आप Hadoop MapReduce बारे में सब कुछ जानना चाहते हैं, तो आप सही स्थान पर आए हैं। यह MapReduce ट्यूटोरियल आप प्रत्येक और Hadoop MapReduce में सब कुछ के बारे में पूरी मार्गदर्शन प्रदान करता है।
इस MapReduce परिचय में, आप का पता लगाने जाएगा क्या Hadoop MapReduce है, कैसे MapReduce ढांचे काम करता है। लेख में यह भी MapReduce dataflow, MapReduce, मैपर, Reducer, विभाजनर, Cominer, फेरबदल, छंटाई, डाटा इलाके में अलग-अलग चरणों, और कई और अधिक शामिल हैं।
हम यह भी MapReduce ढांचे के फायदे सूचीबद्ध किया है।
पहले हम यह पता लगाने के कारण है कि हम Hadoop MapReduce की जरूरत हैं।
क्यों MapReduce?
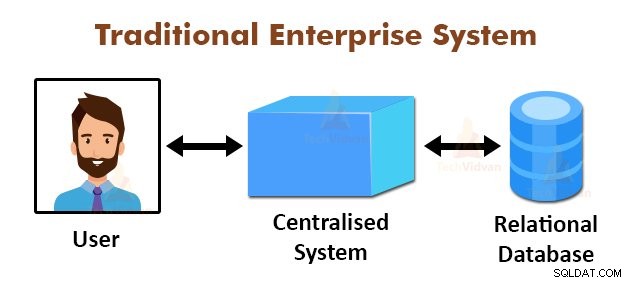
ऊपर चित्र पारंपरिक उद्यम प्रणालियों के योजनाबद्ध दृश्य दर्शाया गया है। पारंपरिक प्रणालियों सामान्य रूप से भंडारण और डेटा के प्रसंस्करण के लिए एक केंद्रीकृत सर्वर है। यह मॉडल स्केलेबल डेटा की भारी मात्रा के प्रसंस्करण के लिए उपयुक्त नहीं है।
इसके अलावा, इस मॉडल मानक डाटाबेस सर्वर से समायोजित नहीं किया जा सकता है। एक साथ कई फ़ाइलों को संसाधित करते समय इसके अतिरिक्त, केंद्रीकृत प्रणाली बहुत ज्यादा अड़चन पैदा करता है।
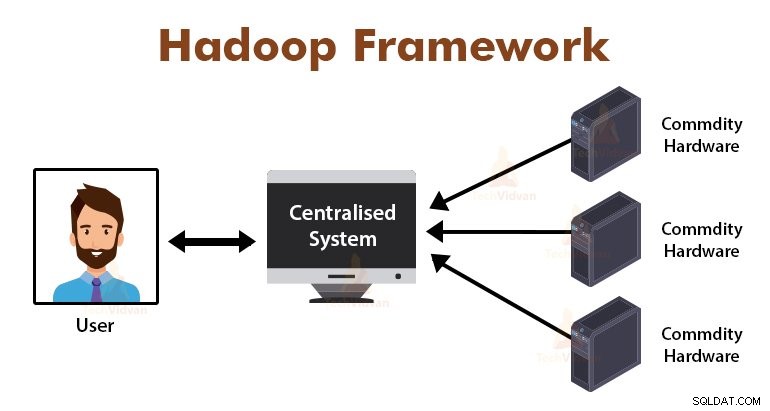
MapReduce कलन विधि का उपयोग करने से, गूगल इस टोंटी समस्या हल हो जाती। MapReduce ढांचे विभाजित कई कंप्यूटरों के लिए छोटे भागों और प्रदान कार्यों में कार्य।
बाद में, परिणाम एक सामान्य में एकत्र कर रहे हैं और उसके बाद परिणाम डाटासेट के रूप में एकीकृत कर रहे हैं।
MapReduce फ्रेमवर्क का परिचय
MapReduce Hadoop में प्रसंस्करण परत है। यह स्वतंत्र कार्यों के सेट में कार्य विभाजित करके समानांतर में डेटा की भारी मात्रा के प्रसंस्करण के लिए डिज़ाइन किया गया एक सॉफ्टवेयर रूपरेखा है।
हम अभी जिस तरह से काम करता है MapReduce में व्यापार तर्क लगाने की जरूरत है, और ढांचे बाकी बातों का ख्याल रखना होगा। MapReduce ढांचे दास को इन कार्यों को छोटे कार्यों और प्रदान में काम को विभाजित करके काम करता है।
MapReduce कार्यक्रमों एक विशेष शैली कार्यात्मक प्रोग्रामिंग निर्माणों, डेटा की सूची के प्रसंस्करण के लिए specifical मुहावरों से प्रभावित में लिखे गए हैं।
MapReduce में, आदानों एक सूची के रूप में कर रहे हैं और ढांचे से उत्पादन एक सूची के रूप में भी है। MapReduce Hadoop का दिल है। दक्षता और Hadoop के powerfulness MapReduce ढांचे समानांतर प्रसंस्करण की वजह से कर रहे हैं।
