इस ब्लॉग में, हम आपको Hadoop Mapper . का संपूर्ण परिचय प्रदान करेंगे . मैं
इस ब्लॉग में, हम जवाब देंगे कि Hadoop MapReduce में मैपर क्या है, Hadoop मैपर कैसे काम करता है, Mapreduce में मैपर की प्रक्रिया क्या है, Hadoop MapReduce में की-वैल्यू पेयर कैसे बनाता है।
Hadoop मैपर का परिचय
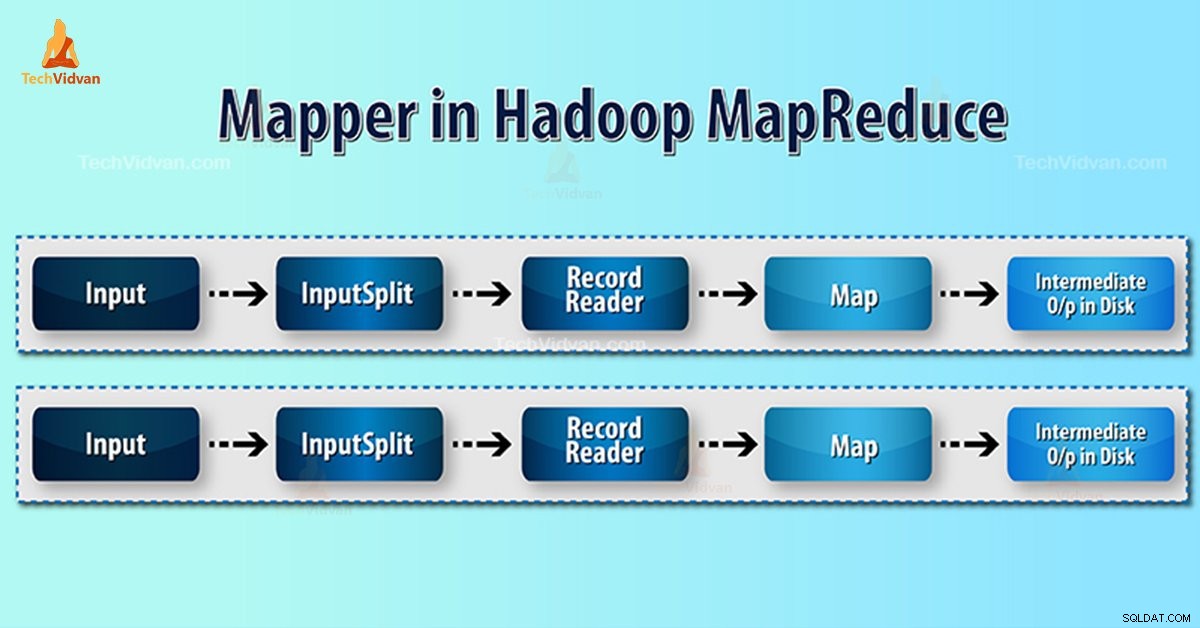
हडूप मैपर RecordReader . द्वारा निर्मित इनपुट रिकॉर्ड को संसाधित करता है और मध्यवर्ती कुंजी-मूल्य जोड़े उत्पन्न करता है। इंटरमीडिएट आउटपुट इनपुट जोड़ी से बिल्कुल अलग है।
मैपर का आउटपुट की-वैल्यू पेयर का पूरा संग्रह है। प्रत्येक मैपर कार्य के लिए आउटपुट लिखने से पहले, कुंजी के आधार पर आउटपुट का विभाजन होता है। इस प्रकार विभाजन यह बताता है कि प्रत्येक कुंजी के सभी मान एक साथ समूहीकृत किए गए हैं।
Hadoop MapReduce प्रत्येक इनपुटस्प्लिट के लिए एक मानचित्र कार्य उत्पन्न करता है।
Hadoop MapReduce केवल डेटा के की-वैल्यू पेयर को समझता है। इसलिए, मैपर को डेटा भेजने से पहले, Hadoop फ्रेमवर्क को डेटा को की-वैल्यू पेयर में छिपा देना चाहिए।
Hadoop में की-वैल्यू पेयर कैसे जेनरेट होता है?
