेड्यूल करने के लिए किया जा सकता है। उदाहरण के लिए, यदि आप निम्न आदेश चलाते हैं, तो क्लस्टर नियंत्रण अब से अगले 50 मिनट तक क्लस्टर आईडी 1 के अंतर्गत सभी नोड्स के लिए रखरखाव मोड सक्रिय करेगा:
$(s9s नोड्स --list --cluster-id=1) में होस्ट के लिए$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneउपरोक्त कमांड का उपयोग करके, हम इसे एक स्क्रिप्ट में डालकर एक निष्पादन फ़ाइल में बदल सकते हैं। एक फ़ाइल बनाएँ:
$ vim /usr/local/bin/enable_maintenance_modeऔर निम्नलिखित पंक्तियाँ जोड़ें:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneइसे सहेजें और सुनिश्चित करें कि फ़ाइल अनुमति निष्पादन योग्य है:
$ chmod 755 /usr/local/bin/enable_maintenance_modeफिर वीएम बैकअप ऑपरेशन 1:00 पूर्वाह्न शुरू होने से ठीक पहले, स्क्रिप्ट को 5 मिनट से 1:00 पूर्वाह्न पर चलने के लिए शेड्यूल करने के लिए क्रॉन का उपयोग करें:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeहमारी स्क्रिप्ट को कतारबद्ध किया जा रहा है यह सुनिश्चित करने के लिए क्रॉन डेमॉन को पुनः लोड करें:
$ systemctl reload crond # or service crond reloadयही बात है। अब हम रखरखाव पूरा होने तक झूठे अलार्म और मेल अधिसूचना से प्रभावित हुए बिना अपना दैनिक रखरखाव कार्य कर सकते हैं।
बोनस रखरखाव सुविधा - नोड पुनर्प्राप्ति छोड़ना
स्वचालित पुनर्प्राप्ति सक्षम होने के साथ, ClusterControl नोड विफलता का पता लगाने के लिए पर्याप्त स्मार्ट है और रखरखाव मोड की स्थिति की परवाह किए बिना, 30-सेकंड की छूट अवधि के बाद विफल नोड को पुनर्प्राप्त करने का प्रयास करेगा। क्या आप जानते हैं कि किसी विशेष नोड के लिए जानबूझकर नोड पुनर्प्राप्ति को छोड़ने के लिए ClusterControl को कॉन्फ़िगर किया जा सकता है? यह बहुत मददगार हो सकता है जब आपको समयावधि और रखरखाव के परिणाम को जाने बिना तत्काल रखरखाव करना होता है।
उदाहरण के लिए, कल्पना करें कि एक फाइल-सिस्टम भ्रष्टाचार हुआ और हार्ड रिबूट के बाद फाइल सिस्टम की जांच और मरम्मत की आवश्यकता है। पहले से यह निर्धारित करना कठिन है कि इस ऑपरेशन को पूरा करने में कितना समय लगेगा। इस प्रकार, हम नोड के लिए पुनर्प्राप्ति को छोड़ने के लिए क्लस्टरकंट्रोल को सिग्नल करने के लिए बस एक फ़्लैग फ़ाइल का उपयोग कर सकते हैं।
सबसे पहले, ClusterControl नोड पर /etc/cmon.d/cmon_X.cnf (जहाँ X क्लस्टर आईडी है) के अंदर निम्न पंक्ति जोड़ें:
node_recovery_lock_file=/root/do_not_recoverफिर, परिवर्तन लोड करने के लिए cmon सेवा को पुनरारंभ करें:
$ systemctl restart cmon # service cmon restartअंत में, सुनिश्चित करें कि निर्दिष्ट फ़ाइल उस नोड पर मौजूद है जिसे हम ClusterControl पुनर्प्राप्ति के लिए छोड़ना चाहते हैं:
$ touch /root/do_not_recoverस्वत:पुनर्प्राप्ति और रखरखाव मोड की स्थिति के बावजूद, ClusterControl नोड को केवल तभी पुनर्प्राप्त करेगा जब यह फ़्लैग फ़ाइल मौजूद न हो। तब व्यवस्थापक डेटाबेस नोड पर फ़ाइल बनाने और निकालने के लिए ज़िम्मेदार होता है।
यही है, दोस्तों। खुश रखरखाव!



