सेंटेंडर यूके में Apache Flume, Apache Kafka, और RocksDB का उपयोग करके डेटा स्ट्रीम को बदलने और समृद्ध करने के लिए रीयल-टाइम डेटा इंजेस्ट आर्किटेक्चर के बारे में जानें।
Cloudera Professional Services, Apache Hadoop पर एक निकट वास्तविक समय (NRT) ट्रांजेक्शनल एनालिटिक्स सिस्टम बनाने के लिए Santander UK के साथ काम कर रही है। इसका उद्देश्य कार्ड से खरीदारी होने के कुछ सेकंड के भीतर लेन-देन को पकड़ना, बदलना, समृद्ध करना, गिनना और संग्रहीत करना है। सिस्टम बैंक के खुदरा ग्राहक कार्ड लेनदेन को प्राप्त करता है और खाता धारक और कई आयामों और टैक्सोनॉमी द्वारा एकत्रित संबंधित प्रवृत्ति जानकारी की गणना करता है। इसके बाद यह जानकारी Santander के "Spendlytics" ऐप (नीचे देखें) में सुरक्षित रूप से पेश की जाती है ताकि ग्राहक अपने नवीनतम खर्च पैटर्न का विश्लेषण कर सकें।
उच्च-थ्रूपुट यादृच्छिक लेखन, और कम-विलंबता यादृच्छिक पढ़ने का समर्थन करने की क्षमता के कारण Apache HBase को अंतर्निहित भंडारण समाधान के रूप में चुना गया था। हालांकि, एनआरटी की आवश्यकता ने बैच में लेनदेन के रूपांतरण और संवर्धन को खारिज कर दिया, इसलिए लेनदेन को एचबीएएस में स्ट्रीम करते समय ये किया जाना चाहिए। इसमें एक्सएमएल से एवरो में संदेशों को बदलना और उन्हें ट्रेंड-सक्षम जानकारी, जैसे ब्रांड और व्यापारी जानकारी के साथ समृद्ध करना शामिल है।
यह पोस्ट बताता है कि कैसे Santander Apache Flume, Apache Kafka और RocksDB का उपयोग HBase में लेनदेन को बदलने, समृद्ध करने और स्ट्रीम करने के लिए करता है। यह बाहरी संदर्भ के साथ एनआरटी इवेंट प्रोसेसिंग . का कार्यान्वयन है इस पोस्ट में टेड मलस्का द्वारा वर्णित स्ट्रीमिंग पैटर्न।
फ्लाफ्का
सेंटेंडर को पहला निर्णय यह करना था कि डेटा को HBase में कैसे स्ट्रीम किया जाए। इसकी सादगी, विश्वसनीयता, समृद्ध स्रोत और सिंक, और अंतर्निहित मापनीयता को देखते हुए Flume लगभग हमेशा Hadoop में अंतर्ग्रहण स्ट्रीमिंग के लिए सबसे अच्छा विकल्प है।
हाल ही में, काफ्का के लिए उत्कृष्ट एकीकरण को जोड़ा गया है, जिससे अनिवार्य रूप से फ्लैफ्का नाम दिया गया है। फ़्लूम अपने फ़ाइल चैनल के माध्यम से मूल रूप से गारंटीकृत ईवेंट डिलीवरी प्रदान कर सकता है, लेकिन ईवेंट को फिर से चलाने की क्षमता और अतिरिक्त लचीलापन और भविष्य-प्रूफिंग काफ्का लाता है जो एकीकरण के लिए प्रमुख ड्राइवर थे।
