इस Hadoop ट्यूटोरियल . में , हम आपको MapReduce Key Value Pair का संपूर्ण परिचय प्रदान करने जा रहे हैं।
सबसे पहले हम चर्चा करेंगे कि Hadoop में एक प्रमुख मूल्य जोड़ी क्या है, MapReduce में कुंजी मूल्य जोड़ी कैसे उत्पन्न होती है। अंत में हम MapReduce की वैल्यू पेयर जेनरेशन को उदाहरणों के साथ समझाएंगे।
Hadoop में Key Value Pair क्या है?
MapReduce में की-वैल्यू पेयर वह रिकॉर्ड इकाई है जिसे Hadoop MapReduce निष्पादन के लिए स्वीकार करता है।
हम Hadoop का उपयोग मुख्य रूप से डेटा विश्लेषण के लिए करते हैं। यह संरचित, असंरचित और अर्ध-संरचित डेटा से संबंधित है। Hadoop के साथ, यदि स्कीमा स्थिर है, तो हम मुख्य मान के बजाय सीधे कॉलम पर काम कर सकते हैं। लेकिन, अगर स्कीमा स्थिर नहीं है तो हम एक महत्वपूर्ण मूल्य पर काम करेंगे।
कुंजी मान डेटा का आंतरिक गुण नहीं है। लेकिन वे डेटा का विश्लेषण करने वाले उपयोगकर्ता द्वारा चुने जाते हैं।
MapReduce Hadoop का मुख्य घटक है, जो डेटा प्रोसेसिंग प्रदान करता है। यह कार्य को दो चरणों में विभाजित करके प्रसंस्करण करता है:मानचित्र चरण और चरण कम करें . प्रत्येक चरण में इनपुट और आउटपुट के रूप में कुंजी-मान होता है।
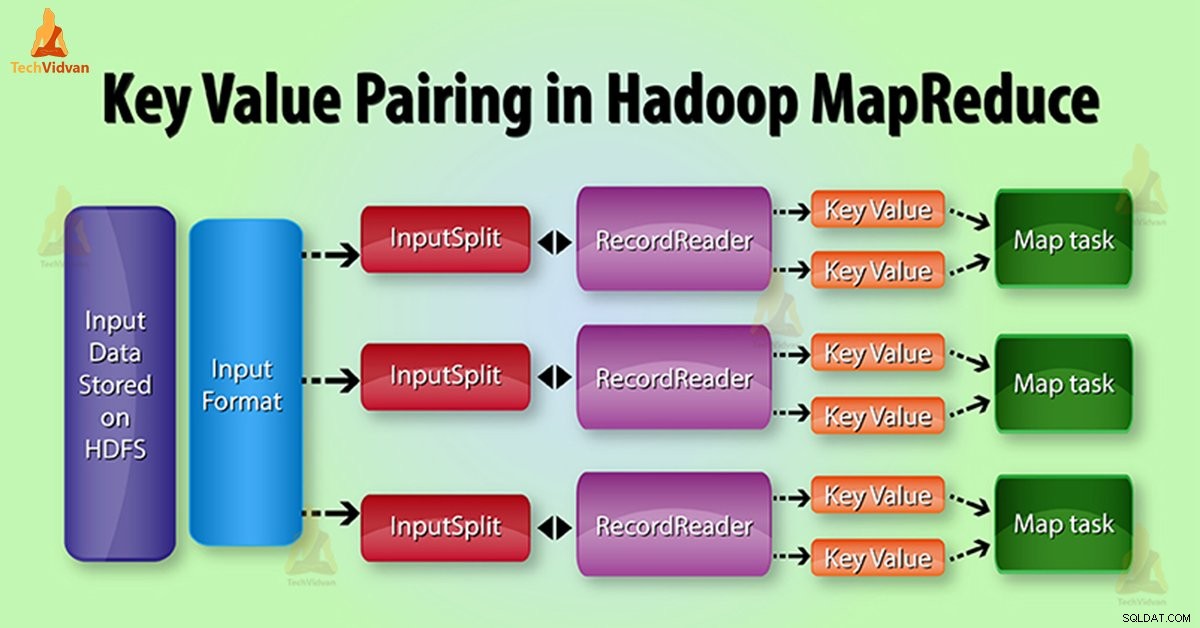
Hadoop में MapReduce की-वैल्यू पेयर जेनरेशन
MapReduce कार्य निष्पादन में, मैपर . को डेटा भेजने से पहले , पहले इसे की-वैल्यू पेयर में बदलें। क्योंकि मैपर डेटा के केवल की-वैल्यू पेयर करता है।
MapReduce में की-वैल्यू पेयर निम्नानुसार उत्पन्न होता है:
इनपुट स्प्लिट – यह डेटा का तार्किक प्रतिनिधित्व है जो InputFormat उत्पन्न करता है। MapReduce कार्यक्रम में यह कार्य की एक इकाई का वर्णन करता है जिसमें एक एकल मानचित्र कार्य होता है।
रिकॉर्ड रीडर – यह InputSplit के साथ संचार करता है। उसके बाद यह डेटा को मैपर द्वारा पढ़ने के लिए उपयुक्त प्रमुख मूल्य जोड़े में परिवर्तित करता है। डिफ़ॉल्ट रूप से RecordReader डेटा को कुंजी मान जोड़े में बदलने के लिए TextInputFormat का उपयोग करता है।
MapReduce कार्य निष्पादन में, मानचित्र फ़ंक्शन एक निश्चित कुंजी-मूल्य जोड़ी को संसाधित करता है। फिर एक निश्चित संख्या में कुंजी-मूल्य जोड़े का उत्सर्जन करता है। कम करें फ़ंक्शन एक ही कुंजी द्वारा समूहीकृत मानों को संसाधित करता है।