जैसा कि हम समझ चुके हैं कि हडूप में मैपर क्या है, अब हम चर्चा करेंगे कि हडूप की-वैल्यू पेयर कैसे उत्पन्न करता है?
- इनपुट स्प्लिट - यह InputFormat. . द्वारा उत्पन्न डेटा का तार्किक प्रतिनिधित्व है MapReduce कार्यक्रम में, यह कार्य की एक इकाई का वर्णन करता है जिसमें एक एकल मानचित्र कार्य होता है।
- रिकॉर्ड रीडर- यह इनपुटस्प्लिट के साथ संचार करता है। और फिर डेटा को मैपर द्वारा पढ़ने के लिए उपयुक्त कुंजी-मूल्य जोड़े में परिवर्तित करता है। डेटा को की-वैल्यू पेयर में बदलने के लिए RecordReader डिफ़ॉल्ट रूप से TextInputFormat का उपयोग करता है।
Hadoop MapReduce में मैपर प्रक्रिया
इनपुट स्प्लिट मैपर के लिए ब्लॉक के भौतिक प्रतिनिधित्व को तार्किक में परिवर्तित करता है। उदाहरण के लिए, 100MB फ़ाइल को पढ़ने के लिए, इसके लिए 2 InputSplit की आवश्यकता होगी। प्रत्येक ब्लॉक के लिए, ढांचा एक इनपुटस्प्लिट बनाता है। प्रत्येक इनपुटस्प्लिट एक मैपर बनाता है।
MapReduce InputSplit हमेशा डेटा ब्लॉक की संख्या पर निर्भर नहीं करता है . हम mapred.max.split.size प्रॉपर्टी सेट करके स्प्लिट की संख्या बदल सकते हैं कार्य निष्पादन के दौरान।
MapReduce RecordReader फ़ाइल के अंत तक डेटा को की-वैल्यू पेयर में पढ़ने/परिवर्तित करने के लिए जिम्मेदार है। RecordReader फ़ाइल में मौजूद प्रत्येक पंक्ति को बाइट ऑफ़सेट असाइन करता है।
फिर मैपर को यह कुंजी जोड़ी मिलती है। मैपर इंटरमीडिएट आउटपुट (कुंजी-मूल्य जोड़े जो कम करने के लिए समझ में आता है) उत्पन्न करता है।
Hadoop में कितने मानचित्र कार्य हैं?
मानचित्र कार्यों की संख्या इनपुट फ़ाइलों के ब्लॉक की कुल संख्या पर निर्भर करती है। MapReduce मानचित्र में, समांतरता का सही स्तर लगभग 10-100 मानचित्र/नोड प्रतीत होता है। लेकिन सीपीयू-लाइट मैप कार्यों के लिए 300 मानचित्र हैं।
उदाहरण के लिए, हमारे पास 128 एमबी का ब्लॉक आकार है। और हमें 10TB इनपुट डेटा की उम्मीद है। इस प्रकार यह 82,000 मानचित्र तैयार करता है। इसलिए नक्शों की संख्या इनपुटफॉर्मेट पर निर्भर करती है।
मैपर =(कुल डेटा आकार)/ (इनपुट स्प्लिट आकार)
उदाहरण - डेटा का आकार 1 टीबी है। इनपुट स्प्लिट आकार 100 एमबी है।
मैपर =(1000*1000)/100 =10,000
निष्कर्ष
इसलिए, हडूप में मैपर डेटा का एक सेट लेता है और इसे डेटा के दूसरे सेट में परिवर्तित करता है। इस प्रकार, यह अलग-अलग तत्वों को टुपल्स (कुंजी/मूल्य जोड़े) में तोड़ देता है।
आशा है कि आपको यह ब्लॉक पसंद आया होगा, यदि आपके पास हडूप मैपर के लिए कोई प्रश्न है, तो कृपया नीचे दिए गए अनुभाग में एक टिप्पणी छोड़ दें। हमें उनका समाधान करने में खुशी होगी.



