हमारे पिछले Hadoop . में ब्लॉग हमने प्रत्येक Hadoop के घटक . का अध्ययन किया है MapReduce प्रक्रिया विस्तार से। इसमें हम बहुत ही दिलचस्प विषय पर चर्चा करने जा रहे हैं यानी हडूप में मैप ओनली जॉब।
सबसे पहले, हम मानचित्र . का संक्षिप्त परिचय लेंगे और कम करें Hadoop Mapreduce में चरण, उसके बाद हम चर्चा करेंगे कि Hadoop MapReduce में मानचित्र केवल नौकरी क्या है।
अंत में हम इस ट्यूटोरियल में हडूप मैप ओनली जॉब के फायदे और नुकसान के बारे में भी चर्चा करेंगे।
Hadoop Map Only Job क्या है?
केवल-नक्शा कार्य Hadoop में वह प्रक्रिया है जिसमें मैपर सभी कार्य करता है। reducer . द्वारा कोई कार्य नहीं किया जाता है . मैपर का आउटपुट अंतिम आउटपुट होता है।
MapReduce Hadoop की डेटा प्रोसेसिंग परत है। यह HDFS . में संग्रहीत बड़े संरचित और असंरचित डेटा को संसाधित करता है . MapReduce समानांतर में बड़ी मात्रा में डेटा को भी संसाधित करता है।
यह कार्य (सबमिट की गई नौकरी) को स्वतंत्र कार्यों (उप-कार्य) के एक सेट में विभाजित करके करता है। Hadoop में, MapReduce प्रसंस्करण को चरणों में विभाजित करके काम करता है:मानचित्र और कम करें ।
- मानचित्र: यह प्रसंस्करण का पहला चरण है, जहां हम सभी जटिल तर्क कोड निर्दिष्ट करते हैं। यह डेटा का एक सेट लेता है और डेटा के दूसरे सेट में परिवर्तित हो जाता है। यह प्रत्येक व्यक्तिगत तत्व को टुपल्स में तोड़ता है (की-वैल्यू पेयर )।
- कम करें: यह प्रसंस्करण का दूसरा चरण है। यहां हम हल्के-फुल्के प्रसंस्करण जैसे एकत्रीकरण/योग को निर्दिष्ट करते हैं। यह मानचित्र से आउटपुट को इनपुट के रूप में लेता है। फिर यह कुंजी के आधार पर उन टुपल्स को जोड़ती है।
इस शब्द-गणना उदाहरण से, हम कह सकते हैं कि समानांतर प्रक्रिया के दो सेट हैं, नक्शा और कम करें। मानचित्र प्रक्रिया में, ऊपर दिखाए गए अनुसार सभी मानचित्र नोड्स के बीच कार्य को वितरित करने के लिए पहले इनपुट को विभाजित किया जाता है।
फिर फ्रेमवर्क प्रत्येक शब्द की पहचान करता है और नंबर 1 पर मैप करता है। इस प्रकार, यह टुपल्स (की-वैल्यू) जोड़े नामक जोड़े बनाता है।
पहले मैपर नोड में, यह तीन शब्दों शेर, बाघ और नदी से गुजरता है। इस प्रकार, यह नोड के आउटपुट के रूप में 3 कुंजी-मूल्य जोड़े उत्पन्न करता है। तीन अलग-अलग कुंजियाँ और मान 1 पर सेट हैं और यही प्रक्रिया सभी नोड्स के लिए दोहराई जाती है।
फिर यह इन टुपल्स को रिड्यूसर नोड्स में भेजता है। पार्टिशनर फेरबदल करता है ताकि एक ही कुंजी वाले सभी टुपल्स एक ही नोड में जा सकें।
कम करने की प्रक्रिया में मूल रूप से जो होता है वह मूल्यों का एकत्रीकरण या बल्कि एक ही कुंजी साझा करने वाले मूल्यों पर एक ऑपरेशन होता है।
अब, आइए एक ऐसे परिदृश्य पर विचार करें जहां हमें केवल ऑपरेशन करने की आवश्यकता है। हमें एकत्रीकरण की आवश्यकता नहीं है, ऐसे मामले में, हम 'केवल-नक्शा कार्य पसंद करेंगे। '.
