यह मूल्यांकन करना कि आपके उपयोग के मामले में कौन सा स्ट्रीमिंग आर्किटेक्चरल पैटर्न सबसे अच्छा मेल खाता है, एक सफल उत्पादन परिनियोजन के लिए एक पूर्व शर्त है।
Apache Hadoop पारिस्थितिकी तंत्र वास्तविक समय में बड़े पैमाने पर डेटा को संसाधित करने और समझने के इच्छुक उद्यमों के लिए एक पसंदीदा मंच बन गया है। Apache Kafka, Apache Flume, Apache Spark, Apache Storm, और Apache Samza जैसी प्रौद्योगिकियां तेजी से लिफाफे को आगे बढ़ा रही हैं जो संभव है। यह अक्सर बड़े पैमाने पर स्ट्रीमिंग उपयोग के मामलों को एक साथ बकेट करने के लिए आकर्षक होता है, लेकिन वास्तव में वे कुछ अलग वास्तुशिल्प पैटर्न में टूट जाते हैं, जिसमें पारिस्थितिकी तंत्र के विभिन्न घटक विभिन्न समस्याओं के लिए बेहतर अनुकूल होते हैं।
इस पोस्ट में, मैं उत्पादन में एंटरप्राइज़ डेटा हब चलाने वाले ग्राहकों के साथ सामना किए गए चार प्रमुख स्ट्रीमिंग पैटर्न की रूपरेखा तैयार करूंगा, और समझाऊंगा कि हडूप पर आर्किटेक्चरल रूप से उन पैटर्न को कैसे कार्यान्वित किया जाए।
स्ट्रीमिंग पैटर्न
चार बुनियादी स्ट्रीमिंग पैटर्न (अक्सर अग्रानुक्रम में उपयोग किए जाते हैं) हैं:
- स्ट्रीम अंतर्ग्रहण: इसमें HDFS, Apache HBase, और Apache Solr की घटनाओं की कम-विलंबता बनी रहती है।
- बाहरी संदर्भ के साथ रीयल-टाइम (NRT) इवेंट प्रोसेसिंग के पास: घटनाओं के आने पर उन्हें अलर्ट करने, फ़्लैग करने, बदलने और फ़िल्टर करने जैसी कार्रवाइयाँ करता है। विसंगति का पता लगाने वाले मॉडल जैसे परिष्कृत मानदंडों के आधार पर कार्रवाई की जा सकती है। सामान्य उपयोग के मामले, जैसे एनआरटी धोखाधड़ी का पता लगाना और अनुशंसा, अक्सर 100 मिलीसेकंड से कम विलंबता की मांग करते हैं।
- NRT इवेंट पार्टिशन प्रोसेसिंग: एनआरटी इवेंट प्रोसेसिंग के समान, लेकिन डेटा को विभाजित करने से लाभ प्राप्त करना - जैसे मेमोरी में अधिक प्रासंगिक बाहरी जानकारी संग्रहीत करना। इस पैटर्न के लिए 100 मिलीसेकंड से कम विलंबता को संसाधित करने की भी आवश्यकता होती है।