इस वास्तुकला में, सैंटेंडर एक विश्वसनीय, आत्म-संतुलन, और स्केलेबल अंतर्ग्रहण बफर प्रदान करने के लिए काफ्का चैनलों का उपयोग करता है जिसमें जंजीर काफ्का विषयों में सभी परिवर्तनों और प्रसंस्करण का प्रतिनिधित्व किया जाता है। विशेष रूप से, हम Flafka के स्रोत और सिंक का व्यापक उपयोग करते हैं, और फ़्लूम की इंटरसेप्टर का उपयोग करके इन-फ़्लाइट प्रोसेसिंग करने की क्षमता। इसने हमें अपने स्वयं के काफ्का निर्माता और उपभोक्ता को कोड करने से रोका, और सेंटेंडर को एजेंटों और दलालों को कॉन्फ़िगर करने, तैनात करने और निगरानी करने के लिए क्लौडेरा प्रबंधक का पूरा लाभ उठाने की अनुमति दी।
रूपांतरण
कोर बैंकिंग सिस्टम द्वारा कैप्चर किए गए लेन-देन फ्लूम को एक्सएमएल संदेशों के रूप में वितरित किए जाते हैं, जिन्हें लॉग प्रतिकृति के माध्यम से स्रोत डेटाबेस से पढ़ा जाता है। (इस तरह से काफ्का विषयों में डेटाबेस लॉग को टेल करना एक तेजी से सामान्य पैटर्न है और लॉग कॉम्पैक्शन के साथ मिलकर, डेटा कैप्चर उपयोग के मामलों में परिवर्तन के लिए डेटाबेस का "सबसे हालिया दृश्य" दे सकता है।)
Flume इन XML संदेशों को "कच्चे" काफ्का विषय में संग्रहीत करता है। यहां से, और अन्य सभी प्रसंस्करण के अग्रदूत के रूप में, मानकीकृत डाउनस्ट्रीम प्रसंस्करण की सुविधा के लिए अर्ध-संरचित एक्सएमएल को संरचित बाइनरी रिकॉर्ड में बदलने का निर्णय लिया गया था। यह प्रसंस्करण एक कस्टम फ्लूम इंटरसेप्टर द्वारा किया जाता है जो एक्सएमएल संदेशों को एक सामान्य एवरो प्रतिनिधित्व में बदल देता है, जहां उपयुक्त विशिष्ट प्रकार लागू करता है और जहां नहीं वहां स्ट्रिंग प्रतिनिधित्व पर वापस आ जाता है। बाद की सभी एनआरटी प्रोसेसिंग तब एवरो में समर्पित काफ्का विषयों में व्युत्पन्न परिणामों को संग्रहीत करती है, जिससे स्ट्रीम में टैप करना और प्रसंस्करण श्रृंखला में किसी भी बिंदु पर एक ईवेंट फ़ीड प्राप्त करना आसान हो जाता है।
यदि अधिक जटिल घटना प्रसंस्करण की आवश्यकता होती है - उदाहरण के लिए स्पार्क स्ट्रीमिंग के साथ एकत्रीकरण - तो इनमें से एक या अधिक विषयों का उपभोग करना और नए व्युत्पन्न विषयों पर प्रकाशित करना एक तुच्छ मामला होगा। (अपाचे एवरो इस प्रारूप के लिए एक स्वाभाविक पसंद है:यह एक कॉम्पैक्ट बाइनरी प्रोटोकॉल है जो स्कीमा विकास का समर्थन करता है, इसकी एक लचीली स्कीमा परिभाषा है, और पूरे हडोप स्टैक में समर्थित है। एवरो तेजी से अंतरिम और सामान्य डेटा भंडारण के लिए एक वास्तविक मानक बन रहा है एक एंटरप्राइज़ डेटा हब और एनालिटिक्स वर्कलोड के लिए Apache Parquet में परिवर्तन के लिए पूरी तरह से तैयार है।)
समृद्धि
