परिचय:यह उदाहरण एक पुरानी विधि को दर्शाता है फ्लैट फाइलों का उपयोग करके परीक्षण या सिस्टम क्षमता के लिए बड़े या जटिल संग्रह प्रोटोटाइप उत्पन्न और पॉप्युलेट करने के लिए आईआरआई रोजेन का उपयोग करना। जैसा कि आप पढ़ेंगे, RowGen आवश्यक परीक्षण डेटा बनाएगा और एक CSV फ़ाइल बनाएगा जिसे Mongo आयात उपयोगिता का उपयोग करके MongoDB में लोड किया जाएगा।
2019 अपडेट:आईआरआई अब भी ऑफर करता है JSON और प्रत्यक्ष ड्राइवर समर्थन MongoDB संग्रह और SortCL- संगत IRI सॉफ़्टवेयर उत्पादों जैसे RowGen या FieldShield के बीच डेटा स्थानांतरित करने के लिए। इसका मतलब है कि आप MongoDB में आयात करने के लिए परीक्षण JSON फ़ाइलों को उत्पन्न करने के लिए RowGen का उपयोग कर सकते हैं (इस आलेख में नीचे दिखाए गए तरीके के विपरीत नहीं), या परीक्षण लक्ष्यों में Mongo तालिकाओं में डेटा को मास्क करने के लिए FieldShield का उपयोग करें।
ध्यान दें कि FieldShield और RowGen दोनों IRI Voracity डेटा प्रबंधन प्लेटफ़ॉर्म में शामिल हैं, जो परीक्षण डेटा बनाने के चार तरीके प्रदान करता है।
हालांकि MongoDB एक बढ़िया क्रॉस-प्लेटफ़ॉर्म, दस्तावेज़-उन्मुख NoSQL डेटाबेस है, लेकिन इसके पास बड़े या जटिल संग्रह प्रोटोटाइप बनाने और पॉप्युलेट करने का कोई सुविधाजनक तरीका नहीं है जिसका उपयोग प्रश्नों या योजना क्षमता का परीक्षण करने के लिए किया जा सकता है। यह लेख बताता है कि परीक्षण डेटा कैसे बनाया जाए MongoDB IRI RowGen के माध्यम से उपयोग कर सकता है, एक सिंथेटिक, लेकिन यथार्थवादी, CSV फ़ाइल के लिए पैरामीटर निर्दिष्ट करता है जिसे MongoDB कार्यात्मक और प्रदर्शन परीक्षण के लिए आयात कर सकता है।
आपको पहले अपने संग्रह (MongoDB तालिका) की ज़रूरतों के लिए परीक्षण डेटा की संरचना और सामग्री पर विचार करना चाहिए। सामान्य योजना संबंधी विचारों के लिए यह लेख देखें।
उदाहरण में, हम जानते हैं कि हमारा संग्रह उन ग्राहकों से बनेगा जिनके पास उपयोगकर्ता नाम है , प्रथम और अंतिम नाम , ईमेल पते , और क्रेडिट कार्ड नंबर ।
अपना परीक्षण डेटा बनाने के लिए, हमें पहले कुछ सेट फ़ाइलें जेनरेट करनी होंगी। एक सेट फ़ाइल एक या अधिक टैब-सीमांकित मानों की एक सूची है जो पहले से मौजूद हो सकती है, या IRI RowGen में 'नई सेट फ़ाइल जेनरेट करें' विज़ार्ड के माध्यम से डेटाबेस कॉलम से मैन्युअल रूप से या स्वचालित रूप से जेनरेट करने की आवश्यकता है।
नाम बनाना