- एकत्रीकरण या एमएल के लिए जटिल टोपोलॉजी: स्ट्रीम प्रोसेसिंग की पवित्र कब्र:संचालन के जटिल और लचीले सेट के साथ डेटा से वास्तविक समय के उत्तर प्राप्त करता है। यहां, क्योंकि परिणाम अक्सर विंडो गणना पर निर्भर करते हैं और अधिक सक्रिय डेटा की आवश्यकता होती है, फोकस अल्ट्रा-लो लेटेंसी से कार्यक्षमता और सटीकता पर स्थानांतरित हो जाता है।
निम्नलिखित अनुभागों में, हम इस तरह के पैटर्न को एक परीक्षण, सिद्ध और बनाए रखने योग्य तरीके से लागू करने के लिए अनुशंसित तरीकों में शामिल होंगे।
स्ट्रीमिंग अंतर्ग्रहण
परंपरागत रूप से, फ्लूम स्ट्रीमिंग अंतर्ग्रहण के लिए अनुशंसित प्रणाली रही है। इसके स्रोतों और सिंक के बड़े पुस्तकालय में क्या उपभोग करना है और कहां लिखना है, इसके सभी आधार शामिल हैं। (फ्लूम को कॉन्फ़िगर और प्रबंधित करने के तरीके के बारे में विवरण के लिए, फ्लूम का उपयोग करना , क्लौडेरा सॉफ्टवेयर इंजीनियर/फ्लूम पीएमसी सदस्य हरि श्रीधरन द्वारा ओ रेली मीडिया पुस्तक एक महान संसाधन है।)
पिछले वर्ष के भीतर, प्लेबैक और प्रतिकृति जैसी शक्तिशाली विशेषताओं के कारण काफ्का भी लोकप्रिय हो गया है। फ्लूम और काफ्का के लक्ष्यों के बीच ओवरलैप होने के कारण, उनका रिश्ता अक्सर भ्रमित करने वाला होता है। वे एक साथ कैसे फिट होते हैं? इसका उत्तर सरल है:काफ्का फ्लूम के चैनल एब्स्ट्रैक्शन के समान एक पाइप है, हालांकि ऊपर वर्णित सुविधाओं के लिए इसके समर्थन के कारण एक बेहतर पाइप है। स्रोत और सिंक के लिए फ्लूम और उनके बीच पाइप के लिए काफ्का का उपयोग करना एक सामान्य तरीका है।
नीचे दिया गया चित्र दिखाता है कि कैसे काफ्का फ्लूम के डेटा के अपस्ट्रीम स्रोत, फ्लूम के डाउनस्ट्रीम गंतव्य या फ्लूम चैनल के रूप में काम कर सकता है।
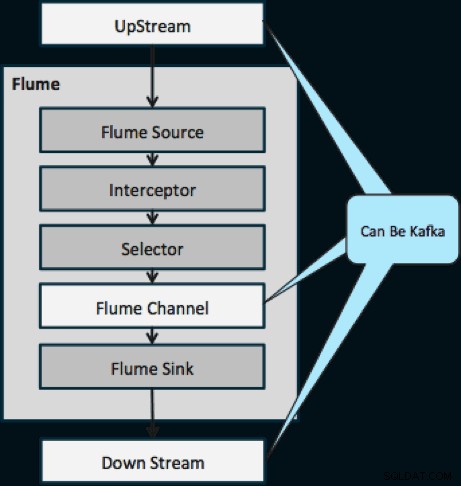
नीचे दिखाया गया डिज़ाइन बड़े पैमाने पर स्केलेबल है, लड़ाई कठोर है, क्लाउडेरा मैनेजर के माध्यम से केंद्रीय रूप से निगरानी की जाती है, दोष सहनशील है, और रीप्ले का समर्थन करता है।
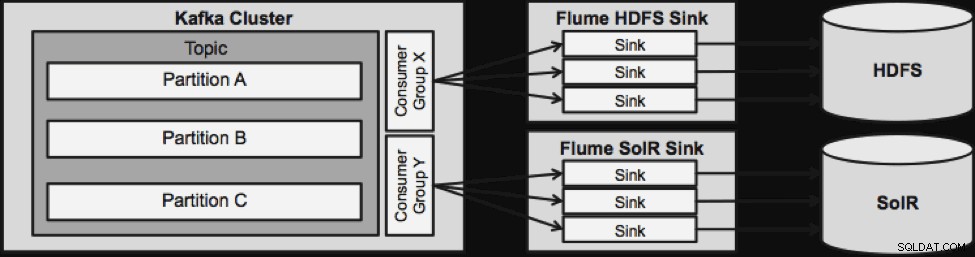