स्ट्रीमिंग संवर्धन समाधान के डिजाइन के लिए प्रेरणा जे क्रेप्स द्वारा लिखित ओ'रेली रडार पोस्ट से मिली। अपने पोस्ट में, जे एक स्थानीय स्टोर का उपयोग करने के लाभों का वर्णन करता है ताकि एक स्ट्रीम प्रोसेसर को अपने इनपुट के जवाब में स्थानीय स्थिति को क्वेरी या संशोधित करने में सक्षम बनाया जा सके, जैसा कि एक वितरित डेटाबेस में दूरस्थ कॉल करने के विपरीत है।
सेंटेंडर में, हमने स्थानीय संदर्भ स्टोर प्रदान करने के लिए इस पैटर्न को अनुकूलित किया है जो कि फ्लूम के माध्यम से स्ट्रीम के रूप में लेनदेन को क्वेरी और समृद्ध करने के लिए उपयोग किया जाता है। संदर्भ स्टोर के रूप में HBase का उपयोग क्यों न करें? खैर, इस प्रकार की समस्या के लिए एक विशिष्ट पैटर्न केवल राज्य को HBase में संग्रहीत करना है और संवर्धन तंत्र को सीधे क्वेरी करना है। हमने कुछ कारणों से इस दृष्टिकोण के खिलाफ फैसला किया। सबसे पहले, संदर्भ डेटा अपेक्षाकृत छोटा है और एक एकल HBase क्षेत्र में फिट होगा, संभवतः एक क्षेत्र हॉटस्पॉट का कारण बन सकता है। दूसरा, HBase ग्राहक-सामना करने वाले स्पेंड्लीटिक्स ऐप की सेवा करता है और सैंटेंडर नहीं चाहता था कि अतिरिक्त लोड ऐप विलंबता को प्रभावित करे, या इसके विपरीत। यही कारण है कि हमने स्टार्टअप पर स्थानीय स्टोर को बूटस्ट्रैप करने के लिए HBase का उपयोग नहीं करने का निर्णय लिया।
इसलिए, प्रत्येक फ़्लूम एजेंट को इन-फ़्लाइट इवेंट्स को समृद्ध करने के लिए तेज़ स्थानीय स्टोर प्रदान करके, सैंटेंडर इन-फ़्लाइट संवर्धन और स्पेंड्लीटिक्स ऐप दोनों के लिए बेहतर प्रदर्शन गारंटी देने में सक्षम है। हमने स्थानीय स्टोरों को लागू करने के लिए रॉक्सडीबी का उपयोग करने का निर्णय लिया क्योंकि यह बड़ी मात्रा में ऑफ-हीप डेटा (जीसी पर बोझ को खत्म करने) तक तेजी से पहुंच प्रदान करने में सक्षम है, और तथ्य यह है कि इसमें जावा एपीआई है जिससे इसका उपयोग करना आसान हो जाता है। एक कस्टम फ्लूम इंटरसेप्टर। इस दृष्टिकोण ने हमें अपने स्वयं के ऑफ-हीप स्टोर को कोड करने से बचाया। रॉक्सडीबी को किसी अन्य स्थानीय स्टोर कार्यान्वयन के लिए आसानी से बदला जा सकता है, लेकिन इस मामले में यह सेंटेंडर के उपयोग के मामले के लिए एकदम उपयुक्त था।
कस्टम फ्लूम संवर्धन इंटरसेप्टर कार्यान्वयन अपस्ट्रीम "रूपांतरित" विषय से घटनाओं को संसाधित करता है, उन्हें समृद्ध करने के लिए अपने स्थानीय स्टोर से पूछताछ करता है, और परिणाम के आधार पर डाउनस्ट्रीम काफ्का विषयों को परिणाम लिखता है। इस प्रक्रिया को नीचे और अधिक विस्तार से दिखाया गया है।
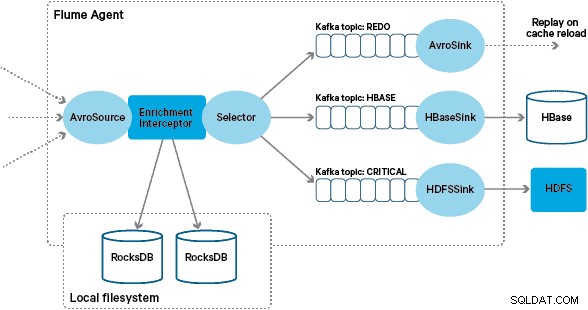
