अपाचे Hadoop एक सॉफ्टवेयर फ्रेमवर्क है कि प्रक्रियाओं और वस्तु हार्डवेयर के क्लस्टर के स्टोर बड़ा डेटा। Hadoop एक वितरित ढंग से डेटा की भारी मात्रा के प्रसंस्करण के लिए MapReduce मॉडल पर आधारित है।
यह MapReduce ट्यूटोरियल MapReduce के कई सुविधाओं सूचीबद्ध किया। इस पढ़ने के बाद, आप स्पष्ट रूप से समझ जायेंगे क्यों MapReduce डेटा की विशाल मात्रा में प्रसंस्करण के लिए सबसे उपयुक्त है।
सबसे पहले, हम MapReduce ढांचे के लिए एक छोटा सा परिचय देखेंगे। फिर हम MapReduce की विभिन्न सुविधाओं का पता लगाने जाएगा।
हमें MapReduce ढांचे के लिए परिचय के साथ शुरू करते हैं।
परिचय MapReduce
MapReduce अनुप्रयोगों है कि में महंगी नोड्स के समूहों में डेटा की भारी मात्रा में संसाधित कर सकते हैं लिखने के लिए एक सॉफ्टवेयर रूपरेखा है। Hadoop MapReduce अपाचे Hadoop के प्रसंस्करण हिस्सा है।
यह भी Hadoop के दिल के रूप में जाना जाता है। यह सबसे पसंदीदा डेटा संसाधित अनुप्रयोग है। ऐसे अमेज़न, याहू और Zuventus, आदि के रूप में ई-कॉमर्स के क्षेत्र में कई खिलाड़ियों को उच्च मात्रा डाटा प्रोसेसिंग के लिए MapReduce ढांचे का उपयोग कर रहे हैं।
हमें अब Hadoop MapReduce की विभिन्न सुविधाओं का अध्ययन करें।
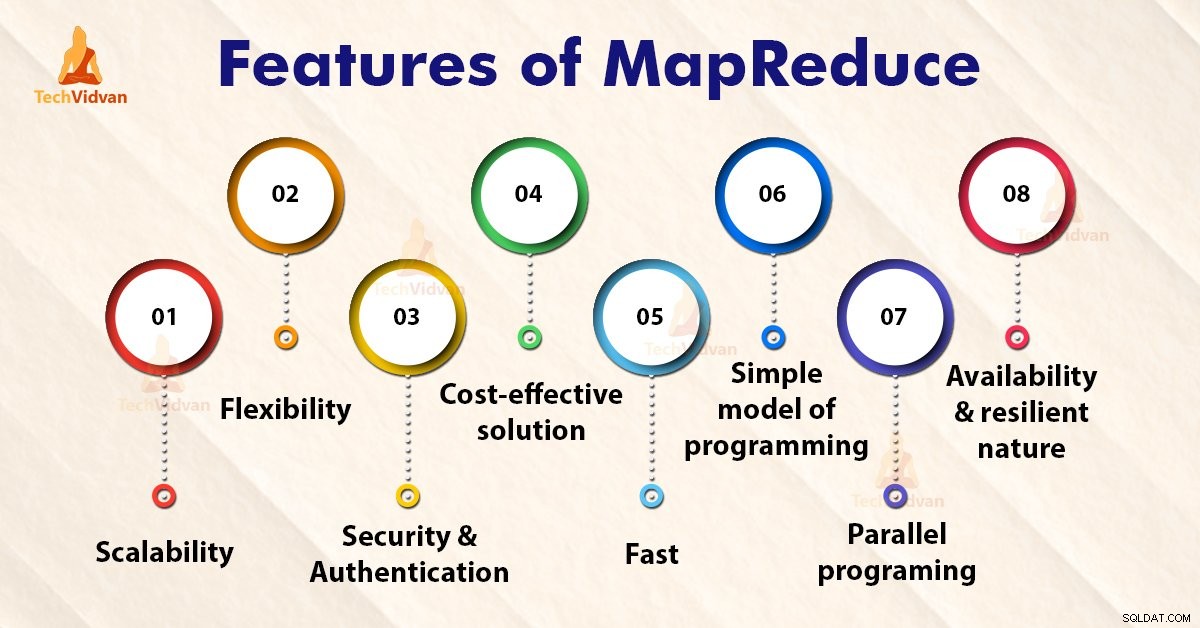
MapReduce की विशेषताएं
1। अनुमापकता
अपाचे Hadoop एक उच्च स्केलेबल रूपरेखा है। इसका कारण यह है की दुकान करने की क्षमता की है और सर्वर के बहुत भर में विशाल डेटा वितरित करते हैं। इन सभी सर्वरों सस्ती थे और समानांतर में कार्य कर सकता है। हम आसानी से क्लस्टर के लिए सर्वर जोड़कर भंडारण और गणना शक्ति माप सकते हैं।
Hadoop MapReduce प्रोग्रामिंग संगठनों नोड्स के बड़े सेट से आवेदन जो डेटा के टेराबाइट्स के हजारों के इस्तेमाल को शामिल कर सकता है चलाने के लिए सक्षम बनाता है।
Hadoop MapReduce प्रोग्रामिंग नोड्स के बड़े सेट से चलाने के आवेदन करने के लिए व्यापार संगठनों सक्षम बनाता है। इस डेटा के टेराबाइट्स के हजारों का उपयोग कर सकते हैं।
2। लचीलापन
MapReduce प्रोग्रामिंग कंपनियों डेटा के नए स्रोतों का उपयोग करने के लिए सक्षम बनाता है। यह कंपनियों के विभिन्न प्रकार के डेटा पर संचालित करने के लिए सक्षम बनाता है। यह उपयोग करने के लिए उद्यमों को अच्छी तरह असंरचित डेटा के रूप में के रूप में संरचित की अनुमति देता है, और डेटा के कई स्रोतों से जानकारी प्राप्त करने कर अपना महत्व निकाले जाते हैं।
साथ ही, MapReduce ढांचे भी ईमेल, सामाजिक मीडिया से लेकर स्रोतों से कई भाषाओं और डेटा के लिए समर्थन, क्लिकस्ट्रीम को उपलब्ध कराता है।
MapReduce सरल कुंजी-मान जोड़ों में डाटा को संसाधित करता इस प्रकार मेटा डेटा, चित्र, और बड़ी फ़ाइलों सहित डेटा प्रकार का समर्थन करता है। इसलिए, MapReduce पारंपरिक डीबीएमएस के बजाय डेटा से निपटने के लिए लचीला है।
3। सुरक्षा और प्रमाणीकरण
MapReduce प्रोग्रामिंग मॉडल है कि डेटा पर संचालित करने के लिए केवल प्रमाणीकृत उपयोगकर्ताओं के लिए उपयोग की अनुमति देता HBase और HDFS सुरक्षा मंच का उपयोग करता है। इस प्रकार, यह प्रणाली डेटा और बढ़ाता सिस्टम सुरक्षा को अनधिकृत पहुँच सुरक्षा करता है।