अगली स्ट्रीमिंग आर्किटेक्चर पर जाने से पहले एक बात ध्यान देने योग्य है कि यह डिज़ाइन विफलता को कैसे इनायत से संभालता है। फ्लूम सिंक काफ्का उपभोक्ता समूह से खींचता है। Apache ZooKeeper की मदद से उपभोक्ता समूह टॉपिक के ऑफसेट को ट्रैक करता है। यदि फ्लूम सिंक खो जाता है, तो काफ्का उपभोक्ता शेष सिंक में लोड को पुनर्वितरित करेगा। जब फ्लूम सिंक वापस आता है, तो उपभोक्ता समूह फिर से वितरित करेगा।
बाहरी संदर्भ के साथ NRT इवेंट प्रोसेसिंग
दोहराने के लिए, इस पैटर्न के लिए एक सामान्य उपयोग मामला स्ट्रीमिंग घटनाओं को देखने और तत्काल निर्णय लेने के लिए है, या तो डेटा को बदलने या किसी प्रकार की बाहरी कार्रवाई करने के लिए। निर्णय तर्क अक्सर बाहरी प्रोफाइल या मेटाडेटा पर निर्भर करता है। इस दृष्टिकोण को लागू करने का एक आसान और स्केलेबल तरीका अपने काफ्का/फ्लूम आर्किटेक्चर में एक स्रोत या सिंक फ्लूम इंटरसेप्टर जोड़ना है। मामूली ट्यूनिंग के साथ, कम मिलीसेकंड में लेटेंसी हासिल करना मुश्किल नहीं है।
फ्लूम इंटरसेप्टर घटनाओं या घटनाओं के बैच लेते हैं और उपयोगकर्ता कोड को उनके आधार पर संशोधित करने या कार्रवाई करने की अनुमति देते हैं। उपयोगकर्ता कोड निर्णयों के लिए आवश्यक प्रोफ़ाइल जानकारी प्राप्त करने के लिए स्थानीय मेमोरी या HBase जैसी बाहरी भंडारण प्रणाली के साथ बातचीत कर सकता है। HBase आमतौर पर हमें नेटवर्क, स्कीमा डिज़ाइन और कॉन्फ़िगरेशन के आधार पर लगभग 4-25 मिलीसेकंड में हमारी जानकारी दे सकता है। आप HBase को इस तरह से भी सेट कर सकते हैं कि विफलता की स्थिति में भी यह कभी भी डाउन या बाधित न हो।
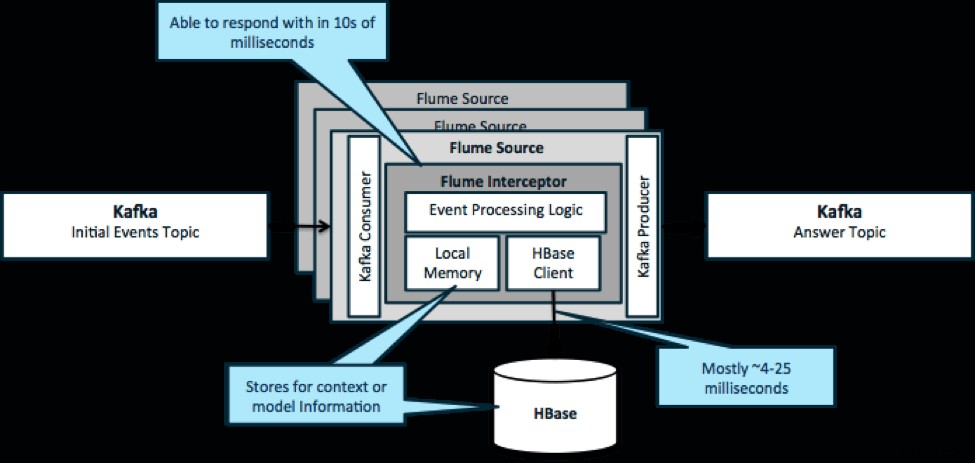
कार्यान्वयन के लिए इंटरसेप्टर में एप्लिकेशन-विशिष्ट तर्क से परे लगभग कोई कोडिंग की आवश्यकता नहीं होती है। क्लाउडेरा मैनेजर पार्सल के माध्यम से इस तर्क को लागू करने के साथ-साथ सेवाओं को जोड़ने, कॉन्फ़िगर करने और निगरानी करने के लिए एक सहज यूआई प्रदान करता है।
बाहरी संदर्भ के साथ NRT पार्टिशनेड इवेंट प्रोसेसिंग
नीचे दिए गए आर्किटेक्चर (विभाजित समाधान) में, आपको HBase को बार-बार कॉल करने की आवश्यकता होगी क्योंकि विशेष घटनाओं के लिए प्रासंगिक बाहरी संदर्भ फ्लूम इंटरसेप्टर पर स्थानीय मेमोरी में फिट नहीं होता है।