इस बिंदु पर आप सोच रहे होंगे:बिना HBase द्वारा प्रदान की गई दृढ़ता के, स्थानीय स्टोर कैसे उत्पन्न होते हैं? संदर्भ डेटा में कई अलग-अलग डेटासेट शामिल होते हैं जिन्हें एक साथ जोड़ने की आवश्यकता होती है। ये डेटासेट दैनिक आधार पर एचडीएफएस में रीफ्रेश किए जाते हैं और एक अनुसूचित अपाचे स्पार्क एप्लिकेशन में इनपुट बनाते हैं, जो रॉक्सडीबी स्टोर उत्पन्न करता है। नव निर्मित RocksDB स्टोर HDFS में तब तक मंचित किए जाते हैं जब तक कि उन्हें Flume एजेंटों द्वारा डाउनलोड नहीं किया जाता है ताकि यह सुनिश्चित हो सके कि ईवेंट स्ट्रीम नवीनतम जानकारी से समृद्ध हो रही है।
आदर्श रूप से, हमें इन डेटासेट के संसाधित होने से पहले HDFS में सभी के उपलब्ध होने की प्रतीक्षा नहीं करनी होगी। यदि ऐसा होता, तो स्थानीय संदर्भ डेटा स्थिति को लगातार बनाए रखने के लिए संदर्भ डेटा अपडेट को Flafka पाइपलाइन के माध्यम से स्ट्रीम किया जा सकता है।
हमारे प्रारंभिक डिजाइन में हमने क्रॉन्स के माध्यम से एक स्क्रिप्ट लिखने और शेड्यूल करने की योजना बनाई थी ताकि रॉक्सडीबी स्टोर्स के नए संस्करणों की जांच करने के लिए एचडीएफएस का सर्वेक्षण किया जा सके, जब उपलब्ध हो तो उन्हें एचडीएफएस से डाउनलोड किया जा सके। हालांकि सैंटेंडर के उत्पादन वातावरण के आंतरिक नियंत्रण और शासन के कारण, इस तंत्र को उसी फ्लूम इंटरसेप्टर में शामिल किया जाना था जिसका उपयोग संवर्धन करने के लिए किया जाता है (यह प्रति घंटे एक बार अपडेट की जांच करता है, इसलिए यह एक महंगा ऑपरेशन नहीं है)। जब स्टोर का एक नया संस्करण उपलब्ध होता है, तो एचडीएफएस से नया स्टोर डाउनलोड करने और इसे रॉक्सडीबी में लोड करने के लिए वर्कर थ्रेड को एक कार्य भेजा जाता है। यह प्रक्रिया पृष्ठभूमि में होती है जबकि संवर्धन इंटरसेप्टर स्ट्रीम को संसाधित करना जारी रखता है। एक बार जब स्टोर का नया संस्करण RocksDB में लोड हो जाता है, तो इंटरसेप्टर नवीनतम संस्करण पर स्विच हो जाता है, और समाप्त हो चुके स्टोर को हटा दिया जाता है। इंटरसेप्टर द्वारा घटनाओं को समृद्ध करने का प्रयास शुरू करने से पहले कोल्ड स्टार्टअप से रॉक्सडीबी स्टोर्स को बूटस्ट्रैप करने के लिए उसी तंत्र का उपयोग किया जाता है।
सफलतापूर्वक समृद्ध संदेशों को काफ्का विषय पर लिखा जाता है ताकि HBaseEventSerializer का उपयोग करके HBase को निष्क्रिय रूप से लिखा जा सके।
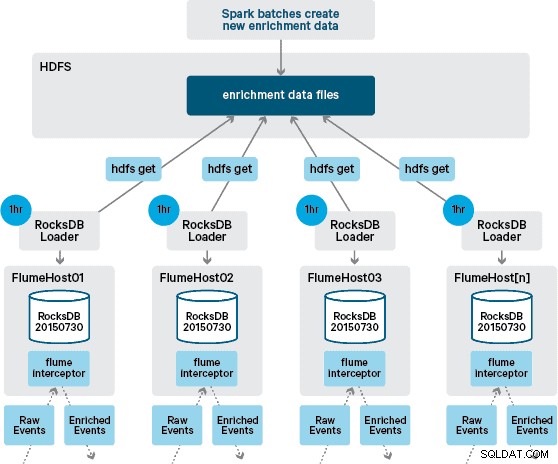