अब हमें पता लगाने कैसे Hadoop MapReduce काम करता है।
कैसे Hadoop MapReduce काम करती है?
Hadoop MapReduce ढांचा स्वतंत्र कार्यों में एक नौकरी विभाजित और गुलाम मशीनों पर इन कार्यों को क्रियान्वित करते हुए काम करता है। MapReduce काम दो चरणों है कि नक्शे चरण होते हैं और चरण को कम में मार डाला गया है।
के लिए इनपुट और दोनों चरणों से उत्पादन कुंजी, मूल्य जोड़े हैं। MapReduce ढांचे डेटा इलाके सिद्धांत (जो बाद में चर्चा की) जो इसे नोड्स गणना भेजता है इसका मतलब है पर आधारित है जहां डाटा बसता था।
- नक्शा चरण - मानचित्र चरण में, उपयोगकर्ता परिभाषित नक्शा समारोह इनपुट डेटा संसाधित करता है। नक्शा समारोह में, उपयोगकर्ता व्यापार तर्क डालता है। मानचित्र चरण से उत्पादन मध्यवर्ती आउटपुट और स्थानीय डिस्क पर संग्रहीत किया जाता है।
- कम चरण - इस चरण में फेरबदल चरण का संयोजन है और चरण को कम। कम चरण में, नक्शा मंच से उत्पादन प्रसारण जहां वे एकत्रित कर रहे हैं करने के लिए पारित कर दिया है। कम चरण के उत्पादन में अंतिम आउटपुट है। कम चरण में, उपयोगकर्ता परिभाषित समारोह को कम मानचित्रकारों उत्पादन संसाधित करता है और अंतिम परिणाम उत्पन्न करता है।
MapReduce काम के दौरान, Hadoop ढांचे मानचित्र कार्यों भेजता है और क्लस्टर में उचित मशीनों के कार्यों को कम करें।
ढांचा ही के सभी विवरण का प्रबंधन करता है डेटा गुजर, कार्य जारी करने के कार्य पूरे होने के सत्यापन, और क्लस्टर के आसपास नोड्स के बीच डेटा की प्रतिलिपि के रूप में इस तरह के। कार्य नोड्स पर जगह ले जहां डाटा बसता था आदेश नेटवर्क यातायात को कम करने में।
MapReduce डेटा प्रवाह
आप सभी को पता है MapReduce इनपुट डेटा को संसाधित करता है कि कैसे इन महत्वपूर्ण मूल्य जोड़े उत्पन्न कर रहे हैं और कैसे कर सकते हैं। इस खंड में ये सभी सवालों का जवाब देता है।
हम देखते हैं कैसे डेटा Hadoop MapReduce में विभिन्न चरणों से प्रवाह के लिए एक समानांतर और वितरित ढंग से आगामी डेटा को संभालने के लिए है करते हैं।
1। InputFiles
इनपुट डाटासेट है, जो MapReduce कार्यक्रम द्वारा संसाधित किया जा रहा है inputfile में संग्रहित है। Inputfile Hadoop वितरित फ़ाइल प्रणाली में संग्रहीत किया जाता है।
2। InputSplit
InputFiles में रिकॉर्ड तार्किक मॉडल में विभाजित है। विभाजन आकार आमतौर पर HDFS ब्लॉक आकार के बराबर है। प्रत्येक विभाजन व्यक्ति मैपर द्वारा संसाधित किया जाता है।
3। InputFormat