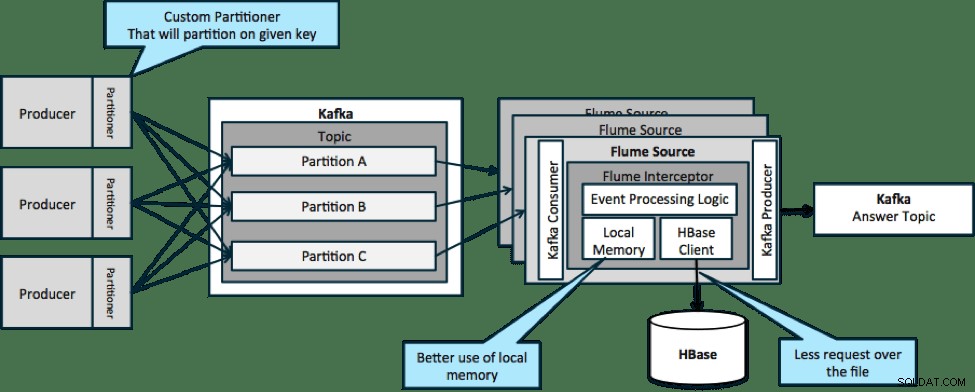
हालांकि, यदि आप अपने डेटा को विभाजित करने के लिए एक कुंजी को परिभाषित करते हैं, तो आप आने वाले डेटा को उस संदर्भ डेटा के सबसेट से मिला सकते हैं जो उससे प्रासंगिक है। यदि आप डेटा को 10 बार विभाजित करते हैं, तो आपको केवल 1/10 वां प्रोफ़ाइल मेमोरी में रखने की आवश्यकता है। HBase तेज है, लेकिन स्थानीय मेमोरी तेज है। काफ्का आपको एक कस्टम पार्टीशनर को परिभाषित करने में सक्षम बनाता है जिसका उपयोग यह आपके डेटा को विभाजित करने के लिए करता है।
ध्यान दें कि फ्लूम यहां सख्ती से जरूरी नहीं है; यहाँ जड़ समाधान सिर्फ एक काफ्का उपभोक्ता है। तो, आप YARN में केवल एक उपभोक्ता का उपयोग कर सकते हैं या केवल MapReduce एप्लिकेशन का उपयोग कर सकते हैं।
एकत्रीकरण या एमएल के लिए जटिल टोपोलॉजी
इस बिंदु तक, हम घटना-स्तर के संचालन की खोज कर रहे हैं। हालांकि, कभी-कभी आपको अधिक जटिल संचालन की आवश्यकता होती है जैसे कि गणना, औसत, सत्रीकरण, या मशीन-लर्निंग मॉडल बिल्डिंग जो डेटा के बैचों पर काम करते हैं। इस मामले में, स्पार्क स्ट्रीमिंग कई कारणों से आदर्श उपकरण है:
- अन्य टूल की तुलना में इसे विकसित करना आसान है। स्पार्क के समृद्ध और संक्षिप्त एपीआई जटिल टोपोलॉजी के निर्माण को आसान बनाते हैं।
- स्ट्रीमिंग और बैच प्रोसेसिंग के लिए समान कोड। कुछ बदलावों के साथ, वास्तविक समय में छोटे बैचों के कोड का उपयोग ऑफ़लाइन बड़े बैचों के लिए किया जा सकता है। कोड आकार को कम करने के अलावा, यह दृष्टिकोण परीक्षण और एकीकरण के लिए आवश्यक समय को कम करता है।
- जानने के लिए एक इंजन है। एक लागत है जो वितरित प्रसंस्करण इंजनों की विचित्रताओं और आंतरिक पर प्रशिक्षण कर्मचारियों में जाती है। स्पार्क पर मानकीकरण इस लागत को स्ट्रीमिंग और बैच दोनों के लिए समेकित करता है।
- माइक्रो-बैचिंग आपको मज़बूती से स्केल करने में मदद करता है। बैच स्तर पर स्वीकार करने से अधिक थ्रूपुट की अनुमति मिलती है और दोहरे-भेजने के डर के बिना समाधान की अनुमति मिलती है। माइक्रो-बैचिंग बड़े पैमाने पर प्रदर्शन के मामले में एचडीएफएस या एचबीएएस में बदलाव भेजने में भी मदद करता है।
