पीडीएफ छवियों को बड़े पैमाने पर संसाधित करने के लिए ओसीआर टूल, अपाचे स्पार्क, और अन्य अपाचे हडूप घटकों का उपयोग करना सीखें।
ऑप्टिकल कैरेक्टर रिकग्निशन (ओसीआर) प्रौद्योगिकियां पिछले 20 वर्षों में काफी उन्नत हुई हैं। हालांकि, उस समय के दौरान, लगभग वास्तविक समय में बड़ी संख्या में छवियों को संसाधित करने के लिए अपाचे हडूप जैसे वितरित आर्किटेक्चर के साथ ओसीआर से शादी करने के लिए बहुत कम या कोई प्रयास नहीं किया गया है।
इस पोस्ट में, आप सीखेंगे कि मानक ओपन सोर्स टूल्स के साथ-साथ अपाचे स्पार्क, अपाचे सोलर, और अपाचे एचबीएएस जैसे हडोप घटकों का उपयोग कैसे करें ताकि चिकित्सा उपकरण की जानकारी के उपयोग के मामले में ऐसा किया जा सके। विशेष रूप से, आप वर्णनात्मक टेक्स्ट को खोजने योग्य फ़ील्ड में बदलने के लिए एक सार्वजनिक डेटासेट का उपयोग करेंगे।
हालांकि यह उदाहरण चिकित्सा उपकरण की जानकारी पर केंद्रित है, इसे कई अन्य परिदृश्यों में लागू किया जा सकता है जहां प्रसंस्करण और स्थायी छवियों की आवश्यकता होती है। उदाहरण के लिए, बीमा कंपनियां अपने सभी स्कैन किए गए दस्तावेज़ों को बेहतर दावा समाधान के लिए दावा फ़ाइलों में खोज योग्य बना सकती हैं। इसी तरह, एक विनिर्माण सुविधा में आपूर्ति-श्रृंखला विभाग पुर्जों के आपूर्तिकर्ताओं से सभी तकनीकी डेटा शीट को स्कैन कर सकता है और उन्हें विश्लेषकों द्वारा खोजने योग्य बना सकता है।
यूज केस:मेडिकल डिवाइस रजिस्ट्रेशन
हाल के वर्षों में इलेक्ट्रॉनिक दवा उत्पाद पंजीकरण के क्षेत्र में बदलावों की झड़ी लग गई है। आईडीएमपी (चिकित्सा उत्पादों की पहचान) आईएसओ मानक उत्पादों और उनमें निहित पदार्थों को पंजीकृत करने के लिए एक ऐसा संदेश प्रारूप है, जिसमें औषधीय उत्पाद आईडी, पैकेजिंग आईडी और बैच आईडी का उपयोग प्रतिकूल अनुभवों के मामलों में उत्पादों को ट्रैक करने के लिए किया जाता है, अवैध आयात, जालसाजी, और फार्माकोविजिलेंस के अन्य मुद्दे। मानक कहता है कि न केवल नए उत्पादों को पंजीकृत करने की आवश्यकता है, बल्कि यह कि प्रत्येक उत्पाद की पुरानी/संग्रहीत फाइलिंग जिससे जनता को अवगत कराया जा सकता है, को भी इलेक्ट्रॉनिक रूप में प्रदान किया जाना चाहिए।
विभिन्न कंपनियों में आईडीएमपी मानकों का अनुपालन करने के लिए, कंपनियों को आरडीबीएमएस जैसे कई डेटा स्रोतों से डेटा खींचने और संसाधित करने में सक्षम होना चाहिए, साथ ही कुछ मामलों में, विरासत उत्पाद डेटा शीट। हालांकि यह सर्वविदित है कि Apache Sqoop जैसी तकनीकों के माध्यम से RDBMS से डेटा को कैसे अंतर्ग्रहण किया जाता है, विरासती दस्तावेज़ प्रसंस्करण के लिए थोड़ा और काम करने की आवश्यकता होती है। अधिकांश भाग के लिए, दस्तावेज़ों को अंतर्ग्रहण करने की आवश्यकता होती है, और प्रासंगिक पाठ को मौजूदा OCR तकनीकों का उपयोग करके प्रोग्राम के रूप में बड़े पैमाने पर निकालने की आवश्यकता होती है।
डेटासेट
हम एफडीए से एक डेटा सेट का उपयोग करेंगे जिसमें 1976 से अब तक चिकित्सा उपकरण निर्माताओं द्वारा जमा की गई सभी 510 (के) फाइलिंग शामिल हैं। खाद्य, औषधि और कॉस्मेटिक अधिनियम की धारा 510 (के) में डिवाइस निर्माताओं की आवश्यकता होती है, जिन्हें सूचित करने के लिए पंजीकरण करना होगा। एफडीए कम से कम 90 दिन पहले एक चिकित्सा उपकरण का विपणन करने का इरादा रखता है।
यह डेटासेट इस मामले में कई कारणों से उपयोगी है:
- डेटा मुफ़्त है और सार्वजनिक डोमेन में है।
- डेटा यूरोपीय विनियमन के साथ सही बैठता है, जो जुलाई 2016 में सक्रिय होता है (जहां निर्माताओं को नए डेटा मानकों का पालन करना चाहिए)। FDA फिलिंग्स में IDMP का संपूर्ण दृश्य प्राप्त करने के लिए प्रासंगिक महत्वपूर्ण जानकारी होती है।
- दस्तावेजों का प्रारूप (पीडीएफ) हमें कई प्रारूपों के दस्तावेजों के साथ काम करते समय सरल लेकिन प्रभावी ओसीआर तकनीकों का प्रदर्शन करने की अनुमति देता है।
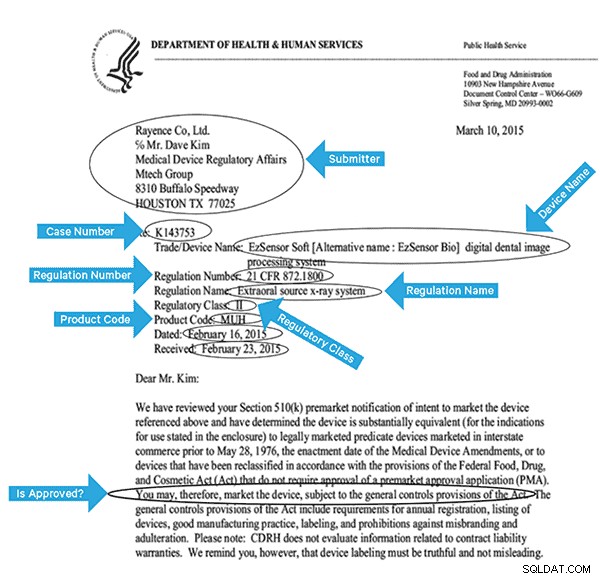