InputFormat फ़ाइल इनपुट विनिर्देश निर्दिष्ट करता है। यह RecordReader जिसमें inputfile से रिकॉर्ड कुंजी में बदल जाता है, मान के जोड़े के लिए रास्ता परिभाषित करता है।
4। RecordReader
RecordReader मानचित्रकारों की कुंजी, मान के जोड़े में InputSplit और रूपांतरित होता रिकॉर्ड से डेटा, और उन्हें प्रस्तुत करता है पढ़ता है।
5। मानचित्रकारों
मानचित्रकारों RecordReader से इनपुट के रूप में कुंजी, मान युग्म लेने के लिए और उपयोगकर्ता-निर्धारित नक्शा समारोह को लागू करने से उन्हें प्रोसेस। प्रत्येक मैपर में, एक समय में, एक एकल विभाजन संसाधित किया जाता है।
डेवलपर नक्शा समारोह में व्यापार तर्क डाल दिया। सभी मानचित्रकारों से उत्पादन मध्यवर्ती उत्पादन है, जो एक कुंजी, मान जोड़ों के रूप में भी है।
6। शफ़ल करें और क्रमबद्ध
मध्यवर्ती मानचित्रकारों द्वारा उत्पन्न उत्पादन आदेश नेटवर्क संकुलता को कम करने के प्रसारण को पार करने से पहले सॉर्ट की गई है। हल कर मध्यवर्ती आउटपुट तो नेटवर्क पर प्रसारण के लिए shuffled हैं।
7। कम करने
प्रसारण की प्रक्रिया और समुच्चय उपयोगकर्ता परिभाषित को लागू करने से मैपर आउटपुट समारोह को कम। कम करने वाली उत्पादन अंतिम आउटपुट है और Hadoop वितरित फ़ाइल सिस्टम (HDFS) में संग्रहित है।
हमें अब कुछ शब्दावलियों और Hadoop MapReduce ढांचे के अग्रिम अवधारणाओं का अध्ययन करें।
MapReduce में कुंजी-मान जोड़ों
MapReduce ढांचे कुंजी, मान जोड़ों पर काम करता है, क्योंकि यह गैर स्थिर स्कीमा से संबंधित है। यह महत्वपूर्ण है, मान के जोड़े के रूप में डेटा लेता है, और उत्पन्न उत्पादन एक प्रमुख, मान जोड़ों के रूप में भी है।
MapReduce कुंजी मान युग्म होता है निष्पादन के लिए MapReduce काम द्वारा प्राप्त होता है एक रिकार्ड इकाई है। एक कुंजी-मान पेयर में:
- कुंजी लाइन फ़ाइल के भीतर पंक्ति के आरंभ से ऑफसेट है।
- मूल्य लाइन सामग्री, लाइन टर्मिनेटर्स को छोड़कर है।
MapReduce विभाजनर
Hadoop MapReduce विभाजनर keyspace विभाजित कर। MapReduce निर्दिष्ट में विभाजन keyspace कि सभी प्रत्येक कुंजी के मूल्यों को एक साथ समूहीकृत कर रहे थे, और यह सुनिश्चित करता है कि सभी एकल कुंजी के मान ही प्रसारण के पास जाना चाहिए।
यह विभाजन आश्वस्त कि सही कुंजी सही प्रसारण को जाता है द्वारा प्रसारण से अधिक नक्शाकार उत्पादन का भी वितरण की अनुमति देता है।
डिफ़ॉल्ट MapReducer विभाजक हैश विभाजनर है, जो हैश मान के आधार पर विभाजन keyspaces।
MapReduce Combiner