फिर आउटपुट के रूप में कुंजी-मूल्य जोड़े का एक और सेट उत्सर्जित करता है। नक्शा आउटपुट प्रकार नीचे दिखाए गए अनुसार कम करें के इनपुट प्रकारों से मेल खाना चाहिए:
- मानचित्र: (K1, V1) -> सूची (K2, V2)
- कम करें: {(K2, सूची (V2}) -> सूची (K3, V3)
Hadoop में की-वैल्यू पेयर किस आधार पर जेनरेट होता है?
MapReduce की-वैल्यू पेयर जेनरेशन पूरी तरह से डेटा सेट पर निर्भर करता है। आवश्यक आउटपुट पर भी निर्भर करता है। फ्रेमवर्क 4 स्थानों में की-वैल्यू पेयर निर्दिष्ट करता है:मैप इनपुट/आउटपुट, इनपुट/आउटपुट कम करें।
<एच4>1. मैप इनपुटडिफ़ॉल्ट रूप से मानचित्र इनपुट लाइन ऑफ़सेट को कुंजी के रूप में लेता है। पंक्ति की सामग्री टेक्स्ट के रूप में मान है। हम उन्हें संशोधित कर सकते हैं; कस्टम इनपुट प्रारूप का उपयोग करके।
<एच4>2. मैप आउटपुटमानचित्र डेटा को फ़िल्टर करने के लिए ज़िम्मेदार है। यह कुंजी के आधार पर डेटा को समूहीकृत करने के लिए वातावरण भी प्रदान करता है।
- कुंजी– यह फ़ील्ड/टेक्स्ट/ऑब्जेक्ट है जिस पर डेटा समूह और एकत्रीकरण reducer . पर होता है ।
- मान– यह फ़ील्ड/टेक्स्ट/ऑब्जेक्ट है जिसे प्रत्येक व्यक्ति मेथड हैंडल को कम करता है।
नक्शा आउटपुट कम करने के लिए इनपुट है। तो यह मैप-आउटपुट जैसा ही है।
<एच4>4. आउटपुट कम करेंयह पूरी तरह से आवश्यक आउटपुट पर निर्भर करता है।
MapReduce की-वैल्यू पेयर उदाहरण
उदाहरण के लिए, फ़ाइल की सामग्री जो HDFS स्टोर हैं चांडलर इज जॉय मार्क इज जॉन है . तो, अब InputFormat का उपयोग करके, हम परिभाषित करेंगे कि यह फ़ाइल कैसे विभाजित होगी और पढ़ेगी। डिफ़ॉल्ट रूप से, RecordReader इस फ़ाइल को की-वैल्यू पेयर में बदलने के लिए TextInputFormat का उपयोग करता है।
- कुंजी – यह फ़ाइल के भीतर लाइन की शुरुआत का ऑफसेट है।
- मान – यह लाइन टर्मिनेटर को छोड़कर लाइन की सामग्री है।
यहां, कुंजी 0 है और मान चांडलर है जॉय मार्क जॉन है।
निष्कर्ष
अंत में, हम कह सकते हैं कि, की-वैल्यू सिर्फ एक रिकॉर्ड इकाई है जिसे MapReduce निष्पादन के लिए स्वीकार करता है। InputSplit और RecordReader की-वैल्यू पेयर जेनरेट करते हैं। इसलिए, कुंजी बाइट ऑफ़सेट है और मान लाइन की सामग्री है।
आशा है आपको यह ब्लॉग पसंद आया होगा। यदि आपके पास MapReduce कुंजी मूल्य जोड़ी से संबंधित कोई सुझाव या प्रश्न है तो कृपया नीचे दिए गए अनुभाग में एक टिप्पणी छोड़ दें।