इस डेटा को प्रभावी ढंग से अनुक्रमित करने के लिए, हमें छवियों से कुछ फ़ील्ड निकालने होंगे। नीचे एक नमूना दस्तावेज़ है, जिसमें संभावित फ़ील्ड निकाले जा सकते हैं।
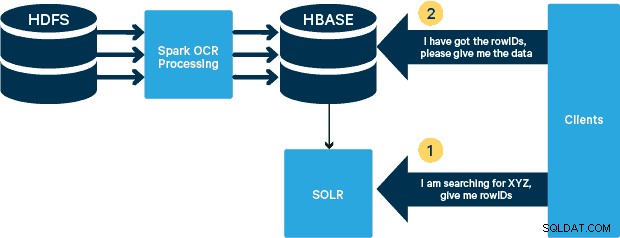
उच्च स्तरीय वास्तुकला
इस उपयोग के मामले में, पीडीएफ को एचडीएफएस में संग्रहीत किया जाता है और स्पार्क और ओसीआर पुस्तकालयों का उपयोग करके संसाधित किया जाता है। (अंतर्ग्रहण चरण इस पोस्ट के दायरे से बाहर है, लेकिन यह चलाने जितना आसान हो सकता है hdfs -dfs -put या एक webhdfs इंटरफ़ेस का उपयोग करना।) स्पार्क लगभग वास्तविक समय स्ट्रीमिंग के लिए स्पार्क स्ट्रीमिंग एप्लिकेशन में लगभग समान कोड के उपयोग की अनुमति देता है, और HBase कम-विलंबता रैंडम एक्सेस के लिए एक आदर्श भंडारण माध्यम है - और छवियों को संग्रहीत करने के लिए अच्छी तरह से अनुकूल है, बूट करने के लिए नई MOB कार्यक्षमता। क्लौडेरा सर्च (जो अपाचे सोलर के शीर्ष पर बनाया गया है) एकमात्र खोज समाधान है जो मूल रूप से HBase के साथ एकीकृत होता है, जिससे आप द्वितीयक अनुक्रमणिका बना सकते हैं।
HBase में मेडिकल डिवाइस टेबल सेट करना
हम अपने उपयोग के मामले के लिए स्कीमा को सीधा रखेंगे। RowID फ़ाइल नाम होगा, और दो कॉलम परिवार होंगे:"जानकारी" और "obj"। "जानकारी" कॉलम परिवार में वे सभी फ़ील्ड होंगे जो हमने छवियों से निकाले हैं। "ओबीजे" कॉलम परिवार वास्तविक बाइनरी ऑब्जेक्ट के बाइट रखेगा, इस मामले में पीडीएफ। हमारे मामले में तालिका का नाम "mdds" होगा।
हम HBASE-11339 में शुरू की गई HBase MOB (मीडियम ऑब्जेक्ट) कार्यक्षमता का लाभ उठाएंगे। भीड़ को संभालने के लिए HBase को स्थापित करने के लिए, कुछ अतिरिक्त चरणों की आवश्यकता होती है, लेकिन, आसानी से, निर्देश इस लिंक पर पाए जा सकते हैं।
HBase में प्रोग्रामेटिक रूप से तालिका बनाने के कई तरीके हैं (जावा एपीआई, आरईएसटी एपीआई, या इसी तरह की विधि)। यहां हम "mdds" तालिका बनाने के लिए HBase शेल का उपयोग करेंगे (जानबूझकर वर्णनात्मक कॉलम परिवार नाम का उपयोग करके चीजों का पालन करना आसान बना सकते हैं)। हम चाहते हैं कि "जानकारी" कॉलम परिवार सोलर को दोहराया जाए, लेकिन एमओबी डेटा नहीं।
नीचे दिया गया आदेश तालिका बनाएगा और "जानकारी" नामक कॉलम परिवार पर प्रतिकृति सक्षम करेगा। विकल्प निर्दिष्ट करना महत्वपूर्ण है REPLICATION_SCOPE => '1' , अन्यथा HBase लिली इंडेक्सर को HBase से कोई अपडेट नहीं मिलेगा। हम 10MB से बड़ी वस्तुओं के लिए HBase में MOB पथ का उपयोग करना चाहते हैं। इसे पूरा करने के लिए हम MOB के लिए निम्नलिखित मापदंडों का उपयोग करके "obj" नामक एक और कॉलम परिवार भी बनाते हैं:
IS_MOB => सच, MOB_THRESHOLD => 10240000
आईएस_एमओबी पैरामीटर निर्दिष्ट करता है कि क्या यह कॉलम परिवार MOB को स्टोर कर सकता है, जबकि MOB_THRESHOLD निर्दिष्ट करता है कि वस्तु को MOB मानने के लिए कितना बड़ा होना चाहिए। तो चलिए टेबल बनाते हैं:
'mdds' बनाएं, {NAME => 'जानकारी', DATA_BLOCK_ENCODING => 'FAST_DIFF',REPLICATION_SCOPE => '1'},{NAME => 'obj', IS_MOB => true, MOB_THRESHOLD => 10240000} यह पुष्टि करने के लिए कि तालिका ठीक से बनाई गई थी, HBase शेल में निम्न कमांड चलाएँ:
hbase(main):001:0> 'mdds' का वर्णन करें तालिका mdds को सक्षम किया गया हैmddsCOLUMN FAMILIES DESCRIPTION{NAME => 'जानकारी', DATA_BLOCK_ENCODING => 'FAST_DIFF', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '1' , VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}{NAME => 'obj', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', COMPRESSION => 'NONE', VERSIONS => '1', MIN_VERSIONS => '0', TTL => 'FOREVER', MOB_THRESHOLD => '10240000', IS_MOB => 'true', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}2 पंक्ति (पंक्तियाँ) 0.3440 सेकंड में टेसरैक्ट के साथ स्कैन की गई छवियों को संसाधित करना