1) "CreateNamesSet.rcl" नाम की एक कंपाउंड डेटा वैल्यू (प्रथम और अंतिम नाम संयुक्त) जॉब स्क्रिप्ट बनाएं, जिसे RowGen एक सेट फ़ाइल बनाने के लिए निष्पादित कर सकता है; आउटपुट को "User.set" कहते हैं क्योंकि इन नामों का उपयोग हमारे उपयोगकर्ता नामों के आधार के रूप में भी किया जाएगा।
2) Names.set में जनरेट करने के लिए तीन फ़ील्ड बनाएं:अंतिम नाम, टैब विभाजक, और पहला नाम। पहले फ़ील्ड को "LastName" नाम दें और वह विधि चुनें जो "names_last.set" नामक IRI द्वारा प्रदत्त सेट फ़ाइल से मानों का चयन करेगी। टैब विभाजक जोड़ने के लिए शाब्दिक मान “\t” जोड़ें, और फिर name_first.set का उपयोग करके LastName और FirstName मानों के लिए उपयोग की जाने वाली प्रक्रिया को दोहराएं।
3) RowGen के साथ CreateNamesSet.rcl चलाएँ, या तो कमांड लाइन पर या IRI वर्कबेंच GUI से, पहले और अंतिम नामों की टैब-सीमांकित User.set फ़ाइल बनाने के लिए, जिसका उपयोग इसमें किया जाएगा उपयोगकर्ता नाम की पीढ़ी और अंतिम परीक्षण फ़ाइल निर्माण दोनों में जो हमारे प्रोटोटाइप संग्रह को पॉप्युलेट करता है।

उपयोगकर्ता नाम बनाना
उपयोगकर्ता नामों के लिए, हम एक सेट फ़ाइल बनाएंगे जो ऊपर जेनरेट की गई User.set फ़ाइल का उपयोग करेगी। इस उदाहरण के लिए उपयोगकर्ता नाम अंतिम नाम, प्रथम नाम और 100 और 999 के बीच एक यादृच्छिक रूप से जेनरेट की गई संख्या को जोड़ देगा।
1) कंपाउंड डेटा विज़ार्ड के साथ एक नई RowGen जॉब स्क्रिप्ट बनाएं, इसे "CreateUsernamesSet.rcl" कहें, और आउटपुट सेट फ़ाइल को "Usernames.set" नाम दें।
2) पार्ट1, पार्ट2 और पार्ट3 नामक तीन घटकों के साथ कंपाउंड यूज़रनेम मान बनाएं।
3) भाग 1 के लिए, वह तरीका चुनें जो पहले से जेनरेट की गई User.set फ़ाइल से (ब्राउज़ करें) मानों का चयन करेगा, और उपयोगकर्ताओं के बीच संबंध बनाए रखने के लिए चयन प्रकार के लिए 'ALL' निर्दिष्ट करें, उपयोगकर्ता नाम, और ईमेल पते। आकार को 5 पर सेट करें।
4) भाग 2 के लिए भाग 1 के लिए उपयोग की जाने वाली प्रक्रिया को दोहराएं, चयन प्रकार को छोड़कर, 'पंक्ति' का चयन करें और कॉलम इंडेक्स को 2 पर सेट करें। आकार को 1 पर सेट करें। यह गारंटी देता है कि सभी अंतिम नामों का उपयोग किया जाएगा। पीढ़ी में, और उसी पंक्ति में पहले नाम का पहला अक्षर उपयोगकर्ता नाम के साथ जोड़ा जाता है।
5) भाग 3 के लिए, प्रत्येक उपयोगकर्ता नाम के साथ एक यादृच्छिक पूर्णांक प्रत्यय लगाने के लिए 100 और 999 के बीच एक संख्यात्मक मान की पीढ़ी निर्दिष्ट करें।