जबकि इवेंट स्ट्रीम को निरंतर आधार पर संसाधित किया जाता है, स्थानीय स्टोर के नए संस्करण केवल दैनिक रूप से उत्पन्न किए जा सकते हैं। फ्लूम द्वारा स्थानीय स्टोर के एक नए संस्करण को लोड करने के तुरंत बाद इसे ताजा माना जाता है," हालांकि यह एक नए संस्करण की उपलब्धता से पहले तेजी से पुराना हो जाता है। नतीजतन, स्थानीय स्टोर का एक नया संस्करण उपलब्ध होने तक "कैश मिस" की संख्या बढ़ जाती है। उदाहरण के लिए, नए और अपडेट किए गए ब्रांड और मर्चेंट जानकारी को संदर्भ डेटा में जोड़ा जा सकता है, लेकिन जब तक इसे फ्लूम के संवर्धन के लिए उपलब्ध नहीं कराया जाता है तब तक इंटरसेप्टर लेनदेन समृद्ध होने में विफल हो सकते हैं, या पुरानी जानकारी से समृद्ध हो सकते हैं जिसे बाद में होना चाहिए HBase में बने रहने के बाद सुलझाया गया।
इस मामले को संभालने के लिए, कैश मिस (ऐसी घटनाएँ जो समृद्ध होने में विफल रहती हैं) को फ़्लुम चयनकर्ता का उपयोग करके "फिर से करें" काफ्का विषय पर लिखा जाता है। नया स्थानीय स्टोर उपलब्ध होने पर फिर से करें विषय को फिर से संवर्धन इंटरसेप्टर के स्रोत विषय में फिर से चलाया जाता है।
"ज़हर संदेश" (ऐसी घटनाएँ जो लगातार संवर्धन को विफल करती हैं) को रोकने के लिए, हमने किसी ईवेंट के हेडर को फिर से करने के विषय में जोड़ने से पहले एक काउंटर जोड़ने का निर्णय लिया। उस विषय पर बार-बार आने वाली घटनाओं को अंततः एक "महत्वपूर्ण" विषय पर पुनर्निर्देशित किया जाता है, जिसे बाद में निरीक्षण और उपचार के लिए एचडीएफएस को लिखा जाता है। यह दृष्टिकोण पहले आरेख में दिखाया गया है।
निष्कर्ष
इस पोस्ट से मुख्य टेक-अवे बिंदुओं को सारांशित करने के लिए:
- अपने अंतर्ग्रहण पाइपलाइन के हिस्से के रूप में मध्यवर्ती साझा डेटा को संग्रहीत करने के लिए काफ्का विषयों की एक श्रृंखला का उपयोग करना एक प्रभावी पैटर्न है।
- आपके पास अपनी एनआरटी इंजेस्ट पाइपलाइन में स्थिति या संदर्भ डेटा को बनाए रखने और क्वेरी करने के लिए कई विकल्प हैं। इस उद्देश्य के लिए HBase को सामान्य पैटर्न के रूप में पसंद करें जब पूरक डेटा बड़ा हो, लेकिन HBase का उपयोग करते समय एम्बेडेड स्थानीय स्टोर (जैसे RocksDB) या JVM मेमोरी के उपयोग पर विचार करना व्यावहारिक नहीं है।
- विफलता से निपटना महत्वपूर्ण है। (उस पर सहायता के लिए #1 देखें।)
एक अनुवर्ती पोस्ट में, हम वर्णन करेंगे कि हम ऐतिहासिक खरीद प्रवृत्तियों के प्रति-ग्राहक एकत्रीकरण प्रदान करने के लिए HBase कोप्रोसेसरों का उपयोग कैसे करते हैं, और कैसे ऑफ़लाइन लेनदेन को बैच में संसाधित किया जाता है (क्लाउडेरा लैब्स प्रोजेक्ट) स्पार्कऑनएचबेस (जो हाल ही में प्रतिबद्ध था) HBase ट्रंक)। हम यह भी बताएंगे कि ग्राहक के क्रॉस-डेटासेंटर, उच्च-उपलब्धता आवश्यकताओं को पूरा करने के लिए समाधान को कैसे डिज़ाइन किया गया था।
जेम्स किनले, इयान बस और रॉब सिविकी क्लौडेरा में समाधान आर्किटेक्ट हैं।