फ़ॉन्ट विविधताओं, छवि शोर और संरेखण मुद्दों से निपटने के मामले में ओसीआर ने एक लंबा सफर तय किया है। यहां हम ओपन सोर्स OCR इंजन Tesseract का उपयोग करेंगे, जिसे मूल रूप से HP लैब में मालिकाना सॉफ्टवेयर के रूप में विकसित किया गया था। Tesseract विकास तब से एक ओपन सोर्स सॉफ़्टवेयर के रूप में जारी किया गया है और 2006 से Google द्वारा प्रायोजित किया गया है।
Tesseract एक अत्यधिक पोर्टेबल सॉफ्टवेयर लाइब्रेरी है। यह ग्रे या रंगीन छवि पर अनुकूली थ्रेशोल्डिंग करके बाइनरी इमेज जेनरेट करने के लिए लेप्टोनिका इमेज-प्रोसेसिंग लाइब्रेरी का उपयोग करता है।
प्रसंस्करण एक पारंपरिक चरण-दर-चरण पाइपलाइन का अनुसरण करता है। निम्नलिखित चरणों का मोटा प्रवाह है:
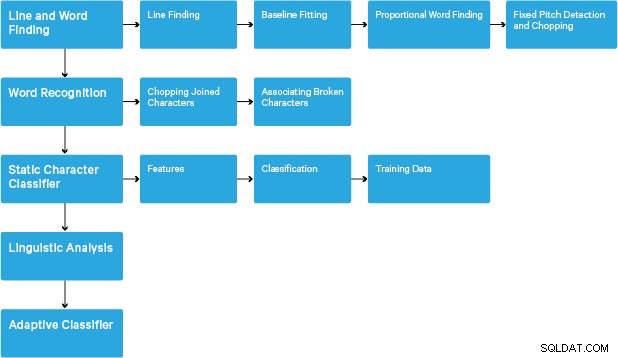
प्रसंस्करण एक जुड़े घटक विश्लेषण के साथ शुरू होता है, जिसके परिणामस्वरूप पाए गए घटकों को संग्रहीत किया जाता है। यह कदम रूपरेखा के घोंसले के निरीक्षण में मदद करता है, और बच्चे और पोते की रूपरेखा की संख्या।
इस स्तर पर, रूपरेखा एक साथ, विशुद्ध रूप से नेस्टिंग द्वारा, बाइनरी लार्ज ऑब्जेक्ट्स (बीएलओबी) में एकत्रित की जाती है। BLOB को टेक्स्ट लाइनों में व्यवस्थित किया जाता है, और निश्चित पिच या आनुपातिक टेक्स्ट के लिए लाइनों और क्षेत्रों का विश्लेषण किया जाता है। टेक्स्ट लाइन्स को कैरेक्टर स्पेसिंग के अनुसार अलग-अलग शब्दों में तोड़ा जाता है। निश्चित पिच टेक्स्ट को कैरेक्टर सेल द्वारा तुरंत काट दिया जाता है। आनुपातिक पाठ को निश्चित रिक्त स्थान और अस्पष्ट रिक्त स्थान का उपयोग करके शब्दों में तोड़ा जाता है।
मान्यता तब दो-पास प्रक्रिया के रूप में आगे बढ़ती है। पहले पास में प्रत्येक शब्द को बारी-बारी से पहचानने का प्रयास किया जाता है। प्रत्येक शब्द जो संतोषजनक है उसे प्रशिक्षण डेटा के रूप में एक अनुकूली क्लासिफायरियर को पास किया जाता है। तब अनुकूली क्लासिफायर को पृष्ठ के निचले हिस्से में पाठ को अधिक सटीक रूप से पहचानने का मौका मिलता है। चूंकि अनुकूली क्लासिफायरियर ने पृष्ठ के शीर्ष के पास योगदान करने के लिए बहुत देर से उपयोगी कुछ सीखा है, पृष्ठ पर एक दूसरा पास चलाया जाता है, जिसमें शब्दों को पर्याप्त रूप से पहचाना नहीं गया था, फिर से पहचाने जाते हैं। एक अंतिम चरण अस्पष्ट रिक्त स्थान को हल करता है, और स्मॉल-कैप टेक्स्ट का पता लगाने के लिए x-ऊंचाई के लिए वैकल्पिक परिकल्पनाओं की जांच करता है।
Tesseract अपने वर्तमान स्वरूप में पूरी तरह से यूनिकोड सक्षम है और कई भाषाओं के लिए प्रशिक्षित है। हमारे शोध के आधार पर, यह ओसीआर के लिए उपलब्ध सबसे सटीक ओपन सोर्स लाइब्रेरी में से एक है। जैसा कि पहले उल्लेख किया गया है, Tesseract Leptonica का उपयोग करता है। हम पीडीएफ फाइलों को छवियों में विभाजित करने के लिए घोस्टस्क्रिप्ट का भी उपयोग करते हैं। (आप अपनी पसंद के छवि संपीड़न प्रारूप में विभाजित कर सकते हैं; हमने पीएनजी चुना है।) ये तीन पुस्तकालय सी ++ में लिखे गए हैं, और उन्हें जावा/स्कैला प्रोग्राम से लागू करने के लिए, हमें संबंधित जावा नेटिव इंटरफेस के कार्यान्वयन का उपयोग करने की आवश्यकता है। हमारे काम में, हम JavaPresets से JNI बाइंडिंग का उपयोग करते हैं। (बिल्ड निर्देश नीचे पाए जा सकते हैं।) हमने स्पार्क ड्राइवर को लिखने के लिए स्काला का इस्तेमाल किया।
वैल रेंडरर :SimpleRenderer =नया SimpleRenderer( )renderer.setResolution(300)val images:List[Image] =renderer.render(document)
लेप्टोनिका पिछले चरण से विभाजित छवियों में पढ़ता है।
ImageIO.write(x.asInstanceOf[RenderedImage], "png", imageByteStream)वैल पिक्स:PIX =pixReadMem (ByteBuffer.wrap(imageByteStream.toByteArray( ))। array( ), ByteBuffer.wrap (imageByteStream.toByteArray( ) ).क्षमता ( ))