CreateUsernamesSet.rcl के निष्पादन पर, हम देखते हैं कि प्रत्येक उपयोगकर्ता नाम में उनके अंतिम नाम के पहले पांच अक्षर होते हैं, फिर उनका पहला प्रारंभिक, फिर एक यादृच्छिक 3-अंकीय संख्या:
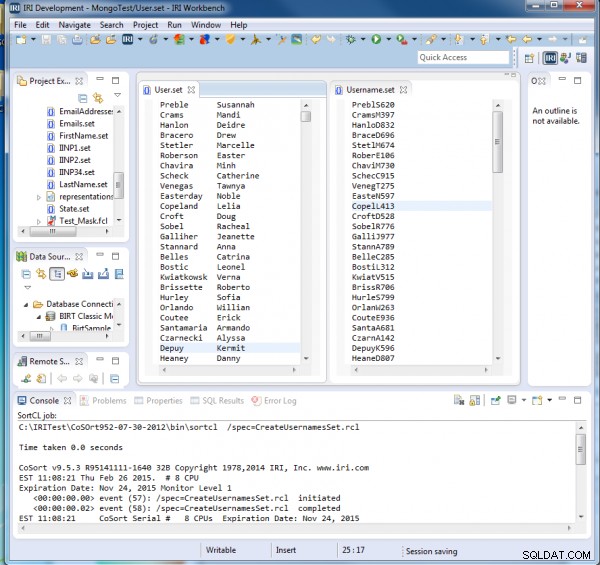
ईमेल जनरेट करना
अगले हम एक ईमेल सेट फ़ाइल बनाएंगे जो उपयोगकर्ता नाम मानों को यादृच्छिक रूप से चयनित डोमेन नामों के साथ जोड़ देगा। चूंकि कुछ ईमेल सेवाएं दूसरों की तुलना में अधिक लोकप्रिय हैं, इसलिए हम याहू और जीमेल डोमेन की उच्च आवृत्ति को दर्शाने के लिए एक वेटिंग सिस्टम भी बनाएंगे।
1) RowGen का 'नया कस्टम टेस्ट डेटा' जॉब विजार्ड चलाकर "CreateEmailsSet" नामक जॉब तैयार करें, जो "Emails.set" नामक एक सेट फाइल तैयार करता है।
2) ईमेल का उपयोगकर्ता नाम भाग तैयार करें। परीक्षण डेटा परिभाषा संवाद में, नया फ़ील्ड क्लिक करें, और पहले फ़ील्ड का नाम बदलें उपयोगकर्ता नाम। जेनरेशन फील्ड डायलॉग लॉन्च करने के लिए उस पर डबल-क्लिक करें और "डिफाइन ..." इसकी सेट फाइल को Usernames.set के रूप में सेट करें। आकार को 9 पर सेट करें और ठीक क्लिक करें।
3) ईमेल का डोमेन भाग तैयार करें (जिसमें @ चिह्न शामिल है)। लेआउट फील्ड्स डायलॉग में, न्यू फील्ड पर क्लिक करें और इसका नाम बदलकर "एड्रेस" कर दें और उस पर डबल-क्लिक करें। जनरेशन फील्ड डायलॉग में, 10 की स्थिति और 20 के आकार के साथ एक "," निर्दिष्ट करें। नीचे डेटा जनरेशन / डेटा वितरण अनुभाग में, "भारित ईमेल" आइटम के एक नए डेटा वितरण को नाम देने के लिए "परिभाषित करें ..." पर क्लिक करें।
4) नए वितरण विज़ार्ड में, 'वस्तुओं का भारित वितरण' चुना और इन वस्तुओं को क्रमशः अनुपात और शाब्दिक टेक्स्ट बॉक्स में दर्ज करें, फिर प्रत्येक को सूची में जोड़ें।
(32 | @gmail.com), (32 | @yahoo.com), (2 | @ibm.com), (4 | @msn.com), (2 | @ymail.com), (2 | @inmail.com), (2 | @cnet.net), (2 | @chase.org), (1 | @iri.com), (1 | @gdic.com), (1 | @aci.com), (2 | @oracle.net), (1 | @gmx.org), (4 | @aol.com), (2 | @inbox.com), (2 | @hushmail.com), (2 | @outlook.com), (2 | @zoho.com), (2 | @yandex.net), (2 | @mail.com)
इन मानों को दर्ज करने के बाद, डेटा लक्ष्य संवाद में जाने के लिए मूल विज़ार्ड में अगला क्लिक करें। आउटपुट फ़ाइल "Email.set" को निर्दिष्ट करने के लिए "डेटा लक्ष्य जोड़ें ..." का उपयोग करें। इसका उपयोग संग्रह-निर्माण के समय भी किया जाएगा।