MapReduce Combiner के रूप में भी जाना जाता है "अर्ध प्रसारण।" यह नेटवर्क भीड़ को कम करने में एक प्रमुख भूमिका निभाता है। MapReduce ढांचे Combiner, जो उन्हें प्रसारण को पार करने से पहले मानचित्रकारों से मध्यवर्ती उत्पादन को जोड़ती है परिभाषित करने के लिए सुविधा प्रदान करता है।
प्रसारण के लिए पार करने से पहले मैपर आउटपुट के एकत्रीकरण में मदद करता है ढांचे डेटा की थोड़ी मात्रा शफ़ल, कम नेटवर्क संकुलता के लिए अग्रणी।
Combiner का मुख्य कार्य एक ही कुंजी के साथ Mappers के उत्पादन में संक्षिप्त और यह प्रसारण को भेजना है। Combiner वर्ग मैपर वर्ग और प्रसारण वर्ग के बीच किया जाता है।
MapReduce में डाटा इलाका
डाटा इलाके "गणना के बजाय गणना करने के लिए डेटा स्थानांतरित करने से डेटा के करीब ले जा रहा है।" को संदर्भित करता है यह बहुत अधिक कुशल है, तो गणना आवेदन द्वारा अनुरोध मशीन जहां डाटा का अनुरोध किया बसता था पर निष्पादित किया जाता है।
इस मामले में जहां डाटा का आकार बहुत बड़ा है में बिल्कुल सच है। क्योंकि यह नेटवर्क संकुलता को कम करता है और इस प्रणाली के समग्र प्रवाह क्षमता बढ़ जाती है यह है।
इसके पीछे केवल धारणा है कि यह गणना मशीन के करीब ले जाने के लिए जहां डाटा बजाय मशीन जहां आवेदन चल रहा है करने के लिए डेटा ले जाने की मौजूद है बेहतर है।
अपाचे Hadoop डेटा की एक बड़ी मात्रा पर काम करता है, तो यह नेटवर्क पर इस तरह के विशाल डेटा स्थानांतरित करने के लिए कुशल नहीं है। इसलिए ढांचा सबसे नवीन सिद्धांत डेटा इलाके, जो बजाय गणना एल्गोरिदम के डेटा ले जाने की आंकड़ों के अभिकलन तर्क ले जाता है कि के साथ आया था। इस डेटा इलाके कहा जाता है।
MapReduce के लाभ
1। अनुमापकता: MapReduce ढांचे अत्यधिक स्केलेबल है। यह संगठनों मशीनों के बड़े सेट है, जो डेटा के टेराबाइट्स के हजारों के इस्तेमाल को शामिल कर सकते हैं से आवेदन को चलाने के लिए सक्षम बनाता है।
2। लचीलापन: MapReduce ढांचे, किसी भी आकार और किसी भी प्रारूप की प्रक्रिया के आंकड़ों के संगठन के लिए लचीलापन प्रदान करता है या तो संरचित, अर्द्ध संरचित, या असंरचित।
3। सुरक्षा और प्रमाणीकरण: MapReduce प्रोग्रामिंग मॉडल उच्च सुरक्षा प्रदान करता है। यह डेटा और बढ़ाता सुरक्षा क्लस्टर के लिए किसी भी अनधिकृत पहुँच सुरक्षा करता है।
4। लागत प्रभावी: ढांचा वस्तु हार्डवेयर के क्लस्टर भर में डेटा है, जिसमें महंगी मशीनें हैं संसाधित करता है। इस प्रकार, यह बहुत लागत प्रभावी है।