फिर हम टेक्स्ट निकालने के लिए Tesseract API कॉल का उपयोग करते हैं। हम मानते हैं कि दस्तावेज़ यहाँ अंग्रेज़ी में हैं, इसलिए Init पद्धति का दूसरा पैरामीटर "eng" है।
वैल एपीआई:TessBaseAPI =नया TessBaseAPI () api.Init (नल, "eng") api.SetImage (पिक्स) api.GetUTF8Text ()। getString ()
छवियों के संसाधित होने के बाद, हम टेक्स्ट से कुछ फ़ील्ड निकालते हैं और उन्हें HBase पर भेजते हैं।
def populateHbase ( fileName:String, लाइन्स:String, pdf:org.apache.spark.input.PortableDataStream) :Unit ={ /** एक HBase कनेक्शन को कॉन्फ़िगर और खोलें */ val mddsTbl =_conn.getTable( TableName. वैल्यूऑफ ("एमडीडीएस")); वैल सीएफ ="जानकारी" वैल पुट =नया पुट (बाइट्स। टूबाइट्स (फाइलनाम)) / ** * रेगेक्स का उपयोग करके यहां फ़ील्ड निकालें * ऑब्जेक्ट बनाएं और एचबीएएस */वैल ए एंडसीपी =""" (? एस) (? एम).*\d\d\d\d\d-\d\d\d\d(.*)\nRe:(\w\d\d\d\d\d\d).*"" ".r …… .. लाइन मैच {केस aAndCP(addr, Casenum) => put.add(Bytes.toBytes(cf),Bytes.toBytes("submitter_info"), Bytes.toBytes(addr) ).add(बाइट्स) .toBytes(cf),Bytes.toBytes("case_num"), Bytes.toBytes( Casenum )) case _ => println ("रेगेक्स से मेल नहीं खाता")} ……. line.split("\n").foreach { val regNumRegex ="""विनियमन संख्या:\s+(.+)""".r val regNameRegex ="""विनियमन नाम:\s+(.+)""" ।आर …….. ……। _ मैच {केस regNumRegex(regNum) => put.add(बाइट्स.toBytes(cf),Bytes.toBytes("reg_num"), …….….. case _ => प्रिंट( "" ) }} put.add ( Bytes.toBytes(cf), Bytes.toBytes("text"), Bytes.toBytes(lines)) वैल pdfBytes =pdf.toArray.clone put.add(Bytes.toBytes("obj"), Bytes.toBytes( " pdf"), pdfBytes) mddsTbl.put (पुट) …….} यदि आप ऊपर दिए गए कोड को बारीकी से देखते हैं, तो हम पुट ऑब्जेक्ट को HBase पर भेजने से ठीक पहले, हम टेबल के "obj" कॉलम परिवार में कच्चे पीडीएफ बाइट्स डालते हैं। हम निकाले गए क्षेत्रों के साथ-साथ कच्ची छवि के लिए भंडारण परत के रूप में HBase का उपयोग करते हैं। यह एप्लिकेशन के लिए मूल छवि को निकालने के लिए तेज़ और सुविधाजनक बनाता है, यदि आवश्यक हो। पूरा कोड यहां पाया जा सकता है। (यह ध्यान देने योग्य है कि जब हमने वास्तविक उत्पादन प्रणाली में HBase के लिए पुट ऑब्जेक्ट बनाने के लिए मानक HBase API का उपयोग किया, तो SparkOnHBase API का उपयोग करने पर विचार करना बुद्धिमानी होगी, जो स्पार्क RDD से HBase को बैच अपडेट की अनुमति देता है।)
निष्पादन पाइपलाइन
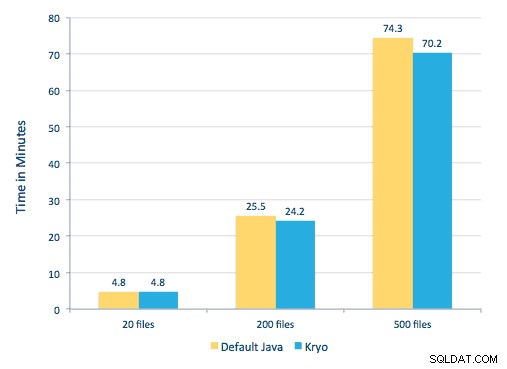
हम प्रत्येक पीडीएफ को एक धारावाहिक ढांचे में संसाधित करने में सक्षम थे। प्रसंस्करण को बढ़ाने के लिए, हमने स्पार्क का उपयोग करके इन पीडीएफ को वितरित तरीके से संसाधित करना चुना। निम्न चार्ट दर्शाता है कि कैसे हम स्पार्क से वर्कफ़्लो को एक साधारण मैक्रो कॉल में बदलने और डेटा को HBase में लोड करने के लिए इस प्रसंस्करण के विभिन्न चरणों को जोड़ते हैं।
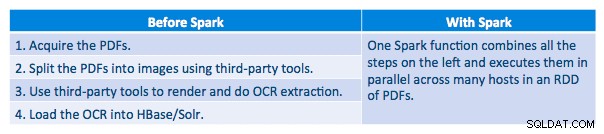
हमने क्रमांकन विधियों के बीच तुलना करने की भी कोशिश की, लेकिन, हमारे डेटासेट के साथ, हमें प्रदर्शन में कोई महत्वपूर्ण अंतर नहीं दिखाई दिया।
पर्यावरण सेटअप
प्रयुक्त हार्डवेयर:15GB मेमोरी, 4 vCPU और 2x40GB SSD के साथ पांच-नोड क्लस्टर
चूंकि हम प्रसंस्करण के लिए सी ++ पुस्तकालयों का उपयोग कर रहे थे, हमने जेएनआई बाइंडिंग का इस्तेमाल किया जो यहां पाया जा सकता है।
JavaCPP प्रीसेट से Tesseract और Leptonica के लिए JNI बाइंडिंग बनाएँ:
-
- सभी नोड्स पर:
yum -y automake autoconf libtool zlib-devel इंस्टॉल करें libjpeg-devel giflib libtiff-devel libwebp libwebp-devel libicu-devel openjpeg-devel cairo-devel गिट क्लोन https://github.com/bytedeco/javacpp-presets.gitcd javacpp-presets- लेप्टोनिका का निर्माण करें। sudo make installcd ../../../mvn clean installcd ..