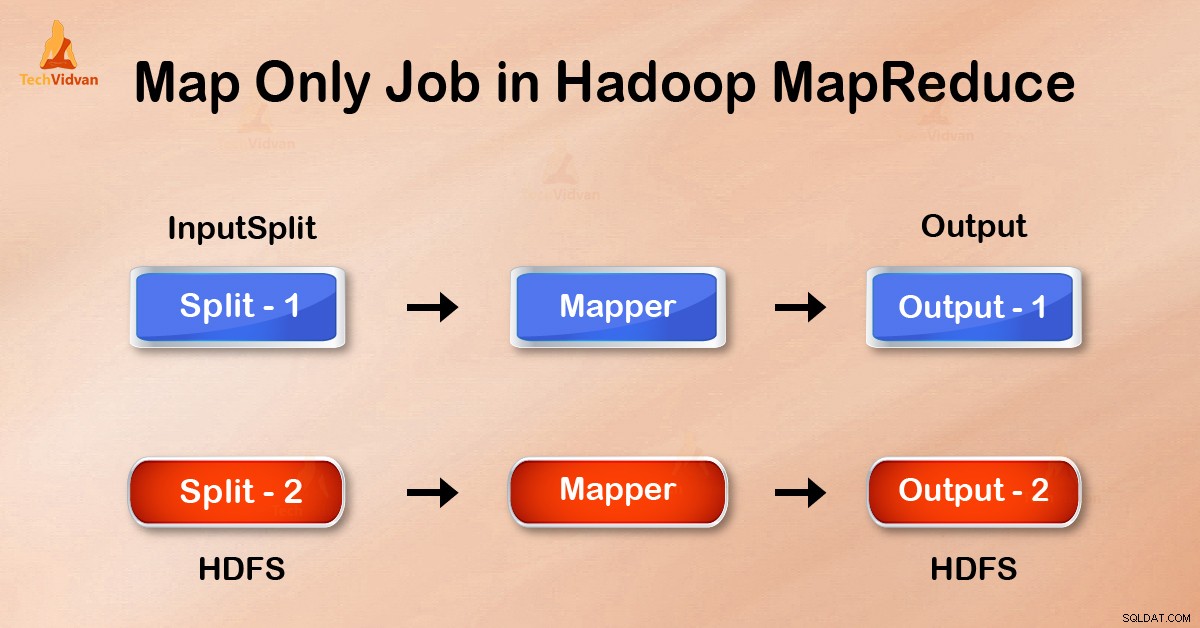
मैप-ओनली जॉब में, मैप अपने इनपुटस्प्लिट . के साथ सभी काम करता है . रेड्यूसर कोई काम नहीं करता है। मैपर आउटपुट अंतिम आउटपुट होता है।
MapReduce में रिड्यूस फेज़ से कैसे बचें?
job.setNumreduceTasks(0) . सेट करके ड्राइवर में कॉन्फ़िगरेशन में हम चरण को कम करने से बच सकते हैं। यह कई रेड्यूसर को 0 . बना देगा . इस प्रकार एकमात्र मैपर ही पूरा कार्य कर रहा होगा।
Hadoop में मैप ओनली जॉब के फायदे
MapReduce में मानचित्र के बीच कार्य निष्पादन और चरणों को कम करता है, कुंजी, सॉर्ट और फेरबदल चरण होता है। शफल करना-क्रमबद्ध करना चाबियों को आरोही क्रम में क्रमबद्ध करने के लिए जिम्मेदार हैं। फिर समान कुंजियों के आधार पर मानों को समूहीकृत करना। यह चरण बहुत महंगा है।
यदि कम चरण की आवश्यकता नहीं है, तो हमें इससे बचना चाहिए। चरण कम करने से बचने के साथ-साथ छँटाई और फेरबदल चरण भी समाप्त हो जाएगा। इसलिए, यह नेटवर्क की भीड़ को भी बचाएगा।
कारण यह है कि फेरबदल में, मैपर का आउटपुट कम करने के लिए यात्रा करता है। और जब डेटा का आकार बहुत बड़ा होता है, तो बड़े डेटा को रिड्यूसर तक ले जाने की आवश्यकता होती है।
कम करने के लिए भेजने से पहले मैपर का आउटपुट स्थानीय डिस्क पर लिखा जाता है। लेकिन मैप ओनली जॉब में, यह आउटपुट सीधे एचडीएफएस को लिखा जाता है। इससे समय की बचत होती है और लागत भी कम होती है।
निष्कर्ष
इसलिए, हमने देखा है कि मैप-ओनली जॉब फेरबदल, सॉर्ट और चरण को कम करने से बचकर नेटवर्क की भीड़ को कम करता है। अकेले नक्शा समग्र प्रसंस्करण का ख्याल रखता है और आउटपुट का उत्पादन करता है। job.setNumreduceTasks(0) . का उपयोग करके यह हासिल किया गया है।
मुझे उम्मीद है कि आप Hadoop मैप ओनली जॉब और उसके महत्व को समझ गए होंगे क्योंकि हमने Hadoop में मैप ओनली जॉब के बारे में सब कुछ कवर कर लिया है। लेकिन अगर आपका कोई सवाल है तो आप हमें कमेंट सेक्शन में साझा कर सकते हैं।