हम (जीमेल और याहू) के लिए जिस ईमेल के लिए उच्चतम भार निर्धारित करते हैं, वह सबसे अधिक बार दिखाई देता है, जबकि अन्य समय-समय पर दिखाई देते हैं।

क्रेडिट कार्ड नंबर जेनरेट करना
अंत में, हम XXXX-XXXX-XXXX-XXXX प्रारूप में कम्प्यूटेशनल रूप से मान्य कार्ड नंबर बनाएंगे। पहले चार अंक विभिन्न क्रेडिट कार्ड कंपनियों के वास्तविक इश्यू आइडेंटिफ़ायर नंबर (IIN) को दर्शाते हैं, और अंतिम अंक कार्ड की प्रामाणिकता की पुष्टि करते हैं।
ऐसा करने के लिए, एक नया (खाली) कार्य बनाएं और चलाएं। इसे "CreateCCNSet.rcl" (या .scl) कहें, और इसे "CCN.set" बनाने के लिए नीचे दी गई स्क्रिप्ट से भर दें। RowGen लिपियों में /INCOLLECT मान उत्पन्न पंक्तियों की संख्या निर्धारित करता है।

RowGen के उद्देश्य से निर्मित CCN जनरेशन फ़ंक्शन, ccn_gen(“ANY, “-”) को इस फ़ील्ड को पॉप्युलेट करने के लिए कहा जाता है। ध्यान दें कि यूएस और कोरियाई सामाजिक सुरक्षा नंबरों और इटली और नीदरलैंड की राष्ट्रीय आईडी के लिए समान कार्य मौजूद हैं।
अंतिम परीक्षण फ़ाइल बनाना
बनाई गई सभी सेट फ़ाइलों के साथ, अब समय आ गया है कि हम परीक्षण CSV फ़ाइल में उनका उपयोग करें जिसे हम MongoDB संग्रह बनाएंगे और निर्यात करेंगे।
1) "CreateMongoUserData.rcl" नामक नौकरी बनाने के लिए RowGen का 'नया कस्टम टेस्ट डेटा' जॉब विज़ार्ड चलाएँ, जो Customers.csv फ़ाइल को जनरेट करेगा, वह फ़ाइल जिसे हम फिर MongoDB को निर्यात करेंगे।
पी>2) लेआउट फ़ील्ड संवाद दर्ज करने के लिए "लेआउट फ़ील्ड ..." पर क्लिक करें। न्यू फील्ड पर क्लिक करें और पहले फील्ड का नाम बदलकर यूजरनेम कर दें। जेनरेशन फील्ड डायलॉग लॉन्च करने के लिए उस पर डबल-क्लिक करें और "डिफाइन ..." इसकी सेट फाइल को Usernames.set के रूप में सेट करें; फिर इसके चयन प्रकार के लिए ALL चुनें।
3) नई फ़ील्ड पर क्लिक करें और दूसरे फ़ील्ड का नाम बदलकर LastNames कर दें। जेनरेशन फील्ड डायलॉग लॉन्च करने के लिए उस पर डबल-क्लिक करें और इसकी सेट फाइल को User.set के रूप में "परिभाषित करें ..."; फिर इसके चयन प्रकार के लिए ALL चुनें।
4) नई फ़ील्ड पर क्लिक करें और तीसरे फ़ील्ड का नाम बदलकर FirstNames कर दें। जेनरेशन फील्ड डायलॉग लॉन्च करने के लिए उस पर डबल-क्लिक करें और इसकी सेट फाइल को User.set के रूप में "परिभाषित करें ..."; फिर इसके चयन प्रकार के लिए ROWS चुनें और कॉलम इंडेक्स को 2 पर सेट करें।