- टेसेरैक्ट बनाएं।
- सभी नोड्स पर:
cd tesseract./cppbuild.sh इंस्टाल tesseractcd tesseract/cppbuild/linux-x86_64/tesseract-3.03LDFLAGS="-Wl,-rpath -Wl,/usr/local/lib" ./configuremake &&make installcd ../ ../../एमवीएन क्लीन इंस्टालसीडी ..
- javaCPP प्रीसेट बनाएं।
mvn clean install --projects leptonica,tesseract
हम पीडीएफ से छवियों को निकालने के लिए घोस्टस्क्रिप्ट का उपयोग करते हैं। यहां इस्तेमाल किए गए टेसेरैक्ट और लेप्टोनिका के संस्करणों के अनुरूप घोस्टस्क्रिप्ट बनाने के निर्देश इस प्रकार हैं। (सुनिश्चित करें कि पैकेज मैनेजर के माध्यम से सिस्टम में घोस्टस्क्रिप्ट स्थापित नहीं है।)
wget https://downloads.ghostscript.com/public/ghostscript-9.16.tar.gztar zxvf Ghostscript-9.16.tar.gzcd Ghostscript-9.16./autogen.sh &&./configure --prefix=/usr - -अक्षम-संकलन-इनिट्स --enable-dynamicsudo make &&make soinstall &&install -v -m644 base/*.h /usr/include/ghostscript &&ln -v -s Ghostscript /usr/include/ps(आपके ldpath पर निर्भर करता है) सेटिंग, आपको करना पड़ सकता है):sudo ln -sf /usr/lib/libgs.so /usr/local/lib/libgs.so
सुनिश्चित करें कि सभी आवश्यक पुस्तकालय क्लासपाथ में हैं। हम सभी प्रासंगिक जार को एक निर्देशिका में डालते हैं जिसे lib कहा जाता है। अल्पविराम नीचे महत्वपूर्ण है:
$ i के लिए `ls lib/*` में; MY_JARS=./$i,$MY_JARS निर्यात करें; didtesseract.jar, tesseract-linux-x86_64.jar, javacpp.jar, Ghost4j-1.0.0.jar, leptonica.jar, leptonica-1.72-1.0.jar, leptonica-linux-x86_64.jar
हम निम्नानुसार स्पार्क कार्यक्रम को लागू करते हैं। हमें देशी घोस्टस्क्रिप्ट पुस्तकालयों के लिए अतिरिक्त लाइब्रेरीपाथ निर्दिष्ट करने की आवश्यकता है; Tesseract के लिए दूसरे कॉन्फिडेंस की जरूरत है।
स्पार्क-सबमिट --जार $MY_JARS --num-executors 12 --executor-memory 4G --executor-cores 1 --conf Spark.executor.extraLibraryPath=/usr/local/lib --confspark.executorEnv. TESSDATA_PREFIX=/home/vsingh/javacpp-presets/tesseract/cppbuild/1-x86_64/share/tessdata/ --confspark.executor.extraClassPath=/etc/hbase/conf:/opt/cloudera/parcels/CDH/lib/hbase /lib/htrace-core-3.1.0-incubating.jar --driver-class-path/etc/hbase/conf:/opt/cloudera/parcels/CDH/lib/hbase/lib/htrace-core-3.1.0 -incubating.jar --conf Spark.serializer=org.apache.spark.serializer.KryoSerializer--conf Spark.kryoserializer.buffer.mb=24 --class com.cloudera.sa.OCR.IdmpExtraction
सौर संग्रह बनाना
सोलर लिली HBase इंडेक्सर के माध्यम से HBase के साथ काफी सहजता से एकीकृत करता है। यह समझने के लिए कि HBase के साथ लिली इंडेक्सर एकीकरण कैसे किया जाता है, आप "HBase प्रतिकृति और लिली HBase अनुक्रमणिका को समझना" अनुभाग में हमारी पिछली पोस्ट के माध्यम से ब्रश कर सकते हैं।
नीचे हम उन चरणों की रूपरेखा तैयार करते हैं जिन्हें अनुक्रमणिका बनाने के लिए निष्पादित करने की आवश्यकता है:
- एक नमूना schema.xml कॉन्फ़िगरेशन फ़ाइल जेनरेट करें:
solrctl --zk localhost:2181 instancedir --generate $HOME/solrcfg - schema.xml फ़ाइल को
$HOME/solrcfgमें संपादित करें , हमारे संग्रह के लिए आवश्यक फ़ील्ड निर्दिष्ट करना। पूरी फाइल यहां मिल सकती है। - ज़ूकीपर पर सोलर कॉन्फ़िगरेशन अपलोड करें:
solrctl --zk localhost:2181/solr instancedir --create mdds_collection $HOME/solrcfg - 2 शार्प (-s 2) और 2 रेप्लिका (-r 2) के साथ सोलर कलेक्शन जेनरेट करें:एस 2-आर 2
ऊपर दिए गए कमांड में हमने दो शार्क (-s 2) और दो प्रतिकृति (-r 2) मापदंडों के साथ एक सोलर संग्रह बनाया। मानदंड हमारे कोष के लिए पर्याप्त थे, लेकिन वास्तविक परिनियोजन में किसी को हमारे यहां चर्चा के दायरे से बाहर अन्य विचारों के आधार पर संख्या निर्धारित करनी होगी।
इंडेक्सर को पंजीकृत करना
अनुक्रमणिका और HBase प्रतिकृति को जोड़ने और कॉन्फ़िगर करने के लिए इस चरण की आवश्यकता है। नीचे दिया गया कमांड ज़ूकीपर को अपडेट करेगा और mdds_indexer को HBase के लिए प्रतिकृति पीयर के रूप में जोड़ेगा। यह ज़ूकीपर में कॉन्फ़िगरेशन भी सम्मिलित करेगा, जिसका उपयोग लिली एचबेस इंडेक्सर सोलर में सही संग्रह को इंगित करने के लिए करेगा। |
hbase-indexer ऐड-इंडेक्सर -n mdds_indexer -c indexer-config.xml -cp solr.zk=localhost:2181/solr -cp solr.collection=mdds_collection।
तर्क:
-n mdds_indexer- इंडेक्सर का नाम निर्दिष्ट करता है जो चिड़ियाघरकीपर में पंजीकृत होगा-c indexer-config.xml- कॉन्फ़िगरेशन फ़ाइल जो अनुक्रमणिका व्यवहार निर्दिष्ट करेगी-cp solr.zk=localhost:2181/solr- ज़ूकीपर और सोलर कॉन्फ़िगरेशन का स्थान निर्दिष्ट करता है। इसे ज़ूकीपर के पर्यावरण विशिष्ट स्थान के साथ अद्यतन किया जाना चाहिए।-cp solr.collection=mdds_collection- निर्दिष्ट करता है कि किस संग्रह को अद्यतन करना है। सोलर कॉन्फ़िगरेशन चरण को याद करें जहां हमने संग्रह1 बनाया था।
index-config.xml इस मामले में फ़ाइल अपेक्षाकृत सीधी है; यह केवल इंडेक्सर को निर्दिष्ट करता है कि किस तालिका को देखना है, वह वर्ग जिसे मैपर के रूप में उपयोग किया जाएगा (com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper ), और मॉर्फलाइन कॉन्फ़िगरेशन फ़ाइल का स्थान। डिफ़ॉल्ट रूप से, मैपिंग-प्रकार पंक्ति . पर सेट होता है , जिस स्थिति में सोलर दस्तावेज़ पूरी पंक्ति बन जाता है। परम नाम ="मॉर्फ़लाइनफ़ाइल" मॉर्फलाइन्स कॉन्फ़िगरेशन फ़ाइल का स्थान निर्दिष्ट करता है। स्थान आपकी Morphlines फ़ाइल का एक संपूर्ण पथ हो सकता है, लेकिन चूंकि आप Cloudera प्रबंधक का उपयोग कर रहे हैं, इसलिए सापेक्ष पथ को morphlines.conf के रूप में निर्दिष्ट करें।
hbase-indexer कॉन्फ़िगरेशन फ़ाइल की सामग्री यहां पाई जा सकती है।
लिली HBase अनुक्रमणिका को कॉन्फ़िगर करना और प्रारंभ करना