4। लागत प्रभावी समाधान
MapReduce प्रोग्रामिंग ढांचे के साथ Hadoop के योग्य संरचना भंडारण और एक बहुत ही किफायती ढंग से बड़े डेटा सेट के प्रसंस्करण की अनुमति देता है।
5। फास्ट
Hadoop एक Hadoop वितरित फ़ाइल सिस्टम है कि मूल रूप से एक क्लस्टर में डेटा का पता लगाने के लिए एक मानचित्रण प्रणाली लागू करता है के रूप में बुलाया एक वितरित भंडारण विधि का उपयोग करता।
इस तरह के MapReduce प्रोग्रामिंग के रूप में उपकरण है कि डाटा प्रोसेसिंग के लिए उपयोग किया जाता है, आम तौर पर बहुत ही सर्वर तेजी से डाटा के प्रसंस्करण के लिए अनुमति देते हैं पर स्थित हैं।
तो, यहां तक कि अगर हम असंरचित डेटा की बड़ी मात्रा के साथ काम कर रहे हैं, Hadoop MapReduce सिर्फ डेटा की प्रक्रिया टेराबाइट्स मिनट लगते हैं। यह सिर्फ एक घंटे में डेटा के बॉबी चांग संसाधित कर सकते हैं।
6। प्रोग्रामिंग के
सरल मॉडलHadoop MapReduce की विभिन्न सुविधाओं के बीच, सबसे महत्वपूर्ण सुविधाओं में से एक यह है कि यह एक सरल प्रोग्रामिंग मॉडल पर आधारित है है। असल में, इस प्रोग्रामर आसानी से और कुशलता से MapReduce प्रोग्राम जो कार्य संभाल कर सकते हैं विकसित करने के लिए अनुमति देता है।
MapReduce कार्यक्रमों जावा, जो बहुत लेने के लिए कठिन नहीं है और भी व्यापक रूप से प्रयोग किया जाता है में लिखा जा सकता है। तो, किसी को भी आसानी से सीख सकते हैं और लिखने MapReduce कार्यक्रमों और अपने डेटा प्रसंस्करण जरूरतों को पूरा कर सकते हैं।
7। समानांतर प्रोग्रामिंग
MapReduce प्रोग्रामिंग के काम के प्रमुख पहलुओं में से एक अपनी समानांतर प्रसंस्करण है। यह एक तरह से कि समानांतर में उनके निष्पादन की अनुमति देता है में कार्य विभाजित करता है।
समानांतर प्रसंस्करण एकाधिक प्रोसेसर इन विभाजित कार्य निष्पादित करने के लिए अनुमति देता है। तो पूरे कार्यक्रम कम समय में चलाया जाता है।
8। उपलब्धता और लचीला प्रकृति
डेटा वैयक्तिक नोड के लिए भेज दिया जाता है जब भी, डेटा के एक ही सेट एक क्लस्टर में कुछ अन्य नोड्स को भेजा जाता है। तो, अगर एक विफलता से किसी विशेष नोड ग्रस्त है, तो वहाँ हमेशा अन्य नोड अभी भी जब भी जरूरत पहुँचा जा सकता है कि पर उपस्थित अन्य प्रतियां हैं। डेटा का यह भरोसा दिलाते उच्च उपलब्धता।
अपाचे Hadoop द्वारा की पेशकश की प्रमुख विशेषताओं में से एक अपने दोष सहिष्णुता है। Hadoop MapReduce ढांचे जल्दी से पहचानने दोष है कि हो करने की क्षमता है।
यह तो एक त्वरित और स्वत:वसूली समाधान लागू होता है। यह सुविधा बड़ा डाटा प्रोसेसिंग की दुनिया में एक खेल परिवर्तक बनाता है।
सारांश
मुझे आशा है कि इस लेख को पढ़ने के बाद आप स्पष्ट रूप से Hadoop MapReduce की विभिन्न सुविधाओं को समझा। लेख MapReduce की विभिन्न सुविधाओं सूचीबद्ध किया। MapReduce ढांचे स्केलेबल, लचीला, लागत प्रभावी, और तेजी से प्रसंस्करण प्रणाली है।
यह सुरक्षा, गलती सहिष्णुता, और प्रमाणीकरण प्रदान करता है। MapReduce प्रोग्रामिंग और प्रस्तावों के समानांतर प्रोग्रामिंग का एक सरल मॉडल है।