- Hadoop पारिस्थितिकी तंत्र एकीकरण बेक किया हुआ है। स्पार्क का एचडीएफएस, एचबेस और काफ्का के साथ गहरा एकीकरण है।
- डेटा हानि का कोई जोखिम नहीं है। वाल और काफ्का के लिए धन्यवाद, स्पार्क स्ट्रीमिंग विफलता के मामले में डेटा हानि से बचाती है।
- डीबग करना और चलाना आसान है। आप डिबग कर सकते हैं और अपने कोड स्पार्क स्ट्रीमिंग के माध्यम से एक स्थानीय आईडीई में एक क्लस्टर के बिना कदम उठा सकते हैं। साथ ही, कोड सामान्य कार्यात्मक प्रोग्रामिंग कोड जैसा दिखता है, इसलिए जावा या स्काला डेवलपर को कूदने में अधिक समय नहीं लगता है। (पायथन भी समर्थित है।)
- स्ट्रीमिंग मूल रूप से स्टेटफुल है। स्पार्क स्ट्रीमिंग में, राज्य एक प्रथम श्रेणी का नागरिक है, जिसका अर्थ है कि स्टेटफुल स्ट्रीमिंग एप्लिकेशन लिखना आसान है जो नोड विफलताओं के लिए लचीला हैं।
- वास्तविक मानक के रूप में, स्पार्क पूरे पारिस्थितिकी तंत्र से दीर्घकालिक निवेश प्राप्त कर रहा है।
इस लेखन के समय, पिछले 30 दिनों में स्पार्क के लिए लगभग 700 कमिट्स थे—तूफान जैसे अन्य स्ट्रीमिंग फ्रेमवर्क की तुलना में, एक ही समय में 15 कमिट्स के साथ। - आपके पास एमएल पुस्तकालयों तक पहुंच है।
स्पार्क का एमएललिब बेहद लोकप्रिय हो रहा है और इसकी कार्यक्षमता केवल बढ़ेगी। - जहाँ आवश्यक हो आप SQL का उपयोग कर सकते हैं।
स्पार्क एसक्यूएल के साथ, आप कोड जटिलता को कम करने के लिए अपने स्ट्रीमिंग एप्लिकेशन में एसक्यूएल तर्क जोड़ सकते हैं।
निष्कर्ष
स्ट्रीमिंग और कई संभावित पैटर्न में बहुत शक्ति है, लेकिन जैसा कि आपने इस पोस्ट में सीखा है, आप न्यूनतम कोडिंग के साथ वास्तव में शक्तिशाली चीजें कर सकते हैं यदि आप जानते हैं कि कौन सा पैटर्न आपके उपयोग के मामले में सबसे अच्छा मेल खाता है।
Ted Malaska Cloudera में एक समाधान वास्तुकार है, जो Spark, Flume, और HBase में योगदानकर्ता है, और O'Reilly पुस्तक के सह-लेखक हैं, Hadoop एप्लिकेशन आर्किटेक्चर.