जब आप लिली एचबेस इंडेक्सर को सक्षम करते हैं, तो आपको मॉर्फलाइन्स ट्रांसफॉर्मेशन लॉजिक निर्दिष्ट करने की आवश्यकता होती है जो इस इंडेक्सर को मेडिकल डिवाइस टेबल में अपडेट को पार्स करने और सभी प्रासंगिक फ़ील्ड निकालने की अनुमति देगा। सर्विसेज पर जाएं और लिली एचबेस इंडेक्सर चुनें जिसे आपने पहले जोड़ा था। कॉन्फ़िगरेशन->देखें और संपादित करें->सर्विस-वाइड->मॉर्फ़लाइन . चुनें . मॉर्फलाइन्स फ़ाइल को कॉपी और पेस्ट करें।
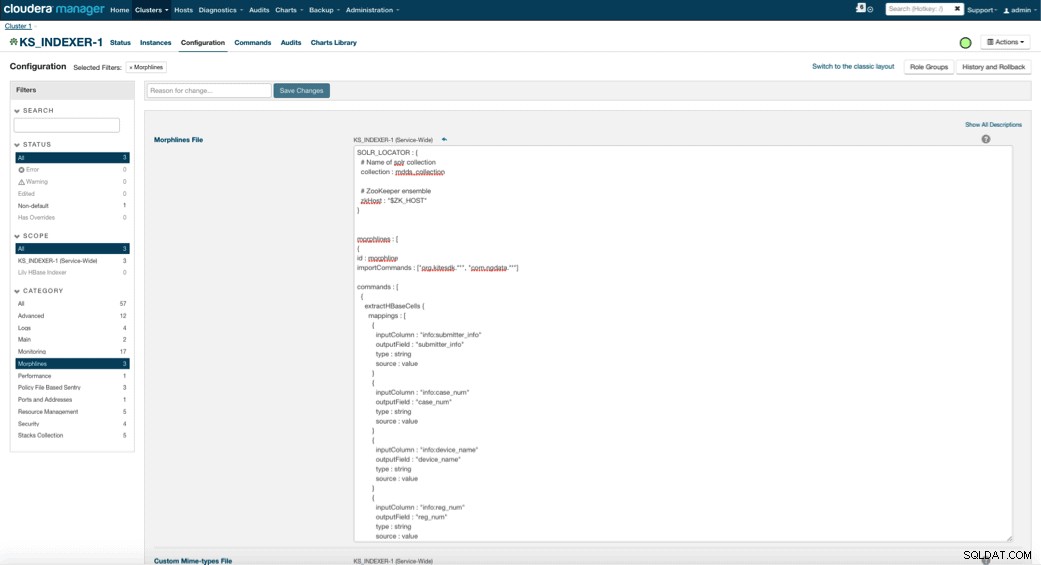
चिकित्सा उपकरण मॉर्फलाइन पुस्तकालय निम्नलिखित कार्य करेगा:
- HBase ईमेल ईवेंट को
extractHBaseCellsके साथ पढ़ें आदेश - दिनांक/टाइमस्टैम्प को
कन्वर्टटाइमस्टैम्पके साथ उस फ़ील्ड में बदलें जिसे सोलर समझेगा आदेश - उन सभी अतिरिक्त फ़ील्ड को छोड़ दें जिन्हें हमने schema.xml में निर्दिष्ट नहीं किया था,
sanitizeUknownSolrFieldsके साथ आदेश
इस मॉर्फलाइन्स फ़ाइल की एक प्रति यहाँ से डाउनलोड करें।
एक महत्वपूर्ण नोट यह है कि आईडी फ़ील्ड स्वचालित रूप से लिली एचबेस इंडेक्सर द्वारा जेनरेट की जाएगी। अद्वितीय-कुंजी-फ़ील्ड विशेषता निर्दिष्ट करके उपरोक्त अनुक्रमणिका-config.xml फ़ाइल में वह सेटिंग कॉन्फ़िगर करने योग्य है। आईडी के डिफ़ॉल्ट नाम को छोड़ना सबसे अच्छा अभ्यास है - क्योंकि यह उपरोक्त xml फ़ाइल में निर्दिष्ट नहीं था, डिफ़ॉल्ट आईडी फ़ील्ड उत्पन्न हुआ था और यह RowID का संयोजन होगा।
डेटा एक्सेस करना
अनुक्रमित छवियों तक पहुँचने के लिए आपके पास कई विज़ुअल टूल का विकल्प है। HUE और Solr GUI दोनों ही बहुत अच्छे विकल्प हैं। HBase न केवल GUI से बल्कि HBase शेल, API और यहां तक कि सरल स्क्रिप्टिंग तकनीकों के माध्यम से भी कई एक्सेस तकनीकों को सक्षम बनाता है।
सोलर के साथ एकीकरण आपको बहुत लचीलापन देता है और आपके डेटा के लिए बहुत ही सरल और साथ ही उन्नत खोज विकल्प भी प्रदान कर सकता है। उदाहरण के लिए, सोलर स्कीमा.एक्सएमएल फ़ाइल को इस तरह कॉन्फ़िगर करना कि ईमेल ऑब्जेक्ट के भीतर सभी फ़ील्ड सोलर में संग्रहीत हों, उपयोगकर्ताओं को स्टोरेज स्पेस के ट्रेड-ऑफ और जटिलता की गणना के साथ एक साधारण खोज के माध्यम से पूर्ण संदेश निकायों तक पहुंचने की अनुमति देता है। वैकल्पिक रूप से, आप सोलर को केवल सीमित संख्या में फ़ील्ड, जैसे कि आईडी, को स्टोर करने के लिए कॉन्फ़िगर कर सकते हैं। इन तत्वों के साथ, उपयोगकर्ता जल्दी से सोलर को खोज सकते हैं और पंक्ति आईडी को पुनः प्राप्त कर सकते हैं जिसका उपयोग एचबीएएस से अलग-अलग फ़ील्ड या पूरी छवि को पुनः प्राप्त करने के लिए किया जा सकता है।
उपरोक्त उदाहरण सोलर में केवल पंक्ति आईडी संग्रहीत करता है लेकिन छवि से निकाले गए सभी क्षेत्रों पर अनुक्रमणिका। इस परिदृश्य में सोलर की खोज करने से HBase पंक्ति आईडी प्राप्त होती है, जिसका उपयोग आप HBase को क्वेरी करने के लिए कर सकते हैं। इस प्रकार का सेटअप सोलर के लिए आदर्श है क्योंकि यह स्टोरेज की लागत कम रखता है और सोलर की इंडेक्सिंग क्षमताओं का पूरा फायदा उठाता है।
नमूना प्रश्न
नीचे कुछ उदाहरण प्रश्न दिए गए हैं जो एप्लिकेशन से सोलर में किए जा सकते हैं। विचार यह है कि क्लाइंट प्रारंभ में सोलर इंडेक्स से पूछताछ करेगा, एचबीएएस से पंक्ति आईडी लौटाएगा। फिर शेष फ़ील्ड और/या मूल कच्ची छवि के लिए HBase को क्वेरी करें।
