अब तक हमने Hadoop परिचय . को कवर किया है और Hadoop HDFS विस्तार से। इस ट्यूटोरियल में, हम आपको Hadoop Reducer का विस्तृत विवरण प्रदान करेंगे।
यहां चर्चा करेंगे कि MapReduce में रेड्यूसर क्या है, Hadoop MapReduce में Reducer कैसे काम करता है, Hadoop Reducer के विभिन्न चरण, हम Hadoop MapReduce में Reducer की संख्या कैसे बदल सकते हैं।
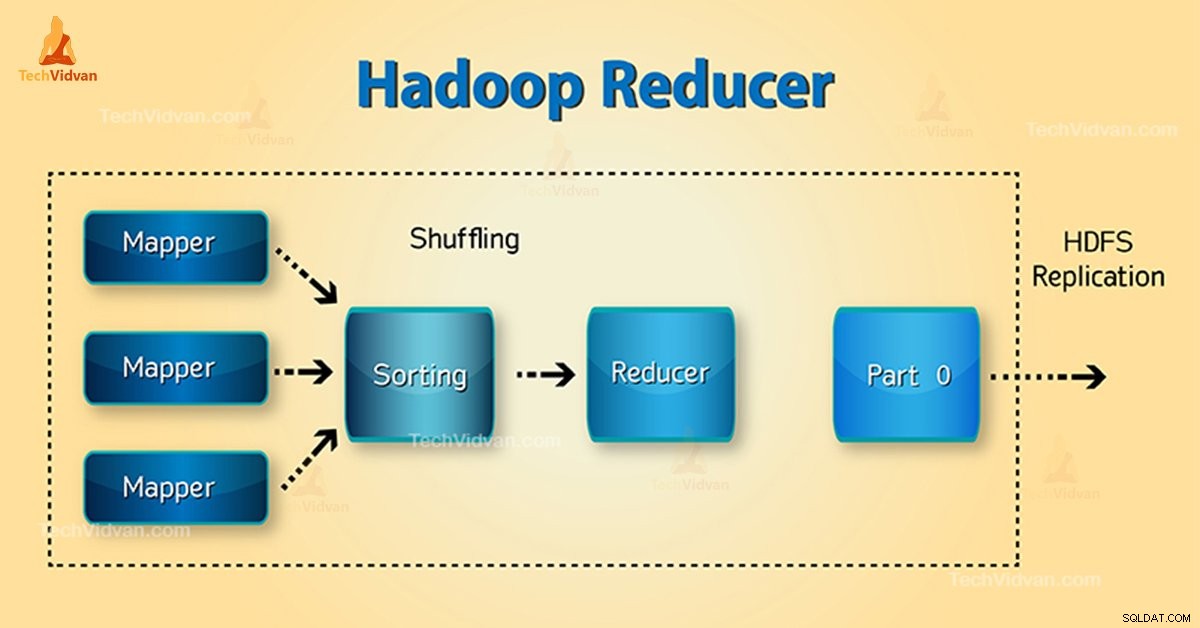
Hadoop Reducer क्या है?
Reducer Hadoop MapReduce में मध्यवर्ती मानों के एक सेट को कम कर देता है, जो मूल्यों के एक छोटे सेट की कुंजी साझा करते हैं।
MapReduce कार्य निष्पादन प्रवाह में, Reducer एक मध्यवर्ती की-वैल्यू पेयर . का एक सेट लेता है मैपर . द्वारा निर्मित इनपुट के रूप में। फिर, रिड्यूसर कुंजी-मूल्य जोड़े को एकत्रित, फ़िल्टर और संयोजित करता है और इसके लिए प्रसंस्करण की एक विस्तृत श्रृंखला की आवश्यकता होती है।
MapReduce कार्य निष्पादन में कुंजियों और रिड्यूसर के बीच एक-एक मैपिंग होती है। वे समानांतर में चलते हैं क्योंकि वे एक दूसरे से स्वतंत्र हैं। उपयोगकर्ता MapReduce में रेड्यूसर की संख्या तय करता है।
Hadoop Reducer के चरण
रेड्यूसर के तीन चरण इस प्रकार हैं:
<एच4>1. फेरबदल चरणयह वह चरण है जिसमें मैपर से सॉर्ट किया गया आउटपुट रिड्यूसर का इनपुट होता है। HTTP की मदद से फ्रेमवर्क इस चरण में सभी मैपर के आउटपुट के प्रासंगिक विभाजन को प्राप्त करता है। चरण को क्रमबद्ध करें
<एच4>2. चरण क्रमित करेंयह वह चरण है जिसमें अलग-अलग मैपर में समान कुंजियों के आधार पर अलग-अलग मैपर के इनपुट को फिर से सॉर्ट किया जाता है।
शफल और सॉर्ट दोनों एक साथ होते हैं।
<एच4>3. चरण कम करेंयह चरण फेरबदल और छँटाई के बाद होता है। कार्य को कम करें कुंजी-मूल्य जोड़े को एकत्रित करता है। OutputCollector.collect() . के साथ संपत्ति, कम कार्य का आउटपुट फाइलसिस्टम को लिखा जाता है। रेड्यूसर आउटपुट क्रमबद्ध नहीं है।
Hadoop MapReduce में रेड्यूसर की संख्या
उपयोगकर्ता ने Job.setNumreduceTasks(int) की सहायता से रेड्यूसर की संख्या निर्धारित की संपत्ति। इस प्रकार सूत्र द्वारा रेड्यूसर की सही संख्या:
0.95 या 1.75 गुणा (<नोड्स की संख्या> * <प्रति नोड अधिकतम कंटेनर की संख्या>)
तो, 0.95 के साथ, सभी रिड्यूसर तुरंत लॉन्च हो जाते हैं। फिर, मैप के आउटपुट को मैप के खत्म होते ही ट्रांसफर करना शुरू करें।
तेज़ नोड 1.75 के साथ रेड्यूसर के पहले दौर को पूरा करता है। फिर यह रेड्यूसर की दूसरी लहर लॉन्च करता है जो लोड संतुलन का बेहतर काम करता है।
रिड्यूसर की संख्या में वृद्धि के साथ:
- फ्रेमवर्क ओवरहेड बढ़ जाता है।
- लोड संतुलन बढ़ता है।
- विफलताओं की लागत कम हो जाती है।
निष्कर्ष
इसलिए, रेड्यूसर मैपर आउटपुट को इनपुट के रूप में लेता है। फिर, कुंजी-मूल्य जोड़े को संसाधित करें और आउटपुट उत्पन्न करें। रेड्यूसर आउटपुट अंतिम आउटपुट है। अगर आपको यह ब्लॉग पसंद है या आपके पास हडूप रेड्यूसर से संबंधित कोई प्रश्न है, तो कृपया एक टिप्पणी छोड़ कर हमारे साथ साझा करें।
आशा है कि हम आपकी सहायता करेंगे।