5। फास्ट: MapReduce समानांतर में डाटा को संसाधित करता जिसके कारण यह बहुत तेजी से है। यह सिर्फ डेटा की प्रक्रिया टेराबाइट्स मिनट लगते हैं।
6। प्रोग्रामिंग के लिए एक सरल मॉडल: MapReduce कार्यक्रमों जैसे जावा, अजगर, पर्ल, आर, आदि तो जैसा कि किसी भी भाषा में लिखा जा सकता है, किसी को भी आसानी से सीख सकते हैं और लिखने MapReduce कार्यक्रमों और अपने डेटा प्रसंस्करण आवश्यकताओं को पूरा।
MapReduce की
प्रयोग1। लॉग विश्लेषण: MapReduce लॉग फाइल विश्लेषण करने के लिए मूल रूप से प्रयोग किया जाता है। ढांचा टूट विभाजन और विभिन्न वेब पृष्ठों है कि पहुँचा रहे थे के लिए एक नक्शाकार खोज में बड़ा लॉग फाइल।
हर बार जब आप एक वेब पृष्ठ लॉग में पाया जाता है, तो एक कुंजी, मान युग्म कम करने, जिनके कुंजी वेबपेज है के लिए पारित किया है, और मूल्य "1" है। एक चाबी, प्रसारण के लिए मान युग्म उत्सर्जन के बाद, कम करने वाली कुछ वेब पृष्ठों के लिए की संख्या दिखाते हैं।
अंतिम परिणाम हर वेबपेज के लिए हिट की कुल संख्या हो जाएगा।
2। पूर्ण पाठ अनुक्रमण: MapReduce भी पूर्ण पाठ अनुक्रमण के प्रदर्शन के लिए प्रयोग किया जाता है। MapReduce में नक्शाकार दस्तावेज़ एक दस्तावेज़ में हर वाक्यांश या शब्द नक्शा होगा। प्रसारण एक सूचकांक करने के लिए इन मैपिंग लिखेगा।
3। गूगल अपने पेजरैंक की गणना के लिए MapReduce का उपयोग करता है।
4। रिवर्स वेब लिंक ग्राफ़: MapReduce भी रिवर्स वेब लिंक ग्राफ में प्रयोग किया जाता है। मानचित्र समारोह यूआरएल लक्ष्य और स्रोत आउटपुट, वेबपेज (स्रोत) से इनपुट लेने।
को कम समारोह तो सभी स्रोत URL जो कि दिए गए लक्ष्य यूआरएल के साथ जुड़े रहे की सूची संयोजित करता है और यह लक्ष्य और स्रोतों की सूची देता है।
5। एक दस्तावेज़ में पद गणना: MapReduce ढांचा किसी दस्तावेज़ में बार शब्द प्रकट होता है की संख्या की गणना के लिए इस्तेमाल किया जा सकता है।
सारांश
यह Hadoop MapReduce ट्यूटोरियल बारे में है। ढांचा वस्तु हार्डवेयर के क्लस्टर भर में समानांतर में डेटा की भारी मात्रा में संसाधित करता है। यह क्लस्टर में अलग नोड्स पर समानांतर में स्वतंत्र कार्यों और उन्हें कार्यान्वित में काम बिताते हैं।
MapReduce पारंपरिक उद्यम प्रणाली के टोंटी पर काबू पा। ढांचा कुंजी, मान जोड़ों पर काम करता है। उपयोगकर्ता दो कार्य है कि नक्शे समारोह कर रहे हैं और समारोह को कम परिभाषित करता है।
व्यापार तर्क नक्शा समारोह में डाल दिया है। लेख MapReduce ढांचे के विभिन्न उन्नत अवधारणाओं के बारे में बताया था।