- मुझे वे सभी दस्तावेज़ दें जो निम्नलिखित तिथियों के बीच दायर किए गए थे:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=received:[2010-01 -06T23:59:59.999Z से 2010-02-06T23:59:59.999Z]
- मुझे ऐसे दस्तावेज़ दें जिन्हें मोबाइल एक्स-रे सिस्टम नियामक नाम के तहत दायर किया गया था:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=reg_name:Mobile एक्स-रे प्रणाली
- मुझे चीनी निर्माताओं से दायर किए गए सभी दस्तावेज़ दें:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=submitter_info:*China*
पूर्व>सोलर दस्तावेज़ों की आईडी HBase में पंक्ति आईडी हैं; क्वेरी का दूसरा भाग डेटा निकालने के लिए HBase को होगा (यदि आवश्यक हो तो कच्चे पीडीएफ सहित)।
HUE के माध्यम से पहुंच
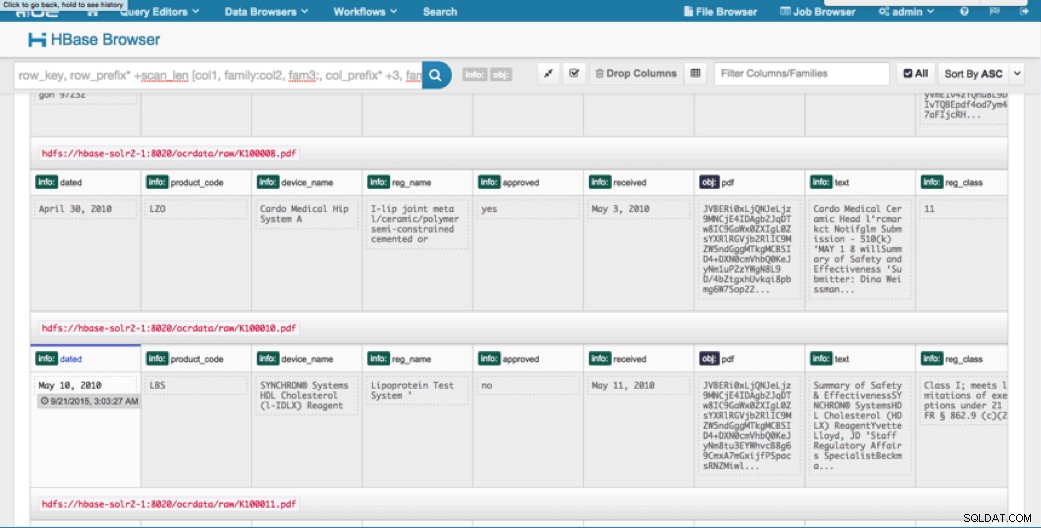
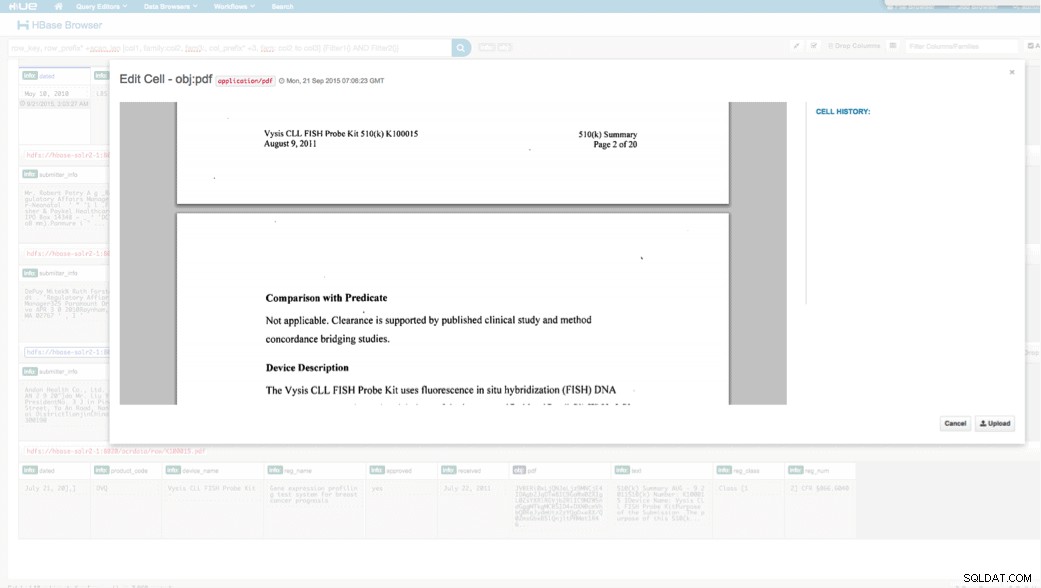
हम अपलोड किए गए डेटा को एचबीएएस ब्राउज़र के माध्यम से एचयूई में देख सकते हैं। HUE के बारे में एक बड़ी बात यह है कि यह PDF के लिए बायनेरिज़ का पता लगा सकता है और क्लिक करने पर उन्हें रेंडर कर सकता है।
नीचे HBase पंक्तियों में पार्स किए गए फ़ील्ड के दृश्य का एक स्नैपशॉट है और साथ ही obj स्तंभ परिवार में एक MOB के रूप में संग्रहीत PDF ऑब्जेक्ट में से एक का रेंडर दृश्य है।
निष्कर्ष
इस पोस्ट में, हमने प्रदर्शित किया है कि स्केलेबल स्पार्क प्रोग्राम का उपयोग करके स्कैन किए गए दस्तावेज़ों पर OCR करने के लिए मानक ओपन सोर्स तकनीकों का उपयोग कैसे करें, तेजी से पुनर्प्राप्ति के लिए HBase में संग्रहीत करें, और सोलर में निकाली गई जानकारी को अनुक्रमित करें। यह स्पष्ट होना चाहिए कि:
- संदेश विनिर्देश प्रारूप को देखते हुए, हम फ़ील्ड और मूल्य जोड़े निकाल सकते हैं और उन्हें सोलर के माध्यम से खोजने योग्य बना सकते हैं।
- डेटा से ये फ़ील्ड लीगेसी डेटा को इलेक्ट्रॉनिक बनाने की IDMP आवश्यकताओं को पूरा कर सकते हैं, जो अगले साल किसी समय प्रभावी हो जाएगा।
- फ़ील्ड के साथ-साथ कच्ची छवियों को HBase में बनाए रखा जा सकता है और मानक API के माध्यम से पहुँचा जा सकता है।
यदि आप अपने आप को स्कैन किए गए दस्तावेज़ों को संसाधित करने और अपने उद्यम में विभिन्न अन्य स्रोतों के साथ डेटा के संयोजन की आवश्यकता पाते हैं, तो स्पार्क, HBase, सोलर के संयोजन के साथ-साथ Tesseract और Leptonica का उपयोग करने पर विचार करें। यह आपका काफी समय और पैसा बचा सकता है!
Jeff Shmain Cloudera में एक वरिष्ठ समाधान वास्तुकार हैं। उनके पास सुरक्षा व्यापार, जोखिम और विनियमों की मजबूत समझ के साथ वित्तीय उद्योग का 16+ वर्षों का अनुभव है। पिछले कुछ वर्षों में, उन्होंने दुनिया के 10 सबसे बड़े निवेश बैंकों में से 8 में विभिन्न उपयोग के मामलों के कार्यान्वयन पर काम किया है।
वर्तिका सिंह क्लौडेरा में एक वरिष्ठ समाधान सलाहकार हैं। उसे एप्लाइड मशीन लर्निंग और सॉफ्टवेयर डेवलपमेंट में 12 साल से अधिक का अनुभव है।