5) नई फ़ील्ड पर क्लिक करें और चौथे फ़ील्ड का नाम बदलकर ईमेल कर दें। जेनरेशन फील्ड डायलॉग लॉन्च करने के लिए उस पर डबल-क्लिक करें और इसकी सेट फाइल को ईमेल.सेट के रूप में "परिभाषित करें ..."; फिर इसके चयन प्रकार के लिए ALL चुनें।
6) नई फ़ील्ड पर क्लिक करें और पांचवें फ़ील्ड का नाम बदलकर CreditCardNumbers कर दें। जेनरेशन फील्ड डायलॉग लॉन्च करने के लिए उस पर डबल-क्लिक करें और इसकी सेट फ़ाइल को CCN.set के रूप में "परिभाषित करें ..."; फिर इसके चयन प्रकार के लिए ALL चुनें।
7) इन मानों को दर्ज करने के बाद, डेटा लक्ष्य संवाद में जाने के लिए मूल विज़ार्ड में अगला क्लिक करें। Customers.csv आउटपुट फ़ाइल निर्दिष्ट करने के लिए “डेटा लक्ष्य जोड़ें…” का उपयोग करें; फिर उस फ़ाइल को जनरेट करने के लिए स्क्रिप्ट को कार्यक्षेत्र में या कमांड लाइन पर चलाएँ:
rowgen /spec=CreateMongoUserData.rcl

ध्यान दें कि RowGen, रनटाइम पर इस CSV फ़ाइल को बनाने के अलावा, कई, अन्य फ़ाइल, डेटाबेस, स्वरूपित-रिपोर्ट, नाम-पाइप, प्रक्रियात्मक और यहां तक कि रीयल-टाइम BIRT डिस्प्ले भी तैयार कर सकता था। , जेनरेट किए गए परीक्षण डेटा से फ़ील्ड के साथ, एक ही समय में।
MongoDB में आयात करना
अपने Mongo डेटाबेस में CSV फ़ाइल आयात करने के लिए, 'mongoimport उपयोगिता' को कॉल करें और निम्न कमांड चलाएँ:
--db <Database Name> --collection <Collection Name> --type csv --fields <fieldname1,fieldname2,...> --file <File path to the CSV file to import>

यहां परीक्षण संग्रह में रिकॉर्ड हैं (MongoVUE के साथ दिखाया गया है), जिसे MongoDB स्वचालित रूप से प्रत्येक प्रविष्टि के लिए उत्पन्न आईडी मानों के साथ अनुक्रमित करेगा:
MongoDB प्रत्येक संग्रह प्रविष्टि के लिए एक अद्वितीय आईडी मान निर्दिष्ट करता है।
आप MongoDB के लिए प्रोग्रेस सॉफ़्टवेयर के DataDirect ODBC ड्राइवर का उपयोग करके सीधे Mongo डेटाबेस में परीक्षण डेटा लोड कर सकते हैं। कार्यक्षेत्र में RowGen जॉब चलाने से पहले, मेरे पास डेटा प्राप्त करने के लिए MYDB में CUSTOMERS_CNN नामक एक खाली संग्रह था।
कंसोल विंडो में अपने परीक्षण डेटा का पूर्वावलोकन करने के लिए, मैंने पहले स्टडआउट का उपयोग करके कार्य चलाया:

वर्कबेंच में स्क्रिप्ट निष्पादित करने के बाद, अब मैं डेटा स्रोत एक्सप्लोरर और डेटाडायरेक्ट जेडीबीसी ड्राइवर का उपयोग करके अपना डेटा देख सकता हूं।

उपलब्ध पीढ़ी विकल्पों के बारे में अधिक जानकारी के लिए, फ़ाइल लक्ष्य का परीक्षण करें . देखें अनुभाग यहां:https://www.iri.com/products/rowgen/technical-details.



